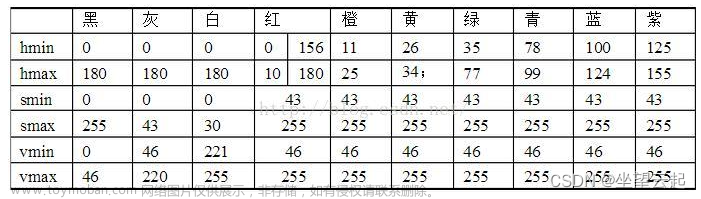
背景
AI制作视频的几种思路
1.从零开始生成:清华的cogview,runway gen-1、gen-2,微软的女娲
这个思路,就是认为可以通过文字描述的方式把视频画面描述出来,通过对文本-视频帧内容-视频内容的数据对的平行语料的学习。学习到文本故事到视频帧到视频生成的转译关系,只要数据足够或者学习的任务设计的够好,机器就能学会文本故事到视频的知识表征关系,就能文本直接生成视频。
但是这个难度其实挺大的,文本是一个线性非连续的数据空间,在描述过程中你会发现文本本身有很多隐藏空间,是需要根据不同受众的知识空间来anchor住这个词的输入向量空间;画面帧的描述其实是一个更具象的数据更丰富的映射空间,然而如何把输入的文本anchor到用户解空间,然后在从用户解空间映射到画面空间是个复杂量很大的事;从画面帧组合成一些列连续无违和感的动态画面,就有需要很多常识性和物理性+用户认知性的空间映射,这又是一个复杂度很高并且很多隐空间的问题。
如果要暴力求解这个问题需要的数据语料对是巨量的,如果把这个问题转成一个退化的矩阵来求解,那么对学习任务的设计要求就很高。这也是为什么现在各大厂都在卷这块,但是并没出现一个通用的稳健的方案。
2.基于已有的驱动视频生成:基于controlnet的mov2mov,multi-frame mov2mov
这种思路其实就是通过改的方式增加信息多样性,只要的改的足够多那其实也是一种生成和创作。前面介绍了从零开始生成视频的难度,既然这么复杂这么难,哪有没可能我就直接拿现成已经有的视频或者生活中容易得到的视频作为一个故事底稿或者说是视频的底稿。然后基于这个底稿我适当的对这个底稿作增删改,这样就可以比较好的解决掉上面讲的各种向量空间映射复杂度太高的问题
这种解法其实优点像计算共形中,构造同构函数或者构造胚模型,可以减少问题复杂度,相当于是对复杂问题的畸变在特定条件下降低复杂度来得到可行解。
这种解法现在最大的问题在于如何稳定住连续的单张图之间的连贯性,也就是怎么样前一帧生成的图和后一帧生成的图是稳定的。不稳定的问题原因在于:我们现在用controlnet方式来求解每一张图的生成效果,这个问题其实本身并没有对对连续帧之间做关联约束(或者说约束只在于输入视频本身是连续),在求解过程中生成图肯定就无法稳定连续。现在的解法是通过multi-frame方式共同约束来求解,但效果并不一定好。原因大家可以自己思考下为什么。
3.3d建模+stable difussion内容生成:stable ai 的animate生成,3d到2d动漫生成,动态漫
这个思路是,假设运动和视频跳转是不会出现突变的。那么我们只要能够建立出摄像机的空间坐标,以及可以定位到到没帧图角色物体的场景坐标,我们就可以通过预测出角色下一帧出现的位置和动作。那我们只要在合适的位置把合适的角色给画出来,这样视频生成问题就变成:
a.计算摄像机的坐标位置,相对角色和场景的位置,两个坐标的转化矩阵
b.根据前几帧预测下一帧任务动作、位置(可以转成pose和动作预测、追踪问题)
c.根据前面求解出的信息作为约束条件+文本描述+角色稳定+背景稳定,生成下帧画面
这种思路的问题在于:
a.是否所有动作都是连续不突变的
b.连续帧之间角色、背景画面如何保持稳定
ipaint的几种思路
inpaint其实很像缝补衣服,衣服破了一个洞,要怎么样补才能看起来不违和;看看勤劳的妇女同学的做法。搞一块足够大的布垫上把窟窿给补上;根据窟窿周围布材质颜色,对窟窿部分织布缝合;再厉害点的脑海想想这个窟窿部分可以有个什么花纹好看,刺绣出花纹把窟窿变成艺术,或者糅合前面几种方法把窟窿变成艺术创作。
1.用背景把图给补上,垫一张背景图把窟窿补上

2.利用mask周围信息作分布预测把图补上:三星LAMA、inpaint anything就是这种思路

3.基于生成方式,prompt把图补上:stablediffusion inpaint、controlnet inpaint

4.组合几种方法,用1方法比较粗暴,和图片融合行不太好,2方法对于大面积mask基本就是把物体移除、用图片均值方法补可控性一般画质也不太好,用3方法生成多多样性,但可能会背景融合性不太好;有没可能集合这几种方法组合出一种更平衡的办法。其实是可以的,比如先用背景+图方式做一张底图,然后再用controlnet inpaint方法+prompt指导生成,出来的图既能保持画面一体,也能比较好的保持前后帧画风一致。

代码实践
前面部分已经介绍了一些宏观层面的背景知识,这部分我们主要是介绍如何来做一个视频生成。我们选择的是mov2mov,但是这部分不是简单的controlnet mov2mov或者简单的multi-frame的mov2mov。而是会把各种技术点融合进来,让生成的视频画面更稳定,生成的视频和原视频有更大差异更多的创造性。
视频拆帧代码
import cv2
import os
import argparse
def video2imgs(videoPath, imgPath):
if not os.path.exists(imgPath):
os.makedirs(imgPath) # 目标文件夹不存在,则创建
cap = cv2.VideoCapture(videoPath) # 获取视频
judge = cap.isOpened() # 判断是否能打开成功
print(judge)
fps = cap.get(cv2.CAP_PROP_FPS) # 帧率,视频每秒展示多少张图片
print('fps:',fps)
frames = 1 # 用于统计所有帧数
count = 1 # 用于统计保存的图片数量
while(judge):
flag, frame = cap.read() # 读取每一张图片 flag表示是否读取成功,frame是图片
if not flag:
print(flag)
print("Process finished!")
break
else:
if frames % 10 == 0: # 每隔10帧抽一张
imgname = 'jpgs_' + str(count).rjust(3,'0') + ".jpg"
