深度强化学习在目标驱动型视觉导航的泛化
参考论文《Towards Generalization in Target-Driven Visual Navigation by Using Deep Reinforcement Learning》
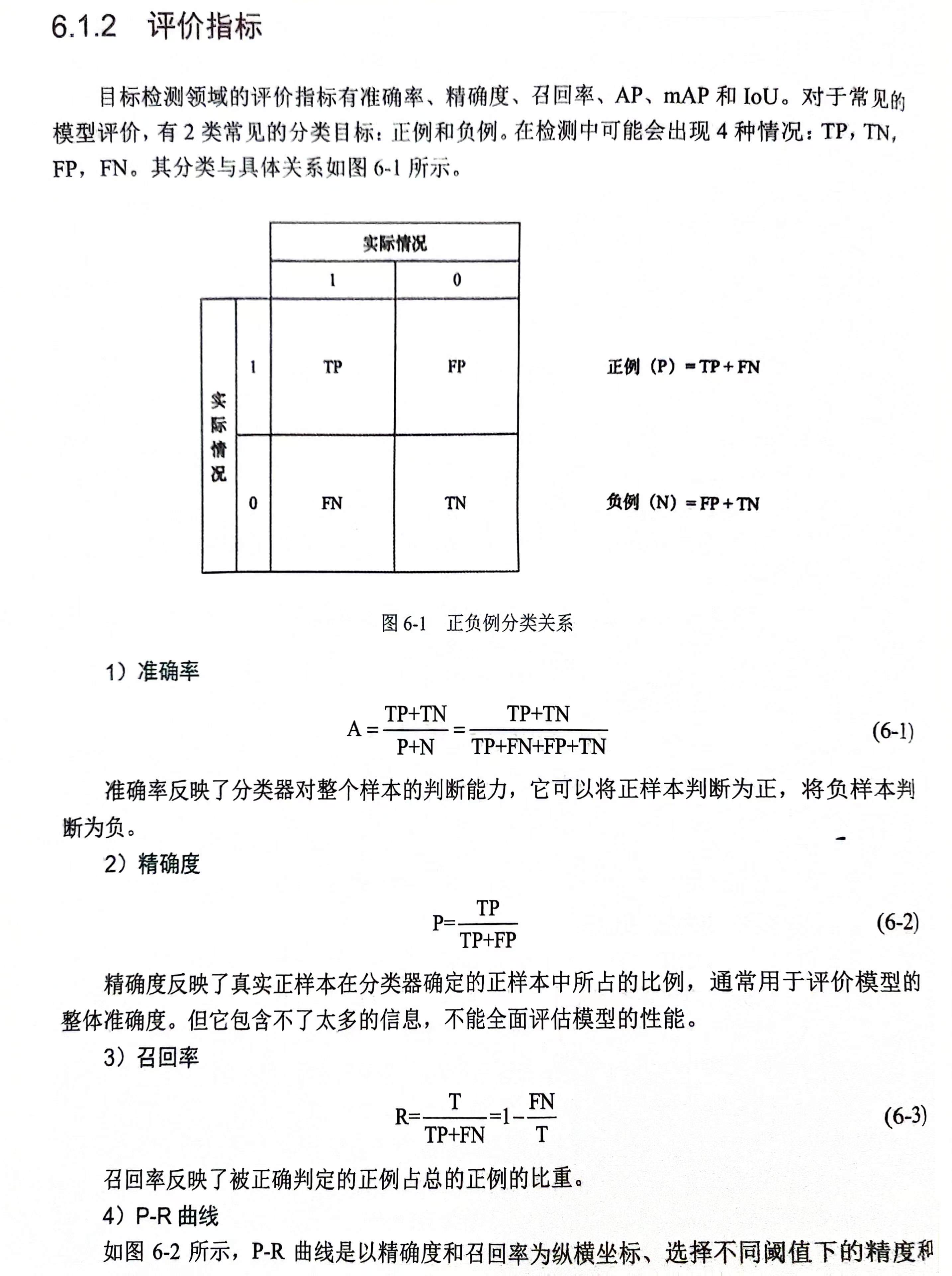
1. 目标驱动型视觉导航问题
目标是仅使用视觉输入就能导航并到达用户指定目标的机器人,对于此类问题的解决办法一般有两种。
- 将经典导航系统与目标检测模块结合起来。
基于地图的导航算法或者SLAM系统与最先进的物体检测或图像识别模型 - 无地图方法
深度卷积神经网络(cnn)与强化学习(RL)相结合
基于地图的导航算法或者SLAM系统与最先进的物体检测或图像识别模型的局限性
- 基于地图的方法假设环境的全局地图可用,而SLAM算法仍然不是专门为目标驱动的视觉导航设计的。
- 几何映射以及映射和规划之间的区别在这个任务中是不必要的,并且会使整个系统不必要地脆弱。
- 深度学习对象检测模型和经典导航算法最初并不是为了一起工作而开发的,将它们结合起来并不是微不足道的。
深度卷积神经网络(cnn)与强化学习(RL)相结合的方法
优势
深度强化学习(DRL)确实允许以自然的方式管理视觉和运动之间的关系,并且它在无地图视觉导航和许多其他机器人任务中显示出令人印象深刻的结果。
局限
在目标驱动的视觉导航中,算法的每次运行都可能指定不同的目标。
强化学习不同目标点解决方案
-
在策略中嵌入目标目标和当前状态。
优点
训练一个算法就可以找到多个目标,而不需要为每个可能的目标学习新的模型参数。
局限性
- 目前的方法仅限于将训练模型的特定场景或对象作为目标
- 对于智能体必须找到的每个特定对象和必须探索的每个新环境,仍然有必要对其进行训练,或者至少对其进行微调。
- 环境是真实的,那么这种DRL代理的训练过程可能非常复杂
-
由两个网络组成的新框架,第一个目标是在未知环境中制定探索策略,而另一个目标是在图像中定位目标物体。域转移技术分别应用于两个网络,并根据各自的任务控制它们的复杂性
2. 创新点和解决的问题
2.1 创新点
设计了双DNN网络组合的架构,第一个是导航网络,其目标是探索环境并接近目标;第二部分是目标定位网络,目的是识别机器人视野中的指定目标。
2.2 解决的问题
强化学习的方法生成的模型泛化能力不强,面对新环境总是需要重新训练和微调,低效、成本高
3. 设计框架
3.1 整体设计
问题建模
系统输入:视觉信息
系统输出:最短动作序列
环境交互:建模为一个POMDP,在离散的时间步长上与环境交互,找到一个策略π,使得折扣奖励的期望最大化
V
π
(
x
)
=
E
π
[
∑
t
=
0
∞
γ
t
r
t
]
V_{\pi}(x)=\mathbb{E}_{\pi}[\sum_{t=0}^{\infin}\gamma^{t}r_t]
Vπ(x)=Eπ[t=0∑∞γtrt]
其中
γ
∈
[
0
,
1
)
\gamma \in[0,1)
γ∈[0,1)是奖励的折扣系数,
r
t
=
r
(
x
t
,
a
t
)
r_t=r(x_t,a_t)
rt=r(xt,at)是
t
t
t时刻的奖励,
x
t
x_t
xt代表
t
t
t时刻的状态,
a
t
∼
π
(
⋅
∣
x
t
)
a_t\sim\pi (\cdot |x_t)
at∼π(⋅∣xt)是策略函数
π
\pi
π产生的动作。MDP(马尔可夫过程)是部分可观察的,智能体不能获取环境的真实状态
x
t
x_t
xt,智能体只能获取到环境的观测值
o
t
o_t
ot。
o
t
o_t
ot由RGB相机当前帧和目标点图像组成。
网络设计思路
o t o_t ot作为输入输入到处理网络中,处理网络由两个分支网络组成:
-
目标定位网络
比较两帧图像并定位目标
-
导航网络
用于学习探索策略以解决复杂的迷宫
注:实验环境基于迷宫,所以这里说是迷宫
输入都由目标定位网络进行处理,输出为在智能体的视野中的相对位置的相对位置向量,将这个向量和当前的RGB帧输入导航网络产生下一个动作。
由于导航任务和目标定位任务的侧重不同,所以在导航任务方面使用轻量级的CNN,而目标定位任务需要更加强的特征提取模型,这样目标定位网络可以通过监督训练的方法离线训练,导航网络可以使用强化学习的方式快速训练。
作者在DRL算法的选择中,使用了IMPALA(Importance Wrighed Actor-Learner Architecture),此算法被用于同时学习大量复杂的视觉任务。其主要优势有两点:
- 利用并行CPU计算实现高效的轨迹生成,并利用gpu实现更快的反向计算。
- 实现了V-trace目标,以取代标准值函数,从而允许样本效率的非策略学习。
关于IMPALA参考【强化学习 44】IMPALA/V-trace - 知乎 (zhihu.com)
3.2 网络架构

