引言
- 本文是使用pytorch对卷积神经网络(Convolutional Neural Network, CNN)的代码实现,作为之前介绍CNN原理的一个代码补充。
- 本文代码相关介绍相对较为详细,也为自己的一个学习过程,有错误的地方欢迎指正。
- 本人介绍CNN原理的链接:CNN原理介绍1
CNN原理介绍2
简述CNN结构
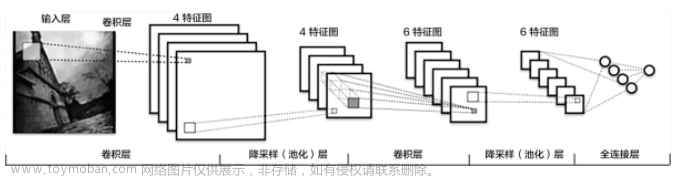
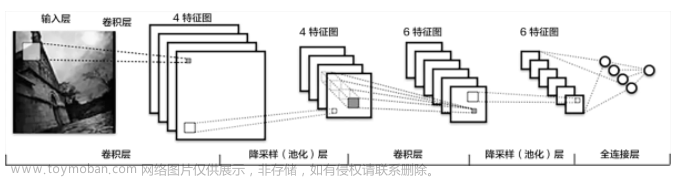
- 为方便理解,如下图所示(详细介绍看上方链接)

- 结构:一个卷积神经网络由若干卷积层、Pooling层、全连接层组成
- 流程通俗理解(卷积):输入图片通过卷积核提取特征参数Feature Maps,此为卷积层的操作;
- 流程通俗理解(池化):得到的特征参数经过池化层进行化简减少参数量,此为池化层的操作
- 流程通俗理解(全连接):将最终提取到的特征信息输入到全连接神经网络进行计算
- 上面图中一张图变成了3张Feature Maps是因为Feature Maps数量跟图片通道数有关,卷积核也同样是对应的,一个通道对应一个卷积核
- 具体名称的介绍可以见:名称介绍
完整流程:
step1 导入需要的包
import torch
import torch.nn as nn
import torch.utils.data as Data
from torch.autograd import Variable
import torchvision # pytorch的一个视觉处理工具包(需单独安装)
- PyTorch中主要的包
- torch.nn :包含用于构建神经网络的模块和可扩展类的子包。
- torch.autograd :支持PyTorch中所有的可微张量运算的子包
- torch.nn.functional :一种功能接口,包含用于构建神经网络的典型操作,如损失函数、激活函数和卷积运算
- torch.optim :包含标准优化操作(如SGD和Adam)的子包。
- torch.utils :工具包,包含数据集和数据加载程序等实用程序类的子包,使数据预处理更容易
- torchvision :一个提供对流行数据集、模型架构和计算机视觉图像转换的访问的软件包
- 这些包可能代码中并未用到;参考资料1
step2 数据预处理
首先是关于将数据转换成tensor的原因
- Tensor的意义:Tensor之于PyTorch就好比是array之于Numpy或者DataFrame之于Pandas,都是构建了整个框架中最为底层的数据结构;
- Tensor的区别:Tensor又与普通的数据结构不同,具有一个极为关键的特性——自动求导而且它表示一个多维矩阵,在计算方面还可以在GPU上使用以加速计算.
- PyTorch中对于数据集的处理有三个非常重要的类:Dataset、Dataloader、Sampler,它们均是 torch.utils.data 包下的模块(类)
- Dataloader是数据的加载类,它是对于Dataset和Sampler的进一步包装,用于实际读取数据,可以理解为它是这个工作的真正实践者。参考资料2
关于torchvision中的数据集
- torchvision中datasets中所有封装的数据集都是torch.utils.data.Dataset的子类,它们都可以用torch.utils.data.DataLoader进行数据加载。以datasets.MNIST类为例,具体参数和用法如下所示:
CLASS torchvision.datasets.MNIST(
root: str,
train: bool = True,
transform: Optional[Callable] = None,
target_transform: Optional[Callable] = None,
download: bool = False
)
- root (string): 表示数据集的根目录,其中根目录存在MNIST/processed/training.pt和MNIST/processed/test.pt的子目录(其实就是对下载的文件指定位置)
- train (bool, optional): 如果为True,则从training.pt创建数据集,否则从test.pt创建数据集
- download (bool, optional): 如果为True,则从internet下载数据集并将其放入根目录。如果数据集已下载,则不会再次下载
- transform (callable, optional): 接收PIL图片并返回转换后版本图片的转换函数(就是把图片或者numpy中的数组转换成tensor)
- target_transform (callable, optional): 接收PIL接收目标并对其进行变换的转换函数
- 具体参考:参考资料3
什么是Variable?
