说在前面:
本文是《Go学习圣经》 的第二部分。
第一部分请参见:Go学习圣经:0基础精通GO开发与高并发架构(1)
现在拿到offer超级难,甚至连面试电话,一个都搞不到。
尼恩的技术社群中(50+),很多小伙伴凭借 “左手云原生+右手大数据”的绝活,拿到了offer,并且是非常优质的offer,据说年终奖都足足18个月。
从Java高薪岗位和就业岗位来看,云原生、K8S、GO 现在对于 高级工程师/架构师来说,越来越重要。尼恩从架构师视角出发,基于自己的尼恩 3高架构师知识体系和知识宇宙,写一本《GO学习圣经》

最终的学习目标
咱们的目标,不仅仅在于 GO 应用编程自由,更在于 GO 架构自由。
前段时间,一个2年小伙伴希望涨薪到18K, 尼恩把GO 语言的项目架构,给他写入了简历,导致他的简历金光闪闪,脱胎换股,完全可以去拿头条、腾讯等30K的offer, 年薪可以直接多 20W。
足以说明,GO 架构的含金量。
另外,前面尼恩的云原生是没有涉及GO的,但是,没有GO的云原生是不完整的。
所以, GO语言、GO架构学习完了之后,咱们在去打个回马枪,完成云原生的第二部分: 《Istio + K8S CRD的架构与开发实操》 , 帮助大家彻底穿透云原生。

本文目录
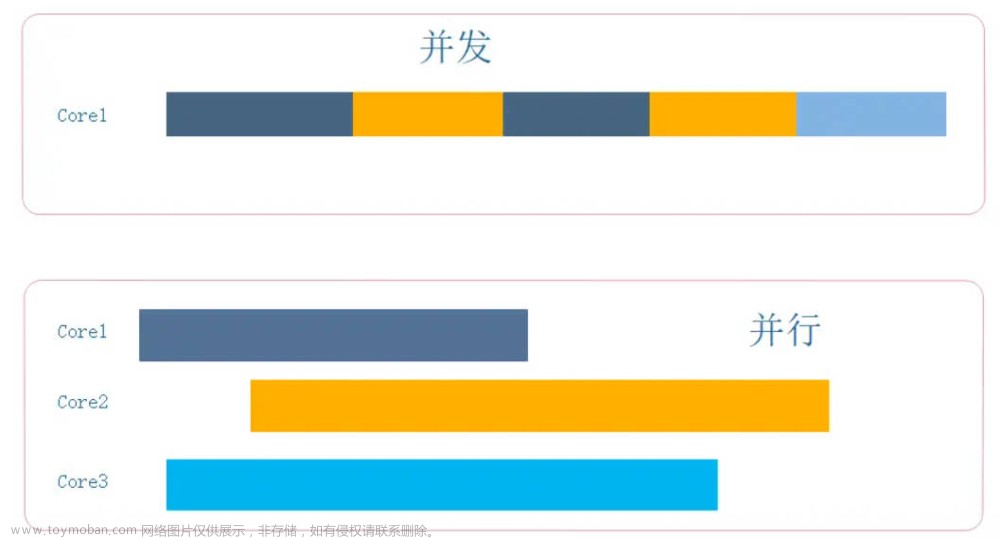
并发编程
Go 将并发结构作为核心语言的一部分提供。
Go 协程
Go 协程(Goroutine)是 Go 语言中的一种轻量级线程实现。
Go 协程(Goroutine)通过在单个线程内同时运行多个函数来实现并发,从而避免了线程切换的开销,并且能够更加高效地利用系统资源。
与传统的线程模型不同,Go 协程不是由操作系统内核调度的,而是由 Go 运行时(runtime)自己调度的。
为啥是轻量级线程呢?Go 协程(Goroutine)可以避免因为线程调度引起的额外开销,并且能够更好地控制协程的数量和调度机制。
创建一个协程非常简单,只需要在函数调用前面添加 go 关键字即可,例如:
func main() {
go func() {
fmt.Println("Hello, world!")
}()
}
这段代码会创建一个新的协程,并在其中执行匿名函数中的代码。
这个协程会在后台运行,不会阻塞主线程的执行。
创建Go 协程(Goroutine)
Go 程(goroutine)是由 Go 运行时管理的轻量级线程。
创建一个协程非常简单,只需要在函数调用前面添加 go 关键字即可
go f(x, y, z)
上面的代码,会启动一个新的 Go 协程(Goroutine)去执行 f(x, y, z) 函数, x, y 和 z 的求值发生在当前的 Go协 程中,而 f 的执行发生在新的 Go 协程中。
下面是一个例子
package cocurrent
import (
"fmt"
"time"
)
func say(s string) {
for i := 0; i < 5; i++ {
time.Sleep(100 * time.Millisecond)
fmt.Printf("字符 %s: %d \n", s, i)
}
}
func GoroutineDemo() {
go say("sync world ")
say("hello")
}

