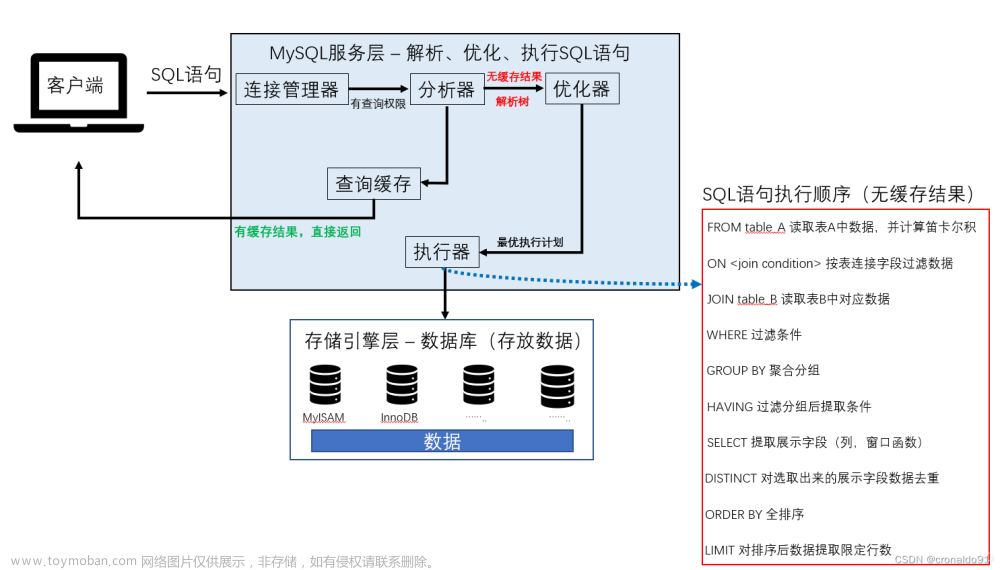
一、一个简单使用示例
我这里创建一张订单表
CREATE TABLE `order_info` (`id` int NOT NULL AUTO_INCREMENT COMMENT '主键',`order_no` int NOT NULL COMMENT '订单号',`goods_id` int NOT NULL DEFAULT '0' COMMENT '商品id',`goods_name` varchar(50) NOT NULL COMMENT '商品名称',`order_status` int NOT NULL DEFAULT '0' COMMENT '订单状态:1待支付,2成功支付,3支付失败,4已关闭',`pay_type` int NOT NULL DEFAULT '0' COMMENT '支付方式:1微信支付,2支付宝支付',`price` decimal(11,2) DEFAULT NULL COMMENT '订单金额',`pay_time` datetime DEFAULT NULL COMMENT '支付时间',PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='订单信息表';
复制代码
同时也在表里插了一些数据
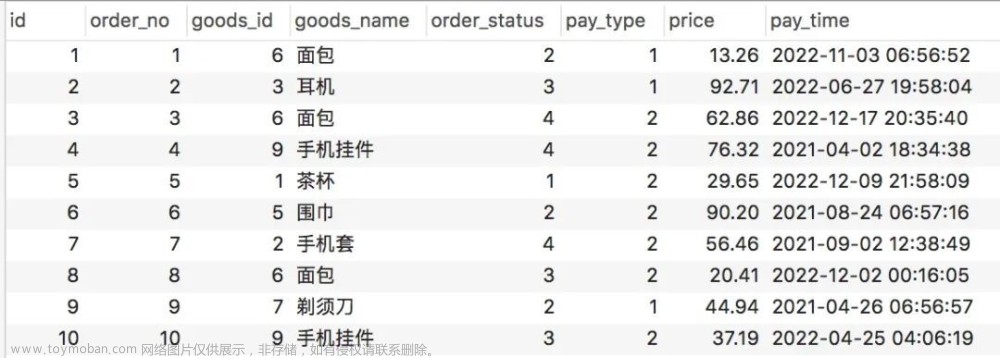
现在我们这里执行 group by 语句
select goods_name, count(*) as numfrom order_infogroup by goods_name
复制代码
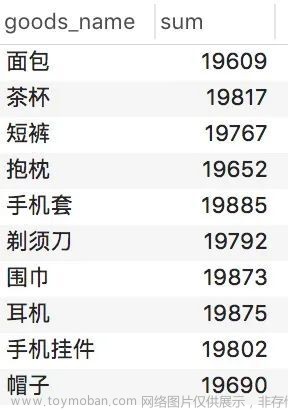
很明显,这里就可以统计出来 每件商品一共有多少订单数据!
