一、DeepStream配置文件解析
参考:官方文档 DeepStream Reference Application - deepstream-app
1. DeepStream应用程序架构
下图为NVIDIA DeepStream 应用程序架构

DeepStream参考应用程序是一个基于GStreamer的解决方案,由一组封装底层api的GStreamer插件组成,以形成一个完整的图。参考应用程序能够接受来自各种源的输入,如摄像头、RTSP输入、编码文件输入,此外还支持多流/源功能。由NVIDIA实现并作为DeepStream SDK的一部分提供的GStreamer插件列表包括:
-
Stream Muxer插件从多个输入源形成一批缓冲区:
Gst-nvstreammux -
预处理插件用于对预定义的roi进行预处理,以进行主要推断:
Gst-nvdspreprocess -
基于NVIDIA TensorRT™的插件分别用于主要和次要(主要对象的属性分类)检测和分类:
Gst-nvinfer -
基于OpenCV的跟踪器插件,用于具有唯一ID的对象跟踪:
Gst-nvtracker -
multistream Tiler插件用于形成2D帧数组:
Gst-nvmultistreamtiler -
屏幕显示(OSD)插件使用生成的元数据在复合框架上绘制阴影框、矩形和文本:
Gst-nvdsosd -
Message Converter和Message Broker插件组合将分析数据发送到云中的服务器:
Gst-nvmsgconvGstGst-nvmsgbroker
2. 配置分组
应用程序配置分为针对每个组件和特定于应用程序的组件的配置组。配置组有:
| Group | Configuration Group |
|---|---|
| Application Group | 与特定组件无关的应用程序配置 |
| Tiled-display Group | 在应用程序中平铺显示 |
| Source Group | 源属性,可以有多个来源,组必须命名为:[source0], [source1]… |
| Streammux Group | streammux组件的参数配置 |
| Primary GIE and Secondary GIE Group | 指定主GIE的属性并修改配置参数,指定辅助GIE的属性并修改配置参数,组必须命名为:[secondary-gie0], [secondary- gi1]… |
| Tracker Group | 指定对象跟踪器的属性并修改配置参数 |
| Message Converter Group | 消息转换器组件的参数配置 |
| Message Consumer Group | 消息使用者组件的参数配置,管道可以包含多个消息使用者组件,组必须命名为[message-consumer0], [message-consumer1]… |
| OSD Group | 屏幕显示(OSD)组件参数配置,该组件在帧上覆盖文本和矩形 |
| Sink Group | Sink 组件的指定属性和参数配置,表示输出显示和文件等渲染,编码,和文件保存,管道可以包含多个汇流点,组必须命名为:[sink0], [sink1]… |
| Tests Group | 诊断和调试,这个组是测试的 |
| NvDs-analytics Group | 指定nvdsanalytics插件配置文件,并将插件添加到应用程序中 |
2.1 Application Group
| Key | Meaning | Type and Value | Example | Platforms |
|---|---|---|---|---|
| enable-perf-measurement | 是否启用应用性能测试 | BOOL型 | enable-perf-measurement=1 | dGPU, Jetson |
| perf-measurement-interval-sec | 采样和打印性能指标的时间间隔,以秒为单位 | Int型, >0 | perf-measurement-interval-sec=10 | dGPU, Jetson |
| gie-kitti-output-dir (不常用) | Pathname of an existing directory where the application stores primary detector output in a modified KITTI metadata format. | String型 | gie-kitti-output-dir=/home/ubuntu/kitti_data/ | dGPU, Jetson |
| kitti-track-output-dir(不常用) | Pathname of an existing directory where the application stores tracker output in a modified KITTI metadata format. | String型 | kitti-track-output-dir=/home/ubuntu/kitti_data_tracker/ | dGPU, Jetson |
- example:
> [application]
> #开启应用程序的性能测试
> enable-perf-measurement=1
> #性能指标测试时间间隔为5(秒)
> perf-measurement-interval-sec=5
> #gie-kitti-output-dir=streamscl
2.2 Tiled-display Group
| Key | Meaning | Type and Value | Example | Platforms |
|---|---|---|---|---|
| enable | 是否使能平铺显示, | Int型 0 = disabled, 1 = tiler-enabled | enable=1 | dGPU, Jetson |
| rows | 平铺显示的行数 | Int型 >0 | rows=5 | dGPU, Jetson |
| columns | 平铺显示的列数 | Int型 >0 | columns=6 | dGPU, Jetson |
| width | 平铺显示的图像宽度 | Int型 >0 | width=1280 | dGPU, Jetson |
| height | 平铺显示的图像宽度 | Int型 >0 | height=720 | dGPU, Jetson |
| gpu-id | 在有多个GPU的情况下,使用的GPU编号 | Int型 ≥0 | gpu-id=0 | dGPU, Jetson |
| nvbuf-memory-type | 元素要分配给输出缓冲区的内存类型 0 (nvbuf-mem-default):平台特定的默认类型 ;1 (nvbuf-mem-cuda-pinned): pinned/主机 CUDA内存;2 (nvbuf-mem-cuda-device):设备CUDA内存;3 (nvbuf-mem-cuda-unified):统一CUDA内存;对于dGPU:所有值都有效;对于Jetson:只有0是有效的 | Int型, 0, 1, 2, or 3 | nvbuf-memory-type=0 | dGPU, Jetson |
| compute-hw | 计算缩放HW来使用,只适用于Jetson,dGPU系统默认使用GPU ;1 (GPU): GPU;2 (VIC): VIC | Int型: 0-2 | compute-hw=1 | dGPU, Jetson |
- example:
> [tiled-display]
> enable=1 #使能图像平铺
> rows=5 #平铺图像行数为5行
> columns=6 #平铺图像列数为6列
> width=1280 #平铺图像宽度为1280
> height=720 #平铺图像高度为720
> gpu-id=0 #使用GPU0
> #(0): nvbuf-mem-default - Default memory allocated, specific to particular platform
> #(1): nvbuf-mem-cuda-pinned - Allocate Pinned/Host cuda memory, applicable for Tesla
> #(2): nvbuf-mem-cuda-device - Allocate Device cuda memory, applicable for Tesla
> #(3): nvbuf-mem-cuda-unified - Allocate Unified cuda memory, applicable for Tesla
> #(4): nvbuf-mem-surface-array - Allocate Surface Array memory, applicable for Jetson nvbuf-memory-type=0
> nvbuf-memory-type=0
2.3 Source Group
设置源属性,DeepStream应用程序支持多个同步源,对于每个源,必须在配置文件中添加一个具有组名的组.
