OpenStack介绍说明
OpenStack起源

- 2006年亚马逊推出AWS,正式开启云计算的新纪元
- 2010年7月美国国家航空航天局(NASA)与Rackspace合作,共同宣布OpenStack开放源码计划,由此开启了属于OpenStack的时代
- OpenStack从诞生之初对标AWS,一直在向AWS学习,同时开放接口去兼容各种AWS服务
认识openstack【重要】
-
OpenStack是什么?
OpenStack是一种云操作系统,可控制整个数据中心内的大型计算、存储和网络资源池,所有资源都通过具有通用身份验证机制的API进行管理和配置。管理员也可通过Web界面控制,同时授权用户通过Web界面配置资源。
- OpenStack是虚拟机、裸金属和容器的云基础架构
- OpenStack可控制整个数据中心的大型计算、存储和网络资源池
- 所有资源都通过API或Web界面进行管理
-
OpenStack能做什么?
OpenStack既是一个社区,也是一个项目和一个开源软件,提供开放源码软件,建立公共和私有云,它提供了一个部署云的操作平台或工具集,其宗旨在于帮助组织运行为虚拟计算或存储服务的云,为公有云、私有云,也为大云、小云提供可扩展的、灵活的云计算。
作为一个开源的云计算管理平台,OpenStack由几个主要的组件组合起来完成具体工作。OpenStack支持几乎所有类型的云环境,项目目标是提供实施简单、可大规模扩展、丰富、标准统一的云计算管理平台。OpenStack通过各种互补的服务提供了基础设施即服务(IaaS)的解决方案,每个服务提供API以进行集成。
- OpenStack通过一组相互关联的服务提供基础设施即服务 (IaaS)解决方案。每个服务都提供了一个应用程序编程接口 (API)来促进这种集成
- OpenStack项目是一个适用于所有类型云的开源云计算平台,项目目标是提供实施简单、可大规模扩展、丰富、标准统一的云计算管理平台
-
OpenStack工作原理概述

- OpenStack实际上由一系列叫作脚本的命令组成。这些脚本会被捆绑到名为项目的软件包中,这些软件包则用于传递创建云环境的任务
- 为了创建这些环境,OpenStack还会使用 2 种其他类型的软件:
- 虚拟化软件,用于创建从硬件中抽象出来的虚拟资源层
- 基础操作系统(OS),用于执行OpenStack脚本发出的命令
- OpenStack本身不会虚拟化资源,但会使用虚拟化资源来构建云
- OpenStack、虚拟化和基础操作系统,这 3 种技术协同工作服务用户
-
开源OpenStack版本演进
- OpenStack第一版代号为Austin,以Rackspace所在的美国德克萨斯州Texas首府命名,计划每隔几个月发布一个全新版本,并且以26个英文字母从A到Z顺序命名后面的版本代号。通常以举办OpenStack峰会所在地的某个城市或地区来命名。
- 2017年华为成功晋级为白金会员,成为亚洲首家OpenStack白金会员。
- OpenStack基金会允许最多8家白金会员资格和24家黄金会员资格,目前已有AT&T、爱立信、华为、英特尔、Rackspace、红帽、SUSE和腾讯这8家白金会员,以及九州云、中国移动、中国联通、中国电信、思科、EasyStack、烽火、浪潮、新华三以及中兴通讯等黄金会员。
- OpenStack每年两个大版本,一般在4月和10月中旬发布,版本命名从字母A-Z

-
OpenStack设计理念

- 开放:
- 源代码开放,设计与开发流程开放。
- “不重复发明轮子”,“站在巨人的肩膀上”。
- 不使用任何不可替代的私有/商业组件。
- 灵活:
- 架构可裁剪,可以根据实际需要决定选取的组件范围。
- 大量采用驱动与插件机制。
- 通过配置项控制对系统功能特性进行便捷配置。
- 可扩展:
- 松耦合架构,组件间RESTful API通信,组件内消息总线通信。
- 无中心架构,核心组件无中心节点,有效避免单点故障。
- 无状态架构,各组件无本地持久化数据,所有持久化数据保存在数据库中。
- 开放:
-
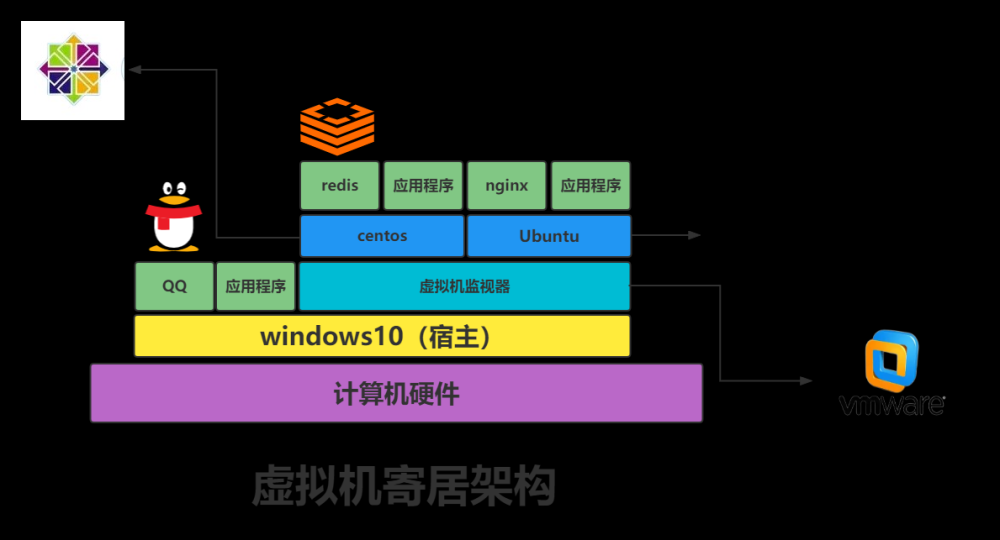
OpenStack与虚拟化
OpenStack优先关注控制面,OpenStack优先考虑如何将计算、存储、网络领域的各类资源抽象为资源池。在此基础上,对资源池内的各类逻辑对象实施控制操作,并将控制操作包装成面向用户的服务。数据面、管理面目前不是OpenStack的重点关注内容。- OpenStack不是虚拟化,OpenStack只是系统的控制面,不包括系统的数据面组件,如Hypervisor、存储和网络设备等
- 虚拟化是OpenStack底层的技术实现手段之一,但并非核心关注点
- OpenStack与虚拟化的关键区别:

