💕**今天的每一秒都是珍贵的,因为它永远不会再次出现。**💕
🐼作者:不能再留遗憾了🐼
🎆专栏:Java学习🎆
🚗本文章主要内容:深入理解哈希表(散列表),散列函数的几种构造方法以及解决哈希冲突的方法。🚗

前言
前面我们可能都了解过如何查找数据,一开始一般将数据放在顺序表中去查找,挨个比较key与array[i]的值是否相等,如果不相等就继续寻找下一个,直到找到相等的数据返回下标或者没找到返回-1。在学习了有序表之后我们可以先通过比较array[i]与key之间的大小关系来折半查找,直到找到与key相等的数据。
这些方法都是需要比较的而且时间效率不高,那么是否有一种方法既不需要比较也有较高的时间效率呢?当然有,那么今天我们就来学习学习这种高效查找的结构——哈希表(也叫作散列表)。
什么是哈希表
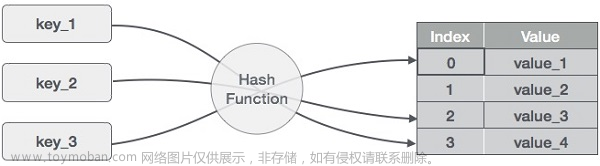
哈希表是指通过构建关键字与存储位置之间的对应的关系,使得每一个关键字key对应一个存储位置f(key)。在查找的时候,我们通过这个关系就可以直接找到key所在的对应位置,这样就大大省略了数据之间比较所需要的时间。
我们把这种对应关系成为散列函数或者哈希函数,采用散列技术讲记录存储在一块连续的存储空间中,这块连续存储的空间称为散列表或者哈希表。
哈希表相对于其他的查找结构有什么优缺点
优点
优点我们都知道,哈希表通过映射关系将数据存储在散列表(哈希表中),当我们需要取出数据的时候同样使用这个哈希关系来找到数据所在的位置,时间复杂度是O(1),这个查找速度是非常快的。
缺点
什么事物都有优缺点,哈希表也不例外。因为你是通过映射关系来确定数据的存储位置的,但不排序多个数据在同一个位置的情况,这种情况在哈希表中是不可避免的,称为哈希冲突。
例如:如果我们选择以男、女作为关键字,一个人不是男就女(但也不包括特殊情况啊),所以数据就全部存储在男和女这两个位置上,当我们查找的时候时间效率就会下降。
散列表不支持范围查找。因为哈希表中的键是通过哈希函数设计计算的一组散列值,存储在哈希表中的位置是无序的,查询时只能按照键值查找对应的值。
如果散列函数或者哈希函数设计的不合理时,也会发生严重的哈希冲突,所以如果要想设计一个好的哈希表关键是减少哈希冲突,不可能避免哈希冲突,也就是说需要我们设计一个适合的哈希(散列)函数。
构造哈希(散列)函数
什么算一个适合的哈希函数呢?
一个好的哈希(散列)函数应该包括以下这几个特点:
1.设计简单
哈希函数不能有过于复杂的算法,如果算法需要很复杂的计算,那么也需要耗费大量的时间。所以我们设计的哈希函数应该简单且合适。
2.使数据通过哈希函数之后分布的位置均匀
如果你哈希函数不能使数据分布的位置均匀一点,使数据都集中在一个地方,这样不仅很容易发生哈希冲突,还会导致空间的浪费。
1.直接定址法
如果我们需要统计一句英文短句中出现了哪些字母以及字母出现的次数,那么我们就可以使用哈希表来存储这些数据。
将字母作为key值,映射关系就直接将单词对应的ASCII码值作为哈希表的下标,但是因为数组的下标是从0开始的,而字母的ANSCII码值是在65 - 122这个范围的,如果直接将ANSCII码值作为数组下标的话,前面的65个内存将会被浪费,所以可以将字母的ANSCII码值减去‘A’后作为数组的下标,这样就可以使字母都存储在0 - 57的范围内,避免了空间的浪费。