| Key | Meaning | Type and Value | Example | Platforms |
|---|---|---|---|---|
| enable | 是否使能源 | Bool型 | enable=1 | dGPU, Jetson |
| type | 图像源的类型: 1:相机(V4L2); 2:URI; 3: 复用URI; 4:RTSP流;5:相机(CSI只针对Jeston) | Int型:1,2,3,4,5 | type=1 | dGPU, Jetson |
| uri | 编码流的URI类型。URI可以是文件、HTTP URI或RTSP实时源。当type=2或3时有效。对于MultiURI, %d格式说明符还可以用于指定多个源 | String型 | uri=file:///home/ubuntu/source.mp4 uri=http://127.0.0.1/source.mp4 uri=rtsp://192.168.1.123:8554/video uri=file:///home/ubuntu/source_%d.mp4 | dGPU, Jetson |
| num-sources | 源的数量,只有type=3时有效 | Int型 , ≥0 | num-sources=1 | dGPU, Jetson |
| intra-decode-enable | 是否使能intra-only解码(开启后帧率很低) | Bool型 | intra-decode-enable=0 | dGPU, Jetson |
| num-extra-surfaces | 除解码器给出的最小解码曲面外的曲面数。可用于管理管道中解码器输出缓冲区的数量 | Int型, ≥0 and ≤24 | num-extra-surfaces=5 | dGPU, Jetson |
| gpu-id | 使用GPU的编号 | Int型 ≥0 | gpu-id=0 | dGPU, Jetson |
| camera-id | 添加到metadata输入源的唯一ID (可选) | Int型 ≥0 | camera-id=0 | dGPU, Jetson |
| camera-width | 输入源为相机的图像宽度(仅type=1,5 有效) | Int型,>0 | camera-width=640 | dGPU, Jetson |
| camera-height | 输入源为相机的图像高度(仅type=1,5 有效) | Int型,>0 | camera-height=480 | dGPU, Jetson |
| camera-fps-n | 源相机的帧率的帧数(仅type=1,5 有效) | Int型,>0 | camera-fps-n=30 | dGPU, Jetson |
| camera-fps-d | 源相机的帧率的秒数(仅type=1,5 有效) | Int型,>0 | camera-fps-d=1 | dGPU, Jetson |
| camera-v4l2-dev-node | V4L2设备节点号,例如:/dev/vide0(仅type=1有效) | Int型,>0 | camera-v4l2-dev-node=0 | dGPU, Jetson |
| latency | Jitterbuffer大小(以毫秒为单位);只适用于RTSP流 | Int型,>0 | latency=200 | dGPU, Jetson |
| camera-csi-sensor-id | 摄像头模块的Sensor ID(仅type=1有效) | Int型,>0 | camera-csi-sensor-id=1 | dGPU, Jetson |
| drop-frame-interval | 丢帧的间隔。5表示解码器每隔五帧输出一次; 0表示没有丢帧 | Int型,≥0,≤30 | drop-frame-interval=5 | dGPU, Jetson |
| cudadec-memtype | 用于为类型2,3或4的源分配输出缓冲区的CUDA内存元素的类型。不适用于CSI或USB摄像头源。0 (memtype_device):用cudaMalloc()分配的设备内存;1 (memtype_pinned):使用cudaMallocHost()分配的主机/固定内存;2 (memtype_unified):使用cudaMallocManaged()分配的统一内存 | Int型, 0, 1, or 2 | cudadec-memtype=1 | dGPU, Jetson |
| nvbuf-memory-type | CUDA内存的类型,该元素用于分配nvvideoconvert的输出缓冲区,对于类型1的源很有用。0 (nvbuf-mem-default,平台特定的默认值;1 (nvbuf-mem-cuda-pinned):固定/主机CUDA内存;2 (nvbuf-mem-cuda-device):设备CUDA内存;3 (nvbuf-mem-cuda-unified):统一CUDA内存;对于dGPU:所有值都有效;对于Jetson:只有0(0)是有效的 | Int型, 0, 1, 2, or 3 | nvbuf-memory-type=3 | dGPU, Jetson |
| select-rtp-protocol | 用于RTP的传输协议(type=4时有效)0: UDP + UDP组播+ TCP;4: TCP | Int型, 0 or 4 | select-rtp-protocol=4 | dGPU, Jetson |
| rtsp-reconnect-interval-sec | RTSP源强制重连接等待的超时时间(以秒为单位)。将其设置为0将禁用重新连接(type=4时有效) | Int型, ≥0 | rtsp-reconnect-interval-sec=60 | dGPU, Jetson |
| rtsp-reconnect-attempts | 尝试重连接的最大次数。将其设置为-1意味着将无限次地尝试重新连接。当源类型为4且rtsp-reconnect-interval-sec为非零正数值时有效 | Integer, ≥-1 | rtsp-reconnect-attempts=10 | dGPU, Jetson |
| udp-buffer-size | RTSP源的UDP缓冲区的字节大小 | Int型, ≥0 | udp-buffer-size=2000000 | dGPU, Jetson |
- example:
> [source0]
> enable=1 #使能源有效
> #Type - 1=CameraV4L2 2=URI 3=MultiURI 4=RTSP
> type=1 #源属性为V4L2相机
> camera-width=640 #相机源的宽度
> camera-height=480 #相机源的高度
> camera-fps-n=30
> camera-fps-d=1 #相机帧率为30fps
> camera-v4l2-dev-node=0
>
> #type=3 #源属性为本地文件的例子
> #uri=file://../../streams/sample_1080p_h264.mp4