-
OpenStack与云计算
- OpenStack是框架:以OpenStack为框架,将计算、存储、网络、管理、运营、运维等多个领域的软硬件产品组件整合在一起,共同组成面向业务场景的整体解决方案。
- OpenStack主要关注的问题:框架本身的开放性,生态的繁荣与活跃;控制面的服务能力、高可靠、高性能、可扩展、易操作、易维护等。
- Cloud BSS:Cloud Business Support System,云业务支撑系统。
- Cloud OSS:Cloud Operation Support System ,云运营支撑系统。
- 综上两个对比,可以总结出云计算与虚拟化的关键区别:
云计算的特点是IT能力的服务化,按需使用,按量计费,多租户隔离等。
虚拟化的特点是环境隔离,资源复用,降低隔离损耗,提升运行效率,提供高级虚拟化特性等。 - openstack只是构建云计算的关键组件:内核、骨干、框架、总线
- 为了构建云计算,我们还需要很多东西:

OpenStack架构说明
OpenStack架构概览
- OpenStack被分解为服务,允许用户根据需要即插即用组件。OpenStack地图让用户可以“一目了然”地了解OpenStack环境,以了解这些服务适合的位置以及它们如何协同工作。
- 图1

- 图2

- 图1
OpenStack逻辑架构
- 要设计、部署和配置OpenStack,管理员必须了解其逻辑架构
- 每个OpenStack服务内部是由多个进程组成。所有服务(Keystone除外)都至少有一个API进程,负责监听API请求,对请求进行预处理并将它们传递给服务的其他部分
- 每个OpenStack服务的进程之间的通信,使用AMQP消息代理。服务的状态存储在数据库中。在部署和配置OpenStack云时,管理员可以在多种消息代理和数据库解决方案中进行选择,例如RabbitMQ、MySQL、MariaDB和SQLite
- 用户可以通过Web用户界面、命令行客户端以及通过浏览器插件或curl等工具发出API请求来访问OpenStack
OpenStack生产环境部署架构示例

- 生产环境中,一般会有专门的OpenStack部署服务节点、控制节点、计算节点、网络节点和存储服务节点等。
- 生产环境的控制节点建议三台以上,其他节点按需求部署。
- 如果只是测试,OpenStack服务可以部署在单节点上。
OpenStack核心服务说明
通用组件
-
Message Queue

- 消息队列,OpenStack使用 Rabbit MQ
- OpenStack各服务内部组件协作的方式
-
Database

- 数据库, OpenStack使用Mariadb
- OpenStack中大部分服务都有自己DB
认证服务Keystone

Keystone:核心概念
- 核心概念(Keystone V3)
- 用户相关
-
domain(域):是项目和用户的容器,用于为管理身份入口定义管理边界 -
project(项目):一个用于分组或隔离资源的容器,资源的所有权是属于项目的,用户只有加入项目后才能访 问该项目的资源,每个项目可设置Quota -
user(用户):任何使用OpenStack服务的实体,OpenStack 为 nova、cinder、neutron 等服务创建了相应 的 user -
group(用户组):用户的集合,可以对group赋予角色,group中的用户都拥有该角色对应的权限 -
role(角色):权限的集合,各服务通过自己的policy.json文件定义各角色的权限,默认只有admin和非admin 两种角色。keystone通过role进行鉴权 -
token(令牌):由数字和字母组成的字符串,是credentials的一种,用户认证成功后keystone生成token分 配给用户,用作访问服务的credential。有效期默认24小时,UUID/PKI/PKIZ/Fernet多种形式的token - 服务相关
-
service(服务):OpenStack 服务,如nova、neutron等,每个服务提供一个或者多个 endpoint 供用户访问 资源以及进行操作 -
endpoint(端点):endpoint是一个网络上可访问的地址,通常是URL。service 通过 endpoint 暴露自己的API,每个Service有public、internal、admin三个endpoint,keystone 负责管理和维护每个 Service 的 Endpoint
-
用户相关说明

-
用户相关
- domain(域)
- project(项目)
- user(用户)
- group(用户组)
- role(角色)
- token(令牌)
-
一个Region中可以包含多个Domain,一个Domain中可以包含多个Group、user和Project,一个Group中可以包 含多个user。
-
通过role可以建立起Group与Project,user与Project之间的联系,即赋予相应的权限。例如:可以通过Group1将
-
Role 直接赋予Domain1,则Group1中的所有用户都将会对Domain1中的所有Projects拥有admin权限。
-
查看用户命令:
openstack user list
-
查看角色命令:
openstack role list
服务相关说明
-
服务相关
- service(服务)
- endpoint(端点)
-
查看服务命令
openstack service list
-
查看endpoint命令
openstack endpoint list
举例:user1用户要登录dashboard查看VM列表
- 举例:user1用户要登录dashboard查看VM列表,流程如下
- user1在horizon登录界面输入用户名和密码(也是credential的一种)
- horizon将用户名和密码发给keystone进行认证
- 用户名密码认证通过后,keystone为user1用户生成token并返回,token中包含了用户的role信息
- 根据token信息可以知道user1用户可以访问哪些服务、哪些Project,并且在这些Project 中是什么角色
- 根据user1的可访问的服务、Project列表,在Project中的角色,以及角色对应的policy权 限,在界面上显示user1可访问的服务、项目、资源
- 当user1点击Instance时,会将请求发给nova的endpoint,nova根据user1的token进行 鉴权,判断user1在这个项目中有是什么角色、有哪些权限,如果有查看Instance的权限,
- 则将Instance列表返回给user1,user1通过界面查看到VM列表信息
镜像服务Glance

组件和架构
- 组件和架构
-
glance-api:对外提供 REST API,响应 image 查询、获取和存储的调用。glance-api 不真正处理请求, 如果操作是与 image metadata(元数据)相关,glance-api 会把请求转发给 glance-registry; 如果操 作是与 image 自身存取相关,glance-api 会把请求转发给该 image 的 store backend。 -
glance-registry:负责处理和存取 image 的 metadata,如 image 的大小和类型。 -
database:使用Mariadb,glance有自己的database -
store backend:glance 自己并不存储 image,真正的 image 存放在 backend 中,glance 支持多种backend,可在配置文件glance-api.conf中定义
-

重要概念
- image:由glance管理的镜像文件,存放在glance的backend中,是instance运行的模板
- 虚拟机镜像文件:虚拟机instance启动盘所对应的文件(一般instance目录下disk文件)*
- 创建虚拟机时,nova将image下载到本地作为虚拟机disk文件的backing file(仅第一次下载),下载的image存放 在
path_to_nova/instances/_base目录下,nova.conf中可配置instance_path/image_cache_subdirectory_name - 创建虚拟机后,每个虚拟机会基于image拷贝出自己的disk镜像文件
- 如果是使用Ceph作为nova、glance后端,则无需下载image和拷贝出disk镜像文件,而是在Ceph内部实现COW


