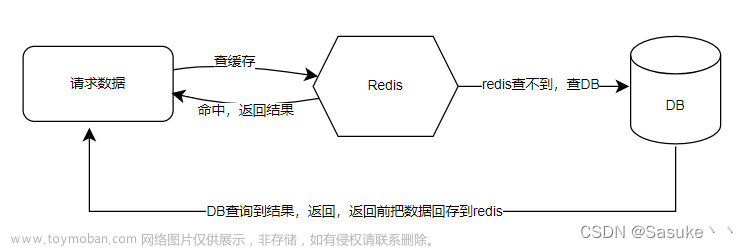
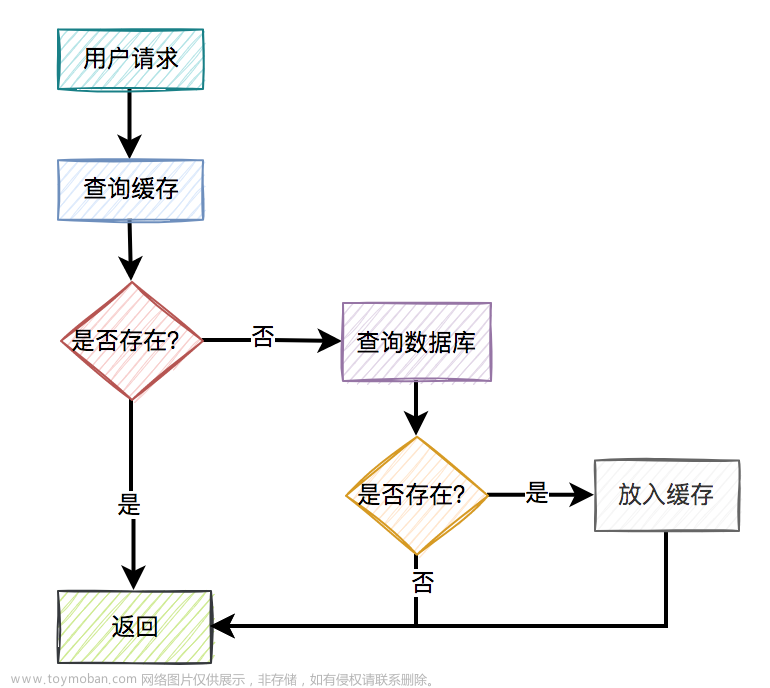
缓存虽然可以提高查询数据的的性能,但是在缓存和数据 进行更新的时候 其实会出现数据不一致现象,而这个不一致其实可能会给业务来带一定影响。无论是Redis 分布式缓存还是其他的缓存机制都面临这样的问题。
数据不一致是如何发生?
数据一致性
- 缓存中有数据,那么缓存的数据和数据库的数据相同。比如缓存是A,数据库也是A
- 缓存中没有数据,数据库是最新的值。
只读缓存
如果是只读缓存,从缓存中查询数据不在的话,那么直接从DB中查询,加载到缓存中。如果有的话直接返回。但是如何要更新/插入数据的话,会先将数据写入DB中,然后将缓存设为失效。
读写缓存
读写缓存,如果有数据进行增删改,需要同步修改缓存的数据,然后按照不同的同步策略,将数据同步到数据库中
- 同步写回策略:更新完缓存,直接将数据写回数据库,一般建议在一个原子事务中操作
- 异步协会策略:更新完缓存,不立即写回数据库,而是按照一定的时间,有丢失数据的风险。
所以汇总一下,只查询不会出现数据不一致情况,但是剩下就是新增和删改。
新增数据
我们来分析一下,如果是插入数据,因为本身缓存中并不存在这个新数据,所以无需对缓存进行任意操作,只需要缓存下次查询的时候拉取到cache中就可以。
修改删除数据
在删除或者修改的时候,因为数据可能已经存在缓存中了,需要在将数据写入DB的同时,将缓存中的数据置为失效,或者是同步更新缓存的数据。所以这个时候就会出现数据的不一致性。
- 先删缓存,在更数据库 (缓存删除了,数据没更新成功,应用会访问到旧值)
- 先更新数据,后删除缓存(数据更新成功,缓存没有删除成功,直接拿缓存的值)

如何解决数据不一致问题?
