知识蒸馏之自蒸馏@TOC
知识蒸馏之自蒸馏
本文整理了近几年顶会中的蒸馏类文章(强调self- distillation),后续可能会继续更新其他计算机视觉领域顶会中的相关工作,欢迎各位伙伴相互探讨。
背景知识-注意力蒸馏、自蒸馏
1.定义:
- 注意力蒸馏 (Attention distillation):用于把大网络学习到的注意力特征图(attention map)迁移到小网络中。
- **自蒸馏(self-distillation)😗*即网络本身既是教师模型又是学生模型,蒸馏通常在网络内部不同层之间进行。
2.追溯:
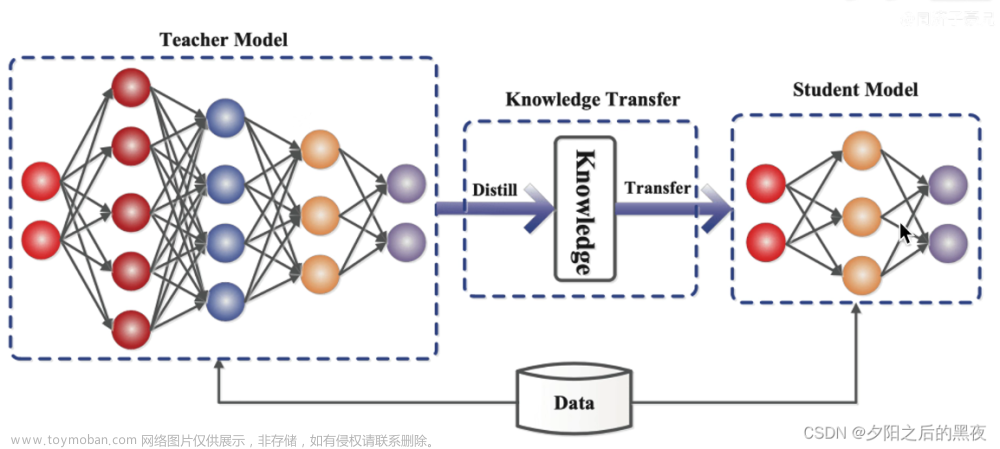
- 知识蒸馏(knowledge distillation)是模型压缩的一种常用的方法,不同于模型压缩中的剪枝和量化,知识蒸馏是通过构建一个轻量化的小模型,利用性能更好的大模型的监督信息,来训练这个小模型,以期达到更好的性能和精度。
- 知识蒸馏中的最重要的三大元素:知识类型、蒸馏策略及teacher-student Architectures。其中,三种常见的知识类型主要包括Response-Based Knowledge、Feature-Based Knowledge、Relation-Based Knowledge。三者的示意图如下:

Response-based侧重于学习teacher model最后一层的响应输出,如在两个模型的logit层建立蒸馏损失

feature-based 侧重于学习teacher model中各个hint layer的feature map,注意力蒸馏就属于feature-based distillation。

relation-based 更加强调teacher model中各个layer之间的关系或者teacher model对于data samples的关联性的响应。
有关知识蒸馏的更多了解可参考:**《Knowledge Distillation: A Survey》【1】*
-
早期的注意力蒸馏:最早提出注意力蒸馏的文章是发表于ICLR2017的《Paying more attention to attention: improving the performance of convolutional neural networks via Attention Transfer》
论文提出:教师模型和学生模型整体结构比较类似的情况下,在教师模型和学生模型的对应阶段建立注意力蒸馏损失。其中注意力特征图的构建方式可以选择Activation-based或Gradient-based 。
Paper Reading
1. ICCV2019:Learning Lightweight Lane Detection CNNs by Self Attention Distillation
code link
-
Main contribution:论文提出一种自注意力蒸馏方法(Self Attention Distillation(SAD)),SAD允许一个网络利用从它自己的层得到的注意力地图作为它较低层的蒸馏目标,并在没有任何额外监督或标签的情况下获得实质性的改进。作者发现,从训练到合理水平的模型中提取的注意力地图可以编码丰富的上下文信息。有价值的上下文信息可以作为一种“免费”监督的形式,通过在网络本身内执行自顶向下和分层的注意蒸馏来进一步表示学习。在不增加推理时间的情况下,SAD可以很容易地融入到任何前馈卷积神经网络中。
-
这篇工作首次尝试使用网络自身的注意力地图作为蒸馏目标。
-
Visulization/问题引入:

