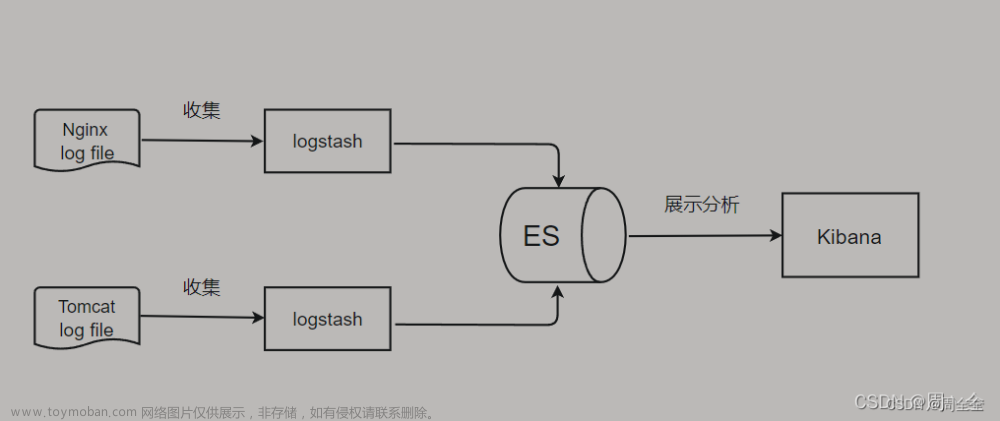
1、索引相关
查看集群状态
http://127.0.0.1:9200/_cluster/health
创建索引
curl -XPUT 10.9.39.37:9200/test_cycle-order_20227_1
查看所有索引
http://127.0.0.1:9200/_cat/indices
查看索引信息
http://127.0.0.1:9200/index_name
{
"user-info": {
"aliases": {},
"mappings": {
"_doc": {
"properties": {
"address": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"age": {
"type": "long"
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"sex": {
"type": "long"
}
}
}
},
"settings": {
"index": {
"creation_date": "1670915768780",
"number_of_shards": "5",
"number_of_replicas": "1",
"uuid": "An2CYpuxSq-6sh0vWRjS2g",
"version": {
"created": "6040299"
},
"provided_name": "user-info"
}
}
}
}
删除索引
curl -XDELETE 127.0.0.1:9200/index_name
2、高级查询 DSL
2.1 查询所有 match_all
使用match_all,默认只会返回10条数据
curl -X GET 'http://10.9.39.37:9200/user-info/_doc/_search' \
-H 'Accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"query":{
"match_all":{
}
}
}'
{
//查询花费的总时间
"took": 1,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
//符合条件的总文档数
"total": 1,
"max_score": 1.0,
//结果集,默认10
"hits": [
{
"_index": "user-info",
"_type": "_doc",
"_id": "1",
"_score": 1.0,
"_source": {
"name": "张三",
"age": 18,
"address": "北京市朝阳区",
"sex": 1
}
}
]
}
}
返回指定条数
{
"query": {
"match_all": {}
},
"size":50
}
size 不能无限大,如果过大会出现异常
{
"error": {
"root_cause": [
{
"type": "query_phase_execution_exception",
"reason": "Result window is too large, from + size must be less than or equal to: [10000] but was [99999]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."
}
],
"type": "search_phase_execution_exception",
"reason": "all shards failed",
"phase": "query",
"grouped": true,
"failed_shards": [
{
"shard": 0,
"index": "user-info",
"node": "uyvZR82uTVGEdPxthCCYHg",
"reason": {
"type": "query_phase_execution_exception",
"reason": "Result window is too large, from + size must be less than or equal to: [10000] but was [99999]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."
}
}
]
},
"status": 500
}
1、查询结果的窗口太大,from + size的结果必须小于或等于10000,而当前查询结果的窗
口为20000。
2、可以采用scroll api更高效的请求大量数据集。
3、查询结果的窗口的限制可以通过参数index.max_result_window进行设置。
注意:参数index.max_result_window主要用来限制单次查询满足查询条件的结果窗口的 大小,窗口大小由from + size共同决定。不能简单理解成查询返回给调用方的数据量。这 样做主要是为了限制内存的消耗。 比如:from为1000000,size为10,逻辑意义是从满足条件的数据中取1000000到 (1000000 + 10)的记录。这时ES一定要先将(1000000 + 10)的记录(即 result_window)加载到内存中,再进行分页取值的操作。尽管最后我们只取了10条数据返 回给客户端,但ES进程执行查询操作的过程中确需要将(1000000 + 10)的记录都加载到 内存中,可想而知对内存的消耗有多大。这也是ES中不推荐采用(from + size)方式进行 深度分页的原因。
同理,from为0,size为1000000时,ES进程执行查询操作的过程中确需要将1000000 条 记录都加载到内存中再返回给调用方,也会对ES内存造成很大压力。
2.2 分页查询 from
{
"query": {
"match_all": {}
},
"from": 0,
"size": 9999
}
2.3 深分页查询 scroll
最佳实践还是根据异常提示中的采用scroll api更高效的请求大量数据集。
- 查询命令中新增scroll=3000ms,说明采用游标查询,保持游标查询窗口3000毫秒
- 这里由于测试数据量不够,所以size值设置为
- 实际使用中为了减少游标查询的次数,可以将size值适当增大,比如设置为1000
curl -X GET 'http://10.9.39.37:9200/user-info/_doc/_search?scroll=3000ms' \
-H 'Accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"query": {
"match_all": {}
},
"size": 2
}'
{
"_scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAACCBzjFnV5dlpSODJ1VFZHRWRQeHRoQ0NZSGcAAAAAB9aKqBZzVkIwYk5kMlNVbWwybnJDaXZwb1VnAAAAAAqiPgUWaUxYa0tPcHZUaHE0bm16TUpZVkpOZwAAAAACCBziFnV5dlpSODJ1VFZHRWRQeHRoQ0NZSGcAAAAAB9aKpxZzVkIwYk5kMlNVbWwybnJDaXZwb1Vn",
"took": 1,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 7,