能够看出,整体网络由目标定位网络和导航网络组成。
3.2.1 目标定位网络
对于目标在当前智能体视野中的情况考虑为5+1种,示例如下图:
- 极右
- 右
- 中
- 左
- 极左
- 无目标

网络接收两张 224 × 224 224\times 224 224×224的RGB图像作为输入,一个为当前图像帧,另外一个为目标图像帧。
网络结构由ResNet-50网络进行预处理,网络结构在ImageNet上预训练,去掉了最后的两个全连接层,特征提取后,将输出馈送到5个卷积层,每一层的卷积都经过 3 × 3 3\times 3 3×3的卷积核进行步长为1的卷积,通道数分别为512、128、16、16、16。每一层都将RelU作为激活函数,并随后跟一个GroupNorm层。最后使用concat的方式连接两个向量,经过256个隐单元和一个ReLU激活处理,输出为6维的分类结果,对应上述情况。

3.2.2 导航网络
导航网络的主要目标是探索环境,输入为当前视觉RGB帧( 84 × 84 84\times 84 84×84)以及3.2.1所得到的预测结果作为位置估计。RGB帧输入后经过16个 8 × 8 8\times 8 8×8的滤波器(stride=4),再经过一层用32个 4 × 4 4\times 4 4×4的滤波器(stride=2)进行处理,处理后经过ReLU激活函数激活和一个GroupNorm层处理,处理后将输出向量与3.2.1节所输出分类向量进行连接(concat),然后通过一个LSTM网络处理,每层有256个隐单元和ReLU激活函数。
在训练结局按CNN提取的特征也会馈送到反卷积层,其设计为CNN的反向过程,用于估计深度信息。
最终的输出是一个三元素的向量,元素值代表了左转、前进、右转的概率,同时还有一个标量值作为未来的折扣奖励。
3.3 训练
3.3.1 目标定位训练阶段
作者将目标定位网络的训练作为了一个相似性度量学习的问题,使用Capture-Level的数据集进行训练,Capture-Level的数据集的样本由三个一组的图像集组成,三元组包括目标的图片、仿真环境中目标可见的图片、仿真环境中目标不可见的图片。这三张
224
×
224
224\times 224
224×224的图片首先通过ResNet-50的网络结构进行预处理,然后输入到三个卷积层,图像三元组损失函数定义:
l
t
=
1
2
m
a
x
(
0
,
m
+
∣
∣
g
−
f
+
∣
∣
2
−
∣
∣
g
−
f
−
∣
∣
2
)
l_t=\frac{1}{2}max(0,m+||g-f^+||^2-||g-f^-||^2)
lt=21max(0,m+∣∣g−f+∣∣2−∣∣g−f−∣∣2)
m
m
m为边界控制常数,
g
g
g代表从目标图像中提取的特征,
f
+
f^+
f+和
f
−
f^-
f−分别表示目标可见图像与目标不可见图像中提取的特征。
g
g
g与
f
−
f^-
f−、
f
+
f^+
f+两两组合定义为
r
1
=
[
f
+
,
g
]
r
2
=
[
f
−
,
g
]
r_1=[f^+,g]\\r_2=[f^-,g]
r1=[f+,g]r2=[f−,g]
最后,
r
1
r_1
r1和
r
2
r_2
r2分别由最后的两个卷积层和两个全连接层接收处理,产生两个概率向量
p
1
p_1
p1、
p
2
p_2
p2。