> #num-sources=0 #资源数
>
> #type=4 #源属性为RTSP流的例子
> #uri=rtsp://192.168.1.123:8554/video
> #rtsp-reconnect-interval-sec=60
> #rtsp-reconnect-attempts=10
> #udp-buffer-size=2000000
> gpu-id=0 #使用GPU0
> # (0): memtype_device - Memory type Device
> # (1): memtype_pinned - Memory type Host Pinned
> # (2): memtype_unified - Memory type Unified
> cudadec-memtype=0
>
> [source1]
> enable=0
> #Type - 1=CameraV4L2 2=URI 3=MultiURI 4=RTSP 5=CSI
> type=5
> camera-csi-sensor-id=1
> camera-width=640
> camera-height=480
> camera-fps-n=30
> camera-fps-d=1
>
> [source2]
> enable=0
> #Type - 1=CameraV4L2 2=URI 3=MultiURI 4=RTSP 5=CSI
> type=5
> camera-csi-sensor-id=2
> camera-width=640
> camera-height=480
> camera-fps-n=30
> camera-fps-d=1
>
2.4 Streammux Group
| Key | Meaning | Type and Value | Example | Platforms |
|---|---|---|---|---|
| gpu-id | 使用GPU的编号 | Int型 ≥0 | gpu-id=0 | dGPU, Jetson |
| live-source | muxer源是否为实时的 | Bool型 | live-source=1 | dGPU, Jetson |
| buffer-pool-size | Muxer输出缓冲池中的缓冲区数量 | Int型,>0 | buffer-pool-size=4 | dGPU, Jetson |
| batch-size | Muxer batch大小 | Int型,>0 | batch-size=30 | dGPU, Jetson |
| batched-push-timeout | 以微秒为单位的超时时间,以便在第一个缓冲区可用后推送批处理,即使没有形成完整的批处理 | Int型,>-1 | batched-push-timeout=40000 | dGPU, Jetson |
| width | Muxer输出宽度 | Int型,>0 | width=1280 | dGPU, Jetson |
| height | Muxer输出高度 | Int型,>0 | height=720 | dGPU, Jetson |
| enable-padding | 在缩放时是否通过添加黑带来保持源宽高比 | Bool型 | enable-padding=0 | dGPU, Jetson |
| nvbuf-memory-type | 用于分配输出缓冲区的CUDA内存类型。0 (nvbuf-mem-default,特定于平台的默认值;1 (nvbuf-mem-cuda-pinned):固定/主机CUDA内存;2 (nvbuf-mem-cuda-device):设备CUDA内存;3 (nvbuf-mem-cuda-unified):统一的CUDA内存。dGPU:所有值都有效;Jetson:只有0是有效的 | Int型, 0, 1, 2, or 3 | nvbuf-memory-type=0 | dGPU, Jetson |
| attach-sys-ts-as-ntp | 对于实时源,muxed缓冲区应关联NvDsFrameMeta->ntp_timestamp设置为系统时间或服务器的NTP时间时,当实时源为RTSP流:如果设置为1,系统时间戳将附加为ntp时间戳。如果设置为0,则附加来自rtspsrc的ntp时间戳(如果可用) | Bool型 | attach-sys-ts-as-ntp=1 | dGPU, Jetson |
- example:
> [streammux]
> gpu-id=0 #使用GPU0
> ##Boolean property to inform muxer that sources are live
> live-source=1 #源为实时源
> batch-size=30
> ##time out in usec, to wait after the first buffer is available
> ##to push the batch even if the complete batch is not formed
> batched-push-timeout=4000000
> ##Set muxer output width and height
> width=1280
> height=720
> ##Enable to maintain aspect ratio wrt source, and allow black borders, works
> ##along with width, height properties
> enable-padding=0
> nvbuf-memory-type=0
> ##If set to TRUE, system timestamp will be attached as ntp timestamp
> ##If set to FALSE, ntp timestamp from rtspsrc, if available, will be attached
> attach-sys-ts-as-ntp=1
>
2.5 Primary GIE and Secondary GIE Group
| Key | Meaning | Type and Value | Example | Platforms |
|---|---|---|---|---|
| enable | 是否使能GIE推理引擎 | Bool型 | enable=1 | dGPU, Jetson |
| gie-unique-id | 分配给nvinfer实例的唯一组件ID,用于标识由实例生成的元数据 | Int型,>0 | gie-unique-id=1 | dGPU, Jetson |
| gpu-id | 使用GPU的编号 | Int型 ≥0 | gpu-id=0 | dGPU, Jetson |
| model-engine-file | 预生成的序列化引擎文件的绝对路径 | String型 | model-engine-file=…/…/models/Primary_Detector/resnet10.caffemodel_b4_gpu0_int8.engine | dGPU, Jetson |