对比上图(a)(b),作者认为当模型训练到一定程度时,来自不同层次的注意力map将捕捉到各种丰富的背景信息,因此作者在40epoch之后添加了SAD机制,使得block3→(mimic)block4、block2→(mimic)block3,从而得到(b)图所示的效果。(1)较低层的注意图得到了细化,视觉注意能够捕捉到更丰富的场景上下文;(2)较低层学习到的更好的表示反过来有利于较深层的注意力map。 -
注意力特征图的选取
- 在acitivation-based Attention map和Gradient-based Attention map的选择中,作者通过实验发现acitivation-based 的方式取得了明显的收益,而Gradient-based 几乎没有带来明显增益。因此论文中采用了acitivation-based的方式。
- 探索使用何种acitivation-based Attention map,即寻找一种合适的映射,从特征图到基于通道维度的注意力特征图。常见的三种方式包括:

三种注意力特征提取的方式差别在于:(1)前两者差别主要在于the larger the p is, the more focus is placed on these highly activated areas.(2)与Fp max(Am)相比,Fp sum(Am)的bias更小,因为它计算多个神经元的权重,而不是选择这些神经元激活的最大值作为权重。本文中通过实验选择F2 sum(Am).
-
总体框架

-
效果展示:

-
Ablation Study
-
The mimicking path
-
作者分别在编码器各个阶段之间建立mimic path,探究何种mimic 路径是更好的

实验发现:(1)middle和higher layer的蒸馏效果更好;(2)增加shallow layer的蒸馏反而会降低性能; 作者分析,SAD在底层不起作用的原因是,这些层最初是用来检测场景的底层细节的。使它们模仿后几层的注意图将不可避免地损害它们检测局部特征的能力,因为后几层编码了更多的全局信息.(3)与模拟非相邻层的注意图相比,连续模拟相邻层的注意图能带来更大的性能提高。作者推测,相邻层的注意图在语义上比非相邻层的注意图更接近. -
蒸馏方向:作者同样做了反向蒸馏实验,探究higher layer向low layer进行蒸馏.但意料之中的是,算法的性能明显降低了,因为浅层包含了更多的噪声信息且对全局语义信息的把握较差.
-
-
SAD vs Deep supervision

实验结果显示:SAD明显胜过Deep supervision.作者分析原因:首先,与稀疏和刻板的标签相比,SAD提供了更软的注意目标,捕捉更多的上下文信息,表明场景结构。从后一层的注意力图中提取信息有助于前一层掌握语境信号。其次,SAD路径提供了一个从深层到浅层的反馈连接。通过注意力蒸馏,这种联系有助于促进连续层次之间的交互学习。 -
The timepoint to introduce SAD in the training process
作者研究了在训练过程的不同阶段加入SAD的效果差异.作者发现,相比于早期加入SAD,后期加入的效果更好.
-
2. ICCV2019:Be Your Own Teacher: Improve the Performance of Convolutional Neural Networks via Self Distillation
(1)问题引入
在一些要求不可容忍错误的应用中,如自动驾驶和医学图像分析,需要进一步提高预测和分析的准确性,同时需要更短的响应时间。传统的方法通常侧重于提高性能或减少计算资源(响应时间)。知识蒸馏是目前流行的一种压缩方法,其灵感来源于教师对学生的知识转移。其关键策略是将紧凑的学生模型的效果向大型参数化的教师模型近似。然而模型间的知识蒸馏存在以下缺陷:(1)知识迁移的低效性,即学生模型往往并不能充分学习到教师模型的全部知识;(2)如何设计并训练合适的教师模型,现有的蒸馏框架往往需要消耗大量的实验来找到最好的教师模型架构。下图为模型蒸馏与本文提出的自蒸馏策略在训练/推理效率及准确率上的直观对比。
(2)Main Contribution
- 本文提出的自蒸馏策略在几乎不引入任何计算成本的前提下显著提升了算法的准确率。这一点在不同model(from ResNeXt to VGG19)上得到了验证。
- 自蒸馏提供了一个不同深度的单一神经网络可执行程序,允许在资源有限的边缘设备上进行自适应精度和效率的权衡。
- 在两种数据集上进行了五种卷积神经网络的实验,验证了该技术的泛化性能。
(3)主要思路
- 架构设计:根据backbone的网络架构进行分级(如下图将会被分为四个子部分),在每个子部分后加Bottleneck模块(该模块只参与训练不参与推理)
-
loss函数设计:loss分为三部分(如下图),
- source1是指在每个classifier末端softmax之后建立与label之间的交叉熵损失(预测概率与label之间的蒸馏);
- source2是在将每个classifier的softmax与最深层classifier的softmax建立KL散度蒸馏损失(即预测概率之间的蒸馏)
- source3是在将每个classifier的feature与最深层classifier的feature建立L2蒸馏损失(即Feature之间的蒸馏)(值得注意的是,这里的蒸馏并不像上一篇文章中所示的相邻层间进行蒸馏,而是全部与最深层之间建立蒸馏路径)
-