二、group by 原理分析
2.1、explain 分析
不同的数据库版本,用 explain 执行的结果并不一致,同样是上面 sql 语句
「MySQL 5.7 版本」
-
Extra 这个字段的
Using temporary表示在执行分组的时候使用了临时表 -
Extra 这个字段的
Using filesort表示使用了排序
「MySQL 8.0 版本」
❝
我们通过对比可以发现:mysql 8.0 开始 group by 默认是没有排序的了!
❞
接下来我们来解释下,什么是临时表。
2.2、聊一聊 Using temporary
Using temporary 表示由于排序没有走索引、使用union、子查询连接查询,group_concat()或count(distinct)表达式的求值等等会创建了一个内部临时表。
注意这里的临时表可能是内存上的临时表,也有可能是硬盘上的临时表,理所当然基于内存的临时表的时间消耗肯定要比基于硬盘的临时表的实际消耗小。
但不是说多大临时数据都可以直接存在内存的临时表,而是当超过最大内存临时表的最大容量就是转为存入磁盘临时表
当 mysql 需要创建临时表时,选择内存临时表还是硬盘临时表取决于参数tmp_table_size和max_heap_table_size,当所需临时表的容量大于两者的最小值时,mysql 就会使用硬盘临时表存放数据。
用户可以在 mysql 的配置文件里修改该两个参数的值,两者的默认值均为 16M。
mysql> show global variables like 'max_heap_table_size';+---------------------+----------+| Variable_name | Value |+---------------------+----------+| max_heap_table_size | 16777216 |+---------------------+----------+1 row in setmysql> show global variables like 'tmp_table_size';+----------------+----------+| Variable_name | Value |+----------------+----------+| tmp_table_size | 16777216 |+----------------+----------+1 row in set
复制代码
2.3、group by 是如何产生临时表的
同样以该 sql 分析
select goods_name, count(*) as numfrom order_infogroup by goods_name
复制代码
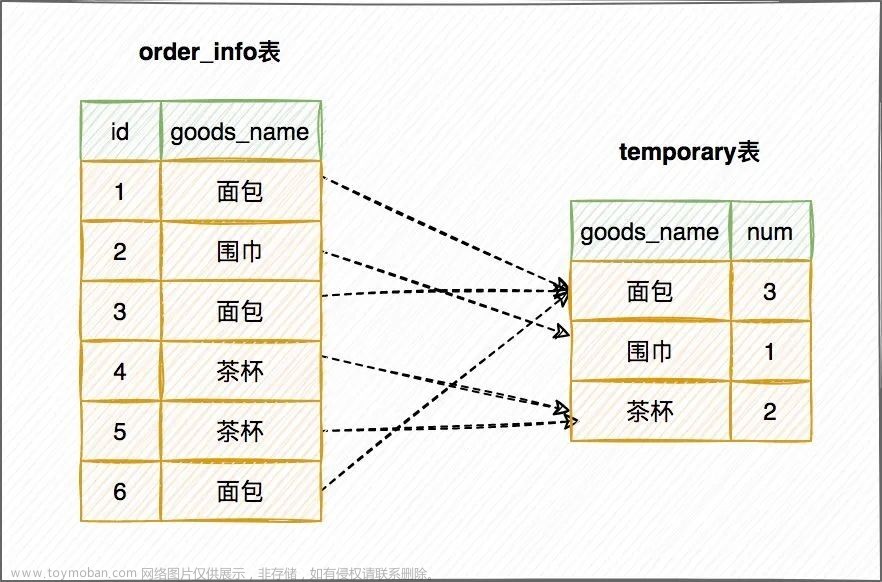
这个 SQL 产生临时表的执行流程如下
-
「创建内存临时表」,表里面有两个字段:goods_name 和 num;
-
全表扫描 order_info 表,取出 goods_name = 某商品(比如围巾、耳机、茶杯等)的记录
-
临时表没有 goods_name = 某商品的记录,直接插入,并记为 (某商品,1);
临时表里有 goods_name = 某商品的记录,直接更新,把 num 值 +1
-
重复步骤 3 直至遍历完成,然后把结果集返回客户端。
这个流程的执行图如下:
三、group by 使用中注意的一个问题
我们来思考一个问题
❝
select 的 列 和 group by 的 列 不一致会报错吗?