- variable是tensor的封装,在神经网络中,常需要反向传播这些的,所以需要各个节点是连接在一起的,是个计算图,tensor的数据格式就好比星星之火,但是无法汇聚一起;等变成variable之后就可以慢慢燎原了。
- 关于Variable
代码分析

- Data.DataLoader:加载数据
- shuffle:表示打乱数据顺序
- torch.unsqueeze:个人理解就是改变数据shape,此处就是把训练数据本来是一维的给"竖"起来作为一条一条数据进行训练(等以后我想起来更通俗的再修改,具体函数用法看下面参考资料)
- 详情介绍:参考资料4 参考资料5
- 图像尺寸是28*28的,具体验证可见最下面我jupyter转成的html结果
step3 定义网络结构

- Net需要继承自nn.Module,通过super(python中的超类)完成父类的初始化,个人理解类比于python中定义类要继承Object类,这样很多基础定义就可以略去了
- nn.Module是nn中十分重要的类,包含网络各层的定义及forward方法参考资料6
- nn.Sequential返回的是一个序列容器用于搭建神经网络的模块,按照被传入构造器的顺序添加到nn.Sequential()容器中,比如con1中就是进行封装先进行第一层的卷积和池化,conv2同理,然后定义前向传播(注意是卷积两次) 参考资料7
- nn.Conv2d: 在Pytorch的nn模块中,封装了nn.Conv2d()类作为二维卷积的实现,二维卷积应该是最常用的卷积方式了 参考资料8
关于网络结构中流程梳理
-
关于卷积层nn.Conv2d中的参数介绍:in_channels 输入图片的通道数,同理out_channels为输出图片的通道数(都为自定义的,我搜集资料看到有1,3,16,32等等);kernel_size为卷积核大小,5 * 5可以直接简写,如果是3 * 5就要写成元组的形式;stride为卷积核移动的步长;padding为填充的大小,具体意义可见文章顶部原理介绍
-
nn.ReLU()为激活函数,使用ReLU激活函数有解决梯度消失的作用(具体作用看文章顶部原理中有介绍)
-
nn.MaxPool2d:maxpooling有局部不变性而且可以提取显著特征的同时降低模型的参数,从而降低模型的过拟合,具体操作看下图,除了最大值,还可以取平均值
-
nn.Linear主要是用于全连接层 参考资料8
-
x.view()就是对tensor进行reshape:参考资料9

-
关于卷积时候图片size的变化
- 首先输入通道为1,尺寸大小为28 * 28,即(1,28,28)
- 经过卷积后因为自定义输出通道为16,那么尺寸为(16,28,28)
- 经过池化层,因为卷积核是2 * 2的,所以尺寸降低为(16,14,14)
- 继续conv2卷积,池化后就尺寸变成了(32,7,7)
- nn.Linear具体用法(10是因为这个识别结果是0-9,为10个类别):参考资料10
-
关于输出尺寸的计算公式
- O = (I - K + 2P)/ S +1
- I输入尺寸,K是卷积核大小,P是padding大小,S是步长
step4 训练模型
 文章来源:https://www.toymoban.com/news/detail-456332.html
文章来源:https://www.toymoban.com/news/detail-456332.html
- 关于优化器torch.optim.Adam,个人也还不是特别理解详细的作用,此处待补充链接
- 交叉熵损失函数(适合分类模型): 个人之前的总结
- optimizer.zero_grad()关于优化器清空上层的梯度
- 有介绍是为了优化内存的 : 参考资料11
- 有介绍是一种tips故意不清零来进行梯度优化的
- 总之还是那句,优化器我搞懂了再补上…
- 其实单纯论反向传播得时候梯度的更新貌似没有提及是否需要清空上层梯度:梯度下降与反向传播
- loss.backward()反向传播上面介绍Variable的时候已经讲过,已经封装好了(看CNN原理部分反向传播求各个参数不同层级参数的偏导求得相似,结果在这里只需要调用api…)
- torch.max 通俗讲就是返回列表中最大的数,具体用法可以见最下方html文件
完整代码
- 参考资料12
- 参考资料13
import torch
import torch.nn as nn
import torchvision
import torch.utils.data as Data
torch.manual_seed(1) # 设置随机种子, 用于复现
# 超参数
EPOCH = 1 # 前向后向传播迭代次数
LR = 0.001 # 学习率 learning rate
BATCH_SIZE = 50 # 批量训练时候一次送入数据的size
DOWNLOAD_MNIST = True
# 下载mnist手写数据集
# 训练集
train_data = torchvision.datasets.MNIST(
root = './MNIST/',
train = True,
transform = torchvision.transforms.ToTensor(),
download=DOWNLOAD_MNIST
)
# 测试集
test_data = torchvision.datasets.MNIST(root='./MNIST/', train=False) # train设置为False表示获取测试集