| nvbuf-memory-type | 用于分配输出缓冲区的CUDA内存类型。0 (nvbuf-mem-default,特定于平台的默认值;1 (nvbuf-mem-cuda-pinned):固定/主机CUDA内存;2 (nvbuf-mem-cuda-device):设备CUDA内存;3 (nvbuf-mem-cuda-unified):统一的CUDA内存。dGPU:所有值都有效;Jetson:只有0是有效的 | Int型, 0, 1, 2, or 3 | nvbuf-memory-type=0 | dGPU, Jetson |
| config-file | 指定Gst-nvinfer插件属性的配置文件路径名。它可以包含该表中描述的任何属性,除了config-file本身。属性必须在名为[property]的组中定义 | String型 | config-file=config_infer_primary.txt | dGPU, Jetson |
| batch-size | 批处理中需要同时推断的帧数(P.GIE)/对象数(S.GIE) | Int型,>0 | batch-size=4 | dGPU, Jetson |
| interval | 要跳过进行推断的连续批次数 | Int型,>0 | interval=2 | dGPU, Jetson |
| bbox-border-colo | 特定类ID的对象的边框颜色,以RGBA格式指定。必须是bbox-border-color(class-id)。对于多个类id,可以多次识别该属性。如果没有为类ID标识此属性,则该类ID的对象不会绘制边框 | R:G:B:A Float, 0≤R,G,B,A≤1 | bbox-border-color0=1;0;0;1 。bbox-border-color1=0;1;1;1。bbox-border-color2=0;0;1;1。bbox-border-color3=0;1;0;1 | dGPU, Jetson |
| bbox-bg-color | 在特定类ID的对象上绘制的框的颜色,采用RGBA格式。必须为bbox-bg-color(class-id)。对于多个类id,此属性可以多次使用。如果没有将其用于类ID,则不会为该类ID的对象绘制方框 | R:G:B:A Float, 0≤R,G,B,A≤1 | bbox-bg-color3=-0;1;0;0.3 | dGPU, Jetson |
| operate-on-gie-id | 一个GIE推理引擎的唯一ID,该GIE将操作其元数据(NvDsFrameMeta) | Int型,>0 | operate-on-gie-id=1 | dGPU, Jetson |
| operate-on-class-ids | 此GIE必须在其上操作的父GIE的类id。父GIE使用operation-on-gie-id指定 | 分号分隔的整数数组 | operate-on-class-ids=1;2 (操作由父GIE生成的类id为1,2的对象) | dGPU, Jetson |
| infer-raw-output-dir | 将原始推断缓冲区内容转储到文件中的现有目录的路径 | String型 | infer-raw-output-dir=/home/nvidia/infer_raw_out | dGPU, Jetson |
| labelfile-path | labelfile的路径名 | String型 | abelfile-path=…/…/models/Primary_Detector/labels.txt | dGPU, Jetson |
| plugin-type | 用于推理的插件,0: nvinfer (TensorRT) 1: nvinferserver (Triton inference server) | Int型, 0 or 1 | plugin-type=0 | dGPU, Jetson |
| input-tensor-meta | 使用nvdspreprocess插件作为元数据附加的预处理输入张量,而不是在nvinfer内部进行预处理 | Int型, 0 or 1 | input-tensor-meta=1 | dGPU, Jetson |
- example:
> [primary-gie]
> enable=1
> gpu-id=0
> model-engine-file=../../models/Primary_Detector/resnet10.caffemodel_b4_gpu0_int8.engine
> batch-size=4
> #Required by the app for OSD, not a plugin property
> bbox-border-color0=1;0;0;1
> bbox-border-color1=0;1;1;1
> bbox-border-color2=0;0;1;1
> bbox-border-color3=0;1;0;1
> interval=0
> gie-unique-id=1
> nvbuf-memory-type=0
> config-file=config_infer_primary.txt
>
>
2.6 Tracker Group
| Key | Meaning | Type and Value | Example | Platforms |
|---|---|---|---|---|
| enable | 是否使能跟踪模块 | Bool型 | enable=1 | dGPU, Jetson |
| tracker-width | 跟踪模块运行的帧宽度 | Int型, ≥0 | tracker-width=640 | dGPU, Jetson |
| tracker-height | 跟踪模块运行的帧高度 | Int型, ≥0 | tracker-height=384 | dGPU, Jetson |
| gpu-id | 使用GPU的编号 | Int型 ≥0 | gpu-id=0 | dGPU, Jetson |
| ll-config-file | 底层tracker的文件路径 | String型 | ll-config-file=iou_config.txt | dGPU, Jetson |
| ll-lib-file | 底层tracker库文件路径 | String型 | ll-lib-file=/opt/nvidia/deepstream/deepstream-5.0/lib/libnvds_mot_klt.so | dGPU, Jetson |
| enable-batch-process | 支持跨多个流的批处理 | Bool型 | enable-batch-process=1 | dGPU, Jetson |
| enable-past-frame | 启用报告past-frame的数据 | Bool型 | enable-past-frame=0 | dGPU, Jetson |
| tracking-surface-type | 设置地面流类型进行跟踪(默认值为0) | Int型, ≥0 | tracking-surface-type=0 | dGPU, Jetson |
