从基础步骤下手
# 指定url
# 发出请求,get或post
# 获取响应
# 把目标文件转存为字符串形式
# 持久性保存
正确获取response数据
import requests
header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.50'}
userInput = input("请输入检索内容:")
# 指定url
url='https://fanyi.**.com/sug'
# 发出请求,get或post
data={'kw':userInput}
# 获取响应
response = requests.post(url=url,data=data,headers=header)
print(response.text)
关于url获取方式

url,请求方式,请求格式,都在此请求的header中
(此内容浏览器不同显示内容应该也是一样的,我用的edge浏览器,我也试过chrom浏览器,效果一样)

关于post方法的参数
ctrl + b进入方法体内即可
关于payload参数填入

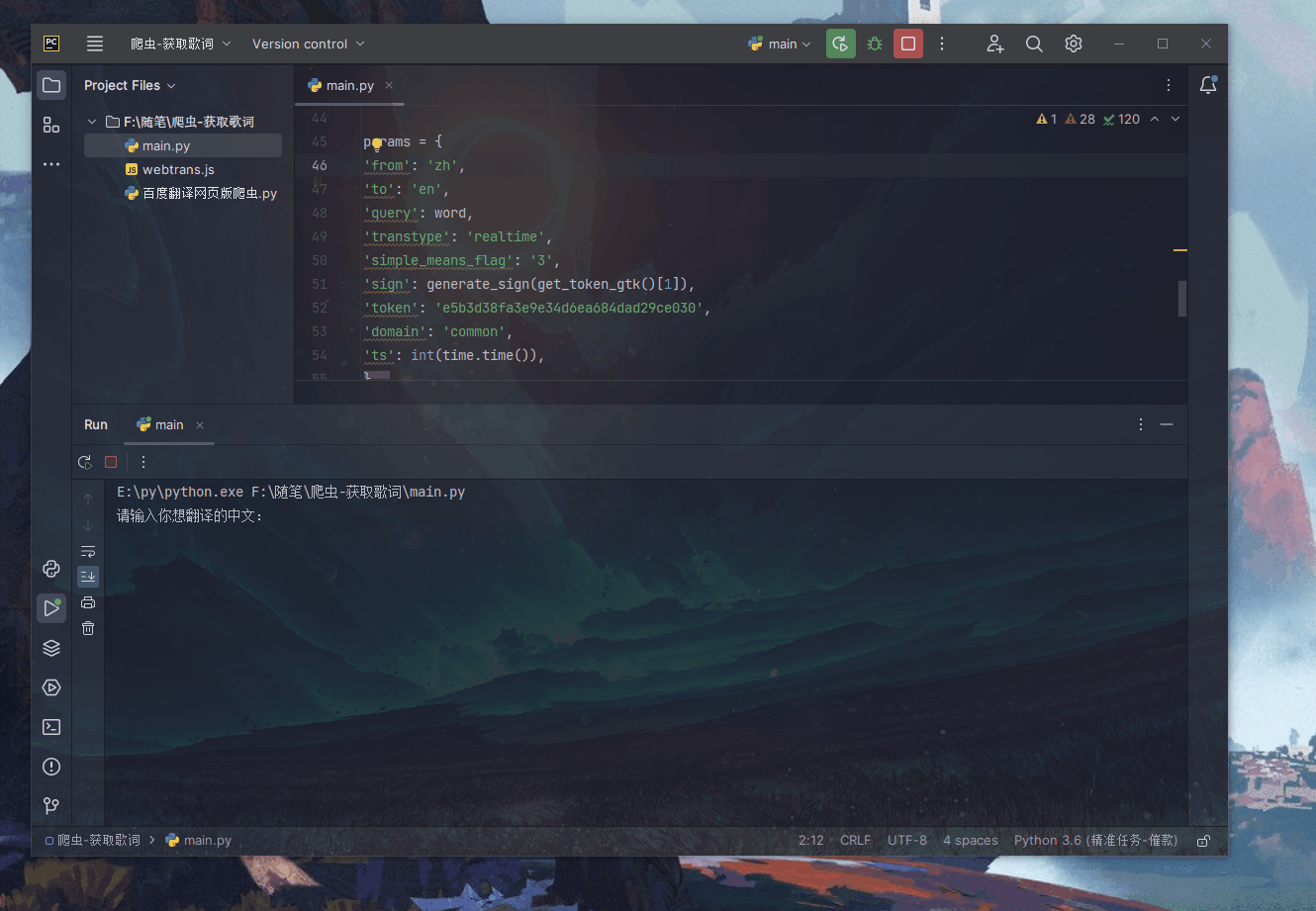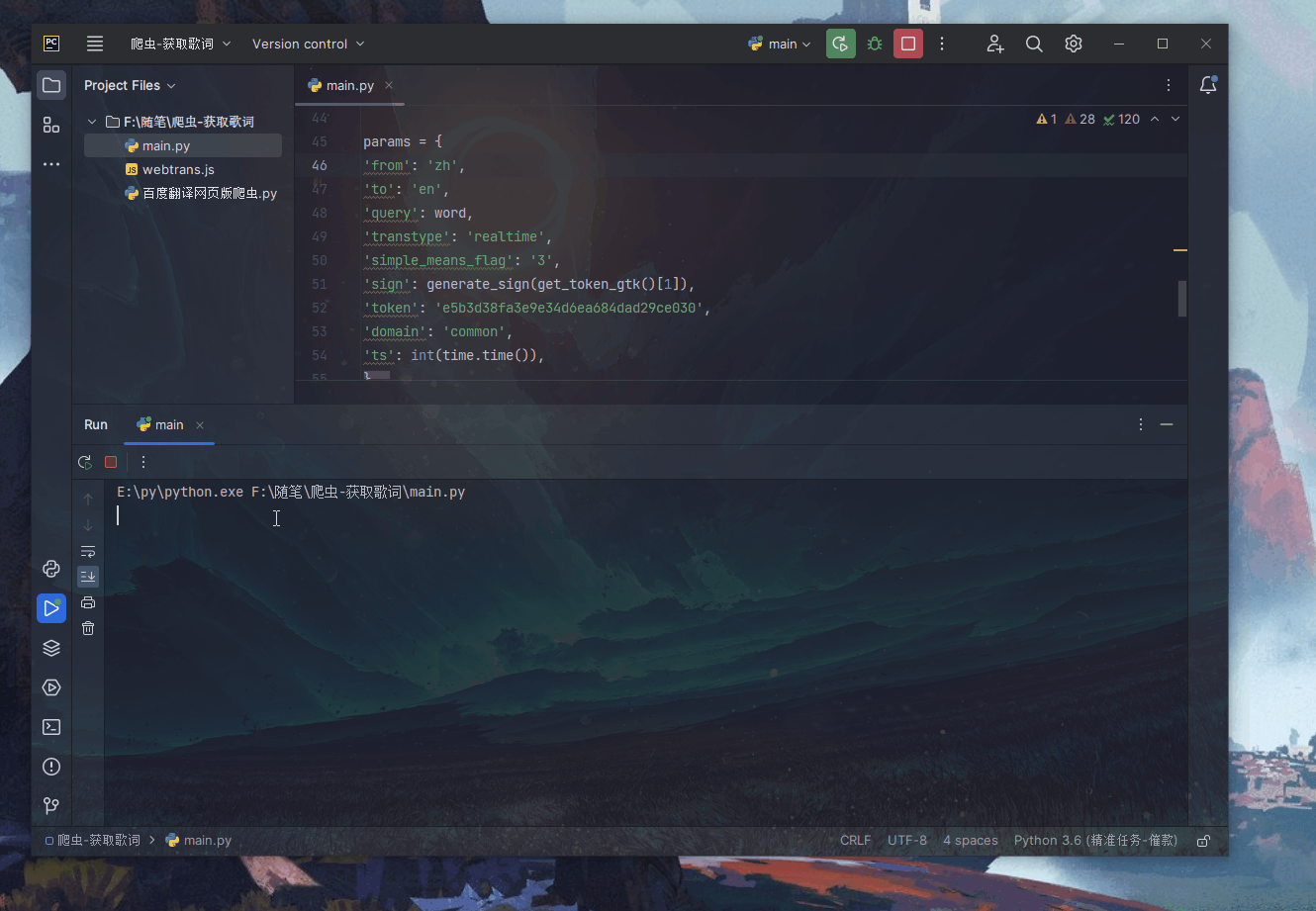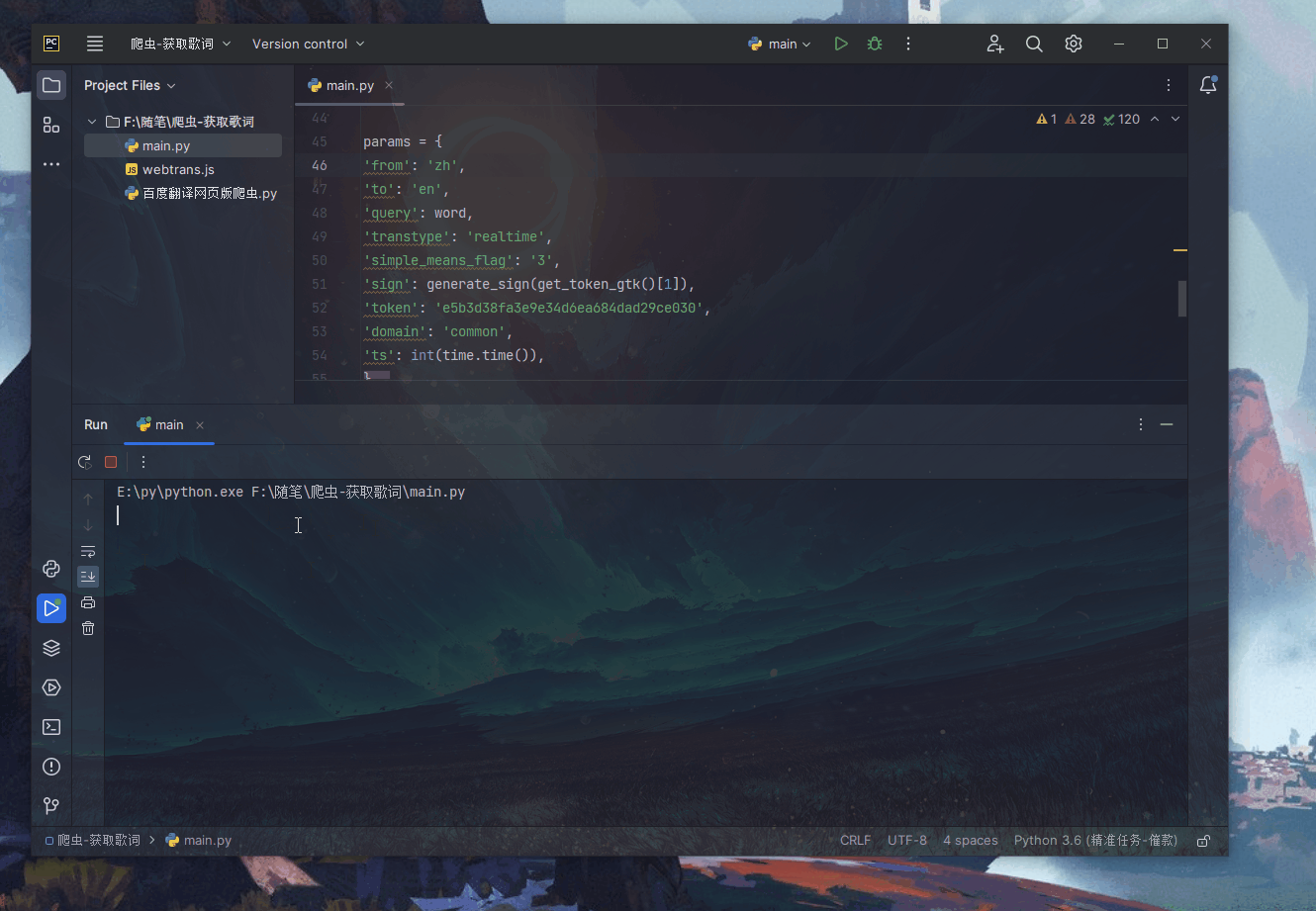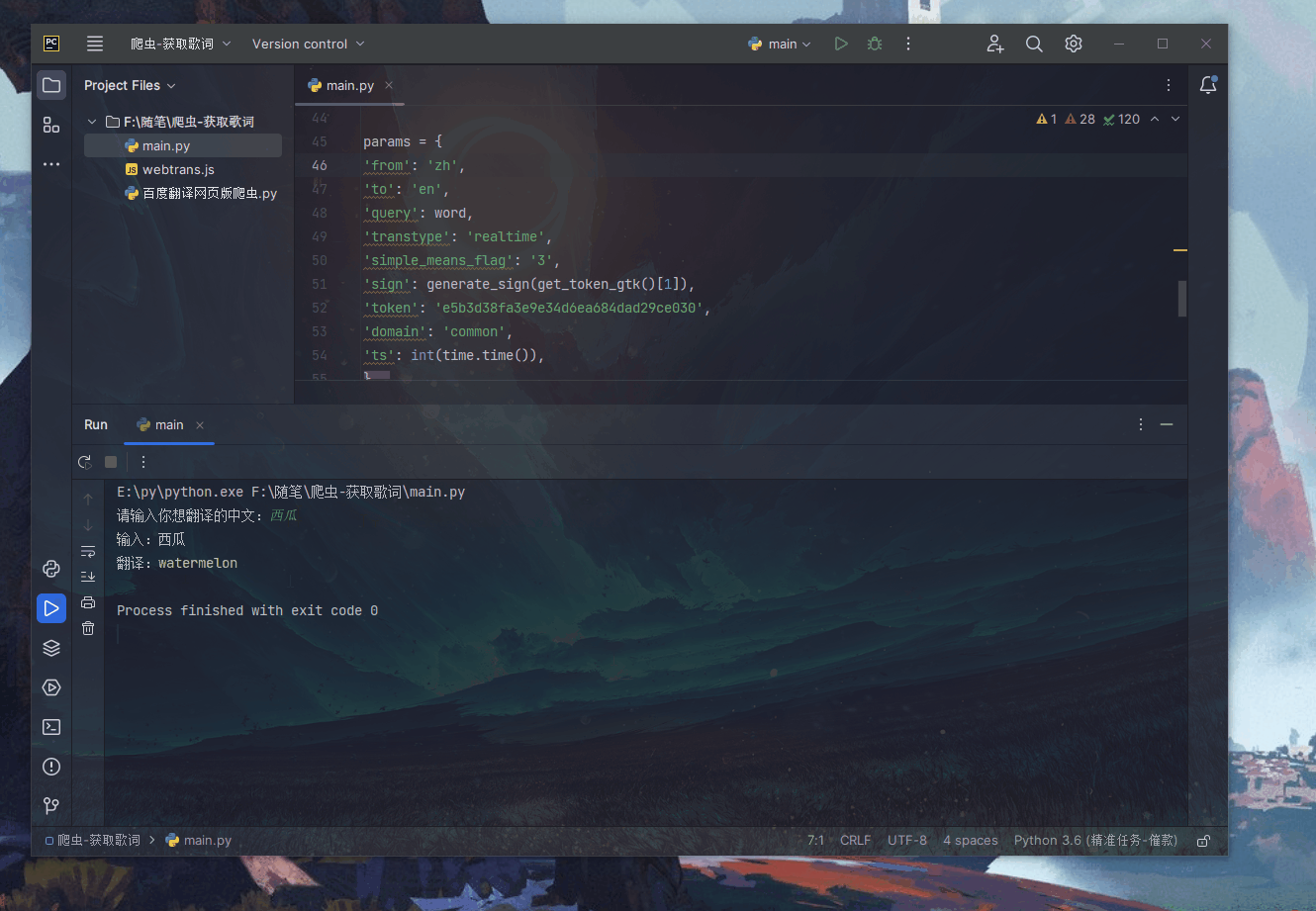
运行效果
解读response.text,这是一个包含Unicode字符的JSON字符串编码
也许我们需要翻译一下

解析json数据到文件中
将API接口返回的JSON数据解析为Python字典对象,并将其以JSON格式写入文件中文章来源:https://www.toymoban.com/news/detail-457587.html
dic_obj = response.json()
fp=open(userInput + '.json','w',encoding='utf-8')
json.dump(dic_obj,fp=fp,ensure_ascii=False)
完整代码
import json
import requests
header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.50'}
userInput = input("请输入检索内容:")
# 指定url
url='https://fanyi.baidu.com/sug'
# 发出请求,get或post
data={'kw':userInput}
# 获取响应
response = requests.post(url=url,data=data,headers=header)
dic_obj = response.json()
fp=open(userInput + '.json','w',encoding='utf-8')
json.dump(dic_obj,fp=fp,ensure_ascii=False)
运行结果
 文章来源地址https://www.toymoban.com/news/detail-457587.html
文章来源地址https://www.toymoban.com/news/detail-457587.html
到了这里,关于python爬虫-获取某某在线翻译的查询结果,爬取json文件并解析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!