HTTP
什么是HTTP?HTTP是应用层的一个重要协议.它定义了浏览器怎样向服务器请求文件,以及服务器怎样把文件传送给浏览器.
我们打开浏览器,手动输入一个网址:baidu.com.那么此时浏览器就会给百度的服务器发送请求.百度服务器在返回一个html的响应.
那么我们如何学习HTTP协议呢?通过它的协议报文格式,我们就能看到HTTP具体是什么样子的了。
HTTP的报文协议格式
学习HTTP的报文格式,需要通过一个抓包工具来实现.
那么抓包工具是什么呢?
一. 抓包工具
抓包工具的本质就是一个代理,简称跑腿的.比如A想喝楼下茶百道奶,让给他买.B此时充当的角色就是代理。
由于B是那个替别人执行任务的,所以非常清楚任务的具体执行过程。
我们引入抓包,就是为了获取想要的原始数据。
我们推荐使用Fiddler来实现http的抓包。
Fidder的使用详解
左右结构
-
左侧:抓到的包的列表(注意,它是一直在持续的)
-
右侧:双击找到的包,会出现这个包的详情页。右上:请求 右下:响应

二.HTTP请求
双击右上的Raw,就可以看到原来的格式,然后点击view in notepad.就可以通过记事本来打开啦!
下图就是一个完整的HTTP请求:
HTTP请求的组成部分
- 首行

2.Header
3.空行
Header的结束标记
4.正文
body (可有可没有)
下面我们着重介绍四个部分的首行和请求头Header部分
1.首行
HTTP方法
HTTP有很多方法,其中比较重要的有两个:
-
get 请求
-
post请求

它们都是客户端向服务器发送请求的方法
get和post的区别
本质上没有室内区别,但是在方法的使用上有些不同.
1.get用来表示“获取一个数据”,post表示“提交一个数据”;
2.get没有body,需要携带数据的话要放入URL中。而Post有body;
3.get是幂等的;=,post无要求;
(幂等就是输入一定,输出也一定。这样只要是同一个输入,就会有同一个输出!!!)
4.get可以缓存,post不可以;
(缓存是建立在幂等的基础之上的,因为输入一定,输出也一定。所以我们可以把输出缓存起来。这样只要是同一个输入。服务器就不用计算了,直接返回缓存中的结果)
5.get可以被浏览器收藏,post不可以。
URL
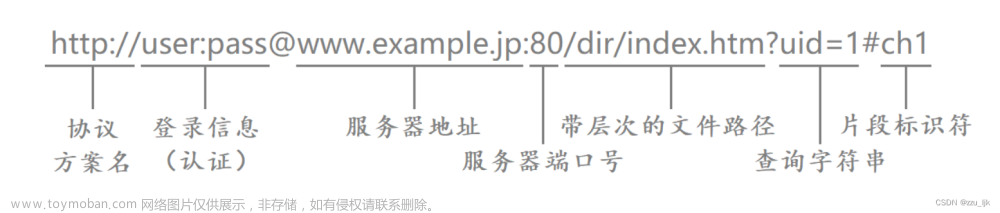
唯一资源定位标识,描述了网络上的一个唯一的资源。

如果觉得很抽象的话!我们可以举一个生活中的例子,便于理解。
假设我们要去重庆工商大学的18窗口吃重庆小面:
那用URL来表示就是:
http://重庆工商大学3食堂:18//重庆小面/豌杂面?葱=不要&辣椒=微辣&香菜=不要
服务器地址:重庆工商大学
端口号:18
访问资源:重庆小面的豌杂面
补充说明:不要葱微辣不要香菜.
注:查询字符串是有键值对组成的。&分割键值对,=分割键和值。
版本号
HTTP的版本号有:HTTP/1.0、HTTP/1.1、HTTP/2、HTTP/3
最新版本:HTTP/3
最常用版本:HTTP/1.1
2. 请求头Header
键值对结构。每个键值对都是一行;键和值之间采用: (冒号+空格)分割

空行结束。
Host
描述了浏览器要访问的服务器是谁(地址+端口号)
与URL的区别:
URL中存放的是当前目标,Host中存放的是最终目标。
content-Type和content-Length
- content-Type
描述body的数据格式
作为请求的写法:

通过form表单提交数据,body的格式和查询字符串(querry String)一样,也就是url中的查询字符串的格式:username=cy&password=gw520
 数据格式是json,字符集是utf-8
数据格式是json,字符集是utf-8
{
username:cy;
password:gw520;
…
}
- content-Length
描述body的数据长度