- 创建虚拟机时,nova将image下载到本地作为虚拟机disk文件的backing file(仅第一次下载),下载的image存放 在
- 查看镜像命令:
openstack image list
- 镜像格式和dashboard创建说明

计算范围Nova

组件和架构

-
组件和架构
-
nova-api:接受并响应用户对计算服务的API请求,是Nova 服务对 外的唯一接口,会周期性访问数据库更新虚拟机信息。 -
nova-conductor:nova-compute 访问数据库的全部操作都由 nova-conductor完成(获取和更新数据库中instance的信息),避 免nova-compute 直接访问数据库,增加系统的安全性和伸缩性 -
nova-scheduler:负责nova的调度服务,创建虚拟机时决定虚拟机 在哪个nova-compute计算节点上启动 -
nova-compute:处理虚拟机相关的操作,使用driver架构,支持多 种虚拟化技术 -
nova-consoleauth:为vnc代理服务器提供token验证服务 -
nova-novncproxy:为浏览器和vncserver之间建立socket,console用来连接到虚机的console接口,实现基于vnc的登录和操作 -
nova-cert:对接EC2-API的时候才使用,为euca-bundle-image提 供证书 databasemessage queue
-
-
查看nova服务列表命令:
nova service-list
Nova Compute与Hypervisor
-
nova通过driver架构支持多种Hypervisor

-
在nova.conf中可配置使用的compute_driver类型
nova-compute定期向OpenStack报告计算节点的状态*,实现instance的生命周期管理
-
通过nova-compute和Hypervisor一起可实现对虚拟机的生命周期管理
主要操作-
launch/terminate:创建虚拟机、终止虚拟机(终止即删除*) -
start/shutoff/reboot:虚拟机的开机、关机、重启操作,硬重启可以是soft/hard reboot -
snapshot:创建快照,对虚拟机的disk镜像文件(不含云硬盘)进行全量备份,生成一个类型为snapshot的image保存在glance中,快照恢复相当于通过snapshot image创建虚拟机 -
pause/resume:暂停虚拟机,将虚拟机状态保存到宿主机内存中,resume的时候再从内存中读回 虚拟机状态继续运行。暂停状态(状态为paused)的虚拟机可以连接到console,但无法登录操作。 -
suspend/resume:挂起虚拟机,将虚拟机状态保存到宿主机硬盘中,resume的时候再从宿主机中 读回虚拟机状态继续运行。挂起状态(状态为suspended)的虚拟机无法连接到console。 -
shelf/unshelf:为虚拟机创建一个快照并将快照的image文件保存在glance中,虚拟机状态变为 Shelved Offloaded,电源状态为shut down。unshelve相当于通过快照恢复虚拟机。 -
lock/unlock:对被加锁的 instance 执行重启等改变状态的操作会提示操作不允许, 执行解锁操作后 恢复正常。admin 角色的用户不受 lock 的影响,无论加锁与否都可以正常执行操作。 -
migrate/live migrate /evacuate:迁移操作只能在管理界面进行,在线迁移时不中断虚拟机运行。 -
resize:变更虚拟机配置,默认会关闭再启动虚拟机 -
rebuild:选择一个image镜像重建虚拟机,可用于虚拟机的恢复 -
其他操作:绑定/解绑定Floating IP、增加/删除虚拟网卡、编辑虚拟机信息、编辑安全组、console登录、查看日志等
-
Nova Conductor和Nova Scheduler
- Nova Conductor

- Nova Scheduler
- Nova中的调度服务
- 决定如何安排新创建的虚拟机(VM Placement)
- 创建虚机的时候进行调度
- 不同于DRS
- 创建 Instance 时,用户会提出资源需求,例如 CPU、内存、磁盘各需要多少。OpenStack 将 这些需求定义在 flavor 中,用户只需要指定用哪个 flavor 就可以了。
- Flavor 主要定义了 vCPU,RAM,Disk和 Metadata 这四类。 nova-scheduler 会按照 flavor 去选择合适的计算节点。
- Filter scheduler 是 nova-scheduler 默认的调度器

Nova Scheduler:Filter Scheduler
- Filter Scheduler调度过程分为两步:
- 通过过滤器(filter)选择满足条件的计算节点(运行 nova-compute)
- 通过权重计算(weighting)选择在最优(权重值最大)的计算节点上创建 Instance

Nova Scheduler:Filter
- nova.conf 中的 scheduler_available_filters 选项用于配置 scheduler 可用的
filter,默认是所有 nova 自带的 filter 都可以用于滤操作。
- nova.conf 中的 scheduler_default_filters 选项用于指定 scheduler 真正使 用的 filter

-
RetryFilter:过滤掉之前已经调度过的节点 -
AvailabilityZoneFilter:根据用户的选择,调度到所选的AZ中 -
RamFilter:将不能满足所选Flavor内存需求的计算节点过滤掉* -
DiskFilter:将不能满足Flavor磁盘需求的计算节点过滤掉 -
ComputeFilter:只有nova-compute服务正常工作的计算节点才能©被2016调Unite度dStack Inc. All Ri
-
Nova Scheduler:weight
- 经过Filter 的过滤,nova-scheduler 选出了能够部署 instance 的计算节点
- 最终选择哪个节点由 weight 来决定

Nova:相关概念

-
Region:针对endpoint的最大概念,endpoint在一个region中是唯一的,region之间完全隔离,有自己 的计算/网络/存储资源,但可以共享Keystone和Horizon -
Availability zone:region内的再次划分,可以理解为一个故障域,AZ对用户可见,创建云主机时可选择 可用域 -
Host aggregate:根据某一属性对硬件的划分,HA只对管理员可见,scheduler可根据参数实现到指定Host aggregate的调度 -
Cell:用于大规模部署时增强nova的横向扩展能力,每个cell有单独的MQ和DB
Nova:Availability Zone与Host Aggregate


Nova:Cell

- 什么是Cell
- G版本引入的nova新内容
- 增强横向扩展
- 如何工作
- 每个Cell有单独的MQ与DB
- 包含nova-api外的所有nova进程
- 如何理解
- Nova-cell类比nova-scheduler
- 每个cell就是一个nova-compute
- 注意
- Cell只针对Nova
- 用途
- 提高集群扩展性
- 在不同的cell之间进行信息同步和虚机调度
- 一个region可以划分多个cell
- 每个cell有单独的数据库和消息队列
- 大规模集群解决方案
块存储Cinder