❞
比如
select goods_id, goods_name, count(*) as numfrom order_infogroup by goods_id;
复制代码
上面我们想根据商品 id 进行分组,统计每个商品的订单数量,但是我们分组只根据 goods_id 分组,但在查询列的时候,既要返回 goods_id,也要返回 goods_name。
我们这么写因为我们知道:一样的 goods_id 一定有相同的 goods_name,所以就没必要写成 group by goods_id,goods_name;
但上面这种写法一定会被支持吗?未必!
我们分别以 mysql5.7 版本和 8.0 版本做下尝试。
mysql5.7版本
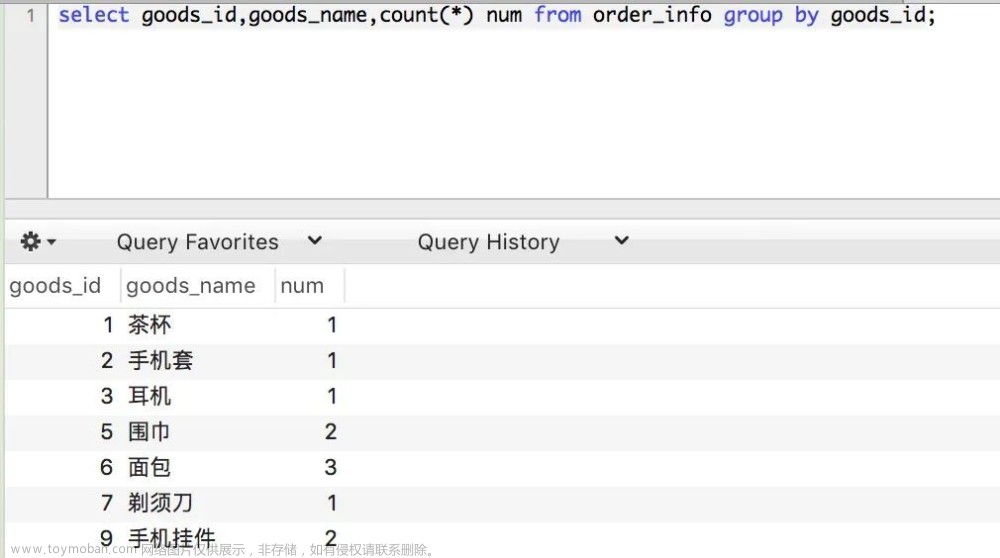
我们发现是可以查询的到的。
mysql8.0版本

我们在执行上面 sql 发现报错了,没错同样的 sql 在不同的 mysql 版本执行结果并不一样,我们看下报什么错!
