前言
KNN (K-Nearest Neighbor)算法是一种最简单,也是一个很实用的机器学习的算法,在《机器学习实战》这本书中属于第一个介绍的算法。它属于基于实例的有监督学习算法,本身不需要进行训练,不会得到一个概括数据特征的模型,只需要选择合适的参数 K 就可以进行应用。KNN的目标是在训练数据中发现最佳的 K 个近邻,并根据这些近邻的标签来预测新数据的标签。每次使用 KNN 进行预测时,所有的训练数据都会参与计算。
kNN有很多应用场景:
- 分类问题,同时天然可以处理多分类问题,比如根据音乐的特征,将其归类到不同的类型。
- 推荐系统,根据用户的历史行为,推荐相似的物品或服务
- 图像识别,比如人脸识别、车牌识别等
一、概念
1.1 机器学习基本概念
机器学习是人工智能领域中非常重要的一个分支,它可以帮助我们从大量数据中发现规律并做出预测。
机器学习可以分为监督学习、无监督学习和半监督学习三种类型。
- 监督学习是指在训练数据中已经标注了正确答案,通过这些数据来训练模型,然后对新数据进行预测。
- 无监督学习是指在训练数据中没有标注正确答案,通过对数据的聚类、降维等操作来发现数据中的规律。
- 半监督学习则是介于有监督学习和无监督学习之间的一种方法。
下表是对机器学习一些基本概念解释
| 概念 | 解释 | 备注 |
|---|---|---|
| 分类 | 将数据集分为不同的类别 | 属于监督学习 |
| 聚类 | 将数据集分为由类似的对象组成多个类的过程 | 属于无监督学习 |
| 回归 | 指预测连续型数值数据 | 属于监督学习 |
| 样本集 | 一般指用于训练模型的数据集,一般分为训练集和测试集。 | 在样本集中,每个样本都包含一个或多个特征和一个标签。 |
| 特征 | 用于描述样本的属性或特点 | 通常是训练样本集的列,他们是独立测量的结果,多个特征联系在一起共同组成一个训练样本 |
| 标签 | 样本所属的类别或结果 | |
| 模型 | 从训练数据中学习到的规律或模式。 | 在机器学习中,模型可以用于预测新数据的标签或值 |
| 梯度 | 指函数在某一点处的变化率。 | 在机器学习中,梯度可以用于以最小化损失函数优化模型参数 |
1.2 k 值
k值是指在多个邻居中,选择前k个最相似邻居的类别来决定当前样本的类别,通常 k 是不大于20的整数,常选择3或5
1.3 距离度量
距离度量是指在 kNN 算法中用来计算样本之间距离的方法。常用的距离度量有欧氏距离、曼哈顿距离、切比雪夫距离、闵可夫斯基距离等。
-
欧式距离
-
二维平面
d = ( x 1 − x 2 ) 2 + ( y 1 − y 2 ) 2 d = \sqrt{(x_1 - x_2)^2 + (y_1 - y_2)^2} d=(x1−x2)2+(y1−y2)2
-
n维
d = ∑ i = 1 n ∣ x i − y i ∣ 2 d=\sqrt{\sum_{i=1}^{n}{\left| x_{i}-y_{i} \right|^{2}}} d=∑i=1n∣xi−yi∣2
-
-
曼哈顿距离
d = ∑ i = 1 n ∣ x i − y i ∣ d= \sum_{i=1}^{n}|x_i - y_i| d=∑i=1n∣xi−yi∣
-
切比雪夫距离
d = m a x ( ∣ x 1 − x 2 ∣ , ∣ y 1 − y 2 ∣ , ⋯ , ∣ x i − y i ∣ ) d= max(|x_1 - x_2|, |y_1 - y_2|, \cdots, |x_i - y_i|) d=max(∣x1−x2∣,∣y1−y2∣,⋯,∣xi−yi∣)
-
闵可夫斯基距离
d = ∑ i = 1 n ( ∣ x i − y i ∣ ) p p d = \sqrt[p]{\sum_{i=1}^{n}(|x_i - y_i|)^p} d=p∑i=1n(∣xi−yi∣)p
1.4 加权方式
KNN 算法中的加权方式指的是在计算距离时,对不同距离的样本使用不同的权重。这些权重可以是距离样本数据源的距离,也可以是不同样本之间的距离。加权的方式可以根据实际情况进行选择,以达到更好的分类或预测效果。
常用的数值数据加权方式如下:
- 加权平均值:将K个邻居的属性值加权平均后作为新数据点的预测值。
- 均值法:将K个邻居的属性值取平均值后作为新数据点的预测值。
- 最差值:将K个邻居的属性值取最小值和最大值,再取平均值作为新数据点的预测值。
常见的离散型数据加权方式如下:
- 反函数
- 高斯函数
- 多项式函数
不同的加权方式可以根据实际情况选择,以达到更好的分类或预测效果。
二、实现
手写数字数据集 为 《机器学习实战》第二章 提供的数据集:https://github.com/pbharrin/machinelearninginaction
2.1 手写实现
import numpy as np
from collections import Counter
import operator
import math
from os import listdir
# inX 输入向量
# dataSet 训练集
# labels 训练集所代表的标签
# k 最近邻居数目
# output: label
def classify0(inX, dataSet, labels, k):
sortedDistIndicies=euclideanDistance(inX, dataSet)
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1.0 * weight(sortedDistIndicies[i])
sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse = True)
return sortedClassCount[0][0]
def euclideanDistance(inX, dataSet):
dataSetSize = dataSet.shape[0]
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet
sqDiffMat = diffMat ** 2
sqDistances = sqDiffMat.sum(axis = 1)
distances = sqDistances ** 0.5
sortedDistIndicies = distances.argsort()
return sortedDistIndicies
def weight(dist):
return 1
def classify1(test, train, trainLabel, k):
distances = []
for i in range(len(train)):
distance = np.sqrt(np.sum(np.square(test - train[i, :])))
distances.append([distance, i])
distances = sorted(distances)
targets = [trainLabel[distances[i][1]] for i in range(k)]
return Counter(targets).most_common(1)[0][0]
def img2vector(filename):
returnVect = np.zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
def handWritingDataSet(inputDir):
hwLabels = []
fileNames = []
dataFileList = listdir(inputDir)
m = len(dataFileList)
dataMat = np.zeros((m,1024))
for i in range(m):
fileNameStr = dataFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
fileNames.append(fileStr)
dataMat[i,:] = img2vector( inputDir + '/%s' % fileNameStr)
return dataMat,hwLabels,fileNames
trainMat, trainLabels, _ = handWritingDataSet('digits/trainingDigits/')
testMat, testLabels,testFileNames = handWritingDataSet('digits/testDigits/')
errorCount = 0
k = 3
for idx, testData in enumerate(testMat):
prefictLabel = classify0(testData, trainMat, trainLabels, k)
# prefictLabel = classify1(testData, trainMat, trainLabels, k)
if testLabels[idx] != prefictLabel:
errorCount+=1
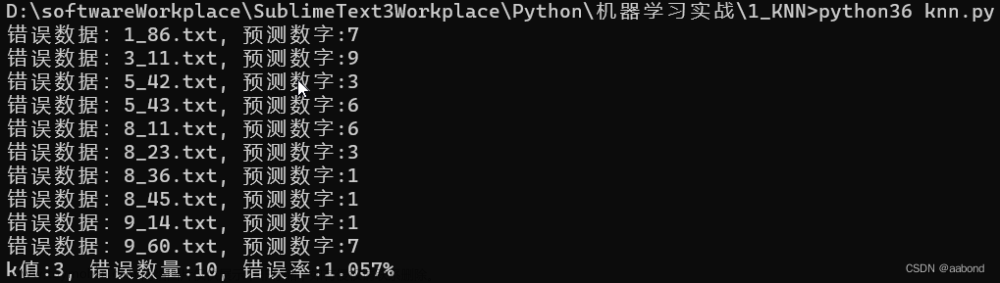
print("错误数据:%s.txt, 预测数字:%d" % (testFileNames[idx], prefictLabel))
print("k值:%d, 错误数量:%d, 错误率:%.3f%%" %(k, errorCount, errorCount / 1.0 / np.size(testMat, 0) * 100))

