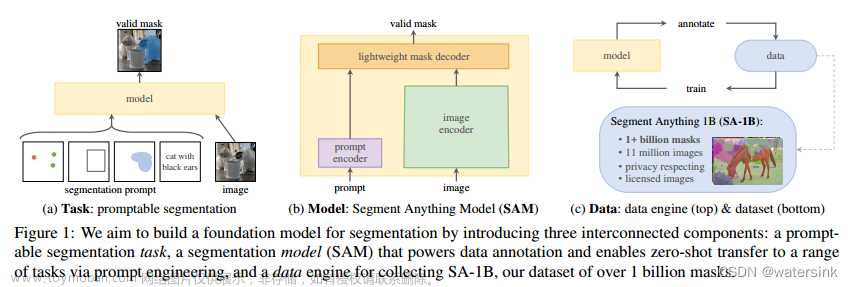
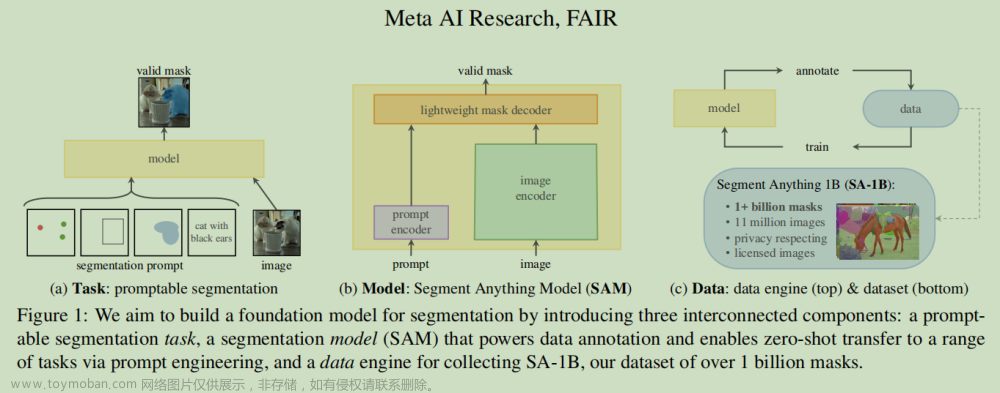
介绍
使用Meta AI的SAM,并添加了一个基本界面来标记图像,并保存COCO格式的掩码。
源码
https://github.com/anuragxel/salt
安装
- 安装SAM;
- 创建conda虚拟环境,使用
conda env create -f environment.yaml; - 安装coco-viewer来快速可视化标注结果。
使用方法
1、将图片放入到<dataset_name>/images/*并且创建空目录<dataset_name>/embeddings
标签会自动保存在<dataset_name>/annotations.json
2、运行helpers脚本
- 运行
extract_embeddings.py来提取图像的中间特征 - 运行generate_onnx.py来生成*.onnx文件,保存在models中。
3、 运行segment_anything_annotator.py,给相关的参数,包括<dataset-path>和<categories>
-
使用左击和右击单击对象(表示在对象边界之外)。
-
n表示添加mask到标注中 -
r拒绝预测的掩膜 -
a和d表示数据集中的循环(next和prev) -
l和k增加和减少其他标注的透明度 -
ctrl+s表示保存当前进度
4、使用coco-viewer来显示你的标注python cocoviewer.py -i <dataset> -a <dataset>/annotations.json
快速使用
docker镜像准备docker pull 1224425503/seg-tool:latest
开启docker容器
docker run -it --rm \
--privileged=true \
--network host \
-e NVIDIA_VISIBLE_DEVICES=all \
-e NVIDIA_DRIVER_CAPABILITIES=all \
--env="DISPLAY" \
--env="QT_X11_NO_MITSHM=1" \
--volume="/tmp/.X11-unix:/tmp/.X11-unix:rw" \
--volume="/dev:/dev" \
-v /dev:/dev \
--gpus all \
--name seg-tool \
1224425503/seg-tool:latest /bin/bash
复现结果
 文章来源:https://www.toymoban.com/news/detail-455880.html
文章来源:https://www.toymoban.com/news/detail-455880.html
安装环境可能存在的问题
This application failed to start because no Qt platform plugin could be initialized
参考https://github.com/NVlabs/instant-ngp/discussions/300文章来源地址https://www.toymoban.com/news/detail-455880.html
到了这里,关于基于Segment anything的实例分割半自动标注的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!