向量
p
1
p_1
p1、
p
2
p_2
p2的加权交叉熵损失函数定义为
l
l
(
p
∗
)
=
{
−
d
⋅
l
o
g
(
p
∗
n
)
,
1
≤
n
,
k
≤
5
−
l
o
g
(
p
∗
n
)
,
n
=
0
∨
k
=
0
\mathscr{l}_l(p_*)=\left\{ \begin{array}{lc} -d\cdot log(p_{*n}),&1\leq n,k\leq5\\ -log(p_{*n}),&n=0\vee k=0 \end{array} \right.
ll(p∗)={−d⋅log(p∗n),−log(p∗n),1≤n,k≤5n=0∨k=0
其中
d
=
∣
n
−
k
∣
d=|n-k|
d=∣n−k∣,
n
n
n代表元素目标的真实位置,
k
k
k代表网络中最可能的位置。
p
∗
n
p_{*n}
p∗n概率向量
p
1
p_1
p1或者
p
2
p_2
p2的第
n
n
n个元素。
KaTeX parse error: Expected group after '_' at position 21: …g\ \mathop{max}_̲\limits{i}\ p_{…
综上,总体损失定义为
l
o
b
j
=
l
l
(
p
1
)
+
l
l
(
p
2
)
\mathscr{l}_{obj}=\mathscr{l}_l(p_1)+\mathscr{l}_l(p_2)
lobj=ll(p1)+ll(p2)
3.3.2 导航训练阶段
导航训练通过强化学习IMPALA训练。其包括两个实体:
- Actor,运行在CPU
- Learner,运行在GPU
这两个实体共享网络参数,actor通过与环境交互收集经验轨迹。learner对收集到的经验轨迹进行处理更新网络参数。作者使用16个actor和1个learner。
Actor设计
在学习阶段,导航网络与目标检测网络完全分离。每个IMPALA actor都被放置在不同的迷宫中,对于每个在迷宫中的动作 a t a_t at,它都会从环境中获得奖励 r t r_t rt和新的观测 o t o_t ot。 r t r_t rt总是0,除非agent到达目标 r t r_t rt+1。观测 o t o_t ot由目标位置和当前RGB帧组成,在学习过程中,它们都是由游戏引擎本身生成的。
一旦actor完成预定迭代步数,就将轨迹发送给learner,learner对其进行重新处理以更新网络。
Learner设计
Learner的主要作用是负责损失计算和参数更新,损失
l
o
b
j
\mathscr{l}_{obj}
lobj与深度估计有关,其与策略函数共享模型参数,为加速性能,计算深度损失时仅取中间
80
×
40
80\times 40
80×40个像素的帧,设预测的深度为
d
p
d_p
dp,虚幻引擎提供的深度为
d
e
d_e
de,那么损失
l
d
l_d
ld设计为均方误差的形式:
l
d
=
1
80
×
40
∑
(
d
p
−
d
e
)
2
l_d=\frac{1}{80\times 40}\sum (d_p-d_e)^2
ld=80×401∑(dp−de)2
在得到的图像帧中,上边缘和下边缘一般对应场景中的天花板和地板,不具备实际计算参数更新意义,故而取中间 80 × 40 80\times 40 80×40的像素区域。
为了加速学习的收敛,作者采用了经验重放机制,将轨迹在Actor之间共享,在每次计算的过程中,从经验回放中随机选择两条轨迹经验,与Actor中的当前一个成批并在单个通道中并行处理。
Actor生成轨迹的时间和Learner估计梯度的时间存在滞后性,遵循的策略分别是
μ
\mu
μ(行为策略)和
π
\pi
π(目标策略)。策略学习阶段使用off-policy方法,IMPALA为此使用V-trace的目标
v
t
v_t
vt,目标是对Bellman方程的泛化,定义拟合V-trace目标
v
t
v_t
vt的损失:
l
v
=
1
2
(
v
t
−
V
θ
(
o
t
)
)
2
l_v=\frac{1}{2}(v_t-V_{\theta}(o_t))^2
lv=21(vt−Vθ(ot))2
V
θ
V_{\theta}
Vθ是
θ
\theta
θ参数化的估计值,基于观测
o
t
o_t
ot,损失
l
p
l_p
lp定义为策略
π
\pi
π的相关:
l
p
=
ρ
t
l
o
g
π
θ
(
a
t
∣
o
t
)
(
r
t
+
γ
v
t
+
1
−
V
θ
(
o
t
)
)
l_p=\rho_{t}\ log\ \pi_{\theta}(a_t|o_t)(r_t+\gamma v_{t+1}-V_{\theta}(o_t))
lp=ρt log πθ(at∣ot)(rt+γvt+1−Vθ(ot))
其中
ρ
t
=
m
i
n
(
ρ
‾
,
π
(
a
t
,
∣
x
t
)
μ
(
a
t
∣
x
t
)
)
\rho_{t}=min(\overline{\rho},\frac{\pi(a_t,|x_t)}{\mu(a_t|x_t)})
ρt=min(ρ,μ(at∣xt)π(at,∣xt))是有下界的重要性采样权值之一,根据重要性采样的性质,其在不同的分布中去产生样本,极端情况下会使得策略彼此偏离,从而导致极高的权重
π
(
a
t
∣
x
t
)
μ
(
a
t
∣
x
t
)
\frac{\pi (a_t|x_t)}{\mu(a_t|x_t)}
μ(at∣xt)π(at∣xt),为了减少梯度估计的方差,在
ρ
‾
=
1
\overline{\rho}=1
ρ=1处对权重进行裁剪。
对于off-policy和重要性采样参考强化学习中的奇怪概念(一)——On-policy与off-policy - 知乎 (zhihu.com)
一般
π
θ
\pi_{\theta}
πθ和
V
θ
V_{\theta}
Vθ的参数
θ
\theta
θ是不同的,但是作者设计的结构中两者的参数是相同的。action选择熵的奖励损失
l
c
l_c
lc的定义如下,其用于避免过早收敛的问题。
l
c
l_c
lc平衡了探索和利用,能够保证智能体收敛之前充分探索MDP也即马尔可夫过程。
KaTeX parse error: Expected group after '_' at position 20: …=-\mathop{\sum}_̲\limits{a}\ \pi…
总体损失的参数更新建模为:
l
n
a
v
=
l
d
+
b
l
v
+
l
p
+
c
l
c
l_{nav}=l_d+bl_v+l_p+cl_c
lnav=ld+blv+lp+clc
b
b
b为baselin,
c
c
c为熵代价,新的权重会传递到actor,从而开启新的轨迹。
3.4 环境
使用UE4图形引擎三维虚拟环境。目的是设计泛化性高、能够推广到现实世界场景的算法。
作者设置了两个关卡:
- 迷宫关卡:训练导航网络的关卡
- 捕获关卡:捕获图像并训练目标定位网络的关卡
3.4.1 迷宫关卡
迷宫由自顶而下如下视角的三维模型组成,其包含16个 3 × 3 3\times 3 3×3的迷宫,蓝色球点为actor(来自IMPALA)的放置位置,其目标也被放置。