newPath = imgPath + imgname
print(imgname)
cv2.imwrite(newPath, frame, [cv2.IMWRITE_JPEG_QUALITY, 100])
# cv2.imencode('.jpg', frame)[1].tofile(newPath)
count += 1
frames += 1
cap.release()
print("共有 %d 张图片"%(count-1))
if __name__ == "__main__":
parser = argparse.ArgumentParser("Vedio-to-Images Demo", add_help=True)
parser.add_argument("--vedio_path", type=str, required=True, help="path to vedio file")
parser.add_argument(
"--image_path", type=str, required=True, help="path to image file"
)
args = parser.parse_args()
video2imgs(args.vedio_path,args.image_path)
#python vedio_to_images.py --vedio_path '/root/autodl-tmp/Grounded-Segment-Anything/normalvedio.mp4' --image_path './vedio_to_images/'视频转风格
这部分可以直接用sd webui的batch插件来实现,也可用sd webui 的api接口调用来实现,也可以你自己写一段代码实现。难度不大,不详细介绍(如果大家这部分有比较多问题,可以根据大家需要后面整理这部分代码)

视频扣除变化比较大部分
这部分用的是meta开源的sam模型,我用的是IDEA团队对这个项目的集成代码:GitHub - IDEA-Research/Grounded-Segment-Anything: Marrying Grounding DINO with Segment Anything & Stable Diffusion & Tag2Text & BLIP & Whisper & ChatBot - Automatically Detect , Segment and Generate Anything with Image, Text, and Audio Inputs,其实用sd web UI的插件也可以实现一样功能。
我观察发现经过视频转化生成后,天空部分有比较多凌乱画面所以我把天空、字、人脸扣掉了。

import argparse
import os
import copy
import numpy as np
import json
import torch
from PIL import Image, ImageDraw, ImageFont
# Grounding DINO
import GroundingDINO.groundingdino.datasets.transforms as T
from GroundingDINO.groundingdino.models import build_model
from GroundingDINO.groundingdino.util import box_ops
from GroundingDINO.groundingdino.util.slconfig import SLConfig
from GroundingDINO.groundingdino.util.utils import clean_state_dict, get_phrases_from_posmap
# segment anything
from segment_anything import build_sam, SamPredictor
import cv2
import numpy as np
import matplotlib.pyplot as plt
def load_image(image_path):
# load image
image_pil = Image.open(image_path).convert("RGB") # load image
transform = T.Compose(
[
T.RandomResize([800], max_size=1333),
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
]
)
image, _ = transform(image_pil, None) # 3, h, w
return image_pil, image
def load_model(model_config_path, model_checkpoint_path, device):
args = SLConfig.fromfile(model_config_path)
args.device = device
model = build_model(args)
checkpoint = torch.load(model_checkpoint_path, map_location="cpu")
load_res = model.load_state_dict(clean_state_dict(checkpoint["model"]), strict=False)
print(load_res)
_ = model.eval()
return model
def get_grounding_output(model, image, caption, box_threshold, text_threshold, with_logits=True, device="cpu"):
caption = caption.lower()
caption = caption.strip()
if not caption.endswith("."):
caption = caption + "."