Openstack中的存储概念
- 存储概念
- 临时块存储
- 与虚拟机生命周期相同
- 作为虚机的本地文件系统
- 虚机的操作系统盘
- Nova管理
- 持久块存储
- 用户管理生命周期
- 虚机外挂磁盘
- 也可以作为虚机的系统盘
- 对象存储
- 用户管理生命周期
- 单独访问接口
- 保存文件
- 临时块存储
Cinder说明
- 块存储
- 卷(volume)
- 可读写
- 系统/扩展盘
- 只能挂载到一个虚机
- 状态与虚机无关
- 快照(snapshot)
- 只读
- 某个卷的某一时间点复制
- 可以用来生成一个卷
- 备份(backup)
- 卷的归档
架构与组件
- Cinder架构

- Cinder组件
-
cinder-api:接受api请求,调用cinder-volume -
cinder-scheduler:通过调度算法选择最合适的cinder-volume去创建volume -
cinder-volume:管理volume的服务和volume的生命周期。与后端存储协调 工作,通过driver架构支持多种backend storage作为volume provider -
cinder-backup:提供volume的备份服务。与后端实际提供备份空间的存储协 调工作,支持多种backup backend storage作为备份后端 -
backend storage:实际提供存储空间的存储设备/系统 -
backup storage backend:实际提供备份存储空间的存储设备/系统 databasemessage queue
-
Cinder scheduler:Filter
- Cinder中的调度服务
- 决定如何安排新创建的 volume
- 创建 volume 时,用户会提出资源需求,如存储容量、存储类型等, cinder scheduler 会按照 这些资源需求去选择合适的 cinder-volume。
- Filter scheduler 是 cinder-scheduler 默认的调度器

-
Filter Scheduler调度过程分为两步:- 1.通过过滤器(filter)选择满足条件的 cinder-volume
- 2.通过权重计算(weighting)选择通过最优(权重值最大)的 cinder-volume 创建 volume
-
AvailabilityZoneFilter:根据用户的选择,调度到所选的AZ中 -
CapacityFilter:将存储空间不满足 volume 创建需求的存储后端对应的 cinder-volume 过滤掉 -
CapabilityFilter:不同的存储后端可以有不同的volume type,创建 volume 时可通过 volume type指定需要的Capability,通过filter过滤掉不满足 type 的 cinder-volume
对象存储服务Swift

Cinder scheduler:weight

- 经过Filter 的过滤,cinder-scheduler 选出了能够创建 volume 的 cinder- volume
- 最终选择哪个节点由 weight 来决定
- 默认的 weigher 是 CapacityWeigher,即基于容量来计算权重值
Cinder volume与后端存储
- cinder通过driver架构支持多种backend storage

- 在 cinder.conf 中可以配置使用的 driver 类型

Cinder volume与后端存储
- cinder-volume 为 volume provider 定义了统一的 driver 接口,volume provider 只需要实 现这些接口,就可以 driver 的形式即插即用到 OpenStack 中。在 marketplace 的 driver 列 表中可以查询到各厂商的 driver 信息。
- 官网地址:
http://www.openstack.org/marketplace/drivers/
Cinder volume与后端存储
- 通过 cinder-volume 和 后端存储 一起可实现对 存储卷 的生命周期管理
主要操作-
Create volume:创建存储卷,可以创建空白卷或从镜像创建卷 -
Delete volume:删除存储卷,存储卷的生命周期不依赖于虚拟机 -
Attach volume:存储卷挂载到虚拟机,初次挂载后需要分区和格式 -
Detach volume:存储卷从虚拟机解挂载 -
Extend volume:存储卷扩容 -
Snapshot volume:存储卷做快照 -
Boot from volume:从存储卷启动虚拟机(虚拟机操作系统放在存储卷上)
-

Cinder 与 Nova 的配合

-
两个层面
- 控制层面
- 数据层面
-
控制和数据的分离,数据不用经过 cinder-volume
Cinder:Cinder backup
- 存储卷的备份
- 支持多种存储后端,可以在 cinder.conf 文件中配置
- NFS
- Ceph
- Tivoli Storage Manager
- Swift
- GlusterFS

网络服务Neutron

Neutron:核心概念
-
Neutron 为整个 OpenStack 环境提供网络支持,包括二层交换,三层路由,负载均衡,安全组,防火墙 等。
Neutron 提供了一个灵活的框架,无论是开源还是商业软件,都可以通过配置被用来实现这些功能。 -
二层交换(Switching)
- Nova 的 instance 通过虚拟交换机连接到虚拟二层网络
- Neutron 支持多种虚拟交换机,包括 Linux 原生的 Linux Bridge 和 Open vSwitch
- 支持 VLAN 网络和 VxLAN 网络
-
三层路由(Routing)
- Instance 可以配置不同网段的 IP,Neutron 的 vRouter 实现 instance 跨网段通信
- vRouter 通过 IP forwarding,iptables 等技术来实现路由和 NAT
-
负载均衡(Load Balancing)
- 负载均衡服务(LBaaS),提供将负载分发到多个 instance 的能力
- LBaaS 支持多种负载均衡产品和方案,不同的实现以 Plugin 的形式集成到 Neutron,目前默认的 Plugin 是 HAProxy
-
安全组(Security Group)
- 通过 iptables 限制进出 instance 的网络包
-
防火墙(Firewalling)
- FWaaS,限制进出虚拟路由器的网络包,通过 iptables 实现或者 Plugin 的形式集成到Neutron
-
Network(网络)
一个隔离的二层广播域。Neutron 支持多种类型的 network,包括local, flat, VLAN, VxLAN 和 GRE
-
Subnet(子网)
- 一个 IPv4 或者 IPv6 地址段,instance 的 IP 从 subnet 中分配。每个 subnet 需要定义 IP 地址的范围 和掩码
- subnet 与 network 是 多对1 关系。同一个network 下的subnet 可以是不同的 IP 段,但不能重叠。不同 network下的subnet 的IP是可以重叠的

-
Port(端口)
- port 可以看做虚拟交换机上的一个端口。port 上定义 了 MAC 地址和 IP 地址,当 instance 的虚拟网卡 VIF
- (Virtual Interface) 绑定到 port 时,port 会将 MAC 和 IP 分配给 VIF
Port属于某个subnet,与subnet是多对1关系。
Neutron:组件和架构