这样的散列函数的优点就是简单、均匀,也不会发生冲突,但是要想这样做必须得提前知道关键字的分布情况,适合查找表较小且连续的情况。这种方法因为这种限制在生活中不常用。
2.数字分析法
如果我们想在一个学校中查找某个学生,我们可以通过学号号来查找,一般学号的前面的几位数往往表示你的入学时间,那么你们同年级的前几位往往是相同的,唯一不同的就是后面几位,我们在同一年级中查找就只需要查找后四位就可以了,所以我们就将学号后四位作为散列地址,如果这四位还是会发生冲突的话,我们还可以对其做出调整,例如对取出的数字进行反转、左旋或者右旋、叠加等。做出这些调整后就能大概使官字子均匀的分配在散列表的各个位置。
这种抽取关键字一部分来作为散列地址的方法是很常见的设计散列函数方法。这种方法通常适合处理关键字位数比较多的情况,如果事先知道关键字的分布且关键字若干位分布较均匀,就可以使用这个方法。
3.平方取中法
将关键字平方后取中间的3位或者若干位作为散列地址。这种方法比较适合不知道关键字的分布而位数也不是很多的情况。
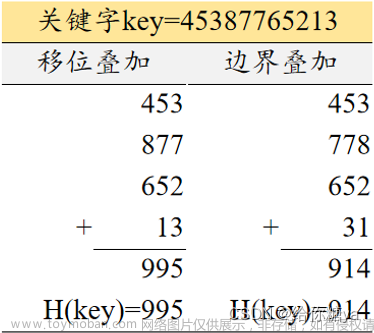
折叠法
折叠法是将关键字从左到右分割成位数相同的几部分(注意如果最后一部分位数不够的时候可以短一些),然后将这几部分叠加求和,并按散列表的表长,取后几位作为散列地址。
例如:关键字是9 8 7 6 5 4 3 2 1 0,散列表的长度为3位,所以我们每部分的长度为3,分为四组
9 8 7 | 6 5 4 | 3 2 1 | 0,然后叠加求和987+654+321+0 = 1962,取后面三位962作为散列地址,如果这样还可能发生较多冲突的时候,我们可以从一端向另一端来回折叠后对齐相加,例如将987和321反转然后再与321和0相加得到1566,散列地址为566。
折叠法事先不必知道关键字的分布,适合关键字位数较多的情况。
保留余数法
保留余数法是指用关键字 % p(p <= 散列表的长度),我们可以直接取模,也可以先对关键字进行折叠、平方取中后再取模。
这个方法的关键是选择合适的p,如果p选择的不合适的话也会发生较多的冲突,所以我们通常p取小于散列表长度的最大质数,因为质数的因子只有1和自己本身,取模不容易产生相同的结果。
随机数法
选择一个随机数,去关键字的随机函数值作为散列地址。也就是f(key) = random(key)。random是随机函数。
那么这里就会有人问了既然存储的时候是随机的散列地址,那么当我想要取出的时候该怎么办呢?他是否是我想要取出的值呢?答案是是的,即使你的关键字是字符串,里面包含了因为字符、中文字符和各种各样的符号,他们都可以转换为某种数字,并且产生的随机数其实是伪随机数。为什么这样说呢?因为伪随机数的生成过程需要一个称为“种子”的初始值,通过对种子进行某些运算(加、乘、平方等),递推生成一系列数值。由于种子和递推公式都是相同的,所以每次使用相同的种子都会产生相同的值。这就被称为伪随机数。
这种方法适合用在当关键字的长度不等的时候。
处理哈希(散列)冲突的方法
前面我们说过,哈希冲突是不可避免的,但是我们可以尽量减少产生哈希冲突。
1.开放寻址法
开放寻址法是指一旦发生了哈希冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录记下。