model = model.to(device)
image = image.to(device)
with torch.no_grad():
outputs = model(image[None], captions=[caption])
logits = outputs["pred_logits"].cpu().sigmoid()[0] # (nq, 256)
boxes = outputs["pred_boxes"].cpu()[0] # (nq, 4)
logits.shape[0]
# filter output
logits_filt = logits.clone()
boxes_filt = boxes.clone()
filt_mask = logits_filt.max(dim=1)[0] > box_threshold
logits_filt = logits_filt[filt_mask] # num_filt, 256
boxes_filt = boxes_filt[filt_mask] # num_filt, 4
logits_filt.shape[0]
# get phrase
tokenlizer = model.tokenizer
tokenized = tokenlizer(caption)
# build pred
pred_phrases = []
for logit, box in zip(logits_filt, boxes_filt):
pred_phrase = get_phrases_from_posmap(logit > text_threshold, tokenized, tokenlizer)
if with_logits:
pred_phrases.append(pred_phrase + f"({str(logit.max().item())[:4]})")
else:
pred_phrases.append(pred_phrase)
return boxes_filt, pred_phrases
def show_mask(mask, ax, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30/255, 144/255, 255/255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
def show_box(box, ax, label):
x0, y0 = box[0], box[1]
w, h = box[2] - box[0], box[3] - box[1]
ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor='green', facecolor=(0,0,0,0), lw=2))
ax.text(x0, y0, label)
def save_mask_data(output_dir, mask_list, box_list, label_list,image_dir):
value = 0 # 0 for background
mask_img = torch.zeros(mask_list.shape[-2:])
for idx, mask in enumerate(mask_list):
mask_img[mask.cpu().numpy()[0] == True] = value + idx + 1
plt.figure(figsize=(10, 10))
plt.imshow(mask_img.numpy())
plt.axis('off')
plt.savefig(os.path.join(output_dir, f'{image_dir }_mask.jpg'), bbox_inches="tight", dpi=300, pad_inches=0.0)
json_data = [{
'value': value,
'label': 'background'
}]
for label, box in zip(label_list, box_list):
value += 1
name, logit = label.split('(')
logit = logit[:-1] # the last is ')'
json_data.append({
'value': value,
'label': name,
'logit': float(logit),
'box': box.numpy().tolist(),
})
with open(os.path.join(output_dir, f'{image_dir}_mask.json'), 'w') as f:
json.dump(json_data, f)
if __name__ == "__main__":
parser = argparse.ArgumentParser("Grounded-Segment-Anything Demo", add_help=True)
parser.add_argument("--config", type=str, required=True, help="path to config file")
parser.add_argument(
"--grounded_checkpoint", type=str, required=True, help="path to checkpoint file"
)
parser.add_argument(
"--sam_checkpoint", type=str, required=True, help="path to checkpoint file"
)
parser.add_argument("--input_image", type=str, required=True, help="path to image file")
parser.add_argument("--text_prompt", type=str, required=True, help="text prompt")
parser.add_argument(
"--output_dir", "-o", type=str, default="outputs", required=True, help="output directory"
)
parser.add_argument("--box_threshold", type=float, default=0.3, help="box threshold")
parser.add_argument("--text_threshold", type=float, default=0.25, help="text threshold")
parser.add_argument("--device", type=str, default="cpu", help="running on cpu only!, default=False")
args = parser.parse_args()
# cfg
config_file = args.config # change the path of the model config file
grounded_checkpoint = args.grounded_checkpoint # change the path of the model