每当Actor到达目标或者最大步长时,相应的迷宫会进行重新生成,Actor和目标也会重新生成,为了避免过度拟合迷宫和角色到目标路径的特定配置,完全随机地生成迷宫和角色/目标。
环境采用导航与目标定位解耦的方式,在导航网络中使用一个不可见目标。其必须到达目标的唯一方法是遵循UE4自己生成的表征相对位置的UE4 one-hot 6元素向量。
为了使导航网络能够从模拟环境直接转移到真实环境,使用了域随机化的方式,为了使得系统对域变化更加有鲁棒性,在每次一个Actor达到目标时,随机改变以下参数:“迷宫墙高度”、“迷宫墙纹理”、“迷宫地板纹理”、“光线颜色”、“光线强度”、“光源角度”。
依赖于两个完全可分离的组件(即导航和目标识别网络)。因此,导航网络可以更小,大大减少了训练时间,提高了其有效性。同样重要的是要强调,这不会损害定位对象的准确性,因为对象识别网络可以任意复杂
DR参考( CV中,域随机化 (Domain Randomization) 与数据增广有何异同? - 知乎 (zhihu.com)
Actor的可能动作有三种:向右转”、“向前移动”、“向左转”。为了模拟真实机器人运动的不确定性,Actor运动的速度和角度中注入均匀噪声,由于两个网络的训练是分开进行的,所以导航网络的输入向量不是目标定位网络产生的输入向量,而是由UE4自身产生的输入向量。为了使导航网络对定位网络可能出现的分类错误具有更强的鲁棒性,我们保证由UE4生成的 one-hot 向量有10%的错误概率(在这种情况下,从所有类中统一选取)。
3.4.2 捕获关卡
目标定位网络以监督方式训练。将摄像机放置在固定位置,并在其视野中随机生成物体。每次相机拍照时,当前的对象都会被随机生成的对象替换。对于每个图像,我们从引擎获得每个物体相对于相机的相对位置。我们将位置离散为五类:“极右”、“右”、“中”、“左”和“极左”。然后,我们从网络上下载描绘目标物体的图片,并将它们与两个图像相关联。然后,数据集的每个条目由以下部分组成:目标的图像、目标不存在的捕获、目标存在的捕获以及目标在该捕获中的相对位置。
该数据集统计了9类物体的63万个样本,分别是:“椅子”、“监视器”、“垃圾”、“微波炉”、“瓶子”、“球”、“灯”、“植物”和“罐子”。在模拟器中,对于每个对象,我们使用4到10个不同的网格。
4. 实验
在实验中,我们测试了目标驱动视觉导航系统在不可见环境下的性能。特别地,我们分析了代理探索周围环境和到达指定目标的能力。为此,我们设计了三种测试,将在下面的部分中进行描述。此外,我们提出了一项消融研究,以检验辅助深度估计损失对助剂性能的好处。最后,为了验证算法的泛化能力,我们在一个复杂的真实环境中使用了一个真实的机器人。
4.1 训练相关
训练导航网络
使用无动量的SGD训练具有16个actor的导航网络,训练了7000万步,学习率为0.0005,批处理大小为8。目标定位网络使用合成数据集的前54万个样本进行50次epoch的训练,学习率为0.0025,批大小为128,边际常数m = 0.1。使用另外90000个样本来实现早期停止和选择最佳模型参数。
训练相关开源项目地址isarlab-department-engineering/DRL4TargetDrivenVN: Repository with the code of the paper Towards Generalization in Target-Driven Visual Navigation by Using Deep Reinforcement Learning (github.com)


4.2 仿真实验
为了衡量我们的目标驱动视觉导航系统在未知环境下的性能,设计了三种类型的测试:一种是检查周围环境的探测能力,另外两种是验证它是否能够定位并到达指定的目标。对目标驱动任务的验证是通过将我们的方法与不同策略进行比较来实现的。分别与随机智能体(RA)、目标驱动导航模型(TDNM)与主动对象感知器(AOP)进行比较,TDNM与AOP考虑了其两版的SOTA基线,其区别为是否具备域随机化(DR)。
TDNM参考Target-driven visual navigation in indoor scenes using deep reinforcement learning | IEEE Conference Publication | IEEE Xplore
AOP参考Active Object Perceiver: Recognition-Guided Policy Learning for Object Searching on Mobile Robots | IEEE Conference Publication | IEEE Xplore
- 对于不具备域随机化的实验,直接评估了TDNM和AOP的性能,在16个3 × 3的迷宫中训练两个模型,但是没有域随机化(即迷宫的配置、纹理、灯光、目标等从训练开始就都是固定的)。根据作者提出的训练协议,对16个迷宫中的每一个都使用了不同的特定层
- 具备域随机化的实验并不能直接应用,因为上述方法需要特定层,每个场景特定层在单个固定场景中进行训练,每一代的训练,16个迷宫都会发生变化,在整个训练过程中会产生大量的场景特定层,每个场景特定层只会在一集中进行训练,从而阻碍了整个网络的正确学习。
为了考虑平衡和通用,直接使用引擎提供的基础真值边界框为其提供信息,而不是从头开始训练AOP的对象识别网络(包括带DR和不带DR)
探索实验:
将智能体放置在一个20 × 20迷宫的中心,这个迷宫比训练agent的3 × 3迷宫要大得多。我们给它180秒,尽可能多地探索它。一代结束后测量其发现迷宫的百分比。(实际证明当前条件不可能探索整个迷宫)
智能体只有在到达目标(在探索开始时,智能体是未知的)时才会得到积极的奖励。因此,鼓励尽可能快地探索迷宫。这意味着应该避免重访已经检查过的地点,这正是wall-following政策所做的。
wall follower是一种著名的解迷宫算法,特别是对于单连通的迷宫,它是一种保证agent不会迷路,不会走同一条路径两次以上的技术。

使用Grad-CAM++中的可视化显著性图的方法,智能体倾向于对右边的墙体以及边缘区域感兴趣。

参考Grad-CAM++: Generalized Gradient-Based Visual Explanations for Deep Convolutional Networks | IEEE Conference Publication | IEEE Xplore
通过对价值函数的分析,也发现可以转弯的角落和死角的转弯价值函数的表现是不同的,死角处明显急剧下降。

对于不同光照强度的考量,用四个级别的光照强度,对于每个迷宫的光照设置,我们随机选择三个地板和墙壁纹理。对于48种可能的组合中的每一种,我们对3次运行的结果取平均值。在暗框中区分墙壁轮廓的困难。