-
组件和架构
-
neutron server:接受api请求,调用 plugin处理请求 -
neutron plugin:处理 neutron server 发来的请求,维护网络逻辑状态,并调用 agent 处理请求(core plugin, service plugin) -
neutron agent:处理 plugin 的请求,负责在 network provider 上真正实现各种网络功能(L2 agent, L3 agent, DHCP agent) -
network provider:实际提供网络服务的虚拟或物理网络 设备,如Linux Bridge、Open vSwitch或者网络厂商的设 备 databasemessage queue
-
-
查看neutron命令
neutron agent-list
Neutron:plugin
-
plugin 按照功能分为两类: core plugin 和 service plugin。core plugin 维护 Neutron 的 netowork, subnet 和 port 相关资源的信息,与 core plugin 对应的 agent 包括 linux bridge, Open
vSwitch 等; service plugin 提供 routing, firewall, load balance 等服务,也有相应的 agent。
-
plugin 的一个主要工作是在数据库中维护 Neutron 网络的状态信息,以前的 core-plugin 架构带来一个问题,所有 network provider 的 plugin 都要编写一套类似的数据库访问代码,绝大部代码是重复的。并且无法同时使用多种 network provider
-
Neutron 在 Havana 版本实现了一个 ML2(Modular Layer 2)plugin,对 plugin 的功能进行抽象和封装,各种 network provider 无需开发自己的 plugin,只需要针对 ML2 开发相应的 driver 就可以了。ML2实现二层网络拓扑与底层实现的解耦

Neutron:plugin 和 agent
-
neutron.conf
-
ml2_conf.ini
- L2 agent
- Linux bridge
- Open vSwitch
- ……
- L3 agent
- Router
- DHCP agent
- Service agent
- Load Balance
- Firewall
- VPN
- ……


常见组网:Linux Bridge

Linux Bridge:bridge 和 tap



Router namespace



常见组网:Open vSwitch

Swift:体系架构

-
访问层,负责处理用户的请求和用户身份的认证
-
Proxy server:对外提供对象服务RestFul API,可横向扩展,一方面 转发认证服务器进行用户信息认证,一方面将请求转发至相应的账户、 容器或者对象服务; -
Authentication Server:验证访问用户的身份信息,并获得一个对 象访问令牌(Token),在一定的时间内会一直有效
-
-
存储层,负责对象数据的实际存储
- 存储层的物理层次划分:
region、zone、storage node、device、 partition - 每个storage node上存储对象的逻辑层次划分:
account、container、object - 每个逻辑层次对应运行在storage node上的一种服务:
account server、container server、 object server
- 存储层的物理层次划分:
-
Swift通过 Ring 来实现对象与真正的物理存储位置的映射
-
Swift通过
Updater、Replicator、Auditor这三种服务来保 证数据一致性 -
每个对象有一定数量的副本(replica,默认为3个),每个副 本存放在不同的zone中,对象的副本是通过partition的副本实现的,即,Swift管理副本的粒度是partition而非单个对象
-
存储层的物理层次划分:
-
Region:地理上互相隔离的区域 -
Zone:region内部,硬件上的隔离,一个zone可以映射为一个硬盘、一台主机或一个机柜。通常可理解为一个zone 代表一组独立的互相隔离的storage node -
Storage node:存储对象数据的物理节点 -
Device:可理解为存储节点上的磁盘 -
Partition:device上的文件系统中的目录
-
-
存储对象的逻辑层次划分:
-
Account:和个人账户不是一个概念,可理解为租户,用来做顶层的隔离机制,可以被多个个人账户所共同使用 -
Container:代表封装一组对象,类似文件夹或目录,container是扁平的,不能嵌套
-
Object:对象是叶节点,由元数据和内容两部分组成(对象可以有虚拟的文件层级pseudo-folder)
-
-
Proxy Server 运行在 Proxy Node上,接收用户HTTP请求
-
请求路由到相应的
Controller:AccountController、ContainerController、ObjectController -
Controller从对应的 Ring 文件中获取请求数据所在的存储 节点Storage node,然后再将请求转发给该节点上的相应Server:AccountServer、ContainerServer、ObjectServer,最终进行具体的操作
-
Object server:提供对象元数据和内容服务,每个对象的内容会 以文件的形式存储在文件系统中,元数据会作为文件属性来存储,需要采用支持扩展属性的文件系统(如XFS) -
Container server:提供容器元数据和统计信息,并维护所含对 象列表的服务,每个容器的信息也存储在一个 SQLite 数据库中 -
Account server:提供账户元数据和统计信息,并维护所含容器
列表的服务,每个账户的信息被存储在一个 SQLite 数据库中
-
Swift:Ring
-
Ring:Swift 通过 Ring 来实现物理节点的管理,包括记录对象与物理存储位置间的映射, 物理节点的添加和删除等。

-
Ring的数据结构,包括是三种重要信息:
- 设备表:对所有 device 编号,设备表中每一项对应一个device,记录device的各种信息
- 设备查询表:存储 Partition 的各个副本与具体 device 的映射信息
- Partition移位值:表示在哈希之后将Object名字二进制移位的位数

-
存储对象与物理位置间的映射:
- 映射分为两层,1) 对象到Partition; 2)Partition到存储节点(device)
- 1)对象到Partition:通过哈希函数和二进制位移操作计算对象到虚拟空间Partition的映射(可将 对象均匀分布到虚拟空间的Partition上)
- 2) Partition到存储节点:通过设备查询表完成

-
物理节点的添加和删除:
添加或者删除物理节点(device)后,需要执行 swift-ring-builder 的 rebalance 命令重新平衡数 据。Ring rebalance 过程是生成了不同的 Ring 文件,更新了设备表和设备查询表,更新
Partition 和 device 之间的映射关系。最终 Partition 的移动是由 Replicator 来实际完成。
Swift:数据一致性
-
分布式系统CAP(Consistency,Availability,Partition Tolerance)理论,无法同时满足 3 个方面,Swift 放弃严格一致性而采用最终一致性模型(Eventual Consistency),来达 到高可用性和无限水平扩展能力。
-
N:数据的副本总数;W:写操作被确认接受的副本数量;R:读操作的副本数量
-
Swift 采用比较折中的策略,写操作需要满足至少一半以上成功 W >N/2,再保证读操作与 写操作的副本集合至少产生一个交集,即 R+W>N。
-
Swift 默认配置是 N=3,W=2>N/2,R=1 或 2
- N=3 每个对象会存在 3 个副本,这些副本会尽量被存储在不同区域的节点上
- W=2 表示至少需要更新 2 个副本才算写成功
- 当 R=1 时意味着某一个读操作成功便立刻返回,此种情况下可能会读取到旧版本;当 R=2 时,需 要通过在读操作请求头中增加 x-newest=true 参数来同时读取 2 个副本的元数据信息,然后比较 时间戳来确定哪个是最新版本;如果数据出现了不一致,后台服务进程会在一定时间窗口内通过检 测和复制协议来完成数据同步,从而保证达到最终一致性。
-
Swift通过三种服务来保证数据一致性:
-
Auditor:检查 object,container 和 account 的完整性,如果发现比特级的错误,文件将 被隔离,并复制其他的副本以覆盖本地损坏的副本(实际的复制工作由replicator完成); 其他类型的错误会被记录到日志中 -
Updater:当 object 或 container 由于高负载的原因而无法立即更新时,任务将会被序列 化到在本地文件系统中进行排队,以便服务恢复后进行异步更新 -
Replicator:检测本地节点的分区副本和远程副本是否一致,发现不一致时会将过时副本更 新为最新版本;另外一个任务是负责并将被标记为删除的数据真正从物理介质上删除。
-
Swift:扩展
- Restful API:GET/PUT/POST/DELETE/HEAD

