论文名称:Segment Anything
论文地址:https://arxiv.org/abs/2304.02643
开源地址:https://github.com/facebookresearch/segment-anything
demo地址:Segment Anything | Meta AI
主要贡献:开发一个可提示的图像分割的基础模型,在一个广泛的数据集上预训练,解决新数据分布上的一系列下游分割问题
1. Introduction
 1.1 任务
1.1 任务
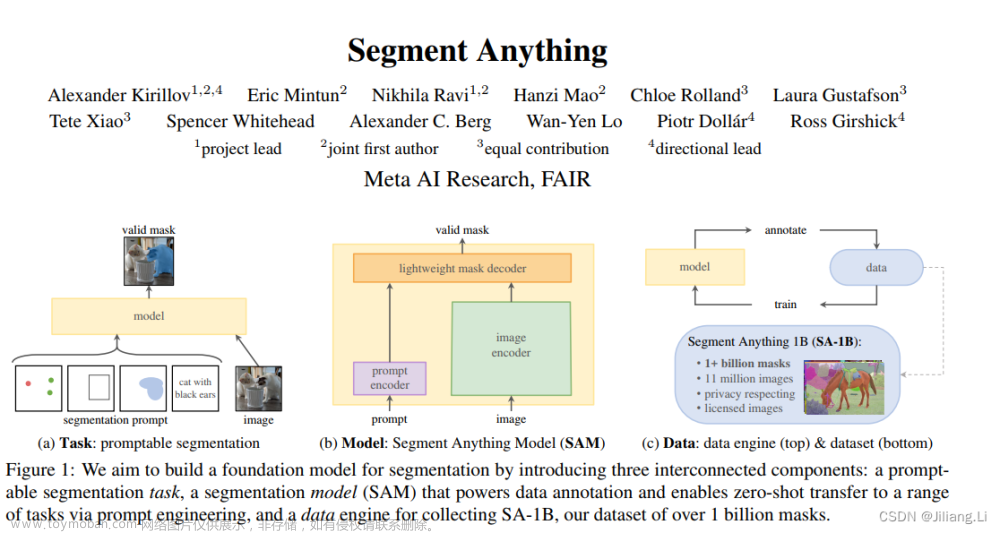
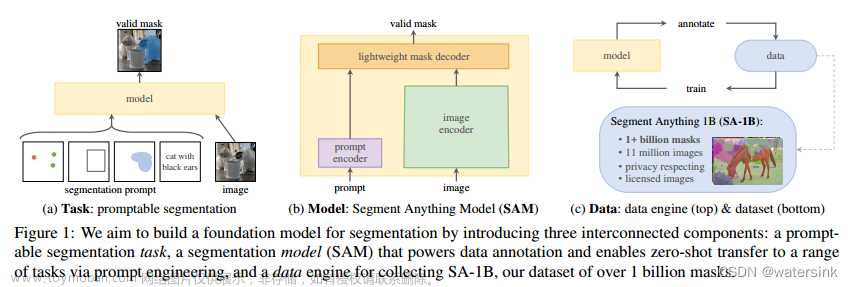
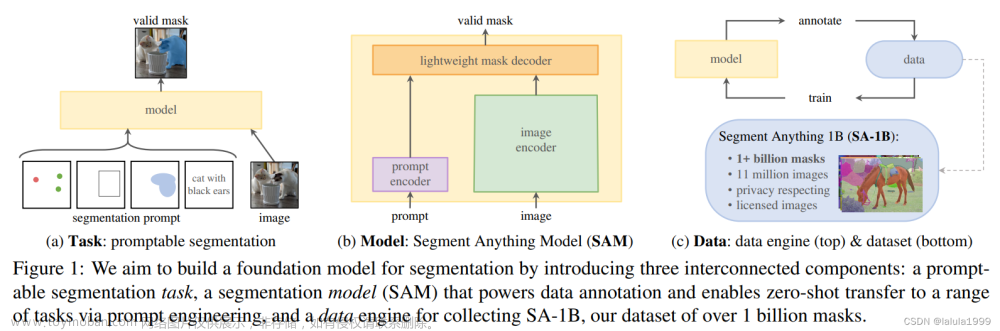
通过使用‘prompt’技术对新的数据集和任务执行zero shot和few shot学习受到启发,提出可交互式图像分割模型,目标是在给定任何分割提示下返回一个有效的分割掩码(见图1a)。提示只是指定要在图像中分割的内容,可以有效的输出,即使提示是模棱两可的,可以指多个对象,输出应该是一个合理的至少一个对象的mask。使用提示分割任务作为训练前的目标,并通过提示工程来解决一般的下游分割任务。
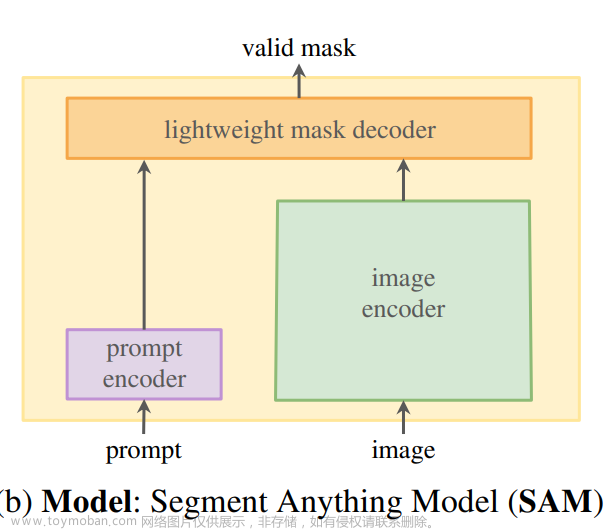
1.2 模型
提示词编码器嵌入提示+图像编码器计算图像嵌入+轻量级掩码解码器中来预测分割掩码=Segment Anything,SAM(见图1b)。通过将SAM分离为一个图像编码器和一个快速提示编码器/掩码解码器,相同的图像嵌入可以用不同的提示被重用。给定一个图像嵌入,提示编码器和掩码解码器在web浏览器中以50毫秒的提示预测掩码。关注点、框和掩码提示,并使用自由形式的文本提示显示初始结果。
1.3 数据
数据用于模型训练,模型检测未知数据,构建一个“数据引擎”。在第一阶段,SAM协助注释器对掩码进行注释,类似于经典的交互式分割设置。在第二阶段,SAM可以通过提示可能的对象位置来为对象子集自动生成掩码,注释器专注于对其余对象的注释,帮助增加掩码的多样性。在最后一个阶段,我们用一个规则的前景点网格提示SAM,平均每张图像产生100个高质量的掩模。最终得到1100万张授权的图片上有超过10亿个尊重隐私的掩码数据。
2. Segment Anything Task
2.1 任务
首先将提示的想法从 NLP 转换为分割,其中提示可以是一组前景/背景点、粗略框或掩码、自由形式的文本,或者任何指示图像中分割什么的信息。根据提示返回一个有效的分割掩码。“有效”意味着,即使提示模棱两可,可以引用多个对象(例如衬衫与人的例子),输出也至少是其中一个合理的掩码。类似于期望一个语言模型对一个模糊的提示输出一个一致的响应。该任务导向了一种自然的预训练算法和一种通过提示将zero shot 转移到下游分割任务的通用方法。
2.2 预训练