智能体的得分为蓝色,人类专家的表现得分为红色线,迷宫生成种子:(a) 2, (b) 3, ©, 4, (d) 5。智能体可以在良好的光强值下获得高分。然而,当亮度降低时,性能会迅速下降。在所有图形中可以看到的广泛得分范围是由特定的墙壁纹理引起的,我们的代理产生了较差的性能。每个光强水平对应的分数范围非常大。代理的性能波动很大,对于某些特定的墙壁纹理,它会达到相当低的水平。然而,在同一张图中,我们还可以看到,在其他一些设置中,智能体可以接近人类专家的表现,考虑到它只是在非常小的3 × 3随机迷宫中训练这种效果令人震惊。

RA的影响如下表所示

目标驱动实验
将智能体放置在一个5 × 5的迷宫中,在一个有三个不同物体的房间结束,包括目标。对于智能体来说,这个实验自然分为两个阶段:它首先要探索迷宫以找到房间,然后它必须将目标与其他物体区分开来,定位并接近它。当代理到达目标时(即,当它们碰撞时)或90秒过去时,事件结束。图例中目标是红色椅子。

我们尝试使用用于训练对象定位网络的所有九个不同对象,以及其他三个以前未见过的对象类(“Can”,“Extinguisher”和“Boot”),平均每个运行六次。为了测量代理性能,使用三个指标:目标到达所需的时间(以秒为单位)、成功率(百分比)、(归一化逆)路径长度(SPL)加权成功率。
SPL定义如下:
S
P
L
=
1
N
∑
i
=
1
N
S
i
l
i
m
a
x
(
p
i
,
l
i
)
SPL=\frac{1}{N}\mathop{\sum}_{i=1}^{N}S_i\frac{\mathscr{l}_i}{max(p_i,l_i)}
SPL=N1∑i=1NSimax(pi,li)li
其中,
N
N
N是测试代数,
l
i
\mathscr{l}_i
li是第
i
i
i代的智能体从起点到终点的最短路径长度,
p
i
p_i
pi是第
i
i
i代的智能体实际路径长度。

实验结果表明,两个SOTA基线确实存在泛化能力不足的情况,测试环境比训练场景要困难得多,因此一个适当的探索策略对于完成任务至关重要。如果没有这样的策略,就极不可能到达有物体的房间,正如RA结果所证实的那样。
即使SOTA的两个baseline使用领域随机化训练,也不能有效的探索整个迷宫,因为其过度依赖特定的场景层,所以在推广到新场景的问题上会出现之前分析过的特定层过多等问题,单一的复杂架构来同时处理探索和目标识别。因此,它们的优化更加困难,并且更难实现导航功能,这些功能可以在比用于训练的测试场景更广泛和更复杂的测试场景中进行推广。
跟两个baseline相比平均奖励也更高,而且训练时间显著减少,作者的模型大约156小时内完成7000万步的训练,而TDVN和AOP需要超过380小时才能完成大约4000万步的训练(我们决定不再继续下去,因为曲线在数百万步内没有显示出任何改善的迹象)。

目标驱动实验(20 × \times × 20)
测试迷宫是一个更大的20 × 20迷宫,时间限制增加到300秒。目的是评估目标定位网络和导航网络在距离较长的情况下的协作能力。
可以注意到到达目标所需的时间显着增加,而成功率和SPL都显着降低。迷宫的大小也意味着一个相当低的SPL,对于代理和人类。事实上,虽然从起始位置到目标的最短路径并不是特别长,但智能体/人所覆盖的实际距离可能非常大。

消融实验
作者使用了不具备深度估计辅助信息和具备深度估计辅助信息的两种实验进行对比,研究结果表明,深度估计有助于制定稳健的导航策略。由于主要任务是导航,我们的目标是教它深度的基本概念,产生的图像精度很差。然而,可以清楚地看到,它能够从图像的其余部分区分出正确的墙,我们认为这可能鼓励了跟随墙策略函数的发展。每个图右侧的小图为反卷积图。

4.3 真实实验
作者构建了几个4 × 4的室内和室外迷宫。

用于前两种类型测试的六种迷宫配置。(a) - (d)在第一行中,用灰色的地板描绘了室内的迷宫。(e) - (h)第二行用绿色地板表示的是室外使用的配置。

第三类测试中使用的四种组合。我们总是使用相同的迷宫,我们将机器人(右下角的红色圆圈)和五个可能的物体:“监视器”(Mo),“垃圾”(T),“微波炉”(Mi),“瓶子”(B)和“灯”(L)。我们形成四个组合,每个组合有三个不同的物体:(a) C1, (B) C2, © C3, (d) C4。然后,对于每个组合,我们对每个目标执行一次运行。

(a)同一迷宫在室内的两个不同方向:0°(左)和180°(右)。(b)室外迷宫举例。在这种设置中,背景是完全不同的。特别是,它的特点是存在大量行人,这是智能体在训练过程中从未看到的动态元素。
在真实实验中,采用三种方式进行测试:
- 机器人和目标都被随机放置在迷宫中,agent的目标是尽可能快地到达目标。当机器人接近目标物或最大步数达到1000步时,运行结束;
- 机器人被随机放置在迷宫中,它的目标只是尽可能多地探索。在这种情况下,当达到最大1000步数时,一代结束;
- 机器人被放置在一个简单的迷宫中,与包括目标在内的三个物体一起。本实验的目的是验证agent区分部分遮挡物体、定位目标并接近目标的能力。对于第一种,当机器人到达目标或经过1000步后,运行结束。
作者考虑到所有的迷宫配置、位置、机器人目标定位和测试类型,我们总共运行了84个实验。
所有实验中使用的机器人与训练中使用的角色有着本质上不同的形状,但执行与模拟实验中的智能体相同的动作:“向右转”,“向前移动”,“向左转”。
室内实验效果
机器人在探索了大约一半的迷宫后,平均成功率为46%。作者期望第一次实验的成功率与勘探效果之间有很强的相关性。但结果表明,前者略逊于后者。这可能是由机器人/目标定位引起的。事实上,我们确保代理和目标处于合理的距离,特别是后者被放置在不太可能被探索的区域。
为了验证智能体对背景和光线变化的敏感性,对一个迷宫配置以两种不同的方式将其定向上面的图中有体现,实验结果可以明显看出,算法更倾向于第一个方向。这表明,虽然它可以导航,但它对迷宫周围的环境很敏感。


在第三个实验中,我们考虑一个迷宫配置和五个目标:“监视器”,“垃圾”,“微波炉”,“瓶子”和“灯”。我们制作了四种不同的配置,每种配置三个对象。每一个一代,总共12代。
从表X中报告的结果来看,可以说智能体能够识别并到达75%的对象。值得注意的是,模型从未见过任何真实的物体,即使是我们在实验中使用的物体。有趣的是,每次它被指定为目标时,它都能够接近“微波”,这与模拟中发生的情况相反,它总是失败。在这方面,我们认为使用预训练的ResNet-50起着重要的作用。