这两个属性是跟着body走的,所以只有请求是Post时,才会出现.
User-Agent(UA)
主要描述系统和浏览器是什么版本。

作用:
UA在早年互联网行业还未发展起来的时候,是用来区分各种上网设备的(不同的型号等),不同的上网设备能支持的功能不同。
而如今,随着互联网的快速发展,浏览器之间的区别以及非常小了,UA存在的价值就是区分用户是手机端、PC端还是平板。
referer
表示这个页面是从哪个页面跳转过来的。
比如我在百度搜索肖战。
此时的referer表示当前页面是从百度页面跳转过来的:
 *
*
Cookie
俗称小饼干,也是由键值对组成的。它是浏览器在本地存储用户自定义数据的一种重要机制。

数据都是存储在服务器的,浏览器也需要存储数据吗?是的。
浏览器要存储数据,比如用户信息。那么它如何存储呢?直接访问硬盘文件吗?不可以,如果允许网页访问文件系统的话,如果有不良网页篡改我们硬盘中的某些数据,后果将不堪设想!!!
所以为了保证网络安全,浏览器会限制网页访问我们的文件系统。
既然浏览器阻止网页访问文件系统,又想要存数据。该如何实现呢?Cookie机制!
浏览器通过Cookie机制,允许网页往浏览器这边写入一些自定义的键值对。这些数据通过浏览器的api,写入特定的文件(往指定位置存储指定文件)。
- Cookie从哪儿来
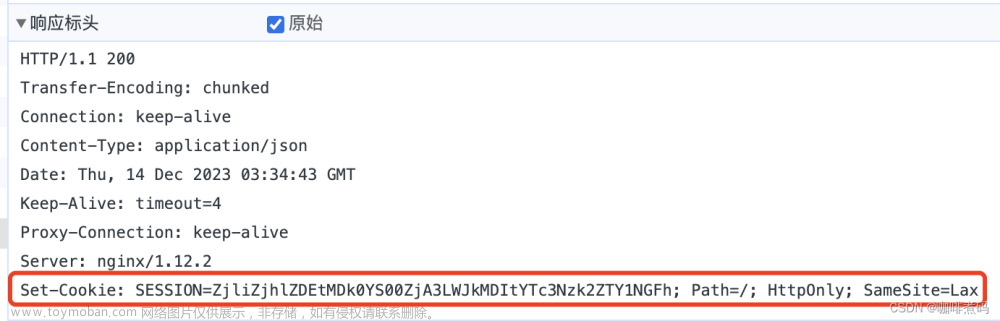
从服务器来。当浏览器访问服务器时,服务器会返回一个HTTP响应,响应中的set-Cookie字段就包含了Cookie键值对。
在浏览器搜索baidu.com,通过抓包工具进行抓包,找到这个包,点击响应,打开:
再次打开浏览器,就可以看到浏览器存储的数据了。
- Cookie到哪里去
浏览器保存之后,后续再访问服务器,就会带上Cookie。
- Cookie有什么用
浏览器本地存储数据的机制。最主要的作用就是存储用户登录信息。当再次访问服务器,带上Cookie,服务器就能知道是哪个用户。
例1:我们登录 QQ邮箱,此时浏览器会记住用户登录信息,服务器根据这个用户登陆信息,返回这个用户信息的数据(比如收件箱,草稿箱等等)。我们再去点击收件箱,就不用重新登录了,会直接出来这个这个用户对应的页面。
例2:cookie有点像我们平时的校园卡,校园卡里存储了每个学生的信息,姓名,学号,余额等等。当我们刷校园卡出入校门,系统就能通过校园卡识别信息。确认是本校学生,就可以进门了。
三.HTTP响应
HTTP响应的组成部分
像HTTP请求一样,先点击Raw,再点击使用记事本打开。可以发现,是一个二进制文件!这是由于此时打开的是一个HTTP响应的压缩文件。我们可以点击这个:
打开,就可以看到解压过后的文本文件了。
如下图是一个完整的HTTP响应:

HTTP响应也可以分成四个部分:
1.首行

2.响应报头(Header)
3.空行
4.正文
(此处是一个HTML代码)
HTTP响应与HTTP请求的组成部分差不多,重点了解HTTP响应首行中的状态码代表什么意思就可以了.
HTTP状态码
表示此次请求是成功还是失败,用数字表示.

比较经典的错误::
200:表示请求成功
301:永久重定向
302:临时重定向
404:表示访问的资源不存在
403:表示访问被拒绝(没有权限)
500:服务器内部错误
504:服务器访问超时文章来源:https://www.toymoban.com/news/detail-458319.html
总结
HTTP协议报文格式: 文章来源地址https://www.toymoban.com/news/detail-458319.html
文章来源地址https://www.toymoban.com/news/detail-458319.html
到了这里,关于HTTP 协议的基本格式的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!