sam_checkpoint = args.sam_checkpoint
image_path = args.input_image
text_prompt = args.text_prompt
output_dir = args.output_dir
box_threshold = args.box_threshold
text_threshold = args.text_threshold
device = args.device
image_dir = image_path.split('/')[2].split('.')[0]
# make dir
os.makedirs(output_dir, exist_ok=True)
# load image
image_pil, image = load_image(image_path)
# load model
model = load_model(config_file, grounded_checkpoint, device=device)
# visualize raw image
image_pil.save(os.path.join(output_dir, f"{image_dir}_raw_image.jpg"))
# run grounding dino model
boxes_filt, pred_phrases = get_grounding_output(
model, image, text_prompt, box_threshold, text_threshold, device=device
)
# initialize SAM
predictor = SamPredictor(build_sam(checkpoint=sam_checkpoint).to(device))
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
predictor.set_image(image)
size = image_pil.size
H, W = size[1], size[0]
for i in range(boxes_filt.size(0)):
boxes_filt[i] = boxes_filt[i] * torch.Tensor([W, H, W, H])
boxes_filt[i][:2] -= boxes_filt[i][2:] / 2
boxes_filt[i][2:] += boxes_filt[i][:2]
boxes_filt = boxes_filt.cpu()
transformed_boxes = predictor.transform.apply_boxes_torch(boxes_filt, image.shape[:2]).to(device)
masks, _, _ = predictor.predict_torch(
point_coords = None,
point_labels = None,
boxes = transformed_boxes.to(device),
multimask_output = False,
)
# draw output image
plt.figure(figsize=(10, 10))
plt.imshow(image)
for mask in masks:
show_mask(mask.cpu().numpy(), plt.gca(), random_color=True)
for box, label in zip(boxes_filt, pred_phrases):
show_box(box.numpy(), plt.gca(), label)
plt.axis('off')
plt.savefig(
os.path.join(output_dir, f"{image_dir}_grounded_sam_output.jpg"),
bbox_inches="tight", dpi=300, pad_inches=0.0
)
save_mask_data(output_dir, masks, boxes_filt, pred_phrases,image_dir )
'''
#图片批量处理bash脚本
function getdir(){
#echo $1
for file in $1/*
do
if test -f $file
then
echo $file
export CUDA_VISIBLE_DEVICES=0
python grounded_sam_demo.py \
--config GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py \
--grounded_checkpoint groundingdino_swint_ogc.pth \
--sam_checkpoint sam_vit_h_4b8939.pth \
--input_image $file \
--output_dir "outputs" \
--box_threshold 0.35 \
--text_threshold 0.25 \
--text_prompt "sky.face.words.dark sky.bird" \
--device "cuda"
arr=(${arr[*]} $file)
else
getdir $file
fi
done
}
getdir ./vedio_to_images
'''视频inpaint
垫背景图代码
import os
# 获取图片路径下面的所有图片名称
image_path ='/root/autodl-tmp/stable-diffusion-webui/vedio3/'
image_names = os.listdir(image_path)
# 对提取到的图片名称进行排序
image_names.sort(key=lambda x: int(x.split('_')[0][5:]))
# 遍历图片,将每张图片垫背景图
for image_name in image_names:
fg_path = os.path.join(image_path, image_name)
ma_path = '/root/autodl-tmp/stable-diffusion-webui/vedio_mask/frame'+ image_name.split('_')[0][5:] +'_0_mask.png'#前景图片的mask
bg_path = '/root/autodl-tmp/stable-diffusion-webui/sky_blue.png'#背景图片
fg = Image.open(fg_path).convert('RGB')
ma = Image.open(ma_path).convert("L")
bg = Image.open(bg_path).convert('RGBA')
empty = Image.new("RGBA", (fg.size), 0)
target = Image.composite(fg, empty, ma.resize(fg.size, Image.LANCZOS))
# target.show()
ma = ma.resize(bg.size, Image.ANTIALIAS)
target = target.resize(bg.size, Image.ANTIALIAS)
synth = Image.composite(target, bg, ma)
