在首次启动Hadoop之前还需要进行一些配置工作
我们是在Linux集群上安装Hadoop集群
Linux中对大小写敏感!
1. 配置操作系统的环境变量
注意,一说Linux操作系统的环境变量配置文件就在/home/wangguowei下的.bash.profile中
将hadoop的家目录写好
并引入到path路径中即可
注意:在编辑完成.bash.profile文件后,一定要再次重新让该配置文件生效
2. 创建Hadoop数据目录
在普通用户的家目录下创建hadoopdata目录,这个目录要与核心组件中的配置要对应
3. 格式化文件系统
这个操作只需要在master机上进行
使用hdfs命令就可以进行格式化
但是如果有些时候终端不认识hdfs命令,这种原因就是操作系统的环境变量配置不正确
因为在终端中有些是内部命令有些是外部命令,外部命令需要在环境变量配置后系统才能识别这个命令,这一点要注意

4. 启动和关闭hadoop集群
在3.1.0中打开Hadoop
start-dfs.sh
start-yarn.sh
在3.1.0中关闭Hadoop
stop-yarn.sh
stop-dfs.sh
这里和在Hadoop2.x版本有点不同
?这里出现slave1: ERROR: JAVA_HOME is not set and could not be found.问题
- 可能是在配置hadoop的过程中的配置文件的问题
- 注意:hadoop中的文件中env结尾的文件的环境变量文件,而site结尾的文件是配置文件
- 环境变量文件是env.sh
- 组件配置文件是site.xml
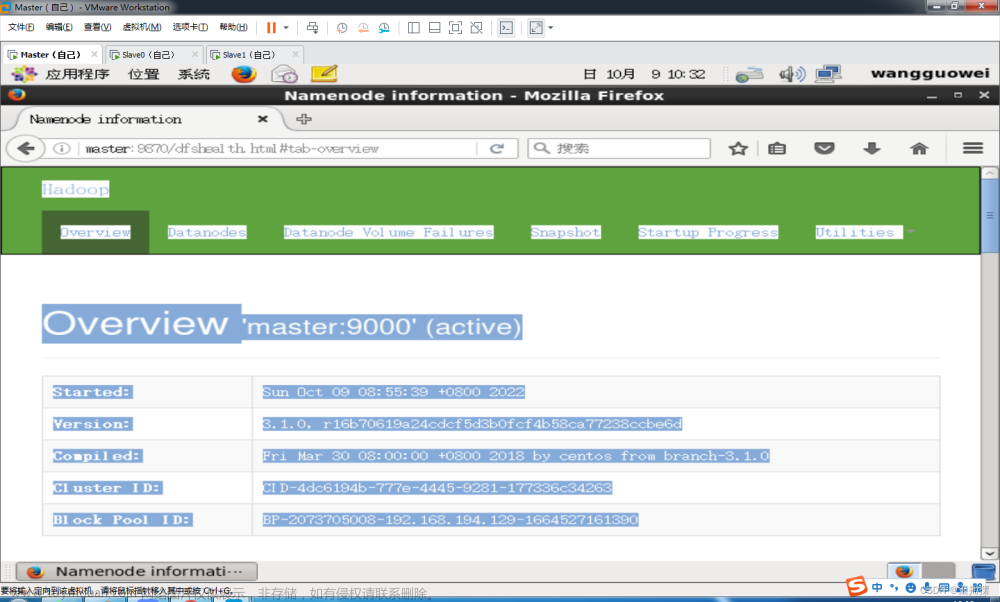
5. 验证hadoop是否启动成功
在hadoop平台上对应用状态进行监测的基本组件
-
hadoop端口号是http://master:9870/可以在浏览器中检测hadoop的运行状况 -
master:18088可以监测yarn的运行状况文章来源:https://www.toymoban.com/news/detail-456453.html
配置hadoop需要的东西
- 2个环境变量文件
- 4个组件配置文件
- 1个workers文件
 文章来源地址https://www.toymoban.com/news/detail-456453.html
文章来源地址https://www.toymoban.com/news/detail-456453.html
到了这里,关于Hadoop集群的启动的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!