| display-tracking-id | 启用跟踪编号显示 | Bool型 | display-tracking-id=1 | dGPU, Jetson |
- example:
> [tracker]
> enable=0
> #For the case of NvDCF tracker, tracker-width and tracker-height must be a multiple of 32, respectively
> tracker-width=640
> tracker-height=384
> #ll-lib-file=/opt/nvidia/deepstream/deepstream-5.0/lib/libnvds_mot_iou.so
> #ll-lib-file=/opt/nvidia/deepstream/deepstream-5.0/lib/libnvds_nvdcf.so
> ll-lib-file=/opt/nvidia/deepstream/deepstream-5.0/lib/libnvds_mot_klt.so
> #ll-config-file required for DCF/IOU only
> #ll-config-file=tracker_config.yml
> ll-config-file=iou_config.txt
> gpu-id=0
> #enable-batch-process and enable-past-frame applicable to DCF only
> enable-batch-process=1
> enable-past-frame=0
> display-tracking-id=1
>
>
2.7 OSD Group
| Key | Meaning | Type and Value | Example | Platforms |
|---|---|---|---|---|
| enable | 是否使能图像叠加功能 | Bool型 | enable=1 | dGPU, Jetson |
| gpu-id | 使用GPU的编号 | Int型 ≥0 | gpu-id=0 | dGPU, Jetson |
| border-width | 绘制目标的边界框的宽度 | Int型, ≥0 | border-width=1 | dGPU, Jetson |
| border-color | Border目标边界框的颜色 | R;G;B;A Float, 0≤R,G,B,A≤1 | border-color=0;0;0.7;1 | dGPU, Jetson |
| text-size | 描述目标的文本大小 | Int型, ≥0 | text-size=15 | dGPU, Jetson |
| text-color | 描述目标的文本颜色,采用RGBA格式 | R;G;B;A Float, 0≤R,G,B,A≤1 | text-color=1;1;1;1; | dGPU, Jetson |
| text-bg-color | 描述目标的文本的背景颜色,RGBA格式 | R;G;B;A Float, 0≤R,G,B,A≤1 | text-bg-color=0.3;0.3;0.3;1 | dGPU, Jetson |
| clock-text-size | 时钟时间文本的大小 | Int型, >0 | clock-text-size=12 | dGPU, Jetson |
| clock-x-offset | 时钟时间文本的x轴偏移量 | Int型, >0 | clock-x-offset=100 | dGPU, Jetson |
| clock-y-offset | 时钟时间文本的y轴偏移量 | Int型, >0 | clock-y-offset=100 | dGPU, Jetson |
| font | 描述目标的文本字体的名称 | String型 | font=Serif | dGPU, Jetson |
| clock-color | 时钟时间文本的颜色,RGBA格式 | R;G;B;A Float, 0≤R,G,B,A≤1 | clock-color=1;0;0;0 | dGPU, Jetson |
| nvbuf-memory-type | 用于分配输出缓冲区的CUDA内存类型。0 (nvbuf-mem-default,特定于平台的默认值;1 (nvbuf-mem-cuda-pinned):固定/主机CUDA内存;2 (nvbuf-mem-cuda-device):设备CUDA内存;3 (nvbuf-mem-cuda-unified):统一的CUDA内存。dGPU:所有值都有效;Jetson:只有0是有效的 | Int型, 0, 1, 2, or 3 | nvbuf-memory-type=0 | dGPU, Jetson |
| process-mode | NvOSD处理模式:0:CPU;1:GPU;2:Hardware(仅Jetson有效) | Int型, 0, 1, or 2 | process-mode=1 | dGPU, Jetson |
| display-text | 是否显示文本 | Bool型 | display-text=1 | dGPU, Jetson |
| display-bbox | 是否显示画框 | Bool型 | display-bbox=1 | dGPU, Jetson |
| display-mask | 是否显示实例掩码 | Bool型 | display-mask=1 | dGPU, Jetson |
- example:
> [osd]
> enable=1
> gpu-id=0
> border-width=1
> text-size=15
> text-color=1;1;1;1;
> text-bg-color=0.3;0.3;0.3;1
> font=Serif
> show-clock=0
> clock-x-offset=800
> clock-y-offset=820
> clock-text-size=12
> clock-color=1;0;0;0
> nvbuf-memory-type=0
> process-mode=1
>
2.8 Sink Group
| Key | Meaning | Type and Value | Example | Platforms |
|---|---|---|---|---|
| enable | 是否使能sink | Bool型 | enable=1 | dGPU, Jetson |
| type | sink的类型:1: Fakesink;2:基于EGL的窗口sink (nveglglessink)将被弃用;3:编码+文件保存(encoder + muxer + filesink);4:编码+ RTSP流;5: nvdrmvideosink(仅限Jetson);6:消息转换器+消息代理;7: nv3dsink(仅限Jetson) | Int型, 1, 2, 3, 4, 5, 6 or 7 | type=2 | dGPU, Jetson |
