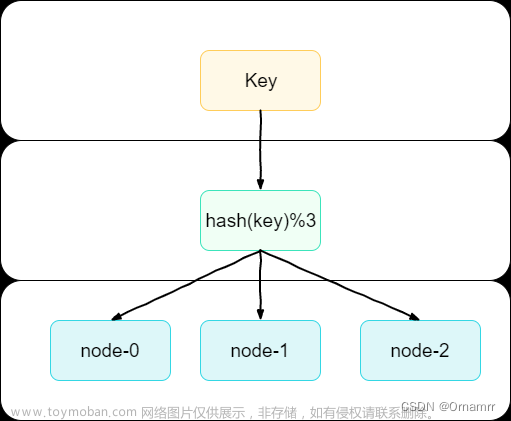
如果你有 n 个缓存服务器,一个常见的负载均衡方式是使用以下的哈希方法:
服务器索引 = 哈希(键) % N,其中 N 是服务器池的大小。
让我们通过一个例子来说明这是如何工作的。如表5-1所示,我们有4台服务器和8个字符串键及其哈希值。
为了获取存储某个键的服务器,我们执行模运算 f(键) % 4。例如,哈希(键0) % 4 = 1 意味着客户端必须联系服务器1来获取缓存的数据。图5-1展示了基于表5-1的键的分布。
当服务器池的大小固定且数据分布均匀时,这种方法工作得很好。然而,当新的服务器被添加,或者现有的服务器被移除时,就会出现问题。例如,如果服务器1离线,服务器池的大小就变成了3。使用相同的哈希函数,我们得到的键的哈希值是相同的。但是应用模运算会因为服务器数量减少了1而得到不同的服务器索引。我们应用 哈希 % 3 得到的结果如表5-2所示:
图5-2展示了基于表5-2的新键分布。
如图5-2所示,大多数键都被重新分配了,而不仅仅是那些最初存储在离线服务器(服务器1)中的键。这意味着,当服务器1离线时,大多数缓存客户端将连接到错误的服务器来获取数据。这导致了一场缓存未命中的风暴。一致性哈希是一种有效的技术来缓解这个问题。
一致性哈希
引用自维基百科:"一致性哈希是一种特殊的哈希,使得当哈希表大小改变且使用一致性哈希时,平均只有 k/n 个键需要被重新映射,其中 k 是键的数量,n 是槽位的数量。相比之下,在大多数传统哈希表中,数组槽位数量的变化导致几乎所有的键都需要被重新映射[1]”。
哈希空间和哈希环
现在我们理解了一致性哈希的定义,让我们了解它是如何工作的。假设使用SHA-1作为哈希函数f,哈希函数的输出范围是:x0, x1, x2, x3, ..., xn。在密码学中,SHA-1的哈希空间从0到2^160 - 1。也就是说,x0 对应0,xn 对应2^160 - 1,所有其他的哈希值都落在0和2^160 - 1之间。图5-3展示了哈希空间。
通过连接两端,我们得到一个如图5-4所示的哈希环:
哈希服务器
使用相同的哈希函数f,我们根据服务器的IP或名字将服务器映射到环上。图5-5显示了4台服务器被映射到哈希环上。
哈希键
值得一提的是,这里使用的哈希函数与“重哈希问题”中的不同,并且没有模运算。如图5-6所示,4个缓存键(key0,key1,key2和key3)被哈希到哈希环上。
服务器查找
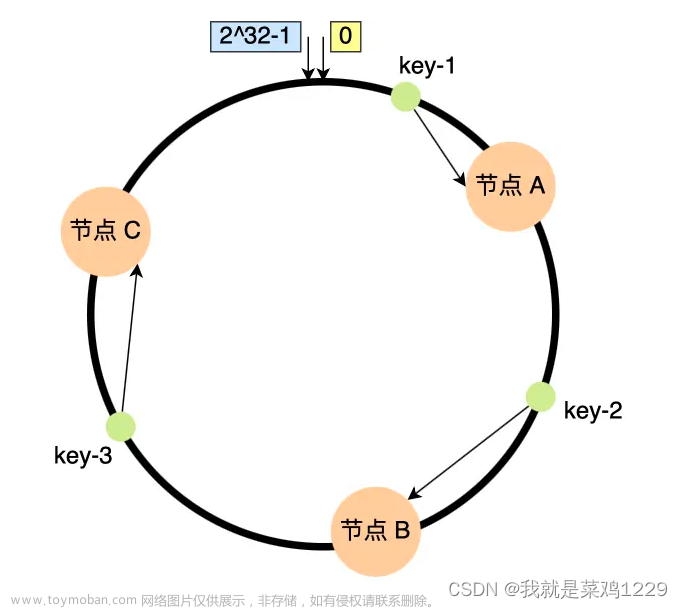
为了确定一个键存储在哪个服务器上,我们从环上的键位置顺时针方向进行寻找,直到找到一个服务器。图5-7解释了这个过程。顺时针方向,key 0 存储在 server 0上;key1 存储在 server 1 上;key2 存储在 server 2 上;key3 存储在 server 3 上。
添加服务器
使用上述逻辑,添加新服务器只需要重新分配一部分键。