执行的结果

Go 协程在相同的地址空间中运行,因此在访问共享的内存时必须进行同步。
Go标准库 协程同步
Go 标准库中提供了多种同步机制,可以满足不同场景下的需求。以下是 Go 中常用的同步机制:
- Mutex:互斥锁,用于保护临界区(critical section)代码,只允许一个协程进入临界区执行代码,其他协程需要等待。使用 sync.Mutex 类型来定义互斥锁。
- RWMutex:读写锁,用于保证在读操作时允许多个协程同时访问资源,在写操作时只允许一个协程进入临界区修改资源。使用 sync.RWMutex 类型来定义读写锁。
- WaitGroup:等待组,用于等待一组并发协程执行完成后再继续执行。使用 sync.WaitGroup 类型来定义等待组。
- Cond:条件变量,用于在协程之间同步和通信。使用 sync.Cond 类型来定义条件变量。
- Once:单次执行,用于确保某个操作只会被执行一次。使用 sync.Once 类型来定义单次执行。
这些同步机制都可以帮助我们更好地控制协程的执行顺序和并发访问共享资源的安全性。在实际开发中,我们需要根据具体情况选择合适的同步机制,并且要注意避免死锁等问题。
Mutex互斥锁同步
这里涉及的概念叫做 互斥(mutual exclusion) ,我们通常使用互斥锁(Mutex)这一数据结构来提供这种机制。
Go 中的 Mutex(互斥锁)是一种最基本的同步机制,用于保护临界区代码,只允许一个协程进入临界区执行代码,其他协程需要等待。在 Go 标准库中,可以使用 sync.Mutex 类型来定义互斥锁。
Go 标准库中提供了 sync.Mutex 互斥锁类型及其两个方法:
LockUnlock
我们可以通过在代码前调用 Lock 方法,在代码后调用 Unlock 方法来保证一段代码的互斥执行。参见 Inc 方法。
我们也可以用 defer 语句来保证互斥锁一定会被解锁。参见 Value 方法。
sync.Mutex类似于java 里边的 Lock 显示锁。 关于java显示锁,请参见 尼恩《Java 高并发核心编程 卷2 加强版》
啰嗦一下,sync.Mutex 类型包含两个方法:
- Lock():获得互斥锁,如果当前锁已经被其他协程获得,就会一直等待,直到锁被释放为止。
- Unlock():释放互斥锁,允许其他协程获得锁并进入临界区。
下面是一个使用 Mutex 实现协程同步的例子:
import (
"fmt"
"sync"
)
var counter int
func MutexDemo() {
var wg sync.WaitGroup
var mu sync.Mutex
wg.Add(100)
for i := 0; i < 100; i++ {
go func() {
mu.Lock()
counter++
mu.Unlock()
wg.Done()
}()
}
wg.Wait()
fmt.Println("Counter:", counter)
}
在这个例子中,我们创建了一个计数器 counter,并启动了 100 个协程对其进行累加操作。由于对 counter 的访问是并发的,因此需要使用互斥锁 mu 来保护它,以避免不同协程之间的竞争条件。
在每个协程中,首先使用 mu.Lock() 方法获得互斥锁,然后对 counter 进行加 1 操作,并最终使用 mu.Unlock() 方法释放互斥锁。由于只有一个协程可以同时获得互斥锁并进入临界区,因此可以保证对 counter 的操作是安全的。
最后,我们使用 sync.WaitGroup 来等待所有协程执行完毕,并输出最终的计数器值。
WaitGroup 等待组
在 Go 中,可以使用 sync.WaitGroup 来等待一组协程完成执行。
sync.WaitGroup 类似于java 里边的闭锁。 关于java闭锁,请参见 尼恩《Java 高并发核心编程 卷2 加强版》
sync.WaitGroup 类型提供了三个方法:
- Add(delta int):将 WaitGroup 的计数器加上 delta 值。如果 delta 是负数,则会 panic。
- Done():将 WaitGroup 的计数器减 1。相当于 Add(-1)。
- Wait():阻塞当前协程,直到 WaitGroup 的计数器为 0。
下面是一个使用 sync.WaitGroup 实现并发下载的例子:
import (
"fmt"
"sync"
)
func main() {
urls := []string{
"https://www.google.com",
"https://www.bing.com",
"https://www.yahoo.com",
"https://www.baidu.com",
"https://www.amazon.com",
"https://www.apple.com",
}
var wg sync.WaitGroup
for _, url := range urls {
wg.Add(1)
go func(url string) {
defer wg.Done()
download(url)
}(url)
}
wg.Wait()
fmt.Println("All downloads completed.")
}
func download(url string) {
fmt.Printf("Downloading %s...\n", url)
// 模拟下载操作
}
在这个例子中,我们定义了一个 urls 列表,包含了需要下载的网址。
然后创建了一个 sync.WaitGroup 对象 wg,并通过调用 wg.Add(1) 把计数器置为 1。
接着使用 for 循环遍历 urls 列表,对每个网址都启动一个新的协程,并在协程中调用 download() 函数来下载网页内容。
在协程中,通过 defer wg.Done() 将 WaitGroup 的计数器减 1,表示当前协程已经完成了下载任务。
最后,主程序调用 wg.Wait() 来等待所有协程执行完毕,并输出提示信息表示所有下载任务都已经完成了。
Cond(条件变量)
Go 中的 Cond(条件变量)是一种同步机制,用于在协程之间同步和通信。
Cond 是基于 Mutex 和 WaitGroup 实现的,它可以让一个或多个协程等待某个条件满足后再执行下一步操作。
在 Go 标准库中,可以使用 sync.Cond 类型来定义条件变量。
sync.Cond 类型包含三个方法:
- Broadcast():唤醒所有正在等待条件变量的协程。
- Signal():唤醒一个正在等待条件变量的协程。
- Wait():阻塞当前协程,并解锁 Mutex,直到收到 Broadcast 或 Signal 信号后才会被唤醒并重新获得 Mutex。
下面是一个使用 Cond 实现生产者-消费者模型的例子:
import (
"fmt"
"sync"
)
const capacity = 5
var queue []int
var mu sync.Mutex
var cond = sync.NewCond(&mu)
func main() {
var wg sync.WaitGroup
wg.Add(2)
// 生产者协程
go func() {
defer wg.Done()
for i := 0; i < capacity*2; i++ {
mu.Lock()
for len(queue) == capacity {
cond.Wait()
}
queue = append(queue, i)
fmt.Println("Produce:", i)
if len(queue) == 1 {
cond.Signal()
}
mu.Unlock()
}
}()
// 消费者协程
go func() {
defer wg.Done()
for i := 0; i < capacity*2; i++ {
mu.Lock()
for len(queue) == 0 {
cond.Wait()
}
item := queue[0]
queue = queue[1:]
fmt.Println("Consume:", item)
if len(queue) == capacity-1 {
cond.Signal()
}
mu.Unlock()
}
}()
wg.Wait()
}
在这个例子中,我们定义了一个长度为 5 的队列,然后创建了两个协程,一个用来生产数据,另一个用来消费数据。
在协程中,使用 sync.Mutex 和 sync.Cond 对象来保护和同步共享资源。
在生产者协程中,首先调用 mu.Lock() 获取互斥锁,然后使用 for 循环判断队列是否已满,
- 如果已满则调用 cond.Wait() 阻塞当前协程,等待消费者协程唤醒。
- 如果队列未满,则将数据插入队列并打印生产的数据。
在插入数据后,如果队列原来为空,则调用 cond.Signal() 唤醒一个正在等待条件变量的协程。最后,使用 mu.Unlock() 释放互斥锁。
在消费者协程中,首先调用 mu.Lock() 获取互斥锁,然后使用 for 循环判断队列是否为空
- 如果为空则调用 cond.Wait() 阻塞当前协程,等待生产者协程唤醒。
- 如果队列非空,则取出队头元素并打印消费的数据。
在取出数据后,如果队列原来已满,则调用 cond.Signal() 唤醒一个正在等待条件变量的协程。
最后,使用 mu.Unlock() 释放互斥锁。
channel 通道
除了标准库 sync 包提供了协程 同步能力,还可以使用channel 来实现。
channel 是一种特殊的数据类型,可以用来在协程之间传递数据,并且能够实现阻塞式等待和唤醒功能。
channel 通道(/信道)的两个基本操作
和映射与切片一样,channel 通道在使用前必须创建:
ch := make(chan int)
使用 make 函数创建 channel 时,第一个参数为 channel 类型,第二个参数为缓冲区大小(可选)。注意,第二个参数是可选的。
channel 通道在创建的时候, 类型参数表示 通道里边 值的类型。所以,通道是带有类型的管道,你可以通过它用信道操作符 <- 来发送或者接收值。
ch <- v // 将 v 发送至信道 ch。
v := <-ch // 从 ch 接收值并赋予 v。
“箭头” <- 就是数据流的方向。默认情况下,发送和接收操作在另一端准备好之前都会阻塞。这使得 Go 程可以在没有显式的锁或竞态变量的情况下进行同步。
在使用 channel 进行同步时,一般有两种基本的操作:
- 发送数据到 channel:通过 channel 的 <- 操作符向其中发送一个值,例如:
ch <- "hello"
- 从 channel 接收数据:通过 channel 的 <- 操作符从其中接收一个值,例如:
msg := <- ch
当调用 <- 操作符时,如果 channel 中没有数据可用,则当前协程会被阻塞,直到有数据可用为止。
下面是一个使用 channel 实现协程同步的例子:
func main() {
ch := make(chan string)
go func() {
fmt.Println("Sending message...")
ch <- "Hello, world!"
fmt.Println("Message sent!")
}()
msg := <- ch
fmt.Println("Received message:", msg)
}
在这个例子中,我们创建了一个字符串类型的 channel,然后启动了一个新的协程。
在协程中,先打印一条信息表示正在发送消息,然后将消息发送到 channel 中。发送完成后,再打印一条信息表示消息已经发送完毕。
在主程序中,我们等待从 channel 中接收到消息,并将其保存到变量 msg 中。接收到消息后,再打印一条信息表示已经接收到了消息,并输出这个消息的内容。
注意,在这个例子中,主程序会被阻塞,直到从 channel 中接收到了消息为止。就是这句:
msg := <- ch
这是因为主程序使用 <- ch 操作符从 channel 中接收数据时,如果 channel 中没有数据可用,它会一直阻塞等待,直到有数据可用为止。
附录:make 函数如何使用?
在 Go 中,make 函数用于创建一个类型为 slice、map 或 channel 的对象,并返回其引用。make 函数的语法如下:
make(Type, size)
其中 Type 表示要创建的对象类型,size 则表示对象大小或缓冲区大小(仅适用于 channel)。具体来说,make 函数有以下三种用法:
1.创建 slice:使用 make 函数创建 slice 时,第一个参数为 slice 类型,第二个参数为 slice 的长度(数量),第三个参数为 slice 的容量(可选)。例如:
// 创建长度为 10,容量为 20 的 int 类型 slice
s := make([]int, 10, 20)
2.创建 map:使用 make 函数创建 map 时,第一个参数为 map 类型,不需要指定大小。例如:
// 创建 string 到 int 的映射表
m := make(map[string]int)
