一、分布式ID
ID可以唯一标识一条记录。
对于单体架构,我们可以使用自增ID来保证ID的唯一性。但是,在分布式系统中,简单的使用自增ID就会导致ID冲突。这也就引出了分布式ID问题。分布式ID也要求满足分布式系统的高性能、高可用、高并发的特点。
二、雪花算法
世界上不存在两片一样的雪花。
雪花算法(Snowflake),是Twitter公司提出的一种分布式ID生成算法,是分布式ID问题的经典解决方案。此算法生成的是一个64bit(8字节)的ID,在Java中使用8字节的long来存放,在数据库推荐用bigint来存储。
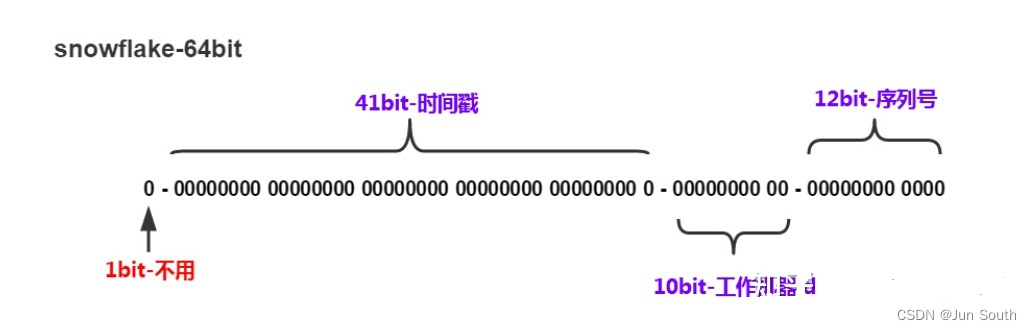
雪花ID结构如下所示,由1bit符号位 + 41bit时间戳 + 10bit工作机器ID + 12bit序列号组成。

- 符号位:恒为0,保证生成的ID为正整数。
- 时间戳:用于记录时间戳的毫秒数,通常选用项目上线时间作为时间戳的相对起点。41bit的时间戳可以保证69年的使用,对于普通的项目绝对是够用了。
- 工作机器ID:10bit的机器ID可以分为两部分,机房ID + 机器ID。这两部分的长度分配没有具体要求,可以根据具体情况动态调整。
- 序列号:用于区分在同一时间戳内,同一机器生成的ID。12bit一共可以标识4096个ID。
从上面的介绍中,我们不难看出雪花算法可以(优点):
- 在高并发的情况下保证分布式ID的全局唯一性。
- 生成的ID按照时间升序排列。
三、时钟回拨问题
时钟回拨,就是服务器上的时间突然倒退回之前的时间,时钟回拨会导致ID不唯一的问题。出现时钟回拨的原因可能是:文章来源:https://www.toymoban.com/news/detail-456417.html
- 人为更改系统时间。
- 有时候不同的机器上需要同步时间,可能不同的机器存在误差,也会出现时钟回拨。
出现时钟回拨后,我们要怎么解决呢?根据回拨的时间长短的不同,可以采取不同的应对方案。文章来源地址https://www.toymoban.com/news/detail-456417.html
- 如果回拨的时间较短,直接在这段时间内拒绝服务,不生成ID。
- 如果回拨的时间较长,直接阻塞是不可取的。可以提前在机器ID或者序列号中留出拓展位置0,当出现时钟回拨时,将拓展位置1,这样也可以保证生成ID的唯一性。
四、其他分布式ID解决方案
- UUID:Universally Unique Identifier,通用唯一识别码。但是存在长度过长(128bit)和完全随机(无序)两个缺点。如果在数据库中作为主键,一个与业务完全无关,二是更占存储空间且无序(用于索引效率低,详情请对照B+树)。
- Redis自增:可以利用redis的原子操作incr来实现分布式ID,但是redis作为一个内存数据库,需要考虑持久化问题。如果用RDB方式持久化,redis宕机可能会导致ID重复。若采用AOF的每修改同步策略虽然能解决重复ID问题,但重启redis的恢复时间会很长。
- 美团leaf算法:跟雪花算法其实是一个思想,这篇博客有详细讲☞传送门。
到了这里,关于分布式ID生成算法——雪花算法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!