#synth.show()
#synth = cv2.cvtColor(np.asarray(synth), cv2.COLOR_RGB2BGR)
synth.save('/root/autodl-tmp/stable-diffusion-webui/vedio4/frame'+image_name.split('_')[0][5:] +'_0_output.png')
垫完背景图用control net方法生成,保持图一致性,这部分你用sd web ui插件也可以实现
import torch
import os
from diffusers.utils import load_image
from PIL import Image
import numpy as np
from diffusers import (
ControlNetModel,
StableDiffusionControlNetPipeline,
UniPCMultistepScheduler,
)
checkpoint = "lllyasviel/control_v11p_sd15_inpaint"
'''
original_image = load_image(
"/root/autodl-tmp/Grounded-Segment-Anything/outputs/raw_image.jpg"
)
mask_image = load_image(
"/root/autodl-tmp/Grounded-Segment-Anything/outputs/raw_image.jpg"
)
'''
from PIL import Image
import numpy as np
import argparse
def make_inpaint_condition(image, image_mask):
image = np.array(image.convert("RGB")).astype(np.float32) / 255.0
image_mask = np.array(image_mask.convert("L"))
assert image.shape[0:1] == image_mask.shape[0:1], "image and image_mask must have the same image size"
image[image_mask < 128] = -1.0 # set as masked pixel
image = np.expand_dims(image, 0).transpose(0, 3, 1, 2)
image = torch.from_numpy(image)
return image
if __name__ == "__main__":
# Construct the argument parser and parse the arguments
arg_desc = '''\
Let's load an image from the command line!
--------------------------------
This program loads an image
with OpenCV and Python argparse!
'''
parser = argparse.ArgumentParser(formatter_class = argparse.RawDescriptionHelpFormatter,
description= arg_desc)
parser.add_argument("-i", "--original_image", metavar="IMAGE", help = "Path to your input image")
parser.add_argument("-m", "--mask_image", metavar="IMAGE_MASK", help = "Path to your mask image")
parser.add_argument("-p", "--prompt", metavar="PROMPT", help = "inpaint prompt")
parser.add_argument("-o", "--out_path", metavar="OUT_PATH", help = "output path")
args = vars(parser.parse_args())
original_image = Image.open(args['original_image']) #"/root/autodl-tmp/Grounded-Segment-Anything/frame2.jpg")#读取数据
original_image = original_image.resize((768, 512))
mask_image = Image.open(args['mask_image']).resize((768, 512)) #"/root/autodl-tmp/Grounded-Segment-Anything/frame2_0_mask.png").resize((768, 512))#读取数据
control_image = make_inpaint_condition(original_image, mask_image) #nothing,clean sky,naive style
prompt = args['prompt'] #"sky"
negative_prompt="lowres, bad anatomy, bad hands, cropped, worst quality"
controlnet = ControlNetModel.from_pretrained("/root/autodl-tmp/Grounded-Segment-Anything/llm_model/control_v11p_sd15_inpaint", torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained("/root/autodl-tmp/Grounded-Segment-Anything/llm_model/models--andite--anything-v4.0/snapshots/1f509626c469baf6fd3ab37939158b4944f90005", controlnet=controlnet, torch_dtype=torch.float16)
#pipe = StableDiffusionControlNetPipeline.from_pretrained( "andite/anything-v4.0", controlnet=controlnet, torch_dtype=torch.float16,cache_dir='./llm_model')
#pipe = StableDiffusionControlNetPipeline.from_pretrained( "/root/autodl-tmp/Grounded-Segment-Anything/llm_model/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16) andite/anything-v4.0
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