3.创建 channel:使用 make 函数创建 channel 时,第一个参数为 channel 类型,第二个参数为缓冲区大小(可选)。例如:
// 创建一个无缓冲的 channel
ch := make(chan string)
// 创建一个可以缓存 10 个字符串的 channel
ch := make(chan string, 10)
除此之外,make 函数还可以用于创建一些类型的值,例如 string、array 和 struct 等。
但是,在这些情况下,通常更推荐使用字面量语法来创建相应的值。
range遍历 和 通道关闭 close
在 Go 中,可以使用 close 函数来关闭通道。关闭通道后,发送方不能再向通道中发送数据,但是接收方仍然可以从通道中接收数据,直到通道中所有的数据都被读取完毕。
如果要关闭通道,生产者/发送者可通过 close 函数关闭一个信道,来表示没有需要发送的值了。
close函数的使用方法,非常简单,具体如下:
close(ch)
消费者/接收者如何判定呢?
在消费的时候, 可以通过接收表达式返回的第二个参数,来测试信道是否被关闭, 两个返回值版本的接收表达式如下:
v, ok := <-ch
若两个返回值中,如果没有值可以接收、且信道已被关闭,第一个值为0值,第二个值 ok 会被设置为 false。
其中 ok 是一个 bool 类型,可以通过它来判断 channel 是否已经关闭,如果 channel 关闭该值为 false ,此时 v 接收到的是 channel 类型的零值。比如:channel 是传递的 int, 那么 v 就是 0 ;如果是结构体,那么 v 就是结构体内部对应字段的零值。
注意:
- 只有发送者才能关闭信道,而接收者不能。
- 向一个已经关闭的信道发送数据会引发程序恐慌(panic)。
在 Go 中,可以使用 range 来遍历通道中的数据。使用 range 遍历通道时,会一直等待通道中有新的数据可读取,直到通道被关闭或者显式地使用 break 终止循环。
简单来说,循环 for i := range c 会不断从信道接收值,直到它被关闭。
还要注意: 信道与文件不同,通常情况下无需关闭它们。只有在必须告诉接收者不再有需要发送的值时才有必要关闭,例如终止一个 range 循环。
下面是一个使用 range 遍历通道的示例:
import (
"fmt"
"time"
)
func main() {
ch := make(chan int)
go func() {
for i := 0; i < 5; i++ {
ch <- i
time.Sleep(time.Second)
}
close(ch)
}()
for x := range ch {
fmt.Println("Received:", x)
}
fmt.Println("Done")
}
在这个例子中,我们创建了一个无缓冲的 channel ch,并启动了一个协程向 ch 中发送数据。
在主程序中,使用 range 遍历 ch 中的数据,并打印接收到的数据。
当协程向 ch 中发送完数据后,通过 close 函数关闭 ch。
在使用 range 遍历通道时,如果通道未关闭,则循环会一直等待直到通道被关闭。当通道被关闭后,循环会自动终止,无需使用其他方式来判断通道是否已经关闭。同时,如果在循环中使用 break 终止循环,则需要注意在终止前将通道关闭,否则可能会导致死锁等问题。
需要注意的是,使用 range 遍历通道时,如果通道中已经没有数据可读取,则循环会被阻塞,直到有新的数据可读取或者通道被关闭。因此,在使用 range 遍历通道时,需要确保在发送方将所有数据发送完毕后及时关闭通道,否则可能会导致循环一直阻塞等待。
close Channel 的一些说明
channel 不需要通过 close 来释放资源,这个是它与 socket、file 等不一样的地方,对于 channel 而言,唯一需要 close 的就是我们想通过 close 触发 channel 读事件。
- close channel对 channel阻塞无效,写了数据不读,直接 close,还是会阻塞的。
- 如果 channel 已经被关闭,继续往它发送数据会导致 panic
send on closed channel - closed 的 channel,再次关闭 close 会 panic
- close channel 的推荐使用姿势是在发送方来执行,因为 channel 的关闭只有接收端能感知到,但是发送端感知不到,因此一般只能在发送端主动关闭。而且大部分时候可以不执行 close,只需要读写即可。
- 从一个已经 close 的 channel中读取数据,是可以读取的,读到的数据为 0
- 读取的 channel 如果被关闭,并不会影响正在读的数据,它会将所有数据读取完毕,在读取完已发送的数据后会返回元素类型的零值(zero value)。
多通道查询select 语句/通道的多路复用
select 语句使一个 Go 程可以等待多个channel通信操作。
select 会阻塞到某个分支可以继续执行为止,这时就会执行该分支。当多个分支都准备好时会随机选择一个执行。
在 Go 中,可以使用 select 语句来等待多个 channel 中的数据,并执行相应的操作。
当有多个 channel 中的数据可读取时,select 语句会随机选择一个可用的 channel,并执行对应的操作。
下面是一个示例代码,演示如何使用 select 语句查询多个 channel 中的数据:
import (
"fmt"
"time"
)
func main() {
ch1 := make(chan int)
ch2 := make(chan string)
go func() {
for i := 0; i < 5; i++ {
ch1 <- i
time.Sleep(time.Second)
}
}()
go func() {
for i := 0; i < 5; i++ {
ch2 <- fmt.Sprintf("Message %d", i)
time.Sleep(time.Second)
}
}()
for i := 0; i < 10; i++ {
select {
case x := <-ch1:
fmt.Println("Received from ch1:", x)
case x := <-ch2:
fmt.Println("Received from ch2:", x)
}
}
fmt.Println("Done")
}
在这个示例代码中,我们创建了两个 channel ch1 和 ch2,分别用于发送 int 类型和 string 类型的数据。
在两个协程中,分别向 ch1 和 ch2 中发送数据,并间隔一秒钟。
在主函数中,使用 select 语句查询 ch1 和 ch2 中的数据,并打印接收到的数据。在循环中共查询 10 次,由于两个协程的间隔时间不同,因此可能会先从 ch1 中接收到数据,也可能会先从 ch2 中接收到数据。最后,当所有数据被读取完毕后,程序输出 Done。
需要注意的是,在使用 select 语句查询多个 channel 时,如果多个 channel 同时有数据可读取,则随机选择一个 channel,并执行对应的操作。
因此,在设计程序逻辑时,需要考虑到 channel 的使用顺序可能会发生变化。此外,如果在 select 语句中同时等待多个 channel,而其中一个 channel 被关闭了,则程序仍然会等待其它的 channel,并在有数据可读取时执行相应的操作。
Go的select 和 OS的select 对比
Go语言中的select 和操作系统中的系统调用select比较相似。
C语言的select系统调用可以同时监听多个文件描述符的可读或者可写的状态,Go 语言的select可以让Goroutine同时等待多个Channel可读或可写,在多个文件或Channel状态改变之前,select会一直阻塞当前线程或Goroutine。
select是与switch相似的控制结构,不过select的case中的表达式必须都是channel的收发操作。当select中的多个case同时被触发时,会随机执行其中一个。
通常情况下,select语言会阻塞goroutine并等待多个Channel中的一个达到可以收发的状态。但如果有default语句,可以实现非阻塞,就是当多个channel都不能执行的时候,运行default。
非阻塞查询
select 默认是阻塞的,如果所有的通道都没有数据,那么 函数就会被阻塞。
如何不进行阻塞呢? 在 Go 中,select 语句还可以使用 default 分支,用于在没有任何 channel 可读取时执行默认操作。当所有被查询的 channel 都没有数据可读取时,select 会立即执行 default 分支,从而实现不会被阻塞。
换句话来说,当 select 中的其它分支都没有准备好时,default 分支就会执行。所以,为了在尝试在接收时不发生阻塞,可使用 default 分支, 使用的方式如下:
select {
case i := <-c:
// 使用 i
default:
// 从 c 中接收会阻塞时执行
}
下面是一个示例代码,演示如何使用 default 分支:
import (
"fmt"
"time"
)
func main() {
ch := make(chan int)
go func() {
time.Sleep(time.Second * 3)
close(ch)
}()
for {
select {
case x, ok := <-ch:
if !ok {
fmt.Println("Channel closed")
return
}
fmt.Println("Received:", x)
default:
fmt.Println("No data received")
time.Sleep(time.Second)
}
}
fmt.Println("Done")
}
在这个示例代码中,我们创建了一个无缓冲的通道 ch,并在一个协程中等待 3 秒钟后关闭通道。
在主函数中,使用 select 语句监听 ch 中的数据,并打印接收到的数据。
由于 ch 一开始并没有数据可读取,因此 select 会立即执行 default 分支,并打印提示信息。在 ch 被关闭后,通过判断第二个返回值 ok 的值来确定通道是否已经关闭。如果通道已经关闭,则跳出循环并输出结束信息。
需要注意的是,在使用 default 分支时,需要考虑到程序的实际需求,并合理设置等待时长。
如果等待时间过短,则可能会频繁地执行 default 分支,导致性能损失;如果等待时间过长,则可能会导致数据延迟等问题。
此外,在使用 default 分支时,需要注意区分通道中的零值和通道已经关闭两种情况,以避免出现不必要的错误。
带缓冲的通道
在 Go 中,可以使用带缓冲的 channel 来实现协程之间的同步和通信。channel 可以是 带缓冲的。
如何创建带缓冲通道呢? 将缓冲长度作为第二个参数提供给 make 来初始化一个带缓冲的信道
在创建带缓冲的 channel 时,需要在 channel 类型后面添加一个整数,表示缓冲区大小。例如:
// 创建一个可以缓存 10 个字符串的 channel
ch := make(chan string, 10)
在这个例子中,我们创建了一个可以缓存 10 个字符串的 channel ch。
- 当有协程向 ch 发送数据时,如果缓冲区未满,则可以直接将数据写入缓冲区;否则,发送操作会被阻塞,直到有协程从 ch 中读取数据为止。
- 同样地,当有协程从 ch 中读取数据时,如果缓冲区非空,则可以直接从缓冲区读取数据;否则,接收操作会被阻塞,直到有协程向 ch 中发送数据为止。
带缓冲的通道的特点是:
- 仅当信道的缓冲区填满后,向其发送数据时才会阻塞。
- 当缓冲区为空时,接受方会阻塞。
带缓冲的 channel 是一种有固定缓冲区大小的 channel,当缓冲区满时,向 channel 发送数据会被阻塞,直到有协程从 channel 中接收数据为止。相反,当缓冲区为空时,从 channel 接收数据也会被阻塞,直到有协程向 channel 中发送数据为止。
下面是一个使用带缓冲的 channel 实现生产者-消费者模型的例子:
import (
"fmt"
)
const capacity = 5
func main() {
ch := make(chan int, capacity)
done := make(chan bool)
// 生产者协程
go func() {
for i := 0; i < capacity*2; i++ {
ch <- i
fmt.Println("Produce:", i)
}
done <- true
}()
// 消费者协程
go func() {
for i := 0; i < capacity*2; i++ {
item := <-ch
fmt.Println("Consume:", item)
}
done <- true
}()
<-done
<-done
}