如上其实就是可能出现的缓存不一致的情况,也就是无论是先删除缓存后更新DB,还是先更新DB后删除缓存,都可能出现一半执行成功一般执行失败。所以这个之后一半引入重试机制来保证。也就是可以可能失败的操作写入到消息队列中,然后如果出现另一半失败的情况下,就从消息队列执行消费,直到成功,但是如果消费成功的话,需要ack 消息队列。
上面其实说的是执行过程中可能执行执行失败的情况,当在高并发场景下,其实可能出现另外两种情况。
1.删除缓存 2.更新数据
比如线程A在删除缓存之后,更新数据到DB中这个时间,有一个请求线程B,发现缓存被删除了,直接读取数据库获取到旧值,写入到缓存中。而线程A这个时候才执行完更新DB的操作,就会导致缓存中数据是旧值,而数据库是新值。
解决方案也比较简单,就是延迟一会进行删除缓存。也就是延迟双删。
redis.delKey(X)
db.update(X)
Thread.sleep(N)
redis.delKey(X)
1.更新数据 2.删除缓存
针对这种情况,可能线程A更新数据完毕,但是还没有删除缓存的值,这个时候进来线程B直接从缓存读取到旧值返回,之后线程A才会删除缓存,也就是存在一个时间差,线程A更新完数据到执行删除缓存成功的间隔,可能导致多线程情况下从缓存读取到旧值,不过这种情况影响的比较小。
小结
本篇主要介绍缓存双写一致性问题,缓存在互联网项目中是提高性能的必备中间件,但是引入一个技术就会带来其他问题,所以我们在实际的开发中,针对缓存和数据之间要多思考可能存在的问题。 文章来源:https://www.toymoban.com/news/detail-456902.html
文章来源:https://www.toymoban.com/news/detail-456902.html
附上一段双检加锁策略文章来源地址https://www.toymoban.com/news/detail-456902.html
/**
* 业务逻辑没有写错,对于小厂中厂(QPS《=1000)可以使用,但是大厂不行
* @param id
* @return
*/
public User findUserById(Integer id)
{
User user = null;
String key = CACHE_KEY_USER+id;
//1 先从redis里面查询,如果有直接返回结果,如果没有再去查询mysql
user = (User) redisTemplate.opsForValue().get(key);
if(user == null)
{
//2 redis里面无,继续查询mysql
user = userMapper.selectByPrimaryKey(id);
if(user == null)
{
//3.1 redis+mysql 都无数据
//你具体细化,防止多次穿透,我们业务规定,记录下导致穿透的这个key回写redis
return user;
}else{
//3.2 mysql有,需要将数据写回redis,保证下一次的缓存命中率
redisTemplate.opsForValue().set(key,user);
}
}
return user;
}
/**
* 加强补充,避免突然key失效了,打爆mysql,做一下预防,尽量不出现击穿的情况。
* @param id
* @return
*/
public User findUserById2(Integer id)
{
User user = null;
String key = CACHE_KEY_USER+id;
//1 先从redis里面查询,如果有直接返回结果,如果没有再去查询mysql,
// 第1次查询redis,加锁前
user = (User) redisTemplate.opsForValue().get(key);
if(user == null) {
//2 大厂用,对于高QPS的优化,进来就先加锁,保证一个请求操作,让外面的redis等待一下,避免击穿mysql
synchronized (UserService.class){
//第2次查询redis,加锁后
user = (User) redisTemplate.opsForValue().get(key);
//3 二次查redis还是null,可以去查mysql了(mysql默认有数据)
if (user == null) {
//4 查询mysql拿数据(mysql默认有数据)
user = userMapper.selectByPrimaryKey(id);
if (user == null) {
return null;
}else{
//5 mysql里面有数据的,需要回写redis,完成数据一致性的同步工作
redisTemplate.opsForValue().setIfAbsent(key,user,7L,TimeUnit.DAYS);
}
}
}
}
return user;
}
到了这里,关于【Redis】聊一下缓存双写一致性的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!