| sync | 指示流渲染的速度:0:尽可能快;1:同步 | Int型, 0 or 1 | sync=1 | dGPU, Jetson |
| qos | 指示sink是否生成服务质量(Quality-of-Service)事件,当流水线FPS跟不上流帧速率时,可能导致流水线丢帧 | Bool型 | qos=0 | dGPU, Jetson |
| source-id | 此source-id必须使用其缓冲区的源的ID。源ID在Source Group模块中已经设置。例如,对于组[source1] source-id=0 | Int型, ≥0 | source-id=0 | dGPU, Jetson |
| gpu-id | 使用GPU的编号 | Int型 ≥0 | gpu-id=0 | dGPU, Jetson |
| container | 保存文件时使用的容器。仅对type=3有效; 1: mp4;2: MKV | Int型, 1 or 2 | container=1 | dGPU, Jetson |
| codec | 用于保存文件的编码器。1: H.264(hardware);2: H.265(hardware) | Int型, 1 or 2 | codec=1 | dGPU, Jetson |
| bitrate | 用于编码的比特率,单位为比特/秒。对类型=3和4有效 | Int型, >0 | bitrate=4000000 | dGPU, Jetson |
| iframeinterval | 编码帧内出现频率 | Int型, 0≤iv≤MAX_INT | iframeinterval=30 | dGPU, Jetson |
| output-file | 输出编码文件的路径名。仅对type=3有效 | String型 | output-file=./out.mp4 | dGPU, Jetson |
| nvbuf-memory-type | 用于分配输出缓冲区的CUDA内存类型。0 (nvbuf-mem-default,特定于平台的默认值;1 (nvbuf-mem-cuda-pinned):固定/主机CUDA内存;2 (nvbuf-mem-cuda-device):设备CUDA内存;3 (nvbuf-mem-cuda-unified):统一的CUDA内存。dGPU:所有值都有效;Jetson:只有0是有效的 | Int型, 0, 1, 2, or 3 | nvbuf-memory-type=0 | dGPU, Jetson |
| rtsp-port | RTSP流媒体服务器的端口;未使用的有效端口号,仅对type= 4有效 | Int型 | rtsp-port=8554 | dGPU, Jetson |
| udp-port | 流实现内部使用的端口未使用的有效端口号,仅对type= 4有效 | Int型 | udp-port=5400 | dGPU, Jetson |
| conn-id | 连接索引,nvdrmvideosink有效 (type = 5) | Int型, >=1 | conn-id=0 | dGPU, Jetson |
| width | 渲染器的宽度 | Int型, >=1 | width=1920 | dGPU, Jetson |
| height | 渲染器的高度 | Int型, >=1 | height=720 | dGPU, Jetson |
| offset-x | 渲染器窗口的x轴偏移量 | Int型, >=1 | offset-x=100 | dGPU, Jetson |
| offset-y | 渲染器窗口的y轴偏移量 | Int型, >=1 | offset-y=100 | dGPU, Jetson |
| plane-id | 图像被渲染的平面,nvdrmvideosink有效 (type = 5) | Int型, >=1 | plane-id=0 | dGPU, Jetson |
| msg-conv-config | Gst-nvmsgconv元素的配置文件路径名(type=6) | String型 | msg-conv-config=dstest5_msgconv_sample_config.txt | dGPU, Jetson |
| msg-broker-proto-lib | 使用Gst-nvmsgbroker (type=6)的协议适配器实现路径 | String型 | msg-broker-proto-lib= /opt/nvidia/deepstream/deepstream-5.0/lib/libnvds_amqp_proto.so | dGPU, Jetson |
| msg-broker-conn-str | 后端服务器的连接字符串(type=6) | String型 | msg-broker-conn-str=foo.bar.com;80;dsapp | dGPU, Jetson |
| topic | 消息主题的名称(type=6) | String型 | topic=test-ds4 | dGPU, Jetson |
| msg-conv-payload-type | 负载的类型:0:PAYLOAD_DEEPSTREAM: DeepStream模式负载;1:payload_deepstream_minimal:深度流模式负载最小;256:PAYLOAD_RESERVED:保留类型;257:PAYLOAD_CUSTOM:自定义模式负载(类型=6) | Int型 0, 1, 256, or 257 | msg-conv-payload-type=0 | dGPU, Jetson |
| msg-broker-config | Gst-nvmsgbroker元素的可选配置文件的路径名(type=6) | String型 | msg-conv-config=/home/ubuntu/cfg_amqp.txt | dGPU, Jetson |
| new-api | 使用协议适配器库api或使用新的msgbroker库包装api | Int型,0:直接使用适配器api;1: msgbroker库包装api的 | new-api = 0 | dGPU, Jetson |
| msg-conv-msg2p-lib | 可选自定义有效载荷生成库的绝对路径名。该库实现了由sources/libs/nvmsgconv/ -nvmsgconv.h定义的API。仅适用于msg-conv-payload-type=257, PAYLOAD_CUSTOM | String型 | msg-conv-msg2p-lib= /opt/nvidia/deepstream/deepstream-4.0/lib/libnvds_msgconv.so | dGPU, Jetson |
| msg-conv-comp-id | comp-id nvmsgconv元素的Gst属性;处理元数据的主/从-gie组件ID (gie-unique-id) | Int型, >=0 | msg-conv-comp-id=1 | dGPU, Jetson |