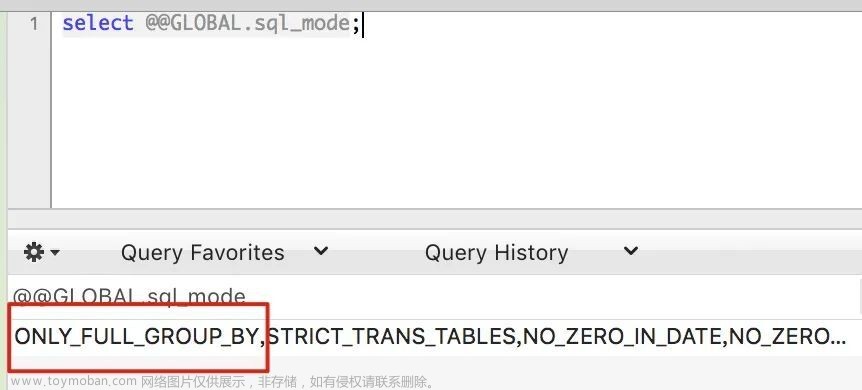
出现这个错误的原因是 mysql 的 sql_mode 开启了 ONLY_FULL_GROUP_BY 模式
❝
该模式的含义就是: 对于 group by 聚合操作,如果在 select 中的列,没有在 group by 中出现,那么这个 sql 是不合法的,因为列不在 group by 从句中。
❞
这其实是一种更加严谨的做法。
就比如上面这个 sql,如果存在这个商品的名称被修改过了,但是它们的 id 确还是一样的,那么这个时候展示的商品名称是修改前的还是修改后的呢?
那对于上面这种情况,mysql5.7 版本是如何做的呢?
1.「创建内存临时表」,表里面有三个字段:goods_id,goods_name 和 num;
2.当第一次这个goods_id=1对应 goods_name=面包 时,那么这个 id 对应 goods_name 就是面包,就算后面这个 id 对应的是火腿面包,鸡腿面包,这都不管,只要第一个是面包,那就固定是这个名称了。这叫先到先得原则。
如果你的 8.0 版本不想要 ONLY_FULL_GROUP_BY 模式,那关闭就可以了。
四、group by 如何优化
group by 在使用不当的时候,很容易就会产生慢 SQL 问题。因为它既用到临时表,又默认用到排序。有时候还可能用到磁盘临时表。
这里总结 4 点优化经验
-
分组字段加索引
-
order by null 不排序
-
尽量使用内存临时表
-
SQL_BIG_RESULT
4.1、分组字段加索引
-- 我们给goods_id添加索引alter table order_info add index idx_goods_id (goods_id)
复制代码
然后再看下执行计划
很明显 之前的 Using temporary 和 Using filesort 都没有了,只有 Using index(使用索引了)
4.2、order by null 不排序
如果需求是不用排序,我们就可以这样做。在 sql 末尾加上 order by null
select goods_id, count(*) as numfrom order_infogroup by goods_idorder by null
复制代码
但是如果是已经走了索引,或者说 8.0 的版本,那都不需要加 order by null,因为上面也说了 8.0 默认就是不排序的了。
4.3、尽量使用内存临时表
因为上面也说了,临时表也分为内存临时表和磁盘临时表。如果数据量实在过大,大到内存临时表都不够用了,这时就转向使用磁盘临时表。
内存临时表的大小是有限制的,mysql 中 tmp_table_size 代表的就是内存临时表的大小,默认是 16M。当然你可以自定义社会中适当大一点,这就要根据实际情况来定了。
4.4、SQL_BIG_RESULT
如果数据量实在过大,大到内存临时表都不够用了,这时就转向使用磁盘临时表。
而发现不够用再转向这个过程也是很耗时的,那我们有没有一种方法,可以告诉 mysql 从一开始就使用 磁盘临时表呢?