generator = torch.manual_seed(28909)
image = pipe(prompt, negative_prompt=negative_prompt, num_inference_steps=30,
generator=generator, image=control_image).images[0]
image.resize((768,512))
image.save(args['out_path'])#'images/output.png')
#python inpaint.py -i "/root/autodl-tmp/Grounded-Segment-Anything/frame2.jpg" -m "/root/autodl-tmp/Grounded-Segment-Anything/frame2_0_mask.png" -p "sky" -o "images/output.png"
'''
#图片批量生controlnet生成的shell脚本
for ((i=1; i<=792; i++))
do
echo $i
a=`printf '%03d\n' $i`
python inpaint.py \
-i "/root/autodl-tmp/Grounded-Segment-Anything/vedio/frame"$i".jpg" \
-m "/root/autodl-tmp/Grounded-Segment-Anything/vedio_mask/frame"$i"_0_mask.png"\
-p "sky" \
-o "images/"$a"_output.png"
done
'''images合成视频
import os
import cv2
from PIL import Image
def image_to_video(image_path, media_path):
'''
图片合成视频函数
:param image_path: 图片路径
:param media_path: 合成视频保存路径
:return:
'''
# 获取图片路径下面的所有图片名称
image_names = os.listdir(image_path)
# 对提取到的图片名称进行排序
# image_names.sort(key=lambda x: int(x.split('_')[0][5:]))
image_names.sort(key=lambda x: int(x.split('-')[0]))
# 设置写入格式
fourcc = cv2.VideoWriter_fourcc('M', 'P', '4', 'V')
# 设置每秒帧数
fps = 30 # 由于图片数目较少,这里设置的帧数比较低
# 读取第一个图片获取大小尺寸,因为需要转换成视频的图片大小尺寸是一样的
image = Image.open(image_path + image_names[0])
# 初始化媒体写入对象
media_writer = cv2.VideoWriter(media_path, fourcc, fps, image.size)
# 遍历图片,将每张图片加入视频当中
for image_name in image_names:
im = cv2.imread(os.path.join(image_path, image_name))
media_writer.write(im)
print(image_name, '合并完成!')
# 释放媒体写入对象
media_writer.release()
print('无声视频写入完成!')
#save_file_list.sort(key=lambda x: int(x.split('_')[0][5:]))
# 图片路径
#image_path = "/root/autodl-tmp/stable-diffusion-webui/vedio4/"
image_path = "/root/autodl-tmp/stable-diffusion-webui/outputs/txt2img-images/2023-05-16/"
# 视频保存路径+名称
media_path = "/root/autodl-tmp/stable-diffusion-webui/original_video3.mp4"
# 调用函数,生成视频
image_to_video(image_path, media_path)小结
1.介绍了文本生成图片的3种思路
2.介绍了inpaint的4种思路
3.用一个实际例子带大家实现了mov2mov的例子,整合了inpaint的各种技巧
附录:
#图片改名字复制脚本
import os
from shutil import copy
path = '/root/autodl-tmp/stable-diffusion-webui/vedio1'
path_list = os.listdir(path)
save_file_list =[]
for file_name in path_list:
if '0_output.png' in file_name:
save_file_list.append(file_name)
pathDir = '/root/autodl-tmp/stable-diffusion-webui/vedio3'
# 文件名 按数字排序
save_file_list.sort(key=lambda x: int(x.split('_')[0][5:]))
for filename in save_file_list: #遍历pathDir下的所有文件filename
print(filename)
from_path = os.path.join(path, filename) #旧文件的绝对路径(包含文件的后缀名)
to_path = pathDir #+ "/" + filename #新文件的绝对路径
if not os.path.isdir(to_path):# 如果 to_path 目录不存在,则创建
os.makedirs(to_path)
copy(from_path, to_path)#完成复制黏贴
#
import os
path= '/root/autodl-tmp/stable-diffusion-webui/vedio5'
#获取该目录下所有文件,存入列表中
fileList=os.listdir(path)
for i in fileList:
#设置旧文件名(就是路径+文件名)
oldname=path+ os.sep + i # os.sep添加系统分隔符
#设置新文件名
file = '%03d' % int(i.split('_')[0][5:])
newname=path + os.sep +file+'_out.png'
os.rename(oldname,newname) #用os模块中的rename方法对文件改名
print(oldname,'======>',newname)
n+=1
文章来源地址https://www.toymoban.com/news/detail-457309.html
文章来源:https://www.toymoban.com/news/detail-457309.html
到了这里,关于AI制作视频——mov2mov以及inpaint的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!