# 一个批训练 50个样本, 1 channel通道, 图片尺寸 28x28 size:(50, 1, 28, 28)
train_loader = Data.DataLoader(
dataset = train_data,
batch_size=BATCH_SIZE,
shuffle=True
)
# 测试数据预处理;只测试前2000个
test_x = torch.unsqueeze(test_data.data,dim=1).float()[:2000] / 255.0
# shape from (2000, 28, 28) to (2000, 1, 28, 28)
test_y = test_data.targets[:2000]
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d( # 输入的图片 (1,28,28)
in_channels=1,
out_channels=16, # 经过一个卷积层之后 (16,28,28)
kernel_size=5,
stride=1, # 如果想要 con2d 出来的图片长宽没有变化, padding=(kernel_size-1)/2 当 stride=1
padding=2
),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2) # 经过池化层处理,维度为(16,14,14)
)
self.conv2 = nn.Sequential(
nn.Conv2d( # 输入(16,14,14)
in_channels=16,
out_channels=32,
kernel_size=5,
stride=1,
padding=2
), # 输出(32,14,14)
nn.ReLU(),
nn.MaxPool2d(kernel_size=2) # 输出(32,7,7)
)
self.out = nn.Linear(32*7*7,10)
def forward(self, x):
x = self.conv1(x) #(batch_size,16,14,14)
x = self.conv2(x) # 输出(batch_size,32,7,7)
x = x.view(x.size(0),-1) # (batch_size,32*7*7)
out = self.out(x) # (batch_size,10)
return out
cnn = CNN()
optimizer = torch.optim.Adam(cnn.parameters(),lr=LR) # 定义优化器
loss_func = nn.CrossEntropyLoss() # 定义损失函数
for epoch in range(EPOCH):
for step,(batch_x,batch_y) in enumerate(train_loader):
pred_y = cnn(batch_x)
loss = loss_func(pred_y,batch_y)
optimizer.zero_grad() # 清空上一层梯度
loss.backward() # 反向传播
optimizer.step() # 更新优化器的学习率,一般按照epoch为单位进行更新
if step % 50 == 0:
test_output = cnn(test_x)
pred_y = torch.max(test_output, 1)[1].numpy() # torch.max(test_out,1)返回的是test_out中每一行最大的数)
# 返回的形式为torch.return_types.max(
# values=tensor([0.7000, 0.9000]),
# indices=tensor([2, 2]))
# 后面的[1]代表获取indices
print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.numpy())
# 打印前十个测试结果和真实结果进行对比
test_output = cnn(test_x[:10])
pred_y = torch.max(test_output, 1)[1].numpy()
print(pred_y, 'prediction number')
print(test_y[:10].numpy(), 'real number')
补充一个测试过程掌握的小tips
- 比如使用anaconda中的jupyter测试,但是anaconda中又很多虚拟环境,怎么将jupyter切换到测试用的虚拟环境呢
- 需要注册,具体参考: 参考资料14
- 比如我创建CNN测试环境是名称是python36,而默认是python3也就是base环境,按照上述安装并注册后就可以切换啦
 文章来源地址https://www.toymoban.com/news/detail-456332.html
文章来源地址https://www.toymoban.com/news/detail-456332.html
附件
- 测试CNN代码的详细步骤html文件
- GitHub上资源(html文件自己下载用浏览器打开)
- csdn资源(这个我设置确实是免费,貌似下载还是要收费)
到了这里,关于深度学习4 -- 卷积神经网络(代码实现篇+付详细流程文件)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!