在这个例子中,我们创建了一个缓冲区大小为 5 的 channel ch,然后创建了两个协程,一个用来生产数据(向 ch 中发送数据),另一个用来消费数据(从 ch 中接收数据)。
当所有数据都被生产和消费完毕后,使用两个 done channel 来通知主程序结束。
在生产者协程中,首先向 ch 中发送数据,并打印生产的数据。如果缓冲区已满,则发送操作会被阻塞,等待消费者协程从 ch 中读取数据。在最后一个数据被生产和发送完毕后,通过 done channel 向主程序发送结束信号。
在消费者协程中,首先从 ch 中接收数据,并打印消费的数据。如果缓冲区为空,则接收操作会被阻塞,等待生产者协程向 ch 中发送数据。在最后一个数据被消费完毕后,通过 done channel 向主程序发送结束信号。
Java BlockingQueue 和 Go channel 对比学习
Java 中的 BlockingQueue 和 Go 中的 channel 都是用于实现线程之间的通信的工具,但是它们在一些方面存在差异 , 主要有3点:
- 1:实现方式
Java 中的 BlockingQueue 是一个接口,它有多个不同的实现类,如 ArrayBlockingQueue、LinkedBlockingQueue 等。这些实现类都是基于数组或链表等数据结构实现的,提供了一些阻塞式的队列操作方法。
Go 中的 channel 是语言内置的类型,直接由编译器实现。在底层,channel 是使用 waitgroup、mutex、cond 等同步原语实现的,而不是基于数据结构实现的。
- 2:缓存机制
Java 的 BlockingQueue 有两种类型:有界阻塞队列和无界阻塞队列。有界阻塞队列的大小是固定的,当队列元素数量达到上限时,生产者线程会被阻塞,直到队列中有空位。无界阻塞队列没有容量限制,在添加元素时不会被阻塞,但是获取元素时可能会被阻塞。
Go 的 channel 也可以分为两种类型:带缓存的 channel 和非缓存的 channel。带缓存的 channel 可以缓存一定数量的元素,当缓冲区满时,发送操作会被阻塞。非缓存的 channel 不允许缓存元素,每个元素只能被发送和接收一次。
- 3:阻塞机制
Java 的 BlockingQueue 提供了多种阻塞式队列操作方法,如 put 和 take 等。其中,put 方法会在队列已满时阻塞直到有空位,而 take 方法会在队列为空时阻塞直到有元素可取。
Go 的 channel 通过阻塞操作实现协程之间的同步和通信。当发送或接收操作无法进行时,协程会被阻塞,并暂停执行,直到对应的操作可以进行为止。
Java 的 BlockingQueue 和 Go 的 channel 在实现方式和应用场景不同,但是它们也有一些相同点。主要有4点:
- 1:用途相同
Java 的 BlockingQueue 和 Go 的 channel 都是用于协程之间的通信和同步。它们允许多个协程在不同的时间段进行读写操作,并提供了阻塞式的方法来确保线程安全和正确性。
- 2:阻塞机制相同
Java 的 BlockingQueue 和 Go 的 channel 都通过阻塞操作来实现协程之间的同步。当队列为空或已满时,生产者线程和消费者线程都会被阻塞,直到对应的条件得到满足为止。
- 3:线程安全性相同
Java 的 BlockingQueue 和 Go 的 channel 都是线程安全的。它们都提供了阻塞式的方法,可以确保多个协程在不同的时间段进行读写操作时不会发生竞态条件等问题。
- 4:可靠性相同
Java 的 BlockingQueue 和 Go 的 channel 都是可靠的。它们都能够确保协程之间的通信和同步。同时,在使用过程中也可以通过异常捕获等方法来处理潜在的错误,并保证程序的正确性和健壮性。
综上所述,Java 的 BlockingQueue 和 Go 的 channel 在用途、阻塞机制、线程安全性和可靠性等方面存在相同点,这些共同点也是它们成为编写多线程程序时的优秀工具的原因之一。
SynchronousQueue VS 无缓冲channel
go 中channel 分为缓冲通道和非缓冲通道(容量为0)。
Go 语言的无缓冲channel,只有在发送操作和接收操作配对上了,发送方和接收方才能得以继续执行,否则将会阻塞在发送或者接收操作。
Go 语言的无缓冲channel,本质上就是以同步的方式来传递数据。
所以, Go 语言的无缓冲channel 正是 Java 中的 SynchronousQueue 具有的特性。
| 零容量 无缓冲 | 有限容量 | |
|---|---|---|
| Go | unbuffered channel | buffered channel |
| Java | SynchronousQueue | LinkedBlockingQueue |
LinkedBlockingQueue VS 缓冲通道 buffered channel
缓冲通道,顾名思义,就是能起到缓冲作用的数据类型。
相对于非缓冲通道发送操作如果没有配对的接收操作则会阻塞的情况,缓冲通道在容量未满的时候允许发送操作发送成功之后立即执行后续的操作而不阻塞。
Java 中的 LinkedBlockingQueue 也具有这一特性,从命名来看就是底层基于链表的阻塞队列。
操作对比
Go中,可以使用 len 获取通道的 长度,cap 函数 获取通道的 容量,下面是一个例子:
unbufChan := make(chan int) // 创建一个非缓冲通道
fmt.Printf("容量为%d\n", cap(unbufChan)) // 容量为0
fmt.Printf("长度为%d\n", len(unbufChan)) // 长度为0
bufChan := make(chan int, 8) // 创建一个缓冲通道
fmt.Printf("容量为%d\n", cap(bufChan)) // 容量为8
fmt.Printf("长度为%d\n", len(bufChan)) // 长度为0
bufChan <- 1
fmt.Printf("容量为%d\n", cap(bufChan)) // 容量为8
fmt.Printf("长度为%d\n", len(bufChan)) // 长度为1
对于 Go 语言的非缓冲通道,其容量也总是为0
其中队列(或通道)的长度代表它当前包含的元素值的个数。当队列(或通道)已满时,其长度与容量相同。
SynchronousQueue VS 无缓冲channel 的长度和 容量比较:
| 容量 | 长度 | 剩余容量 | |
|---|---|---|---|
| SynchonousQueue | 0 | 0 | 0 |
| unbuffered channel | 0 | 0 | 0 |
LinkedBlockingQueue VS 缓冲通道 buffered channel 的长度和 容量比较:
| 容量 | 长度 | 剩余容量 | |
|---|---|---|---|
| LinkedBlockingQueue | 构造函数指定的capacity | size() | remainingCapacity() |
| buffered channel | cap(ch) | len(ch) | cap(ch) - len(ch) |
其中队列(或通道)的长度代表它当前包含的元素值的个数。当队列(或通道)已满时,其长度与容量相同。
go rocketmq 编程
Apache RocketMQ 是一个开源的、分布式的消息中间件系统,支持高吞吐量和高可用性的消息传递。
在 Go 编程中,可以使用 Apache RocketMQ 的 Go 客户端来实现与 RocketMQ 的交互。
golang 模块安装
go get github.com/apache/rocketmq-client-go/v2
尼恩提示:
在 goland 工具中的 模块安装过程,请参考后面的附录。
实例:使用 RocketMQ 的 Go 客户端来发送和接收消息
下面是一个简单的示例代码,演示如何使用 RocketMQ 的 Go 客户端来发送和接收消息:
package batchprocess
import (
"context"
"fmt"
"github.com/apache/rocketmq-client-go/v2"
"log"
"time"
"github.com/apache/rocketmq-client-go/v2/consumer"
"github.com/apache/rocketmq-client-go/v2/primitive"
"github.com/apache/rocketmq-client-go/v2/producer"
)
// 创建生产者
const NAME_NODE = "192.168.56.121:9876"
const TOPIC = "test"
func RocketMQDemo() {
producer, err := rocketmq.NewProducer(
producer.WithNameServer([]string{NAME_NODE}),
producer.WithRetry(2),
)
if err != nil {
fmt.Println("create producer error:", err)
return
}
err = producer.Start()
if err != nil {
fmt.Println("start producer error:", err)
return
}
defer producer.Shutdown()
// 发送消息
for i := 0; i < 10; i++ {
msg := &primitive.Message{
Topic: TOPIC,
Body: []byte("Hello RocketMQ"),
}
res, err := producer.SendSync(context.Background(), msg)
if err != nil {
log.Printf("send message error: %v\n", err)
} else {
log.Printf("send message success: %v\n", res)
}
time.Sleep(time.Second)
}
// 创建消费者
c, err := rocketmq.NewPushConsumer(
consumer.WithNameServer([]string{NAME_NODE}),
consumer.WithGroupName("test-group"),
)
if err != nil {
fmt.Println("create consumer error:", err)
return
}
err = c.Subscribe(TOPIC, consumer.MessageSelector{},
func(ctx context.Context, msgs ...*primitive.MessageExt) (consumer.ConsumeResult, error) {
for _, msg := range msgs {
log.Printf("receive message: topic=%s, body=%s\n",
msg.Topic, string(msg.Body))
}
return consumer.ConsumeSuccess, nil
})
if err != nil {
fmt.Println("subscribe error:", err)
return
}
err = c.Start()
if err != nil {
fmt.Println("start consumer error:", err)
return
}
defer c.Shutdown()
time.Sleep(time.Second * 10)
}
在这段代码中,首先生产者并用其向 RocketMQ 中的 test 主题发送了一条消息。然后创建了一个消费者,订阅了 test 主题,并在回调函数中处理接收到的消息。
在这个示例中,首先创建了一个 RocketMQ 生产者,并通过 WithNameServer 和 WithRetry 分别设置了 NameServer 地址和重试次数等配置项。
然后,在循环中创建了一个消息对象,并调用 SendSync 方法发送同步消息。该方法的第一个参数是上下文对象,可以使用 context.Background() 创建;第二个参数是消息对象。如果发送成功,则返回一个 SendResult 对象,否则返回一个非空的错误对象。
最后,使用 time.Sleep() 方法等待一秒钟,以便观察发送结果。在真实的应用程序中,可以根据需要调整等待时间。
综上所述,在 RocketMQ 的 Go 版本客户端 rocketmq-client-go 中,可以使用 SendSync 方法发送同步消息,并通过返回值和错误对象获取发送结果。
需要注意的是: 在使用 RocketMQ 的 Go 客户端时,必须先安装和配置好 RocketMQ 的服务端,并将 Go 客户端库引入到项目中。同时,也需要根据实际情况进行配置和参数设置,以确保程序能够正常运行。
消息发送和接受的验证
启动 rocketmq
使用尼恩的一键启动环境