(4)实验探究
-
训练策略的对比:各层classifier的结果、集成结果与不适用自蒸馏策略的性能差异

可以看出,首先本文提出的策略在各个数据集和各个模型下都有性能的提升;网络模型越深,这种策略取得的性能收益越大;Cifar100整体上比ImageNet取得的收益更大,主要是因为ImageNet中浅层的classifier性能太差 -
与其他蒸馏方法的对比
本文在CIfar10数据集上与其他模型间的蒸馏算法进行对比,效果明显更优 -
与深度监督的对比
这里本人认为:由于文章中提出的蒸馏策略相当于是在深度监督的基础上增加了logit层以及hint层间的自蒸馏,所以理论上来说也是应该比深度监督的监督力度更强的。(作者指出,特别是浅层的classifier提升明显)
-
性能与效率之间的trade-off(3/4的模型在classifier3/4上获得稳定的性能提升同时伴随着推理速度的加快)

(5)自蒸馏剖析
- 自蒸馏可以使模型收敛到具有泛化特性的较为平坦的局部极小。因为随着噪声水平的提升,算法性能表现更加稳定。
- 自蒸馏能够有效改善梯度爆炸问题,在自蒸馏过程中,神经网络的监督被注入到不同的深度
- 在自蒸馏中,

3.CVPR2021:Refine Myself by Teaching Myself :Feature Refinement via Self-Knowledge Distillation
(1)问题引入:
-
从教师模型进行知识蒸馏,主要有三种方式:soft label(类别预测概率);倒数第二层的输出(如同一实例在倒数第二层的输出特征图之间建立余弦相似度);中间层的feature map。
-
在基于特征图的蒸馏方面,前人研究诱导学生模拟 1)教师网络的特征;2)教师网络的注意力图抽象;3)教师网络的FSP矩阵
-
自蒸馏主要分为两种:基于数据增强的(即网络对于同一个实例或同一类的一对实例产生一致的预测)和基于辅助网络的(利用分类器网络中间的附加分支,通过知识转移诱导这些附加分支做出相似的输出)
基于辅助网络的:这些方法依赖于辅助网络,辅助网络具有与分类器网络相同或更小的复杂度;因此,无论是通过特征(即卷积层的输出),还是通过分类器网络的软标签,都很难生成精细化的知识
基于数据增强的:基于数据增强的方法很容易丢失实例之间的局部信息,例如不同扭曲的实例或旋转的实例 -
本文提出一种特征自蒸馏方法,可以利用软标签和特征地图蒸馏的自我知识蒸馏(下图为本文方法(d)与上述两种类型方法的不同)

(2)主要思路(同时借鉴BiFPN和自蒸馏策略来精化特征并实现自我蒸馏)

与上述两篇文章不同的是,本文不是在不同深度特征图之间建立蒸馏,而是通过对各个深度特征层的整合与细化来指导建立同级的特征图蒸馏。文章来源:https://www.toymoban.com/news/detail-458182.html
- loss组成包括三个部分:1)同级特征图之间的蒸馏(对特征图进行了channel-wise pooling);2)原始分类网络末端与self-teacher末端softmax层之间的KL散度蒸馏; 3)原始分类网络、self-teacher分别于label之间的蒸馏

(3)实验评估
-
分类实验中与其他方法间的对比(其中SAD和BYOD分别对应上述两篇文章)
算法在多个公开数据集上进行了测试,这里只列举了部分
可以看出,算法即便是在去除Feature级别的监督情况下(FRSKD\F),依然取得了更好的性能。在加入SLA自监督策略[6]后,效果提升更加明显。 -
分割实验中对比(在实验中,我们堆叠了三层BiFPN,并增加了两层作为自助教师网络)

- 注意力map可视化

可以看出,相对于主要的classifier,self-teacher产生的注意力能够更好得聚焦到目标最具有辨识度得区域。
此外,算法对于self-teacher的结构选择、与模型间知识蒸馏方法的对比、添加数据增强(前后以及何种增强)的效果对比等都做了相应的实验,有需要可自行查看。
Reference
[1] Jianping Gou,Baosheng Yu, et al. Knowledge Distillation: A Survey.2021
[2] Paying more attention to attention: improving the performance of convolutional neural networks via Attention Transfer.ICLR2017
[3] Yuenan Hou, Zheng Ma,et al.Learning Lightweight Lane Detection CNNs by Self Attention Distillation,ICCV2019.
[4] Linfeng Zhang,Jiebo Song,et al.Be Your Own Teacher: Improve the Performance of Convolutional Neural
Networks via Self Distillation,ICCV2019.
[5] Mingi Ji,et al. Refine Myself by Teaching Myself :Feature Refinement via Self-Knowledge Distillation,CVPR2021.
[6]Hankook Lee,et al .Self-supervised Label Augmentation via Input Transformations,ICML2020.文章来源地址https://www.toymoban.com/news/detail-458182.html
到了这里,关于知识蒸馏之自蒸馏的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!