- Storage polices:
- 默认是replication副本的方式,可以采用Erasure Coding纠删码的方式。每个 container可以关联一个storage policy并应用到container中的所有object
- Storage policy和object ring之间通过storage policy的索引号来一一映射

编排服务Heat

简介
-
什么Heat
-
- Heat 是一套业务流程平台,旨在帮助用户更轻松地配置以 OpenStack 为基础的云体系。利用Heat应用程序,开发人员能够在程序中使用模板以实现资源的自动化部署。Heat能够启动应用、创建虚拟机并自动处理整个流程。它还拥有出色的跨平台兼容性,能够与 Amazon Web Services 业务流程平台 CloudFormation 相对接——这意味着用户完全可以将 AWS 模板引入 OpenStack 环境当中。
-
- Heat 是 OpenStack 提供的自动编排功能的组件,基于描述性的模板,来编排复合云应用程序。
-
-
为什么需要Heat
-
- 更快更有效的管理 OpenStack 的资源:云平台系统在相对比较稳定的情况下,管理成本逐渐变成首要的解决问题。云上自动化能力是一个云平台的刚需,可以有效降低维护难度。Heat 采用了模板方式来设计或者定义编排,为方便用户使用,Heat 还提供了大量的模板例子,使用户能够方便地得到想要的编排。
-
- 更小的研发成本:引入 Heat,对于不了解 OpenStack 的研发者来说,可以更快的接入现有的业务系统。开发者更关心的是授权认证和对虚拟资源的增删改,而对于底层的状态并不用太多了解。
-
-
概念
-
- 堆栈(stack):管理资源的集合。单个模板中定义的实例化资源的集合,是 Heat 管理应用程序的逻辑单元,往往对应一个应用程序。
-
- 模板(template):如何使用代码定义和描述堆栈。描述了所有组件资源以及组件资源之间的关系,是 Heat 的核心。
-
- 资源(resource):将在编排期间创建或修改的对象。资源可以是网络、路由器、子网、实例、卷、浮动IP、安全组等。
-
- 参数(parameters):heat模板中的顶级key,定义在创建或更新 stack 时可以传递哪些数据来定制模板。
-
- 参数组(parameter_groups):用于指定如何对输入参数进行分组,以及提供参数的顺序。
-
- 输出(outputs):heat模板中的顶级key,定义实例化后 stack 将返回的数据。
-
架构
- 核心架构

-
-
heat command-line client:CLI通过与 heat-api 通信,来调用 API 实现相关功能。终端开发者可以直接使用编排 REST API。
-
-
-
heat-api:实现 OpenStack 原生支持的 REST API。该组件通过把 API 请求经由 AMQP 传送给 Heat engine 来处理 API 请求。
-
-
-
heat-api-cfn:提供与 AWS CloudFormation 兼容的、AWS 风格的查询 API,处理请求并通过 AMQP 将它们发送到 heat-engine。
-
-
-
heat-engine:执行模板内容,最终完成应用系统的创建和部署,并把执行结果返回给 API 调用者。
-
-
-
heat-cfntools:完成虚拟机实例内部的操作配置任务,需要单独下载。
-
-
工作流程
-
- 用户在 Horizon 中或者命令行中提交包含模板和参数输入的请求
-
- Horizon 或者命令行工具会将接收到的请求转化为 REST 格式的 API 调用 Heat-api 或者是 Heat-api-cfn。
-
- Heat-api 和 Heat-api-cfn 会验证模板的正确性,然后通过 AMQP 异步传递给 Heat Engine 来处理请求。
-
- Heat Engine 接收到请求后,会把请求解析为各种类型的资源,每种资源都对应 OpenStack 其它的服务客户端,然后通过发送 REST 的请求给其它服务。
-
- Heat Engine 在这里的作用分为三层: 第一层处理 Heat 层面的请求,就是根据模板和输入参数来创建 Stack,这里的 Stack 是由各种资源组合而成。 第二层解析 Stack 里各种资源的依赖关系,Stack 和嵌套 Stack 的关系。第三层就是根据解析出来的关系,依次调用各种服务客户段来创建各种资源。