启动之后的效果
启动 go 实例
package main
import (
"crazymakercircle.com/awesomeProject/batchprocess"
"fmt"
)
func main() {
fmt.Println("\tcocurrent RocketMQDemo :")
//cocurrent.GoroutineDemo()
fmt.Println("\tcocurrent MutexDemo :")
batchprocess.RocketMQDemo()
}
使用goland 直接执行
发送消息效果

消费消息效果

附录:Go 模块的安装和使用
Go 模块是 Go 语言1.11版本后引入的官方包管理工具,可以自动管理依赖项和版本。
一个模块是一些以版本作为单元相关的包的集合。模块记录精确的依赖要求并创建可复制的构建。
通常,版本控制存储库仅包含在存储库根目录中定义的一个模块。(单个存储库中支持多个模块,但是通常,与每个存储库中的单个模块相比,这将导致正在进行的工作更多)。
总结存储库,模块和软件包之间的关系:
- 一个存储库包含一个或多个Go模块。
- 每个模块包含一个或多个Go软件包。
- 每个软件包都在一个目录中包含一个或多个Go源文件。
下面是使用 Go 模块安装和管理第三方库的步骤:
启用 Go 模块
在使用 Go 模块之前,需要先启用 Go 模块功能。
可以通过设置 GO111MODULE 环境变量来控制 Go 是否使用模块。要启用模块,请将该环境变量设置为 on,例如:
$ export GO111MODULE=on
创建新项目
在开始开发项目之前,需要创建一个新的项目目录,并在其中初始化 Go 模块。
可以使用 go mod init 命令来完成初始化操作,例如:
$ go mod init crazymakercircle.com/awesomeProject

这个命令会创建一个新的 Go 模块,并在当前目录中生成一个名为 go.mod 的文件。
打开看看
go.mod
模块由Go源文件树定义,该go.mod文件在树的根目录中。模块源代码可能位于GOPATH之外。
在 Go 1.11 版本之后,Go 引入了官方的包管理工具 Go modules。使用 Go modules 可以更好地管理项目中的依赖项和版本,避免了 GOPATH 和 vendor 目录等传统的包管理方式中存在的一些问题。
在使用 Go modules 时,需要在项目根目录中创建一个名为 go.mod 的文件,并在其中定义模块路径和依赖项等信息。
下面是一个示例的 go.mod 文件:
module example.com/myproject
go 1.16
require (
github.com/gin-gonic/gin v1.7.4
github.com/go-sql-driver/mysql v1.6.0
)
在这个文件中,第一行指定了当前模块的名称,即 example.com/myproject。
注意,这个名称应该是唯一的,以便其他项目可以引用该模块。
第二行指定了所使用的 Go 版本,即 go 1.16。
下面的 require 块定义了所有依赖项及其版本信息。
每个依赖项都由一个完整的包名称和版本号组成,例如 github.com/gin-gonic/gin v1.7.4。这个版本号表示需要使用的确切版本,也可以使用语义化版本号范围来指定版本,例如 github.com/gin-gonic/gin v1.7.x。
mod文件 有四种指令:module,require,replace,exclude。
在 Go modules 中,一个模块可以包含多个软件包,每个软件包都有一个唯一的导入路径。这个导入路径由模块路径和从 go.mod 到软件包目录的相对路径共同确定。
假设有一个名为 example.com/myproject 的模块,其中包含两个软件包 foo 和 bar,它们的目录结构如下:
myproject/
|- go.mod
|- foo/
|- foo.go
|- bar/
|- bar.go
在这个例子中,软件包 foo 的导入路径为 example.com/myproject/foo,软件包 bar 的导入路径为 example.com/myproject/bar。
这个导入路径由模块路径 example.com/myproject 和相对路径 foo 或 bar 共同组成。
注意,在 Go modules 中,所有软件包的导入路径都将模块路径共享为公共前缀。这个公共前缀可以帮助防止命名冲突和混淆。
总之,模块中所有软件包的导入路径是由模块路径和从 go.mod 到软件包目录的相对路径共同决定的。对于不同的软件包,它们的相对路径是不同的,但它们共享相同的模块路径前缀。
安装第三方库
在 Go 模块中安装第三方库与在传统的 GOPATH 中安装方式略有不同。可以使用 go get 命令来安装第三方库并将其添加到当前项目的依赖项中,例如:
$ go get github.com/gin-gonic/gin@v1.7.4
这个命令会下载指定版本的 gin 库,并将其添加到当前项目的依赖项中。
go get github.com/apache/rocketmq-client-go/v2
此外,还可以使用 go get 命令下载最新版本的库,并将其添加到依赖项中,例如:
$ go get github.com/gin-gonic/gin
这个命令会下载指定版本的 rocketmq-client-go库,并将其添加到当前项目的依赖项中。
比如,安装 RocketMQ client 依赖
go get github.com/apache/rocketmq-client-go/v2

如果下载不来,或者设置代理试试,打开你的终端并执行(Go 1.13 及以上)
go env -w GO111MODULE=on
go env -w GOPROXY=https://goproxy.cn,direct
下载依赖项
当安装了第三方库后,还需要将其下载到本地计算机上。
可以使用 go mod download 命令来下载所有依赖项,例如:
$ go mod download
这个命令会下载当前项目依赖的所有库及其版本。
管理依赖项
在开发过程中,可能需要升级或删除某些依赖项。可以使用 go mod tidy 命令来清理不再使用的依赖项,例如:
$ go mod tidy
这个命令会分析项目代码并移除未使用的库。
同时,还可以使用 go get -u 命令来升级依赖项到最新版本,例如:
$ go get -u github.com/gin-gonic/gin
这个命令会下载并安装 gin 库的最新版本,并更新 go.mod 文件中的版本号。
综上所述,使用 Go 模块安装和管理第三方库非常方便,可以自动解决依赖关系和版本问题,大大简化了项目的依赖管理。
GoLand 中使用 Go 模块(go mod)管理依赖项
在 GoLand 中使用 Go 模块(go mod)管理依赖项,可以通过以下步骤进行操作:
打开或创建一个 Go 项目
在 GoLand 中打开或创建一个 Go 项目,并确保该项目启用了 Go 模块功能。
要启用 Go modules,可以通过菜单栏中的 File > Settings > Go > Go Modules 来启用 Go modules。
在这个对话框中,可以选择全局或项目级别的 Go modules 设置。建议选择项目级别的设置,以避免影响其他项目。

初始化 Go modules
在启用 Go modules 后,需要初始化 Go modules。可以在终端中切换到项目目录,然后执行以下命令来初始化 Go modules:
go mod init crazymakercircle.com/awesomeProject
这个命令会创建一个新的 Go 模块,并在当前目录中生成一个名为 go.mod 的文件。

添加依赖项
在 GoLand 中添加依赖项非常简单。可以使用 go get 命令来安装第三方库并将其添加到当前项目的依赖项中。例如,在 GoLand 的终端窗口中输入以下命令:
$ go get github.com/gin-gonic/gin
这个命令会下载并安装 Gin HTTP 框架,并将其添加到 go.mod 文件中。在此之后,即可在代码中引用 gin 库。
比如,安装 RocketMQ client 依赖
go get github.com/apache/rocketmq-client-go/v2

解决require内依赖全部飘红问题
解决go.mod文件中require内依赖全部飘红

设置 go 模块化,并设置环境变量 GOPROXY=https://goproxy.cn,direct

ok了

管理依赖关系
在开发过程中,可能需要升级或删除某些依赖项。可以使用 go get -u 命令来升级依赖项到最新版本,并更新 go.mod 文件中的版本号,例如:
$ go get -u github.com/gin-gonic/gin
除此之外,还可以使用 GoLand 自带的依赖关系管理工具,包括自动生成和维护 go.mod 和 go.sum 文件、自动提示缺失的依赖项以及检查依赖项的版本等。
比如:
go get -u github.com/apache/rocketmq-client-go/v2
构建和运行项目
在完成依赖项的添加和管理后,即可构建和运行项目。可以使用 GoLand 的集成工具来构建和运行项目,例如:
- 点击菜单栏中的 Run 按钮或使用快捷键 Shift + F10 来运行程序;
- 在编辑器窗口中右键单击并选择 Run ‘main’ 选项来运行程序;
- 在终端中输入
go build命令来编译项目,并使用./<executable>命令来运行可执行文件。
综上所述,GoLand 提供了便捷的工具来支持使用 Go 模块管理依赖项,包括自动化生成和维护 go.mod 和 go.sum 文件、自动提示缺失的依赖项以及检查依赖项的版本等,大大简化了项目的依赖管理。
gorm 操作mysql
什么是ORM?
ORM框架操作数据库都需要预先定义模型,模型可以理解成数据模型,作为操作数据库的媒介。
例如:
- 从数据库读取的数据会先保存到预先定义的模型对象,然后我们就可以从模型对象得到我们想要的数据。
- 插入数据到数据库也是先新建一个模型对象,然后把想要保存的数据先保存到模型对象,然后把模型对象保存到数据库。
在golang中gorm模型定义是通过struct实现的,这样我们就可以通过gorm库实现struct类型和mysql表数据的映射。
提示:gorm负责将对模型的读写操作翻译成sql语句,然后gorm再把数据库执行sql语句后返回的结果转化为我们定义的模型对象。
gorm介绍
GORM是Golang目前比较热门的数据库ORM操作库,对开发者也比较友好,使用非常方便简单,使用上主要就是把struct类型和数据库表记录进行映射,操作数据库的时候不需要直接手写Sql代码,
GORM库github地址: https://github.com/go-gorm/gorm
gorm安装
操作MySQL需要安装两个包:
- MySQL驱动包
- GORM包 使用go get命令安装依赖包
//安装MySQL驱动
go get -u gorm.io/driver/mysql
//安装gorm包
go get -u gorm.io/gorm