室外实验效果
重复第1类和第2类测试,同样在室外迷宫中测量agent的性能。

实验结果结果中可以看出(参考表VIII和IX),第一类测试的性能略有下降。另一方面,智能体的勘探能力实际上保持不变。尽管室内和室外的照明和背景差异很大,但算法的性能是一致的。
5. 主要代码
作者公开代码地址文章来源:https://www.toymoban.com/news/detail-457044.html
isarlab-department-engineering/DRL4TargetDrivenVN: Repository with the code of the paper Towards Generalization in Target-Driven Visual Navigation by Using Deep Reinforcement Learning (github.com)文章来源地址https://www.toymoban.com/news/detail-457044.html
5.1 目标定位网络
class ObjNet(nn.Module):
def __init__(self):
super(ObjNet, self).__init__()
self.resnet = nn.Sequential(*list(models.resnet50(pretrained=True).children())[:-2])
for p in self.resnet.parameters():
p.requires_grad = False
self.conv_1 = nn.Conv2d(in_channels=RESNET_SIZE, out_channels=D1, kernel_size=3, padding=1)
self.bnc1 = nn.GroupNorm(int(D1 / 2), D1)
self.conv_2 = nn.Conv2d(in_channels=D1, out_channels=D2, kernel_size=3, padding=1)
self.bnc2 = nn.GroupNorm(int(D2 / 2), D2)
self.conv_3 = nn.Conv2d(in_channels=D2, out_channels=D3, kernel_size=3, padding=1)
self.bnc3 = nn.GroupNorm(int(D3 / 2), D3)
self.conv_4 = nn.Conv2d(in_channels=D3, out_channels=D3, kernel_size=3, padding=1)
self.bnc4 = nn.GroupNorm(int(D3 / 2), D3)
self.conv_5 = nn.Conv2d(in_channels=D3, out_channels=D3, kernel_size=3, padding=0)
self.bnc5 = nn.GroupNorm(int(D3 / 2), D3)
self.lin_match = nn.Linear(D3 * 5 * 5 * 2, DL)
self.match_softmax = nn.Linear(DL, 6)
def forward(self, x1, goal):
self.resnet.eval()
x_ = torch.cat([x1, goal], dim=0)
x3_r = self.resnet(x_)
x3_act = self.bnc1(F.relu(self.conv_1(x3_r)))
x3_act = self.bnc2(F.relu(self.conv_2(x3_act)))
x3_act = self.bnc3(F.relu(self.conv_3(x3_act)))
x_1g = x3_act[:x1.shape[0] + goal.shape[0]]
x_1g = self.bnc4(F.relu(self.conv_4(x_1g)))
x_1g = self.bnc5(F.relu(self.conv_5(x_1g)))
x_1 = x_1g[:x1.shape[0]].view(x1.shape[0], D3 * 5 * 5)
x_g = x_1g[x1.shape[0]:].view(goal.shape[0], D3 * 5 * 5)
x_1g = torch.cat([x_1, x_g], dim=1)
x_1g = F.relu(self.lin_match(x_1g))
vis_match_1g = torch.clamp(F.softmax(self.match_softmax(x_1g), dim=-1), 0.00001, 0.99999)
return vis_match_1g
@staticmethod
def get_weights(layer):
tot = 0
for p in layer.parameters():
tot += p.sum()
return tot.item()
5.2 导航网络
class Net(nn.Module):
def __init__(self, a_dim):
super(Net, self).__init__()
self.a_dim = a_dim
self.goal = None
self.conv1 = nn.Conv2d(in_channels=CHANNELS, out_channels=D1, kernel_size=8, stride=4, padding=0)
self.bnc1 = torch.nn.GroupNorm(int(D1 / 2), D1)
self.conv2 = nn.Conv2d(in_channels=D1, out_channels=D2, kernel_size=4, stride=2, padding=0)
self.bnc2 = torch.nn.GroupNorm(int(D2 / 2), D2)
self.deconv1 = nn.ConvTranspose2d(in_channels=D2, out_channels=D1, kernel_size=4, stride=2, padding=0)
self.debnc1 = torch.nn.GroupNorm(int(D1 / 2), D1)
self.deconv2 = nn.ConvTranspose2d(in_channels=D1, out_channels=1, kernel_size=8, stride=4, padding=0)
self.lin = nn.Linear(NEW_SIZE * D2 + 5, DL)
self.lstm = nn.LSTM(DL, DR)
self.p = nn.Linear(DR, a_dim)
self.v = nn.Linear(DR, 1)
self.distribution = torch.distributions.Categorical
def forward(self, x, hc, vis_match):
x_84 = F.adaptive_avg_pool2d(x.view(-1, CHANNELS, x.shape[-2], x.shape[-1]), 84)
x1 = self.bnc1(F.relu(self.conv1(x_84)))
x2 = self.bnc2(F.relu(self.conv2(x1)))
x2_ = x2.view(-1, D2 * NEW_SIZE)
x3 = F.relu(self.lin(torch.cat([x2_, vis_match.view(-1, 5)], dim=1)))
x4, hc = self.lstm(x3.view(-1, x.shape[-4], DL), hc)
s0 = x4.shape[0]
s1 = x4.shape[1]
x4 = F.relu(x4.view(-1, DR))
logits = self.p(x4).view(s0, s1, self.a_dim)
values = self.v(x4).view(s0, s1)
x1_depth = self.debnc1(F.relu(self.deconv1(x2)))
x2_depth = F.relu(self.deconv2(x1_depth))
depth_pred = torch.clamp(x2_depth[:, :, 22:62, 2:82], min=0, max=1)
return logits.squeeze(), values, hc, depth_pred
def set_goal(self, goal):
self.goal = goal
def choose_action(self, s, hc, vis_match, train=False):
if not train:
self.eval()
logits, values, hc, depth_pred = self.forward(s, hc, vis_match)
probs = torch.clamp(F.softmax(logits, dim=-1), 0.00001, 0.99999).data
m = self.distribution(probs)
action = m.sample().type(torch.IntTensor)
return action, (hc[0].data, hc[1].data), logits, values, depth_pred
def choose_action1(self, s, hc, vis_match):
self.eval()
logits, values, hc, _ = self.forward(s, hc, vis_match)
probs = torch.clamp(F.softmax(logits, dim=-1), 0.00001, 0.99999).data
return torch.argmax(probs, -1), (hc[0].data, hc[1].data), logits, values
def get_weights(self):
layers = [self.conv1, self.bnc1, self.conv2, self.bnc2, self.deconv1, self.debnc1, self.deconv2, self.lin_match, self.match_softmax, self.lin, self.lstm, self.p, self.v]
weigths = []
for layer in layers:
tot = 0
for p in layer.parameters():
tot += p.sum()
weigths.append(tot.item())
return weigths
5.3 Learner
class Learner(mp.Process):