可提示的分割任务提出了一种自然的预训练算法,该算法模拟每个训练样本的一系列提示(例如,点、框、掩码),并将模型的掩码预测与基本事实进行比较。我们采用交互分割的方法,与旨在最终在足够的用户输入后预测有效掩码的交互分割不同,我们的目标是始终为任何提示预测有效的掩码,即使提示不明确。这确保了预训练模型在涉及歧义的用例中是有效的,包括数据引擎所需的自动注释。
2.3 zero shot transfer
预训练任务赋予模型在推理时对任何提示做出适当反应的能力,因此下游任务可以通过工程适当的提示来解决。例如,如果一个有猫的目标检测器,则可以通过提供检测框输出作为我们模型的提示来解决猫实例分割。一般来说,广泛的实用分割任务可以被视为提示。
2.4 相关任务
分割是一个广泛的领域:交互式分割,边缘检测,超像素化,目标区域生成,前景分割,语义分割,实例分割,全景分割等。我们的可提示分割任务的目标是建立一种能力广泛的模型,可以通过提示工程适应许多(尽管不是全部)现有和新的分割任务该能力是任务泛化的一种形式。不同于多任务系统(单个模型执行一组固定的任务,如联合语义、实例和全光分割,训练和测试任务相同),我们的可提示分割的模型,可以作为一个更大的系统中的一个组件,在推理时执行一个新的、不同的任务,例如,执行实例分割,一个可提示分割模型与现有的目标检测器相结合。
2.5讨论
提示和组合是一种强大的工具,它使单个模型能够以可扩展的方式使用,并有可能完成在模型设计时未知的任务。类似于其他基础模型的使用方式,例如,CLIP如何使DALL·E图像生成系统的文本-图像对齐组件。
3. Segment Anything Model
SAM有三个组件,如图4所示:图像encoder、灵活的提示encoder和快速掩码decoder。我们建立在Vision Transformer上,对实时性能进行特定的权衡。如图
 3.1 图像编码器
3.1 图像编码器
基于可扩展和强大的预训练方法,我们使用MAE预训练的ViT,最小限度地适用于处理高分辨率输入。图像编码器对每张图像运行一次,在提示模型之前进行应用。
3.2 提示编码器
考虑两组提示:稀疏(点、框、文本)和密集(掩码)。通过位置编码来表示点和框,并将对每个提示类型的学习嵌入和自由形式的文本与CLIP中的现成文本编码相加。密集的提示(即掩码)使用卷积进行嵌入,并通过图像嵌入进行元素求和。
3.3 掩码解码器
掩码解码器有效地将图像嵌入、提示嵌入和输出token映射到掩码。该设计的灵感来自于DETR,采用了对(带有动态掩模预测头的)Transformer decoder模块的修改。
3.4 解决歧义
对于一个输出,如果给出一个模糊的提示,该模型将平均多个有效的掩码。为了解决这个问题,我们修改了模型,以预测单个提示的多个输出掩码(见下图,绿色点为输入的提示点)。我们发现3个掩模输出足以解决大多数常见的情况(嵌套掩模通常最多有三个深度:整体、部分和子部分)。在训练期间,我们只支持mask上的最小损失[匈牙利损失]。为了对掩码进行排名,该模型预测了每个掩码的置信度分数(即估计的IoU)