| msg-broker-comp-id | comp-id nvmsgbroker元素的Gst属性;处理元数据的主/从gie组件ID (gie-unique- ID) | Int型, >=0 | msg-broker-comp-id=1 | dGPU, Jetson |
| disable-msgconv | 只添加消息代理组件,而不是消息转换器+消息代理 | Int型 | disable-msgconv = 1 | dGPU, Jetson |
| enc-type | 引擎用于编码器;0: NVENC硬件引擎;1: CPU软件编码器 | Int型, 0 or 1 | enc-type=0 | dGPU, Jetson |
| profile (HW) | 编解码器V4L2 H264编码器(HW)的编码器配置文件:0:Baseline;2:Main;4:High。V4L2 H265编码器(HW): 0: Main;1: Main10 | Int型, valid values from the column beside | profile=0 | dGPU, Jetson |
| udp-buffer-size | UDP内核缓冲区大小(字节)用于内部RTSP输出管道 | Int型, >=0 | udp-buffer-size=100000 | dGPU, Jetson |
| link-to-demux | 用于启用或禁用将特定的“source-id”单独流到该sink | Bool型 | link-to-demux=0 | dGPU, Jetson |
- example:
> [sink0]
> enable=1
> # 1:Fakesink 2:基于EGL的窗口接收器(nveglglessink) 3:编码+文件保存(编码器+混合器+ filesink)4:编码+ RTSP流 5:叠加层(仅适用于Jetson) 6:消息转换器+消息代理
> #Type - 1=FakeSink 2=EglSink 3=File
> type=2
> sync=1 #1:渲染的速度为同步
> source-id=0
> gpu-id=0
> nvbuf-memory-type=0
>
> [sink1]
> enable=0
> type=3
> # 用于文件保存的容器。 仅对type = 3有效
> #1=mp4 2=mkv
> container=1
> # 用于保存文件的编码器
> #1=h264 2=h265
> codec=1
> #encoder type 0=Hardware 1=Software
> enc-type=0
> sync=0
> # 编码帧内出现频率
> #iframeinterval=10
> # 用于编码的比特率,以每秒位数为单位。 适用于type = 3和4
> bitrate=2000000
> #H264 Profile - 0=Baseline 2=Main 4=High
> #H265 Profile - 0=Main 1=Main10
> profile=0
> # 输出编码文件的路径名。 仅对type = 3有效
> output-file=out.mp4
> source-id=0
>
> [sink2]
> enable=1
> #Type - 1=FakeSink 2=EglSink 3=File 4=RTSPStreaming
> type=4
> #1=h264 2=h265
> codec=1
> #encoder type 0=Hardware 1=Software
> enc-type=0
> sync=0
> bitrate=4000000
> #H264 Profile - 0=Baseline 2=Main 4=High
> #H265 Profile - 0=Main 1=Main10
> profile=0
> #set below properties in case of RTSPStreaming
> # RTSP流服务器的端口; 有效的未使用端口号。 对type = 4有效
> rtsp-port=8554
> # 流实现内部使用的端口; 有效的未使用端口号。 对type = 4有效
> udp-port=5400
>
> [sink3]
> enable=0
> type=5
> overlay-id=1
> width=1920
> height=1920
> # 渲染器窗口的水平偏移量(以像素为单位)
> offset-x=10
> # 渲染器窗口的垂直偏移量,以像素为单位
> offset-y=10
> # 显示HEAD的ID。 对叠加水槽有效(类型= 5)
> display-id=0
[sink4]
> enable=0
> type=6
> # Gst-nvmsgconv元素的配置文件的路径名(类型= 6)。
> msg-conv-config=out/source30_1080p_dec_infer-resnet_tiled_display_int8_copy/dstest5_msgconv_sample_config.txt
> msg-broker-proto-lib=/home/nvidia/libnvds_amqp_proto.so
> # 后端服务器的连接字符串(类型= 6)。
> msg-broker-conn-str=foo.bar.com;80;dsapp
> topic=test-ds4
> # 有效负载类型。 0,PAYLOAD_DEEPSTREAM:深度流架构有效负载。1,PAYLOAD_DEEPSTREAM_MINIMAL:深流架构有效负载最小。256,PAYLOAD_RESERVED:保留类型。257,PAYLOAD_CUSTOM:自定义架构有效负载(类型= 6)。
> msg-conv-payload-type=0
> # Gst-nvmsgbroker元素的可选配置文件的路径名(类型= 6)。
> msg-conv-config=/home/ubuntu/cfg_amqp.txt
> # 仅在msg-conv-payload-type = 257,PAYLOAD_CUSTOM时适用。
> msg-conv-msg2p-lib= /opt/nvidia/deepstream/deepstream-5.0/lib/libnvds_msgconv.so
> # nvmsgconv元素的comp-id Gst属性; 要从中处理元数据的主要/次要gie组件的ID(gie-unique-id)。
> msg-conv-comp-id=1
> # nvmsgbroker元素的comp-id Gst属性; 要从中处理元数据的主要/次要gie组件的ID(gie-unique-id)。
> msg-broker-comp-id=1
>
>
2.9 Test Group
- example:
> [tests]
> file-loop=0
>
| Key | Meaning | Type and Value | Example | Platforms |
|---|---|---|---|---|
| file-loop | 输入文件是否应该无限循环 | Bool型 | enable=0 | dGPU, Jetson |
3. Deepstream 最佳设置方法