在图5-8中,新增 server 4 后,只有 key0 需要被重新分配。k1, k2, 和 k3 仍然在相同的服务器上。让我们仔细看看这个逻辑。在 server 4 添加之前,key0 存储在 server 0 上。现在,key0 将存储在 server 4 上,因为 server 4 是它从环上的 key0 位置顺时针方向遇到的第一个服务器。其他的键根据一致性哈希算法不需要重新分配。
移除服务器
当服务器被移除时,只有少部分的键需要通过一致性哈希进行重新分配。在图5-9中,当 server 1 被移除时,只有 key1 必须被映射到 server 2。其余的键不受影响。
基本方法中的两个问题
一致性哈希算法是由MIT的Karger等人提出的[1]。基本步骤如下:
- 使用均匀分布的哈希函数将服务器和键映射到环上。
- 要找出键映射到哪个服务器,从键位置开始顺时针方向找到环上的第一个服务器。
这种方法存在两个问题。首先,考虑到服务器可能会被添加或移除,不可能在环上为所有服务器保持相同大小的分区。分区是相邻服务器之间的哈希空间。每个服务器被分配到的环上的分区大小可能非常小或者相当大。在图5-10中,如果s1被移除,s2的分区(双向箭头高亮表示)就是s0和s3分区的两倍大。
第二,环上的键分布可能非均匀。例如,如果服务器映射到图5-11中列出的位置,大部分的键都存储在server 2上。然而,server 1 和 server 3 没有任何数据。
一种被称为虚拟节点或副本的技术被用来解决这些问题。
虚拟节点
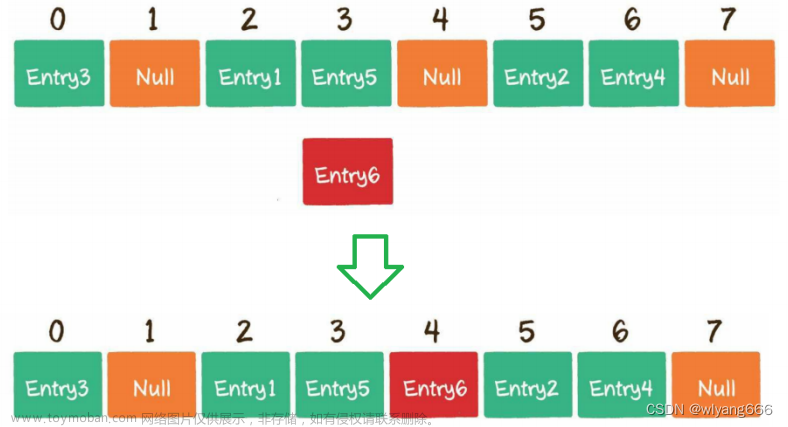
虚拟节点是指实际节点,每个服务器在环上都由多个虚拟节点表示。在图5-12中,server 0 和 server 1 都有3个虚拟节点。这个3是随意选择的;在实际系统中,虚拟节点的数量要多得多。我们不再使用 s0,而是使用 s0_0, s0_1 和 s0_2 来在环上表示 server 0。同样,s1_0, s1_1 和 s1_2 在环上表示 server 1。有了虚拟节点,每个服务器就负责多个分区。标签为 s0 的分区(边)由 server 0 管理。另一方面,标签为 s1 的分区由 server 1 管理。
要找出一个键存储在哪个服务器上,我们从键的位置顺时针方向去找环上遇到的第一个虚拟节点。在图5-13中,要找出k0存储在哪个服务器上,我们从k0的位置顺时针方向找到虚拟节点s1_1,它指向server 1。
随着虚拟节点数量的增加,键的分布变得更加均衡。这是因为随着虚拟节点数量的增加,标准差变得更小,导致数据分布均衡。标准差衡量了数据的分散程度。在线研究的一项实验结果[2]表明,当有一百或两百个虚拟节点时,标准差在均值的5%(200个虚拟节点)到10%(100个虚拟节点)之间。当我们增加虚拟节点数量时,标准差会变小。然而,我们需要更多的空间来存储虚拟节点的数据。这是一个权衡,我们可以调整虚拟节点的数量以适应我们的系统需求。
找到受影响的键
当添加或移除一个服务器时,部分数据需要被重新分布。我们如何找到受影响的范围以重新分配键呢?
