1. 项目简介
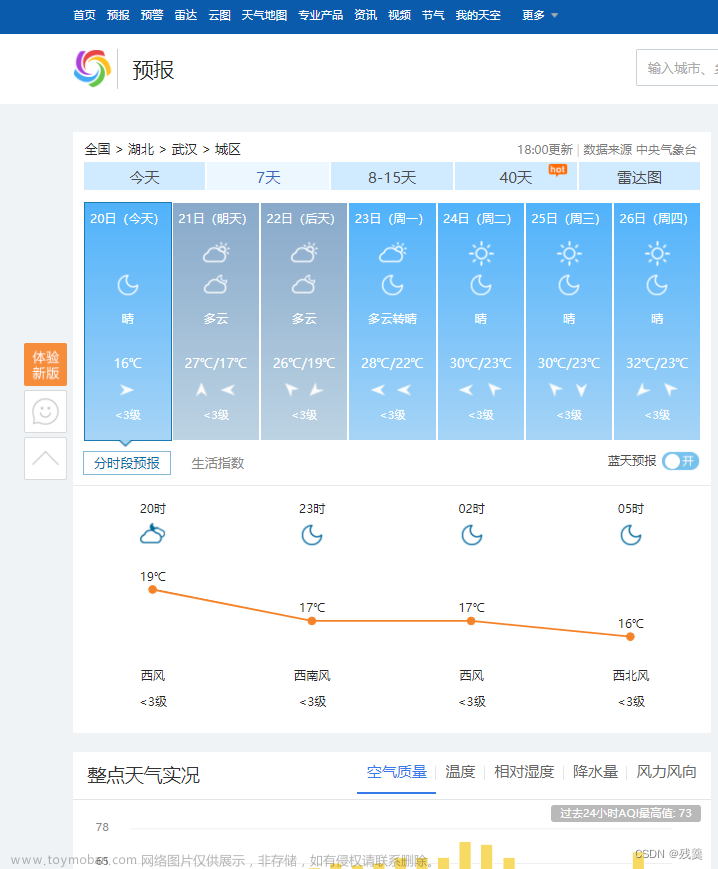
在中国天气网(天气网)中输入一个城市的名称,例如输入深圳,那么会转到地址深圳天气预报,深圳7天天气预报,深圳15天天气预报,深圳天气查询的网页显示深圳的天气预报,其中101280601是深圳的代码,每个城市或者地区都有一个代码。如下图:


在上图中可以看到,深圳今天,7天,8-15天等的天气数据,这里爬取7天的天气预报数据。
2. HTML 代码分析
分析这段代码:

7天的天气预报实际上在一个<ul class="t clearfix">元素中,每天是一个M<li>元素,7天的结构差不多是一样的(注意:今天没有最高温度与最低温度)。
3. 爬取天气预报数据
from bs4 import BeautifulSoup
from bs4.dammit import UnicodeDammit # BS内置库,用于推测文档编码
import urllib.request # 发起请求,获取响应
url = "http://www.weather.com.cn/weather/101280601.shtml"
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.78"}
req = urllib.request.Request(url, headers=headers) # 创建请求对象
data = urllib.request.urlopen(req) # 发起请求
data = data.read() # 获得响应体
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup # 解码
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")
x = 0
for li in lis:
try:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
if x == 0: # 为今天只有一个温度做判断 <i>14℃</i>
x += 1
temp = li.select('p[class="tem"] i')[0].text
else:
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
print(date, weather, temp)
# 22日(今天) 晴 14℃
# 23日(明天) 晴 23℃/14℃
# 24日(后天) 晴转多云 25℃/13℃
# 25日(周六) 多云 21℃/13℃
# 26日(周日) 多云转晴 22℃/12℃
# 27日(周一) 晴 21℃/12℃
# 28日(周二) 晴 24℃/14℃
except Exception as err:
print(err)
except Exception as err:
print(err)
4. 爬取与存储天气预报数据
获取北京、上海、广州、深圳等城市的代码,爬取这些城市的天气预报数据,并存储到sqllite数据库weathers.db中,存储的数据表weathers是:
create table weathers (wCity varchar(16),wDate varchar(16),wWeather varchar(64),wTemp varchar(32),constraint pk_weather primary key (wCity,wDate))"
编写程序依次爬取各个城市的天气预报数据存储在数据库中,程序如下:
from bs4 import BeautifulSoup
from bs4.dammit import UnicodeDammit
import urllib.request
import sqlite3
# 天气数据库
class WeatherDB:
def __init__(self):
self.cursor = None
self.con = None
def openDB(self):
self.con = sqlite3.connect("weathers.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute(
"create table weathers (wCity varchar(16),"
"wDate varchar(16),"
"wWeather varchar(64),"
"wTemp varchar(32),"
"constraint pk_weather primary key (wCity,wDate))")
except Exception as err:
print(err)
self.cursor.execute("delete from weathers")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, city, date, weather, temp):
try:
self.cursor.execute("insert into weathers (wCity,wDate,wWeather,wTemp) values (?,?,?,?)",
(city, date, weather, temp))
except Exception as err:
print(err)
def show(self):
self.cursor.execute("select * from weathers")
rows = self.cursor.fetchall()
print("%-16s%-16s%-32s%-16s" % ("city", "date", "weather", "temp"))
for row in rows:
print("%-16s%-16s%-32s%-16s" % (row[0], row[1], row[2], row[3]))
# 天气预报
class WeatherForecast:
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) "
"Gecko/2008072421 Minefield/3.0.2pre"}
self.cityCode = {"北京": "101010100", "上海": "101020100", "广州": "101280101", "深圳": "101280601"}
def forecastCity(self, city):
if city not in self.cityCode.keys():
print(city + " 找不到代码")
return
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml"
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")
x = 0
for li in lis:
try:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
if x == 0: # 为今天只有一个温度做判断 <i>14℃</i>
x += 1
temp = li.select('p[class="tem"] i')[0].text
else:
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
print(city, date, weather, temp)
self.db.insert(city, date, weather, temp)
except Exception as err:
print(err)
except Exception as err:
print(err)
def process(self, cities):
self.db = WeatherDB()
self.db.openDB()
for city in cities:
self.forecastCity(city)
# self.db.show()
self.db.closeDB()
ws = WeatherForecast()
ws.process(["北京", "上海", "广州", "深圳"])
print("completed")程序执行结果如下:文章来源:https://www.toymoban.com/news/detail-458471.html

下一篇文章:爬取大学排名信息文章来源地址https://www.toymoban.com/news/detail-458471.html
到了这里,关于【爬虫】2.6 实践项目——爬取天气预报数据的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!