- 将streammux和主检测器的批量大小设置为输入源的数量。这些设置在配置文件的
[streammux]和[primary-gie]组中。这可以保持管道以最大容量运行。批处理大小大于或小于输入源数量有时会增加管道中的延迟。 - 将streammux的高度和宽度设置为输入分辨率。这在配置文件的
[streammux]组下设置。这确保流不会经过任何不必要的图像缩放。 - 如果从实时源(如RTSP或USB摄像头)进行流传输,请在配置文件的
[streammux]组中设置live-source=1。这可以为实时源提供适当的时间戳,以创建更平滑的播放。 - 图像分块和视觉输出会占用GPU资源。若不需要在屏幕上渲染输出时,可以禁用以下3个功能来最大化吞吐量。例如,在边缘运行推理并仅将元数据传输到云端进行进一步处理时,不需要渲染。
1、禁用OSD或屏幕显示。OSD插件用于绘制边界框等工件,并在输出帧中添加标签。要禁用OSD,在配置文件的
[OSD]组中设置enable=0
2、分块器创建一个NxM网格来显示输出流。要禁用分块输出,请在配置文件的[tile -display]组中设置enable=0
3、禁用渲染输出sink:选择fakesink,即在配置文件的[sink]组中type=1。performance部分中的所有性能基准运行时都禁用了tiling、OSD和output sink
- 如果CPU/GPU利用率较低,则可能是管道中的元素缺乏缓冲区。然后尝试通过设置应用程序中的
[source#]组的num-extra-surfaces属性或者Gst-nvv4l2decoder元素的num-extra-surfaces属性来增加解码器分配的缓冲区数量。 - 当在docker控制台中运行应用程序,并且它的FPS较低,在配置文件的
[sink0]组中设置qos=0。这个问题是由初始负载引起的。当qos设置为1时,[sink0]组中的属性默认值,decodebin开始丢弃帧。 - 优化处理管道的端到端延迟,可以使用DeepStream中的延迟测量方法。
二、DeepStream-5.0 摄像头源&&RTSP拉流源输入,RTSP推流输出
1. USB摄像头源输入,RTSP推流输出
进入/opt/nvidia/deepstream/deepstream-5.0/samples/configs/deepstream-app目录下,打开任一source配置文件,设置[source0]模块的type=1,配置自己的USB摄像头输入参数;设置[sink2]模块的enable=1,配置RTSP推流的参数。
> [source0]
> #Type - 1=CameraV4L2 2=URI 3=MultiURI 4=RTSP
> type=1
> camera-width=640
> camera-height=480
> camera-fps-n=30
> camera-fps-d=1
> camera-v4l2-dev-node=0
> gpu-id=0
>
> [sink2]
> enable=1
> #Type - 1=FakeSink 2=EglSink 3=File 4=RTSPStreaming
> type=4
> #1=h264 2=h265
> codec=1
> #encoder type 0=Hardware 1=Software
> enc-type=0
> sync=0
> bitrate=4000000
> #H264 Profile - 0=Baseline 2=Main 4=High
> #H265 Profile - 0=Main 1=Main10
> profile=0
> # set below properties in case of RTSPStreaming
> rtsp-port=8554
> udp-port=5400
>
>
根绝自己的需求配置好文件后,保存退出,输入命令
deepstream-app -c source4_1080p_dec_infer-resnet_tracker_sgie_tiled_display_int8.txt


2. RTSP拉流输入,RTSP推流输出
进入/opt/nvidia/deepstream/deepstream-5.0/samples/configs/deepstream-app目录下,打开任一source配置文件,设置[source0]模块的type=4,配置RTSP参数;设置[sink2]模块的enable=1,配置RTSP推流的参数。
> [source0]
> #Type - 1=CameraV4L2 2=URI 3=MultiURI 4=RTSP
> type=4
> uri=rtsp://192.168.1.123:8554/video
> drop-frame-interval=2
> rtsp-reconnect-interval-sec=60
> rtsp-reconnect-attempts=10
> udp-buffer-size=2000000
> gpu-id=0
>
> [sink2]
> enable=1
> #Type - 1=FakeSink 2=EglSink 3=File 4=RTSPStreaming
> type=4
> #1=h264 2=h265
> codec=1
> #encoder type 0=Hardware 1=Software
> enc-type=0
> sync=0
> bitrate=4000000
> #H264 Profile - 0=Baseline 2=Main 4=High
> #H265 Profile - 0=Main 1=Main10
> profile=0
> # set below properties in case of RTSPStreaming
> rtsp-port=8554
> udp-port=5400
>
>
- 关于RTSP推拉流部分可参考我的另一篇博客 windows&&linux环境下实现ffmpeg&&vlc rtsp本地视频、摄像头推流,VLC推拉流
根绝自己的需求配置好文件后,保存退出,输入命令文章来源:https://www.toymoban.com/news/detail-456103.html
deepstream-app -c source4_1080p_dec_infer-resnet_tracker_sgie_tiled_display_int8.txt
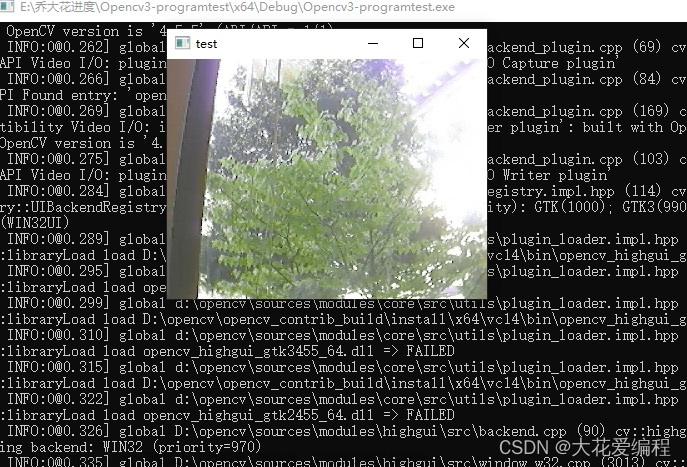
此图为Jstson nx拉流收到windows RTSP推流图像并处理显示结果
此图为windows拉流收到Jetson nx RTSP推流显示结果 文章来源地址https://www.toymoban.com/news/detail-456103.html
文章来源地址https://www.toymoban.com/news/detail-456103.html
到了这里,关于NVIDIA DeepStream配置文件解析;摄像头源&&RTSP拉流源输入,RTSP推流输出的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!