因此,如果预估数据量比较大,我们使用 SQL_BIG_RESULT 这个提示直接用磁盘临时表。
explain select sql_big_result goods_id, count(*) as numfrom order_infogroup by goods_id
复制代码

从执行结果来看 确实已经不存在临时表了。
五、一个很有意思的优化案例
为了让效果看去明显点,我在这里在数据库中添加了 100 万条数据(整整插了一下午呢)。
同时说明下当前数据库版本是8.0.22。
执行得 sql 如下:
select goods_id, count(*) as numfrom order_infowhere pay_time >= '2022-12-01 00:00:00' and pay_time <= '2022-12-31 23:59:59'group by goods_id;
复制代码
5.1、不加任何索引
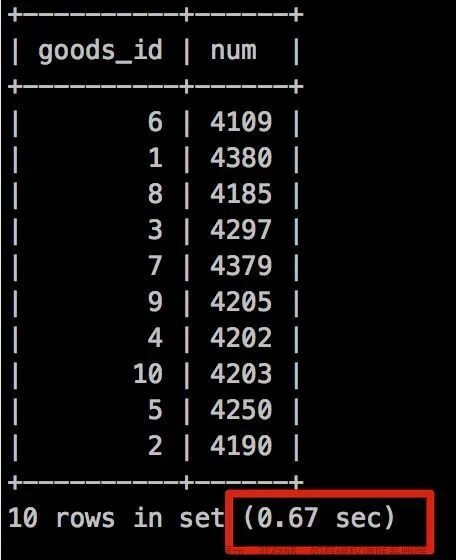
执行时间是: 0.67秒。
我们在执行下 explain

我们发现没有走任何索引,而且有临时表存在,那我是不是考虑给 goods_id 加一个索引?
5.2、仅分组字段加索引
alter table order_info add index idx_goods_id(goods_id);
复制代码
我们在执行下 explain

确实是走了上面创建的idx_goods_id,索引,那查询效率是不是要起飞了?
我们在执行下上面的查询 sql
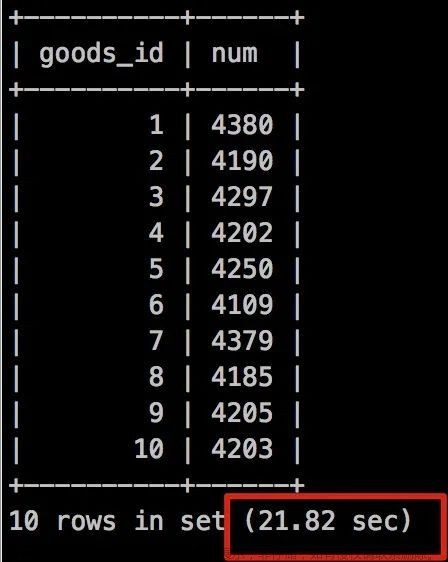
执行时间是: 21.82秒!
天啦,明明我的分组字段加了索引,而且从执行计划来看确实走了索引,而且也不存在Using temporary临时表了,怎么速度反而下来了,这是为什么呢?
原因:
虽然说我们用到了idx_goods_id 索引,那我们看上图执行计划中 rows = 997982,说明啥,说明虽然走了索引,但是从扫描数据来看依然是全表扫描呢,为什么会这样?
首先 group by 用到索引,那就在索引树上索引数据,但是因为加了 where 条件,还是需要在去表里检索几乎所有的数据, 这样子,还不如直接去表里进行全表扫,这样还更快些。
所以没有索引反而更快了
5.3、查询字段和分组字段建立组合索引
那我们给 pay_time 和 goods_id 建立组合索引呢?
-- 先删除idx_goods_id索引drop index idx_goods_id on order_info;-- 再新建组合索引alter table order_info add index idx_payTime_goodsId(pay_time,goods_id);
我们在执行下 explain

这次可以很明显的看到
-
Extra 这个字段的
Using index表示该查询条件确实用到了索引,而且是索引覆盖 -
Extra 这个字段的
Using temporary表示在执行分组的时候使用了临时表
为什么加了索引还会有临时表存在呢,其实原因很简单
❝
range 类型查询字段后面的索引全都无效
❞
因为 pay_time 是范围查询,索引 goods_id 无效,所以分组一样有临时表存在!