4. SAM Data engine
4.1 模型辅助手动注释阶段
4.2 包含自动预测掩码和模型辅助注释的半自动化阶段
4.3全自动阶段
5. 数据集
1100万张新图产生了1.1B个mask
7. Zero-Shot Transfer Experiments(熟悉的名称他来了)
7.1 zero shot 单点有效掩模评估
任务:评估从单个前景点分割一个对象,因为一个点可以指代多个对象。大多数数据集中的标签掩码不会枚举所有可能的掩码,这可能会使自动度量不可靠。因此,我们补充了标准mIoU度量(即预测和标签掩模之间的所有IoU的平均值),在该研究中,注释者将掩码质量从1(无意义)评级到10(像素完美)。
数据集:使用一套新编译的23个具有不同图像分布的数据集,来进行mIoU评估
7.2 zero shot 目标 proposal
接下来,我们评估了SAM在对象提案生成的中级任务上的作用。这项任务在目标检测研究中发挥了重要的作用,作为开创性系统的中间步骤。为了生成对象建议,我们运行一个稍微修改的自动掩码生成管道的版本,并将掩码输出为提案。
我们计算了LVIS v1 上的标准平均召回率(AR)度量。我们关注LVIS,因为它的大量类别是一个具有挑战性的测试。我们与作为ViTDet 检测器(带有级联掩模R-CNN ViT-H)实现的强基线进行了比较。
SAM在中型和大型物体以及稀有和普通物体上都优于ViTDet-H,在小对象和频繁对象上的表现低于ViTDet-H,其中ViTDet-H可以很容易地学习LVIS特定的注释偏差,因为它是在LVIS上训练的。我们还比较了消融的模糊模糊版本的SAM,它在所有AR指标上的表现都明显低于SAM。
7.3 zero shot 文本到掩码
最后,我们考虑一个更高层次的任务:从自由形式的文本中分割对象。这个实验证明了SAM处理文本提示的能力。SAM的训练过程被修改以使其能够感知文本,但其方式不需要新的文本注释。具体来说,对于每个手动收集的面积大于1002的掩模,我们提取了CLIP图像嵌入。然后,在训练过程中,我们将提取的CLIP图像嵌入作为第一次交互,提示SAM。这里的关键观察结果是,由于CLIP的图像嵌入被训练成与文本嵌入对齐,所以我们可以使用图像嵌入进行训练,但要使用文本嵌入进行推理。也就是说,在推理时,我们通过CLIP的文本编码器运行文本,然后将生成的文本嵌入作为提示符提供给SAM。当SAM不能仅从文本提示中选择正确的对象时,一个额外的点提示可以提供帮助。

8.总结
目标检测and分割什么的已经到顶了,研究点别的吧哈哈哈文章来源:https://www.toymoban.com/news/detail-459575.html
文章来源地址https://www.toymoban.com/news/detail-459575.html
到了这里,关于Segment Anything论文详解(SAM)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!