def __init__(self, g_n, que_i, que_o, n, global_ep, gamma, lr, up_step, length, bs, entropy_cost, baseline_cost):
super(Learner, self).__init__()
self.daemon = True
self.gnet = g_n
self.queue_i = que_i
self.queue_o = que_o
self.n = n
self.global_ep = global_ep
self.gamma = gamma
self.lr = lr
self.up_step = up_step
self.length = length
self.bs = bs
self.entropy_cost, self.baseline_cost = entropy_cost, baseline_cost
def run(self):
count = 0
n = 0
if torch.cuda.is_available():
self.gnet.cuda()
params = self.gnet.parameters()
opt = torch.optim.SGD(params, lr=self.lr, momentum=0, weight_decay=0)
n_iterations = 3
torch.manual_seed(0)
torch.cuda.manual_seed(0)
np.random.seed(0)
random.seed(0)
torch.backends.cudnn.deterministic = True
while True:
n += self.bs
opt.zero_grad()
pl, vl, cl, dl, loss = 0, 0, 0, 0, 0
for i in range(n_iterations * self.bs):
rg = self.queue_i.get()
if rg is None:
count += 1
if count == self.n:
torch.save(self.gnet.state_dict(), 'path_to_model')
break
else:
if torch.cuda.is_available():
self.gnet.cuda()
s = rg[0].unsqueeze(1).cuda()
a = rg[1].unsqueeze(1).type(torch.IntTensor)
s_ = rg[2].unsqueeze(0).cuda()
d = torch.tensor(rg[3]).unsqueeze(1).type(torch.FloatTensor)
h = rg[4][0].cuda()
c = rg[4][0].cuda()
r = rg[5].type(torch.FloatTensor)
r = Learner.clip_rewards(r)
l = rg[6].unsqueeze(1)
depth = rg[7].cuda()
vis_match = rg[8].cuda()
vis_match_ = rg[9].cuda()
else:
s = rg[0].unsqueeze(1)
a = rg[1].unsqueeze(1).type(torch.IntTensor)
s_ = rg[2].unsqueeze(0)
d = torch.tensor(rg[3]).unsqueeze(1).type(torch.FloatTensor)
h = rg[4][0]
c = rg[4][0]
r = rg[5].type(torch.FloatTensor)
r = Learner.clip_rewards(r)
l = rg[6].unsqueeze(1)
depth = rg[7]
vis_match = rg[8]
vis_match_ = rg[9]
self.gnet.train()
logits, values, (h, c), d_pred = self.gnet(s, (h, c), vis_match)
logits = logits.view(-1, h.shape[1], logits.shape[-1])
hc = (h, c)
self.gnet.eval()
_, bootstrap_value, _, _ = self.gnet(s_, hc, vis_match_)
bootstrap_value = bootstrap_value.squeeze().cpu() * (1 - d[-1])
probs = torch.clamp(F.softmax(logits, dim=-1), 0.000001, 0.999999)
m = torch.distributions.Categorical(probs)
discounts = (1 - d) * self.gamma
vs, pg_advantages = Learner.v_trace(probs.cpu(), l, a, bootstrap_value, values.cpu(), r, discounts)
p_, v_, c_, l_ = self.get_loss(a, pg_advantages, m, vs, values, probs)
d_ = (d_pred - depth).pow(2).mean()
dl += d_
l_ += d_
pl += p_
vl += v_
cl += c_
loss += l_
lr = self.lr
l_.backward()
l_.detach_()
torch.nn.utils.clip_grad_norm_(self.gnet.parameters(), 400)
grad_norm = 0
for gp in self.gnet.parameters():
if gp.grad is not None:
grad_norm += gp.grad.pow(2).sum()
grad_norm = math.sqrt(grad_norm)
if grad_norm != grad_norm:
opt.zero_grad()
print('grad_norm nan')
opt.step()
loss = loss.cpu() / n_iterations
vl, pl, cl, dl = vl.cpu() / n_iterations, pl.cpu() / n_iterations, cl.cpu() / n_iterations, dl.cpu() / n_iterations
loss.detach_(), vl.detach_(), pl.detach_(), cl.detach_(), dl.detach_()
g = self.gnet.cpu()
while not self.queue_o.empty():
try:
self.queue_o.get(timeout=0.01)
except:
pass
for b in range(self.bs):
self.queue_o.put([g.state_dict(), loss, vl, pl, cl, dl, grad_norm, lr])
if n % (10000 * self.bs / self.up_step) == 0:
torch.save(self.gnet.state_dict(), 'path_to_model')
@staticmethod
def v_trace(probs, bl, ba, bootstrap_value, values, br, discounts):
m = torch.distributions.Categorical(probs)
clip_rho_threshold = 1
clip_pg_rho_threshold = 1
b_probs = torch.clamp(F.softmax(bl, dim=-1), 0.000001, 0.999999)
b_m = torch.distributions.Categorical(b_probs)
target_action_log_probs = m.log_prob(ba)
behaviour_action_log_probs = b_m.log_prob(ba)
log_rhos = target_action_log_probs - behaviour_action_log_probs
rhos = torch.exp(log_rhos)
clipped_rhos = torch.clamp(rhos, 0, clip_rho_threshold)
clipped_pg_rhos = torch.clamp(rhos, 0, clip_pg_rho_threshold)
values_t_plus_1 = torch.cat((values[1:], bootstrap_value.unsqueeze(0)))
deltas = clipped_rhos * (br + discounts * values_t_plus_1 - values)
acc = 0
dt = []
for i in reversed(range(len(deltas))):
acc = deltas[i] + discounts[i]*clipped_rhos[i]*acc
dt.append(acc)
vs_minus_v_xs = torch.stack(dt).flip(0)
vs = (vs_minus_v_xs + values)
vs_t_plus_1 = torch.cat((vs[1:], bootstrap_value.unsqueeze(0)))
pg_advantages = clipped_pg_rhos * (br + discounts * vs_t_plus_1 - values)
return vs.detach(), pg_advantages.detach()
def get_loss(self, ba, pg_advantages, m, vs, values, probs):
if torch.cuda.is_available():
pl = (-m.log_prob(ba.cuda()) * pg_advantages.cuda()).sum()
vl = 0.5 * (vs.cuda() - values).pow(2).sum()
else:
pl = (-m.log_prob(ba) * pg_advantages).sum()
vl = 0.5 * (vs - values).pow(2).sum()
cl = (probs * - torch.log(probs)).sum()
return pl, vl, cl, pl + self.baseline_cost * vl - self.entropy_cost * cl