2.2 调库 Scikit-learn
文档地址:https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html#sklearn.neighbors.KNeighborsClassifier
from sklearn.neighbors import KNeighborsClassifier
trainMat, trainLabels, _ = handWritingDataSet('digits/trainingDigits/')
testMat, testLabels,testFileNames = handWritingDataSet('digits/testDigits/')
errorCount = 0
k = 3
neigh = KNeighborsClassifier(n_neighbors=k)
neigh.fit(trainMat, trainLabels)
for idx, testData in enumerate(testMat):
prefictLabel = neigh.predict([testData])
if testLabels[idx] != prefictLabel:
errorCount+=1
print("错误数据:%s.txt, 预测数字:%d" % (testFileNames[idx], prefictLabel))
print("k值:%d, 错误数量:%d, 错误率:%.3f%%" %(k, errorCount, errorCount / 1.0 / np.size(testMat, 0) * 100))

2.3 测试自己的数据
上面的手写数据集,训练集有1934个,测试集有946个,都是32x32的图片转的文本。如果想测试自己的手写数字,那就需要将手写数字图片先转成32x32像素格式的图片,然后再转成文本,下面是一个图片转文本代码
import cv2
import os
def img2txt(inputDir):
dataFileList = os.listdir(inputDir)
for file in dataFileList:
if not file.endswith('png'):
continue
img = cv2.imread(inputDir + file, cv2.IMREAD_GRAYSCALE)
fr = open(inputDir + file.split('.')[0] + '.txt', 'w')
height, width = img.shape[0:2]
for row in range(height):
line = ''
for col in range(width):
if img[row, col] > 250:
line+='0'
else:
line+='1'
fr.write(line)
fr.write('\n')
fr.close()
if __name__ == '__main__':
img2txt('img/')
下面准备自己手写的0-9 十个数字进行测试,下面数字是用windows画图工具,先裁剪为32x32像素,再用鼠标手写实现。

将10个数字转成文本进行测试,结果错误率在30%文章来源:https://www.toymoban.com/news/detail-457234.html
 文章来源地址https://www.toymoban.com/news/detail-457234.html
文章来源地址https://www.toymoban.com/news/detail-457234.html
三、总结
3.1 分析
- 识别测试集手写数字时,总是有一些样本不能正确识别,通过观察发现是因为与其他类别特征比较接近
- 使用自身手写数字识别,识别错误的样本并不是因为相类似,例如4被识别为7,这个不太明白,可能与样本特征有关
3.2 KNN 优缺点
- 优点
- 思想简单,理论成熟,既可以用来做分类也可以用来做回归
- 由于选择距离最近的 k 个,对异常值不敏感
- 缺点
- KNN 需要计算每个测试样本与所有训练样本之间的距离,时间复杂度很高,计算成本也很高
- 无法给出数据任何的基础结构信息
- 算法比较简单,当训练数据较小时,对于一些很相似的不同类数据很难区分
参考
- https://github.com/pbharrin/machinelearninginaction
到了这里,关于机器学习小结之KNN算法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!