go.md里边,加了依赖
导入包
import (
"bytes"
"fmt"
_ "gorm.io/driver/mysql"
_ "gorm.io/gorm"
"sync"
"time"
)
gorm模型定义
gorm模型定义主要就是在struct类型定义的基础上增加字段标签说明实现,下面看个完整的例子。
假如有个sample表,表结构如下
CREATE TABLE `sample` (
`id` int(11) NOT NULL COMMENT '主键' ,
`title` varchar(255) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL COMMENT '标题' ,
`create_time` datetime NULL DEFAULT NULL COMMENT '创建时间' ,
PRIMARY KEY (`id`)
)
ENGINE=InnoDB
DEFAULT CHARACTER SET=utf8 COLLATE=utf8_bin
ROW_FORMAT=DYNAMIC
;
模型定义如下
//字段注释说明了gorm库把struct字段转换为表字段名长什么样子。
type Sample struct {
Id int64 //表字段名为:id
Title string //表字段名为:title
//字段定义后面使用两个反引号``包裹起来的字符串部分叫做标签定义,这个是golang的基础语法,不同的库会定义不同的标签,有不同的含义
CreateTime int64 `gorm:"column:create_time"` //表字段名为:create_time
}
默认gorm对struct字段名使用Snake Case命名风格转换成mysql表字段名(需要转换成小写字母)。
根据gorm的默认约定,上面例子只需要使用gorm:"column:create_time"标签定义为CreateTime字段指定表字段名,其他使用默认值即可。
提示:Snake Case命名风格,就是各个单词之间用下划线(_)分隔,例如: CreateTime的Snake Case风格命名为create_time
3、gorm模型标签
通过上面的例子,大家看到可以通过类似gorm:"column:createtime"这样的标签定义语法,定义struct字段的列名(表字段名)。
gorm标签语法:gorm:"标签定义"
标签定义部分,多个标签定义可以使用分号(;)分隔,例如定义列名:
gorm:"column:列名"
gorm常用标签如下:
| 标签 | 说明 | 例子 |
|---|---|---|
| column | 指定列名 | gorm:“column:createtime” |
| primaryKey | 指定主键 | gorm:“column:id; PRIMARY_KEY” |
| - | 忽略字段 | gorm:“-” 可以忽略struct字段,被忽略的字段不参与gorm的读写操作 |
定义表名
可以通过定义struct类型的TableName函数实现定义模型的表名
接上面的例子:
//设置表名,可以通过给Food struct类型定义 TableName函数,返回一个字符串作为表名
func (v Sample) TableName() string {
return "sample"
}
建议:
默认情况下都给模型定义表名,有时候定义模型只是单纯的用于接收手写sql查询的结果,这个时候是不需要定义表名;手动通过gorm函数Table()指定表名,也不需要给模型定义TableName函数。
gorm.Model
GORM 定义一个 gorm.Model 结构体,其包括字段 ID、CreatedAt、UpdatedAt、DeletedAt。
// gorm.Model 的定义
type Model struct {
ID uint `gorm:"primaryKey"`
CreatedAt time.Time
UpdatedAt time.Time
DeletedAt gorm.DeletedAt `gorm:"index"`
}
以将它嵌入到我们的结构体中,就以包含这几个字段,类似继承的效果。
type User struct {
gorm.Model // 嵌入gorm.Model的字段
Name string
}
自动更新时间
GORM 约定使用 CreatedAt、UpdatedAt 追踪创建/更新时间。
如果定义了这种字段,GORM 在创建、更新时会自动填充当前时间。
要使用不同名称的字段,您可以配置 autoCreateTime、autoUpdateTime 标签
如果想要保存 UNIX(毫/纳)秒时间戳,而不是 time,只需简单地将 time.Time 修改为 int 即可。
例子:
type User struct {
CreatedAt time.Time // 默认创建时间字段, 在创建时,如果该字段值为零值,则使用当前时间填充
UpdatedAt int // 默认更新时间字段, 在创建时该字段值为零值或者在更新时,使用当前时间戳秒数填充
Updated int64 `gorm:"autoUpdateTime:nano"` // 自定义字段, 使用时间戳填纳秒数充更新时间
Updated int64 `gorm:"autoUpdateTime:milli"` //自定义字段, 使用时间戳毫秒数填充更新时间
Created int64 `gorm:"autoCreateTime"` //自定义字段, 使用时间戳秒数填充创建时间
}
gorm连接数据库
gorm支持多种数据库,这里主要介绍mysql,连接mysql主要有两个步骤:
1)配置DSN (Data Source Name)
2)使用gorm.Open连接数据库
1、配置DSN (Data Source Name)
gorm库使用dsn作为连接数据库的参数,dsn翻译过来就叫数据源名称,用来描述数据库连接信息。
一般都包含数据库连接地址,账号,密码之类的信息。
DSN格式:
[username[:password]@][protocol[(address)]]/dbname[?param1=value1&...¶mN=valueN]
mysql连接dsn例子:
//mysql dsn格式
//涉及参数:
//username 数据库账号
//password 数据库密码
//host 数据库连接地址,可以是Ip或者域名
//port 数据库端口
//Dbname 数据库名
username:password@tcp(host:port)/Dbname?charset=utf8&parseTime=True&loc=Local
//填上参数后的例子
//username = root
//password = 123456
//host = localhost
//port = 3306
//Dbname = tizi365
//后面K/V键值对参数含义为:
// charset=utf8 客户端字符集为utf8
// parseTime=true 支持把数据库datetime和date类型转换为golang的time.Time类型
// loc=Local 使用系统本地时区
root:123456@tcp(localhost:3306)/tizi365?charset=utf8&parseTime=True&loc=Local
//gorm 设置mysql连接超时参数
//开发的时候经常需要设置数据库连接超时参数,gorm是通过dsn的timeout参数配置
//例如,设置10秒后连接超时,timeout=10s
//下面是完成的例子
root:123456@tcp(localhost:3306)/tizi365?charset=utf8&parseTime=True&loc=Local&timeout=10s
//设置读写超时时间
// readTimeout - 读超时时间,0代表不限制
// writeTimeout - 写超时时间,0代表不限制
root:123456@tcp(localhost:3306)/tizi365?charset=utf8&parseTime=True&loc=Local&timeout=10s&readTimeout=30s&writeTimeout=60s
2、使用gorm.Open连接数据库
有了上面配置的dsn参数,就可以使用gorm连接数据库,下面是连接数据库的例子
package main
import (
"gorm.io/driver/mysql"
"gorm.io/gorm"
)
func main() {
//配置MySQL连接参数
username := "root" //账号
password := "123456" //密码
host := "127.0.0.1" //数据库地址,可以是Ip或者域名
port := 3306 //数据库端口
Dbname := "tizi365" //数据库名
timeout := "10s" //连接超时,10秒
//拼接下dsn参数, dsn格式可以参考上面的语法,这里使用Sprintf动态拼接dsn参数,因为一般数据库连接参数,我们都是保存在配置文件里面,需要从配置文件加载参数,然后拼接dsn。
dsn := fmt.Sprintf("%s:%s@tcp(%s:%d)/%s?charset=utf8&parseTime=True&loc=Local&timeout=%s", username, password, host, port, Dbname, timeout)
//连接MYSQL, 获得DB类型实例,用于后面的数据库读写操作。
db, err := gorm.Open(mysql.Open(dsn), &gorm.Config{})
if err != nil {
panic("连接数据库失败, error=" + err.Error())
}
//延时关闭数据库连接
defer db.Close()
}
3、gorm调试模式
为了方便调试,了解gorm操作到底执行了怎么样的sql语句,开发的时候需要打开调试日志,这样gorm会打印出执行的每一条sql语句。
使用Debug函数执行查询即可
result := db.Debug().Where("username = ?", "tizi365").First(&u)
4、gorm连接池
在高并发实践中,为了提高数据库连接的使用率,避免重复建立数据库连接带来的性能消耗,会经常使用数据库连接池技术来维护数据库连接。
gorm自带了数据库连接池使用非常简单只要设置下数据库连接池参数即可。
数据库连接池使用例子:
定义tools包,负责数据库初始化工作(备注:借助连接池说明,一般在操作数据库时,可以将数据库连接单独封装成一个包)
// 定义一个工具包,用来管理gorm数据库连接池的初始化工作。
package tools
import (
"fmt"
"gorm.io/driver/mysql"
"gorm.io/gorm"
)
// 定义全局的db对象,我们执行数据库操作主要通过他实现。
var _db *gorm.DB
// 包初始化函数,golang特性,每个包初始化的时候会自动执行init函数,这里用来初始化gorm。
func init() {
//配置MySQL连接参数
host := "192.168.56.121" //数据库地址,可以是Ip或者域名
username := "root" //账号
password := "123456" //密码
port := 3306 //数据库端口
Dbname := "store" //数据库名
timeout := "10s" //连接超时,10秒
//拼接下dsn参数, dsn格式可以参考上面的语法,这里使用Sprintf动态拼接dsn参数,因为一般数据库连接参数,我们都是保存在配置文件里面,需要从配置文件加载参数,然后拼接dsn。
dsn := fmt.Sprintf("%s:%s@tcp(%s:%d)/%s?charset=utf8&parseTime=True&loc=Local&timeout=%s", username, password, host, port, Dbname, timeout)
// 声明err变量,下面不能使用:=赋值运算符,否则_db变量会当成局部变量,导致外部无法访问_db变量
var err error
//连接MYSQL, 获得DB类型实例,用于后面的数据库读写操作。
_db, err = gorm.Open(mysql.Open(dsn), &gorm.Config{})
if err != nil {
panic("连接数据库失败, error=" + err.Error())
}
sqlDB, _ := _db.DB()
//设置数据库连接池参数
sqlDB.SetMaxOpenConns(100) //设置数据库连接池最大连接数
sqlDB.SetMaxIdleConns(20) //连接池最大允许的空闲连接数,如果没有sql任务需要执行的连接数大于20,超过的连接会被连接池关闭。
}
// 获取gorm db对象,其他包需要执行数据库查询的时候,只要通过tools.getDB()获取db对象即可。
// 不用担心协程并发使用同样的db对象会共用同一个连接,db对象在调用他的方法的时候会从数据库连接池中获取新的连接
func GetDB() *gorm.DB {
return _db
}
使用例子:
package main
//导入tools包
import tools
func main() {
//获取DB
db := tools.GetDB()
//执行数据库查询操作
u := User{}
//自动生成sql: SELECT * FROM `users` WHERE (username = 'tizi365') LIMIT 1
db.Where("username = ?", "tizi365").First(&u)
}
注意:使用连接池技术后,千万不要使用完db后调用db.Close关闭数据库连接,这样会导致整个数据库连接池关闭,导致连接池没有可用的连接。
CRUD操作
gorm 是一个 Go 语言的 ORM(Object Relational Mapping)库,可以方便地操作数据库。下面是 gorm 模块的使用步骤:
插入数据
func InsertDemo() {
// 创建 Sample 实例
Sample := Sample{Id: 1, Title: "张三", CreateTime: time.Now()}
//获取DB
MysqlDB := tools.GetDB()
// 添加数据
MysqlDB.Create(&Sample)
// 获取添加后的自增 ID
fmt.Println(Sample.Id)
}
执行结果