模板
-
概念:Heat 模板全称为heat orchestration template,简称为HOT。
-
模板详解
1.典型 Heat 模板结构
heat_template_version: -- ### HOT版本
description: ### 说明
# a description of the template
parameter_groups: ### 指定参数顺序
- label: <human-readable label of parameter group>
description: <description of the parameter group>
parameters:
- <param name>
- <param name>
parameters: ### 传递的参数
<param name>: ### 参数名
type: <string | number | json | comma_delimited_list | boolean> ### 参数类型
label: <human-readable name of the parameter> ### 标签
description: <description of the parameter>
default: <default value for parameter>
hidden: <true | false> ### 是否隐藏
constraints: ### 已有的内置参数:OS::stack_name、OS::stack_id、OS::project_id
<parameter constraints>
immutable: <true | false>
resources: ### 资源对象
<resource ID>: ### 资源的ID
type: <resource type> ### 资源的类型
properties: ### 资源的属性
<property name>: <property value>
metadata: ### 资源的元数据
<resource specific metadata>
depends_on: <resource ID or list of ID>
update_policy: <update policy>
deletion_policy: <deletion policy>
outputs: ### 返回值
<parameter name>: ### 参数名
description: <description> ### 说明
value: <parameter value> ### 输出值
例子
heat_temp_version:--
Description: AWS::CloudWatch::Alarm using Ceilometer.
parameters:
user_name:
type: string
label: User Name
description: User name to be configured for the application
port_number:
type: number
label: Port Number
description: Port number to be configured for the web server
resources:
my_instance:
type: OS::Nova::Server
properties:
flavor: m1.small
image: F18-x86_64-cfntools
outputs:
instance_ip:
description: IP address of the deployed compute instance
value: { get_attr: [my_instance, first_address] }
模板内部函数
-
- get_attr:获取所创建资源的属性
语法
get_attr:
- <resource name> ### 必须是模板 resouce 段中指定的资源。
- <attribute name> ### 要获取的属性,如果属性对应的值是list 或map, 则可以指定key/index来获取具体的值。
- <key/index > (optional)
- <key/index > (optional)
- ...
示例
resources:
my_instance:
type: OS::Nova::Server
# ...
outputs:
instance_ip:
description: IP address of the deployed compute instance
value: { get_attr: [my_instance, first_address] }
instance_private_ip:
description: Private IP address of the deployed compute instance
value: { get_attr: [my_instance, networks, private, ] }
-
- get_file:获取文件的内容
语法
get_file: <content key>
示例
resources:
my_instance:
type: OS::Nova::Server
properties:
# general properties ...
user_data:
get_file: my_instance_user_data.sh
my_other_instance:
type: OS::Nova::Server
properties:
# general properties ...
user_data:
get_file: http://example.com/my_other_instance_user_data.sh
-
- get_param:引用模板中指定的参数
语法
get_param:
- <parameter name>
- <key/index 1> (optional)
- <key/index 2> (optional)
- ...
示例
parameters:
instance_type:
type: string
label: Instance Type
description: Instance type to be used.
server_data:
type: json
resources:
my_instance:
type: OS::Nova::Server
properties:
flavor: { get_param: instance_type}
metadata: { get_param: [ server_data, metadata ] }
key_name: { get_param: [ server_data, keys, 0 ] }
输出
{"instance_type": "m1.tiny",
{"server_data": {"metadata": {"foo": "bar"},"keys": ["a_key","other_key"]}}}
-
- get_resource:获取模板中指定的资源
语法
get_resource: <resource ID>
示例
resources:
instance_port:
type: OS::Neutron::Port
properties: ...
instance:
type: OS::Nova::Server
properties:
...
networks:
port: { get_resource: instance_port }
-
- list_join:使用指定的分隔符将一个list中的字符串合成一个字符串
语法
list_join:
- <delimiter>
- <list to join>
示例输出:one,two,three
list_join: [', ', ['one', 'two', 'and three']]
-
- digest:在指定的值上使用algorithm
语法
digest:
- <algorithm> ### 可用的值是hashlib(md5, sha1, sha224, sha256, sha384, and sha512) 或openssl的相关值
- <value>
示例
# from a user supplied parameter
pwd_hash: { digest: ['sha512', { get_param: raw_password }] }
-
- repeat:迭代fore_each中的列表,按照template的格式生成一个list
语法
repeat:
template:
<template>
for_each:
<var>: <list>
示例
parameters:
ports:
type: comma_delimited_list
label: ports
default: "80,443,8080"
protocols:
type: comma_delimited_list
label: protocols
default: "tcp,udp"
resources:
security_group:
type: OS::Neutron::SecurityGroup
properties:
name: web_server_security_group
rules:
repeat:
for_each:
<%port%>: { get_param: ports }
<%protocol%>: { get_param: protocols }
template:
protocol: <%protocol%>
port_range_min: <%port%>
结果
[{‘protocal’:tpc, ‘prot_range_min’:},
{‘protocal’:tpc, ‘prot_range_min’:},
{‘protocal’:tpc, ‘prot_range_min’:},
{‘protocal’:udp, ‘prot_range_min’:},
{‘protocal’:udp, ‘prot_range_min’:},
{‘protocal’:udp, ‘prot_range_min’:}]
-
- str_replace:使用params中的值替换template中的占位符,从而构造一个新的字符串
语法
str_replace:
template: <template string>
params: <parameter mappings>
示例
resources:
my_instance:
type: OS::Nova::Server
# general metadata and properties ...
outputs:
Login_URL:
description: The URL to log into the deployed application
value:
str_replace:
template: http://host/MyApplication
params:
host: { get_attr: [ my_instance, first_address ] }
-
- str_split:将一个字符串按照分隔符分隔成一个list
语法
str_split:
- ','
- string,to,split
示例
str_split: [',', 'string,to,split']
结果
['string', 'to', 'split']
常用操作
-
一、栈、资源、模板管理

-
二、软件、快照管理

计量服务 Ceilometer

简介
背景
-
为什么要有Ceilometer
-
- 通常云的计算层次
-
- 计量 (Metering): 收集资源的使用数据,其数据信息主要包括:使用对象(what), 使用者(who), 使用时间(when)和 用量(how much)。
-
- 计费 (Rating):将资源使用数据按照商务规则转化为可计费项目并计算费用。
-
- 结算 (Billing):收钱开票
-
- Ceilometer 的目标是计量(Metering) 方面,为上层的计费、结算或者监控应用提供统一的资源使用数据收集功能。
-
-
历史
-
- 项目始于2012年四五月份,10月份发布第一个版本,实现对一些重要数据的计量,包括Compute, Network, Memory, CPU, Image, Volume等,并且提供了REST API。
-
- 2013年作为OpenStack发行版的计量计费功能的项目,后来逐步发展增加了部分监控采集和告警等功能。
-
- 但是由于种种原因,Ceilometer项目在Openstack中已经处于一种没落的状态,基本没有什么新的特性开发了,原本该项目的PTL也另起炉灶开始在做Gnocchi项目(ceilometer的后端存储系统)。
-
- 虽然该项目已经没有前几年活跃,但是还是在很多公有云场景中有比较多的应用,而生产环境中,可能很多公司还用的是M、N版本。
-
概念
-
- Meter
-
- 概念:资源使用的某些测量值(计量项,监控项),如内存占用、网络IO、磁盘IO等。
-
- 属性:名称(name)、单位 (unit)、类型 (cumulative:累计值;delta:变化值;gauge:离散或者波动值)以及对应的资源属性等。
-
- Sample
-
- 概念:每个采集时间点上meter对应的值(某时刻某个 resource 的某个 meter 的值),收集数据具有时间间隔。
-
- 属性:测量值(meter)、采样时间(timestampe)和采样值(Volume)。
-
- Statistics:某个周期内(Period)的Samples聚合值,包括计数(Count)、最大(Max)、最小(Min)、平均 (Avg)、求和(Sum)等
-
- Resource:被监控的资源对象,如虚拟机、磁盘等