@staticmethod
def clip_rewards(br):
squeezed = torch.tanh(br / 5.0)
squeezed = torch.where(br < 0, .3 * squeezed, squeezed) * 5.
return squeezed
5.4 Agent
class MyAgent(mp.Process):
def __init__(self, gnet, idx, global_ep, wins, total_rewards, res_queue, queue, g_que, gamma, up_step, bs, n_actions):
super(MyAgent, self).__init__()
self.daemon = True
self.idx = idx
self.global_ep, self.res_queue, self.queue, self.g_que, self.gamma, self.up_step, self.wins = global_ep, res_queue, queue, g_que, gamma, up_step, wins
self.loss, self.vl, self.pl, self.cl, self.dl, self.grad_norm = 0, 0, 0, 0, 0, 0
self.lnet = copy.deepcopy(gnet)
self.rewards, self.personal_reward = 0, 0
self.bs = bs
self.n_actions = n_actions
self.total_rewards = total_rewards
self.lr = 0
def step(self, reward, image, hc, vis_match):
with self.total_rewards.get_lock():
self.total_rewards.value += reward
with self.global_ep.get_lock():
self.global_ep.value += 1
action, hc, logits, _, _ = self.lnet.choose_action(image, hc, vis_match)
self.rewards += reward
self.personal_reward += reward
return action, hc, logits
def push_and_pull(self, bd, s_, bs, ba, br, hc, bl, b_depth, b_match, vis_match_):
self.queue.put([torch.cat(bs), torch.tensor(ba), s_, bd, hc, torch.tensor(br).unsqueeze(1), torch.stack(bl), torch.cat(b_depth), torch.stack(b_match), vis_match_])
g_dict, self.loss, self.vl, self.pl, self.cl, self.dl, self.grad_norm, self.lr = self.g_que.get()
self.lnet.load_state_dict(g_dict)
def run(self):
torch.manual_seed(self.idx)
torch.cuda.manual_seed(self.idx)
np.random.seed(self.idx)
random.seed(self.idx)
torch.backends.cudnn.deterministic = True
env = Environment(9734 + self.idx)
reward = 0
sample_count = 0
d = 0
buffer_a, buffer_r, buffer_l, buffer_d, buffer_obs, buffer_i, buffer_hc, buffer_depth, buffer_match = (), (), (), (), (), (), (), (), ()
(h, c) = init_hidden()
hc = (h, c)
n_step = 0
obs, depth, vis_match = env.reset() # RGB image, Depth image, visibility one-hot vector
for p in self.lnet.parameters():
p.requires_grad = False
while self.global_ep.value < 1000000000:
n_step += 1
sample_count += 1
action, hc, logits = self.step(reward, obs, hc, vis_match)
reward, obs_, depth_, vis_match_ = env.env_step(action) # reward, RGB image, Depth image, visibility one-hot vector
if n_step % 900 == 0:
d = True
obs_, depth_, vis_match_ = env.reset() # RGB image, Depth image, visibility one-hot vector
if len(buffer_obs) < 500:
buffer_obs += (obs,)
buffer_depth += (depth,)
buffer_a += (action,)
buffer_r += (reward,)
buffer_match += (vis_match,)
buffer_l += (logits,)
buffer_d += (d,)
buffer_hc += (hc,)
else:
buffer_obs = buffer_obs[1:] + (obs,)
buffer_depth = buffer_depth[1:] + (depth,)
buffer_match = buffer_match[1:] + (vis_match,)
buffer_a = buffer_a[1:] + (action,)
buffer_r = buffer_r[1:] + (reward,)
buffer_l = buffer_l[1:] + (logits,)
buffer_d = buffer_d[1:] + (d,)
buffer_hc = buffer_hc[1:] + (hc,)
if sample_count == self.up_step or d:
for _ in range(2):
if len(buffer_obs) == 100:
self.queue.put([torch.cat(buffer_obs), torch.tensor(buffer_a), obs_, buffer_d, buffer_hc[-100], torch.tensor(buffer_r).unsqueeze(1), torch.stack(buffer_l), torch.cat(buffer_depth), torch.stack(buffer_match), vis_match_])
else:
replay_index = torch.randint(101, len(buffer_obs), (1,))
self.queue.put([torch.cat(buffer_obs[-replay_index: -replay_index + 100]), torch.tensor(buffer_a[-replay_index: -replay_index + 100]), buffer_obs[-replay_index + 101], buffer_d[-replay_index: -replay_index + 100], buffer_hc[-replay_index], torch.tensor(buffer_r[-replay_index: -replay_index + 100]).unsqueeze(1), torch.stack(buffer_l[-replay_index: -replay_index + 100]), torch.cat(buffer_depth[-replay_index: -replay_index + 100]), torch.stack(buffer_match[-replay_index: -replay_index + 100]), buffer_match[-replay_index + 101]])
self.push_and_pull(buffer_d[-100:], obs_, buffer_obs[-100:], buffer_a[-100:], buffer_r[-100:], (h, c), buffer_l[-100:], buffer_depth[-100:], buffer_match[-100:], vis_match_)
sample_count = 0
if d:
print('Agent %i, step %i' % (self.idx, n_step))
self.res_queue.put([self.rewards, self.global_ep.value, self.loss / self.bs, self.vl / self.bs, self.pl / self.bs, self.cl / (self.bs * self.n_actions * self.up_step), self.dl / self.bs, self.grad_norm, self.lnet, self.total_rewards.value, self.wins.value, self.lr, self.personal_reward, self.idx])
self.rewards, self.personal_reward = 0, 0
hc = init_hidden()
d = 0
(h, c) = hc
obs = obs_
vis_match = vis_match_
depth = depth_
self.res_queue.put(None)
self.queue.put(None)
time.sleep(1)
env.close_connection()
print('Agent %i finished after %i steps.' % (self.idx, n_step))
到了这里,关于基于深度强化学习的目标驱动型视觉导航泛化模型的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!