查询数据
func SearchDemo() {
//获取DB
db := tools.GetDB()
//获取第一个 Sample 记录
var firstSample Sample
db.First(&firstSample)
fmt.Println("('%d','%s','%s');", firstSample.Id, firstSample.Title, firstSample.CreateTime)
// 条件查询
var sample Sample
db.Where("title = ?", "张三").First(&sample)
fmt.Println("('%d','%s','%s');", firstSample.Id, firstSample.Title, firstSample.CreateTime)
// 查询所有 Sample 记录
var samples []Sample
db.Find(&samples)
}

更新数据
func UpdateDemo() {
//获取DB
db := tools.GetDB()
//获取第一个 Sample 记录
var sample Sample
db.Where("title = ?", "张三").First(&sample)
fmt.Println("('%d','%s','%s');", sample.Id, sample.Title, sample.CreateTime)
// 更新指定字段
db.Model(&sample).Update("age", 20)
// 更新多个字段
db.Model(&sample).Updates(Sample{Id: 20, Title: "李四"})
}
删除数据
func DeleteDemo() {
//获取DB
db := tools.GetDB()
//获取第一个 Sample 记录
var sample Sample
db.Where("title = ?", "张三").First(&sample)
fmt.Println("('%d','%s','%s');", sample.Id, sample.Title, sample.CreateTime)
// 删除 sample 记录
db.Delete(&sample)
// 根据条件删除多个记录
db.Where("title = ?", "张三").Delete(&Sample{})
}
这些是 gorm 模块的基本使用方法,可以根据实际需求进行调整和扩展。
go与mysql数据类型关系

mysql日期时间格式

go 存储 mysql TIMESTAMP格式
存:
type TestTime struct{
CreatedAt time.Time
}
m:=new(TestTime)
m.CreatedAt:=time.Now()
取:
go orm 取TestTime结构体数据
str:=orm_data.CreatedAt.Format("2006-01-02 15:04:05")
str == "2019-08-27 09:35:13"
高并发实操: 消息队列削峰解耦+ 批量写入DB
为什么要使用消息队列
三个最主要的应用场景:解耦、异步、削峰
- 削峰填谷(最主要的作用)可以削去到达系统的峰值流量,让业务逻辑的处理更加缓和;但是会造成请求处理的延迟
- 异步处理可以简化业务流程中的步骤,提升系统性能;
- 需要分清同步流程和异步流程的边界
- 消息存在着丢失的风险
- 解耦合可以将系统和系统解耦开,这样两个系统的任何变更都不会影响到另一个系统
削峰
传统模式:并发量大的时候,所有的请求直接怼到数据库,造成数据库连接异常

消息队列模式:系统A慢慢的按照数据库能处理的并发量,从消息队列中慢慢拉取消息。
在生产中,这个短暂的高峰期积压是允许的。

解耦
传统模式:系统间耦合性太强,如下图所示,
系统A在代码中直接调用系统B和系统C的代码,如果将来D系统接入,系统A还需要修改代码,过于麻烦!

消息队列模式:将消息写入消息队列,需要消息的系统自己从消息队列中订阅,从而系统A不需要做任何修改

异步
传统模式:一些非必要的业务逻辑以同步的方式运行,太耗费时间。

消息队列模式: 将消息写入消息队列,非必要的业务逻辑以异步的方式运行,加快相应速度。

实操:用GO实现消息队列削峰解耦
用GO实现消息队列削峰解耦,参考代码如下:
package batchprocess
// 创建生产者
const SAMPLE_TOPIC = "sample"
func ProducerStart() {
producer, err := rocketmq.NewProducer(
producer.WithNameServer([]string{NAME_NODE}),
producer.WithRetry(2),
)
...
// 发送消息,无限循环
for i := 0; ; i++ {
sample := Sample{Id: int64(i + 100), Title: "张三", CreateTime: time.Now()}
//序列化
json, err := json.Marshal(&sample)
msg := &primitive.Message{
Topic: SAMPLE_TOPIC,
Body: []byte(json),
}
res, err := producer.SendSync(context.Background(), msg)
if err != nil {
log.Printf("send Sample error: %v\n", err)
} else {
log.Printf("send Sample success: %v\n", res)
}
time.Sleep(time.Second)
}
}
func ConsumerStart() {
// 创建消费者
c, err := rocketmq.NewPushConsumer(
consumer.WithNameServer([]string{NAME_NODE}),
consumer.WithGroupName("test-group"),
)
err = c.Subscribe(SAMPLE_TOPIC, consumer.MessageSelector{},
func(ctx context.Context, msgs ...*primitive.MessageExt) (consumer.ConsumeResult, error) {
for _, msg := range msgs {
var sample Sample
err := json.Unmarshal(msg.Body, &sample)
if err != nil {
fmt.Println(err)
}
fmt.Println(sample)
messageMysqlChan <- sample // 加入通道
log.Printf("receive Sample: topic=%s, body=%s\n",
msg.Topic, string(msg.Body))
}
return consumer.ConsumeSuccess, nil
})
wg.Wait()
}
执行的效果如下(后面尼恩会在 穿透云原生视频中,进行详细介绍):