- Resource:被监控的资源对象,如虚拟机、磁盘等
-
- Alarm
-
- 概念:告警机制,可以通过阈值或者组合条件告警,并设置告警时触发的action,但是相对ceilometer是独立的一块,只是放在了ceilometer的代码树里面。
-
- 类型
-
- 阈值告警(Threshold Alarm):根据一个监控项的阈值去判断Alarm的状态,它包括几个要素:
-
- 一个静态阈值和比较方法 (a static threshold value & comparison operator)
-
- 指定的 meter statistic (against which a selected meter statistic is compared)
-
- 比较的时间窗 (over an evaluation window of configurable length into the recent past.)
-
- 组合告警(Combination Alarm):根据多个监控项建立一个Alarm,多个alarm之间是or/and的关系。
-
- 属性
-
- name: 告警名称
-
- meter-name:meter 名称
-
- threshold: 阈值
-
- comparison_operator: 比较方式,有6个可选:lt, le, eq, ne, ge, gt,默认是eq
-
- statistic: 比较方式,有5种可选:max, min, avg, sum, count,默认是avg
-
- period: 获取该监控指标的监控数据的时间周期
-
- evaluation_periods:统计次数
-
- alarm-action:告警产生后的动作
-
- Action(动作)
-
- ‘log://’:Alarm 被写入 Log 文件
-
- Webhook URL: 这是一个 HTTP(S) endpoint 的URL,例如 ‘http://130.56.250.199:8080/alarm/instances_TOO_MANY’。Alarm 的内容会以 JSON 的格式被 POST 到该URL 中。
组件
-
- 控制节点
-
- Central Agent: 调用OpenStack其它组件api采集指标
-
- Notification Agent:接收其它组件主动上报的通知消息
-
- Collector:基于AMQP接收消息,并记录到DataStore
-
- API:运行在管理节点,提供接口访问Data Store
-
- 计算节点
-
- Compute Agent:采集本节点性能指标
数据处理
数据收集

-
- Poller方式
-
- Compute agent (ceilometer-agent-compute)运行在每个 compute 节点上,以轮询的方式通过调用 Image 的 driver 来获取资源使用统计数据。
-
- Central agent (ceilometer-agent-central)运行在 management server 上,以轮询的方式通过调用 OpenStack 各个组件(包括 Nova、Cinder、Glance、Neutron、Swift 等)的 API 收集资源使用统计数据。
-
- Notificaiton方式

- Notificaiton方式
数据处理
-
- Pipeline(处理器)

-
- Meters 数据的处理使用 Pipeline 的方式,即Metes 数据依次经过(零个或者多个) Transformer 和 (一个或者多个)Publisher 处理,最后达到(一个或者多个)Receiver。其中Recivers 包括 Ceilometer Collector 和 外部系统。
-
- Ceilometer 根据配置文件 /etc/ceilometer/pipeline.yaml 来配置 meters 所使用的 transformers 和 publishers。以 cpu meter 为例:
- Pipeline(处理器)
sources: A source is a producer of samples
......
- name: cpu_source
interval: 600 ## Poller 获取 cpu samples 的间隔为 10 分钟
meters:
- "cpu"
sinks:
- cpu_sink
......
sinks: A sink on the other hand is a chain of handlers of samples
......
- name: cpu_sink
transformers: ## 转换器
- name: "rate_of_change"
parameters:
target:
name: "cpu_util"
unit: "%"
type: "gauge"
scale: "100.0 / (10**9 * (resource_metadata.cpu_number or1))"
publishers: ## 分发器
- notifier://
-
- Transformer (转换器)
-
- unit_conversion:单位转换器,比如温度从°F 转换成°C
-
- rate_of_change::计算方式转换器,比如根据一定的计算规则来转换一个sample
-
- accumulator:累计器,如下图所示

- accumulator:累计器,如下图所示
-
- Publisher(分发器)


- Publisher(分发器)
数据保存
-
- Ceilometer Collector 从 AMQP 接收到数据后,会原封不动地通过一个或者多个分发器(dispatchers)将它保存到指定位置。目前它支持的分发器:
-
- 文件分发器:保存到文件 - 添加配置项dispatcher = file 和 [dispatcher_file] 部分的配置项
-
- HTTP 分发器:保存到外部的 HTTP target - 添加配置项 dispatcher = http
-
- 数据库分发器:保存到数据库 - 添加配置项 dispatcher = database。


- 数据库分发器:保存到数据库 - 添加配置项 dispatcher = database。
-
- Ceilometer 支持同时配置多个分发器,将数据保存到多个目的位置。比如在 ceilometer.conf 中做如下配置使得同时使用 file 和 database dispatcher:
[DEFAULT]
dispatcher = database
dispatcher = file
[dispatcher_file]
backup_count = 5
file_path = /var/log/ceilometer/ceilometer-samples
max_bytes = 100000
数据访问
-
- 外部系统通过 ceilometer-api 模块提供的 Ceilometer REST API 来访问保存在数据库中的数据。API 有 V1 和 V2 两个版本,现在使用的是 V2.

- 外部系统通过 ceilometer-api 模块提供的 Ceilometer REST API 来访问保存在数据库中的数据。API 有 V1 和 V2 两个版本,现在使用的是 V2.
告警
-
- 架构
-
- ceilometer-alarm-evaluator 使用 Ceilometer REST API 获取 statistics 数据
-
- ceilometer-alarm-evaluator 生成 alarm 数据, 并通过 AMQP 发给 ceilometer-alarm-notifer
-
- ceilometer-alarm-notifer 会通过指定方式把 alarm 发出去。

- ceilometer-alarm-notifer 会通过指定方式把 alarm 发出去。
-
- Heat 和 Ceilometer 通过 Ceilometer Alarm 进行交互来实现 Instance auto-scaling


- Heat 和 Ceilometer 通过 Ceilometer Alarm 进行交互来实现 Instance auto-scaling
架构
核心架构


京东对 Ceilometer 的优化 (摘自京东架构师在2015年初OpenStack meetup 上的材料)

常用操作

OpenStack创建VM,服务间交互示例
-
提问:创建一个VM需要些什么资源?
在OpenStack中创建虚拟机实例,资源需求和物理PC类似。文章来源:https://www.toymoban.com/news/detail-458510.html -
OpenStack创建VM,服务间交互示例如图
 文章来源地址https://www.toymoban.com/news/detail-458510.html
文章来源地址https://www.toymoban.com/news/detail-458510.html
到了这里,关于OpenStack介绍说明、OpenStack架构说明、OpenStack核心服务说明、OpenStack创建VM,服务间交互示例的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!