"max_score": 1.0,
"hits": [
{
"_index": "user-info",
"_type": "_doc",
"_id": "5",
"_score": 1.0,
"_source": {
"name": "1211111",
"age": 18,
"address": "北京市朝阳区",
"sex": 1
}
},
{
"_index": "user-info",
"_type": "_doc",
"_id": "8",
"_score": 1.0,
"_source": {
"name": "娃娃",
"age": 18,
"address": "北京市朝阳区",
"sex": 1
}
}
]
}
}
除了返回前2条记录,还返回了一个游标ID值_scroll_id。
采用游标ID查询
curl -X GET 'http://10.9.39.37:9200/_search/scroll' \
-H 'Accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"scroll": "1m",
"scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAACCDZHFnV5dlpSODJ1VFZHRWRQeHRoQ0NZSGcAAAAAB9aaaxZzVkIwYk5kMlNVbWwybnJDaXZwb1VnAAAAAAqiVaMWaUxYa0tPcHZUaHE0bm16TUpZVkpOZwAAAAACCDZIFnV5dlpSODJ1VFZHRWRQeHRoQ0NZSGcAAAAAB9aabBZzVkIwYk5kMlNVbWwybnJDaXZwb1Vn"
}'
{
"_scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAACCDZHFnV5dlpSODJ1VFZHRWRQeHRoQ0NZSGcAAAAAB9aaaxZzVkIwYk5kMlNVbWwybnJDaXZwb1VnAAAAAAqiVaMWaUxYa0tPcHZUaHE0bm16TUpZVkpOZwAAAAACCDZIFnV5dlpSODJ1VFZHRWRQeHRoQ0NZSGcAAAAAB9aabBZzVkIwYk5kMlNVbWwybnJDaXZwb1Vn",
"took": 1,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 8,
"max_score": 1.0,
"hits": []
}
}
多次根据scroll_id游标查询,直到没有数据返回则结束查询。采用游标查询索引全量数据, 更安全高效,限制了单次对内存的消耗。
2.3 指定字段排序 sort
注意:会让得分失效
curl -X GET 'http://10.9.39.37:9200/user-info/_doc/_search' \
-H 'Accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"query": {
"match_all": {}
},
"size": 5,
"sort":[
{
"age":"desc"
}
]
}'
排序分页
{
"query": {
"match_all": {}
},
"size": 5,
"from": 5,
"sort": [
{
"age": "desc"
}
]
}
2.4 返回指定字段_source
{
"query": {
"match_all": {}
},
"size": 5,
"from": 5,
"sort": [
{
"age": "desc"
}
],
"_source":["age","name"]
}
2.5 关键词 match
match在匹配时会对所查找的关键词进行分词,然后按分词匹配查找
{
"query": {
"match": {
"age":18
}
},
"size": 5,
"from": 5,
"sort": [
{
"age": "desc"
}
],
"_source":["age","name"]
}
2.5 多字段查询 multi_match
{
"query": {
"multi_match": {
"query": "张三",
"fields": [
"name",
"address"
]
}
},
"size": 5,
"from": 5,
"sort": [
{
"age": "desc"
}
],
"_source": [
"age",
"name"
]
}
2.6 query_string
允许我们在单个查询字符串中指定AND | OR | NOT条件,同时也和 multi_match query 一样,支持多字段搜索。和match类似,但是match需要指定字段名,query_string是在所 有字段中搜索,范围更广泛
{
"query": {
"query_string": {
"query": "张三 or 娃娃22211"
}
},
"size": 100,
"from": 0,
"sort": [
{
"age": "desc"
}
],
"_source": [
"age",
"name"
]
}
指定单个字段查询
{
"query": {
"query_string": {
"default_field": "address",
"query": "张三 or 娃娃22211"
}
},
"size": 100,
"from": 0,
"sort": [
{
"age": "desc"
}
],
"_source": [
"age",
"name"
]
}
指定多个字段查询
{
"query": {
"query_string": {
"fields": [
"name",
"address"
],
"query": "张三 or 娃娃22211"
}
},
"size": 100,
"from": 0,
"sort": [
{
"age": "desc"
}
],
"_source": [
"age",
"name"
]
}
2.6 关键词查询 term
Term用来使用关键词查询(精确匹配),还可以用来查询没有被进行分词的数据类型。Term是 表达语意的最小单位,搜索和利用统计语言模型进行自然语言处理都需要处理Term。 match在匹配时会对所查找的关键词进行分词,然后按分词匹配查找,而term会直接对关 键词进行查找。一般模糊查找的时候,多用match,而精确查找时可以使用term文章来源:https://www.toymoban.com/news/detail-459122.html
{
"query": {
"term": {
"name": {
"value": "张三"
}
}
},
"size": 100,
"from": 0,
"sort": [
{
"age": "desc"
}
]
}
采用term精确查询, 查询字段映射类型为keyword文章来源地址https://www.toymoban.com/news/detail-459122.html
{
"query": {
"term": {
"address.keyword": {
"value": "北京市朝阳区"
}
}
},
"size": 100,
"from": 0,
"sort": [
{
"age": "desc"
}
]
}
到了这里,关于ES常用命令与常用查询(1)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!