为什么应该使用批量插入来提高MySQL性能?
MySQL是一种常用的开源关系数据库管理系统(RDBMS),常用于建立网站和应用程序后端的数据存储和管理系统。但随着数据量的增大,MySQL的性能也会逐渐下降,此时需要使用批量插入来提高MySQL性能。
批量插入是指一次性向MySQL数据库中插入多条记录,相对于逐个插入单条记录,批量插入可以大大提高MySQL的性能。那么,为什么应该使用批量插入呢?以下是几个原因。
- 减少网络往返次数
MySQL是一种客户端/服务器模式的数据库,在客户端插入一条记录时,需要与MySQL服务器建立一次网络连接,而这个过程将耗费时间和带宽。如果每插入一条记录就要建立一次网络连接,那么对于大批量的数据插入将会非常低效。通过批量插入,可以减少网络连接次数,从而提高MySQL的性能。
- 减少SQL语句的解析次数
MySQL中,每条SQL语句都需要进行解析并编译成执行计划,这个过程也需要耗费时间。如果逐个插入单条记录,那么每条SQL语句都需要解析和编译,而使用批量插入,只需要解析和编译一次SQL语句即可,从而减少了SQL语句的解析次数,提高MySQL的性能。
- 减少磁盘I/O操作
MySQL将数据存储在磁盘上,每次向磁盘写入一条记录都将会进行一次磁盘I/O操作。如果逐个插入单条记录,那么每次插入都将会进行一次磁盘I/O操作,而使用批量插入,多条记录将会一起写入磁盘,从而减少了磁盘I/O操作,提高了MySQL的性能。
- 减少锁的竞争
在MySQL中,插入一条记录时需要获取表级锁或行级锁,如果逐个插入单条记录,那么每次插入都将会竞争锁资源,从而影响MySQL的性能。使用批量插入时,多条记录被看做一个事务,只需要获取一次锁,从而减少了锁的竞争,提高了MySQL的性能。
以上是使用批量插入来提高MySQL性能的几个原因。但是,批量插入也存在一些缺点,例如批量插入一起错误时很难进行回滚操作,可能导致数据的不一致性。因此,在使用批量插入时,需谨慎考虑。
总而言之,使用批量插入是提高MySQL性能的有效方式,可以减少网络连接次数、SQL语句的解析次数、磁盘I/O操作和锁的竞争,从而提高MySQL的性能。但是,在使用批量插入时也需要注意一些可能的缺陷。
实操:用GO实现批量写入
package batchprocess
func StartBatchWriter() {
messageMysqlChan = make(chan Sample, 100)
insertedFlags = make(map[int64]bool)
go batchMessageReceive()
go batchStartTimer()
}
/*
接收消息的逻辑,只负责接收消息
*/
func batchMessageReceive() {
for {
select {
case oneMessage := <-messageMysqlChan:
mesLock.Lock()
tmpMessage = append(tmpMessage, oneMessage)
mesLock.Unlock()
}
}
}
func batch(batchMessage []Sample) {
if len(batchMessage) == 0 {
fmt.Print(">>>>>>>>> 空消息")
return
}
var buffer bytes.Buffer
sql := "insert into `sample` (`id`,`title`,`create_time`) values"
if _, err := buffer.WriteString(sql); err != nil {
fmt.Print(err.Error())
}
for index, value := range batchMessage {
/*查看元素在集合中是否存在 */
_, ok := insertedFlags[value.Id] /*如果确定是处理过 */
if ok {
continue
} else {
insertedFlags[value.Id] = true
}
if index == len(batchMessage)-1 {
buffer.WriteString(fmt.Sprintf("('%d','%s','%s');", value.Id, value.Title, value.CreateTime.Format("2006-01-02 15:04:05")))
} else {
buffer.WriteString(fmt.Sprintf("('%d','%s','%s'),", value.Id, value.Title, value.CreateTime.Format("2006-01-02 15:04:05")))
}
}
//获取DB
MysqlDB := tools.GetDB()
err := MysqlDB.Exec(buffer.String()).Error
if err != nil {
fmt.Println("插入数据库失败:", err.Error())
} else {
fmt.Printf("插入数据库成功,一共插入的条数: %d:", len(batchMessage))
fmt.Println("祝贺")
}
return
}
执行效果
执行的效果如下(后面尼恩会在 穿透云原生视频中,进行详细介绍):

Golang GC垃圾回收器
Cache 和 Buffer的区别
在理解垃圾回收之前,我们先理解一下Cache 和 Buffer,这两个都是缓存,这两者之间有什么区别呢?
buffer:缓冲
用于存储速度不同步的设备或优先级不同的设备之间传输数据;通过buffer可以减少进程间通信需要等待的时间,当存储速度快的设备与存储速度慢的设备进行通信时,存储慢的数据先把数据存放到buffer,达到一定程度存储快的设备再读取buffer的数据,在此期间存储快的设备CPU可以做其他的事情。
A buffer is something that has yet to be "written" to disk.
cache:缓存
是高速缓存,是位于CPU和主内存之间的容量较小但速度很快的存储器,因为CPU的速度远远高于主内存的速度,CPU从内存中读取数据需等待很长的时间,而 Cache保存着CPU刚用过的数据或循环使用的部分数据,这时从Cache中读取数据会更快,减少了CPU等待的时间,提高了系统的性能。
A cache is something that has been "read" from the disk and stored for later use.
buffer是用于存放将要输出到disk(块设备)的数据,进行流量整形,把突发的大数量较小规模的 I/O 整理成平稳的小数量较大规模的 I/O,以减少响应次数,而cache是存放从disk上读出的数据,为了弥补高速设备和低速设备的鸿沟而引入的中间层,最终起到加快访问速度的作用。。二者都是为提高IO性能而设计的。
而Go标准库Buffer是一个可变大小的字节缓冲区,可以用Wirte和Read方法操作它.
Golang GC发展史
通常在编程中的垃圾指内存中不再使用的内存区域,自动发现与释放这种内存区域的过程就是垃圾回收。
内存资源是有限的,而垃圾回收可以让内存重复使用,并且减轻开发者对内存管理的负担,减少程序中的内存问题。
我们透过这个来看下Go垃圾回收发展史:
- go1.1,提高效率和垃圾回收精确度。
- go1.3,提高了垃圾回收的精确度。
- go1.4,之前版本的runtime大部分是使用C写的,这个版本大量使用Go进行了重写,让GC有了扫描stack的能力,进一步提高了垃圾回收的精确度。
- go1.5,目标是降低GC延迟,采用了并发标记和并发清除,三色标记,write barrier,以及实现了更好的回收器调度,设计文档1,文档2,以及这个版本的[Go talk]。
- go1.6,小优化,当程序使用大量内存时,GC暂停时间有所降低。
- go1.7,小优化,当程序有大量空闲goroutine,stack大小波动比较大时,GC暂停时间有显著降低。
- go1.8,write barrier切换到hybrid write barrier,以消除STW中的re-scan,把STW的最差情况降低到50us,设计文档。
混合屏障的优势在于它允许堆栈扫描永久地使堆栈变黑(没有STW并且没有写入堆栈的障碍),这完全消除了堆栈重新扫描的需要,从而消除了对堆栈屏障的需求。重新扫描列表。特别是堆栈障碍在整个运行时引入了显着的复杂性,并且干扰了来自外部工具(如GDB和基于内核的分析器)的堆栈遍历。
此外,与Dijkstra风格的写屏障一样,混合屏障不需要读屏障,因此指针读取是常规的内存读取; 它确保了进步,因为物体单调地从白色到灰色再到黑色。
混合屏障的缺点很小。它可能会导致更多的浮动垃圾,因为它会在标记阶段的任何时刻保留从根(堆栈除外)可到达的所有内容。然而,在实践中,当前的Dijkstra障碍可能几乎保留不变。混合屏障还禁止某些优化:特别是,如果Go编译器可以静态地显示指针是nil,则Go编译器当前省略写屏障,但是在这种情况下混合屏障需要写屏障。这可能会略微增加二进制大小。
- go1.9,提升指标主要是:
- 过去
runtime.GC,debug.SetGCPercent, 和debug.FreeOSMemory都不能触发并发GC,他们触发的GC都是阻塞的,go1.9可以了,变成了在垃圾回收之前只阻塞调用GC的goroutine。 -
debug.SetGCPercent只在有必要的情况下才会触发GC。
- go.1.10,小优化,加速了GC,程序应当运行更快一点点。
- go1.12,显著提高了堆内存存在大碎片情况下的sweeping性能,能够降低GC后立即分配内存的延迟。
还有 5W字待发布
本文,仅仅是《Golang 圣经》 的第一部分。
《Golang 圣经》后面的内容 更加精彩,涉及到高并发、分布式微服务架构、 WEB开发架构,具体请关注进展,请关注《技术自由圈》 公众号。
如果需要领取 《Golang 圣经》, 请关注《技术自由圈》 公众号,发送暗号 “领电子书” 。
最后,如果学习过程中遇到问题,可以来尼恩的 万人高并发社群中交流。
参考资料
- Tracing Garbage Collection - wikipedia
- On-the-fly Garbage Collection: an exercise in cooperation.
- Garbage Collection
- Tracing Garbage Collection
- Copying Garbage Collection
- Generational Garbage Collection
- Golang Gc Talk
- Eliminate Rescan
技术自由的实现路径 PDF:
实现你的 架构自由:
《吃透8图1模板,人人可以做架构》
《10Wqps评论中台,如何架构?B站是这么做的!!!》
《阿里二面:千万级、亿级数据,如何性能优化? 教科书级 答案来了》
《峰值21WQps、亿级DAU,小游戏《羊了个羊》是怎么架构的?》
《100亿级订单怎么调度,来一个大厂的极品方案》
《2个大厂 100亿级 超大流量 红包 架构方案》
… 更多架构文章,正在添加中
实现你的 响应式 自由:
《响应式圣经:10W字,实现Spring响应式编程自由》
这是老版本 《Flux、Mono、Reactor 实战(史上最全)》
实现你的 spring cloud 自由:
《Spring cloud Alibaba 学习圣经》
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)》
实现你的 linux 自由:
《Linux命令大全:2W多字,一次实现Linux自由》
实现你的 网络 自由:
《TCP协议详解 (史上最全)》
《网络三张表:ARP表, MAC表, 路由表,实现你的网络自由!!》
实现你的 分布式锁 自由:
《Redis分布式锁(图解 - 秒懂 - 史上最全)》
《Zookeeper 分布式锁 - 图解 - 秒懂》
实现你的 王者组件 自由:
《队列之王: Disruptor 原理、架构、源码 一文穿透》
《缓存之王:Caffeine 源码、架构、原理(史上最全,10W字 超级长文)》
《缓存之王:Caffeine 的使用(史上最全)》
《Java Agent 探针、字节码增强 ByteBuddy(史上最全)》
实现你的 面试题 自由:
4000页《尼恩Java面试宝典 》 40个专题文章来源:https://www.toymoban.com/news/detail-458274.html
以上尼恩 架构笔记、面试题 的PDF文件更新,请到下面《技术自由圈》公号取↓↓↓文章来源地址https://www.toymoban.com/news/detail-458274.html
到了这里,关于Go学习圣经:队列削峰+批量写入 超高并发原理和实操的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!