在图5-14中,server 4被添加到环中。受影响的范围从s4(新添加的节点)开始,逆时针移动到找到一个服务器(s3)。因此,位于s3和s4之间的键需要被重新分配给s4。
当一个服务器(s1)如图5-15所示被移除时,受影响的范围从s1(被移除的节点)开始,逆时针绕环移动到找到一个服务器(s0)。因此,位于s0和s1之间的键必须被重新分配给s2。
总结
在这一章,我们深入讨论了一致性哈希,包括为什么需要它以及它是如何工作的。一致性哈希的好处包括:
- 当服务器被添加或移除时,最小化键的重新分布。
- 因为数据更均匀地分布,所以易于横向扩展。
- 缓解热点键问题。过度访问特定的分片可能导致服务器过载。想象一下,Katy Perry、Justin Bieber和Lady Gaga的数据全部都在同一个分片上。一致性哈希通过更均匀地分布数据来缓解这个问题。
一致性哈希在现实世界的系统中被广泛应用,包括一些著名的系统:
- Amazon的Dynamo数据库的分区组件 [3]
- Apache Cassandra中跨集群的数据分区 [4]
- Discord聊天应用 [5]
- Akamai内容分发网络 [6]
- Maglev网络负载均衡器 [7]
恭喜你走到这一步!现在给自己一个赞。干得好!
参考资料
[1] 一致性哈希:https://en.wikipedia.org/wiki/Consistent_hashing
[2] 一致性哈希:
https://tom-e-white.com/2007/11/consistent-hashing.html
[3] Dynamo:亚马逊的高可用键值存储:
https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
[4] Cassandra - 一个去中心化的结构化存储系统:
http://www.cs.cornell.edu/Projects/ladis2009/papers/Lakshman-ladis2009.PDF
[5] 如何将Discord Elixir扩展到500万并发用户:
https://blog.discord.com/scaling-elixir-f9b8e1e7c29b
[6] CS168:现代算法工具箱第一课:简介和一致性哈希:http://theory.stanford.edu/~tim/s16/l/l1.pdf文章来源:https://www.toymoban.com/news/detail-459051.html
[7] Maglev:一个快速可靠的软件网络负载均衡器:
https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/44824.pdf文章来源地址https://www.toymoban.com/news/detail-459051.html
到了这里,关于什么是一致性哈希?一致性哈希是如何工作的?如何设计一致性哈希?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!