什么是limit 深分页问题?怎么解决?
select * from table order by key limit 10;
select * from table order by key limit 9999, 10;
我们想到给这个要排序的字段加上索引,但是加上索引之后,查询的速度依旧很慢。
当深分页的时候,优化器都不会选择走key这个辅助索引了,而是选择type = All,全表扫描,因为优化器这时候觉得,你走辅助索引,还要大量的回表,可能效率还不如直接全表扫描 + 排序呢。
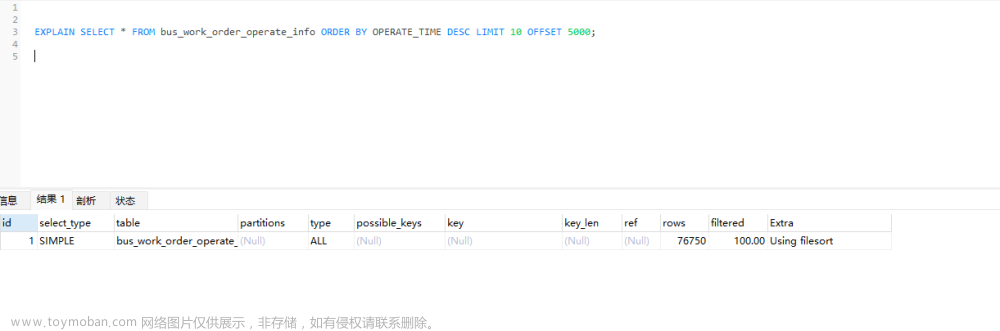
为什么深分页慢呢?
因为深分页,会有很多不必要,没有意义的回表操作。我只要第9999页的记录,但是第 9998,9997…页的记录也都会进行回表操作。
从sql角度优化:
select * from table where key >=
(select key from table order by key limit 9999, 1)
// 利用索引覆盖特性查找第9999页的第一条记录,type = index,extra = using index
order by key limit 10;
// 走key的索引,快速定位,然后再往后取10条记录就行了,type = range,extra = using where
从业务角度优化:
连续翻页,可以利用上一页的最后一条记录的字段值,作为下一页的查询的起始值,可以减少一次子查询。
这时你就明白了,为什么有的地方UI只有上一页,下一页了吧。没有可以跳转的页数,给用户点击。
还有移动端的滚动加载,上拉加载下一页也是基于这个思路优化的。
还可以省去 count(*) 计算总页数的过程
select * from table where key >
上一页最后一条记录的字段值
order by key limit 10;
但是存在一个问题:还需要考虑出现大量重复数据的情况,在后续页的查询需要增加偏移量的处理
但是这样的设计真的有必要,有意义吗?用户真的会没事来查询第1万页的数据吗?
美年达大佬提供的调优方案:
先通过子查询拿到第99000页的所有记录的id值,然后和原表进行一次join表连接,比对id值,减少大量的回表操作。
select * from order_info as o
join (select id from order_info where period = 202207 order by modified desc limit 99000, 1000)
as temp on temp.id = o.id order by modified;文章来源地址https://www.toymoban.com/news/detail-458173.html
文章来源:https://www.toymoban.com/news/detail-458173.html
到了这里,关于什么是limit 深分页问题?怎么解决?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![Elasticsearch分页搜索数量不能超过10000的解决This limit can be set by changing the [index.max_result_window] index](https://imgs.yssmx.com/Uploads/2024/02/756796-1.png)