我们在看下查询时间
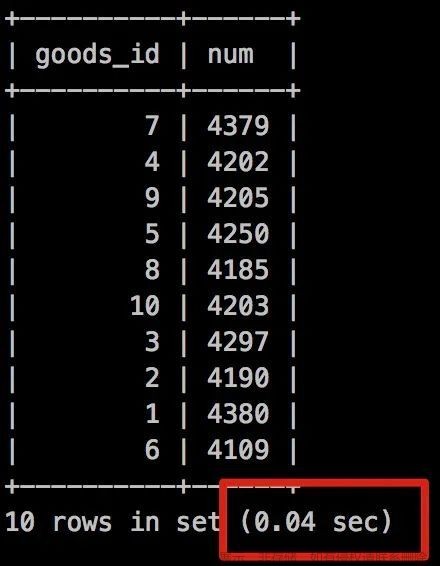
执行时间是: 0.04秒!
是不是快到起飞,虽然我们从执行计划来看依然还是存在 Using temporary ,但查询速度却非常快。
关键点就在Using index(索引覆盖),虽然排序是无法走索引了,但是不需要回表查询,这个效率提升是惊人的!
5.4、仅查询字段建立索引
上面说了就算建立了 pay_time,goods_id 组合索引,对于 goods_id 分组依然不走索引的。
这里我自建立 pay_time 单个索引
-- 先删除组合索引drop index idx_payTime_goodsId on order_info;-- 再新建单个索引alter table order_info add index idx_pay_time(pay_time);

这次可以很明显的看到
-
Extra 这个字段的
using index condition需要回表查询数据,但是有部分数据是在二级索引过滤后,再回表查询数据,减少了回表查询的数据行数 -
Extra 这个字段的
Using MRR优化器将随机 IO 转化为顺序 IO 以降低查询过程中 IO 开销 -
Extra 这个字段的
Using temporary表示在执行分组的时候使用了「临时表」
查看查询时间
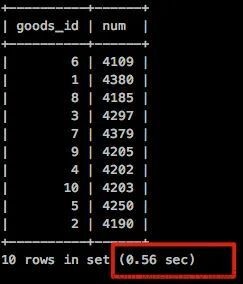
执行时间 0.56秒!
从结果看出,跟最开始不加索引查询速度相差不多,原因是什么呢?
最主要原因就是虽然走了索引,但是依然还需要回表查询,查询效率并没有提高多少!
那我们思考如何优化呢,既然上面走了回表,我们是不是可以不走回表查询,这里修改下 sql
select goods_id, count(*) as numfrom order_infowhere id in (select idfrom order_infowhere pay_time >= '2022-12-01 00:00:00'and pay_time <= '2022-12-31 23:59:59')group by goods_id;
查看查询时间
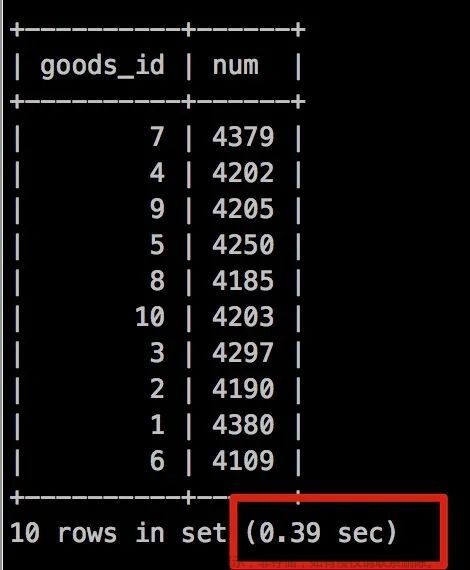
执行时间 0.39秒!
速度确实有提升,我们在执行下 explain

我们可以看到 没有了using index condition,而有了Using index,说明不需要再回表查询,而是走了索引覆盖!文章来源:https://www.toymoban.com/news/detail-457597.html
本篇到这里就结束啦,希望整篇文章对你有帮助哦文章来源地址https://www.toymoban.com/news/detail-457597.html
到了这里,关于MySQL 数据库 group by 语句怎么优化?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!