f(key) = (f(key)+ di)MOD m(di = 1,2,3,4···,m-1) MOD是取模

这种开放寻址法被称为线性探测法。
但是这种方法可能还是会使数据堆积在一个部分,所以我们可以对d的取值稍作调整。
f(key)= (f(key)+ di)MOD m(di = 1^2, -1^2, 2^2, -2^2,···, q^2, -q^2)
这样改变d的取值可以使在某个地址的左右两边都查找空位,并且每次查找的地址的间隔变大了,可以使数据分布更均匀。这种方法被称为二次探测法。
位移量d还可以通过随机函数来取值。
2.再散列函数法
我们可以事先多准备几个散列函数,当发生了散列冲突的时候,就换一个散列函数进行计算。
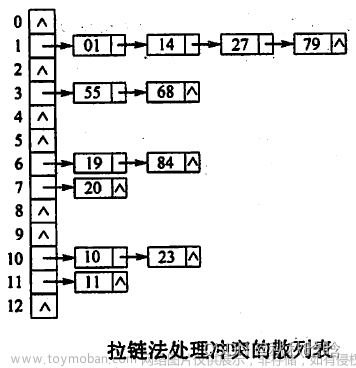
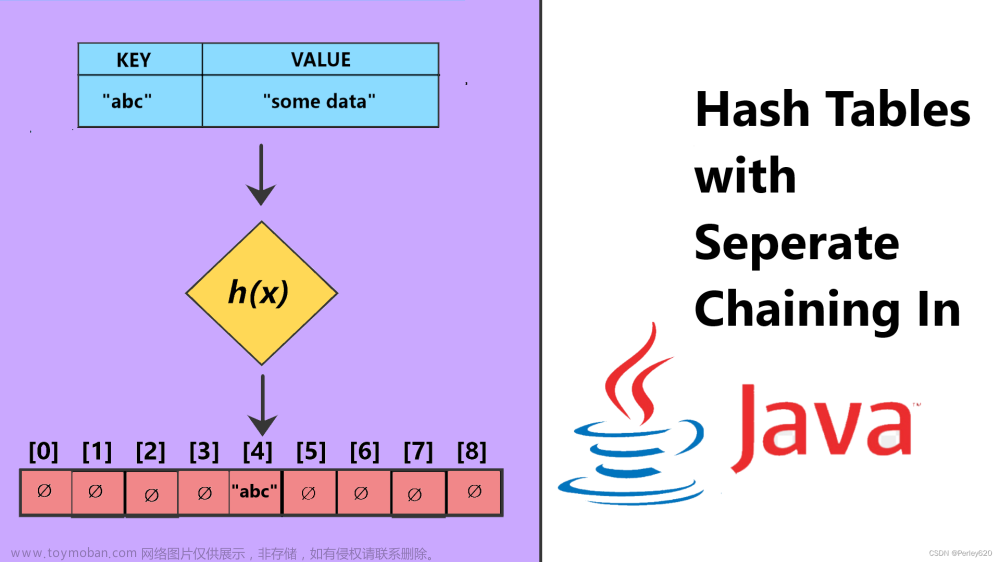
3.链地址法
当某个地址发生了散列冲突的时候,我们不需要换一个地方,只需要将这些冲突的数据放在一个单链表中,将这个单链表挂在该散列地址处,这种表也称为同义词子表。

用Java自己实现链地址法
这是使用Java语言来自己实现一个哈希桶,也就是链地址法。
public class HashBuck {
//每一个节点有三个域,key域、value域和指向下一个节点的域
static class Node {
public int key;
public int value;
Node next;
public Node(int key, int value) {
this.key = key;
this.value = value;
}
}
public Node[] array;
private int usedSize;
//这个是负载因子,负载因子 = 散列表中的数据个数 / 散列表的大小,
//通常当负载因子大于0.75的时候就容易发生哈希冲突,
// 所以我们就需要尽量使负载因子较小,散列表中的数据是不确定的,
//所以我们能做的就只能增加散列表的容量
public static final double LOAD_FACTOR = 0.75;
public HashBuck() {
this.array = new Node[10];
}
public void put(int key, int value) {
int index = key % array.length;
Node cur = array[index];
//当key值相同时,我们就需要在该散列地址的链表上查找该key,
//只需要将之前的value值更改就行了
while(cur != null) {
if(cur.key == key) {
cur.value = value;
return;
}
cur = cur.next;
}
//使用头插法
Node newNode = new Node(key,value);
newNode.next = array[index];
array[index] = newNode;
usedSize++;
//判断负载因子
double ret = calculateLoadFactor(usedSize);
//如果负载因子过大就扩容,但是当我们扩容之后key和散列地址的映射关系就改变了,
// 需要我们再去重新构建散列表
if(ret >= LOAD_FACTOR) {
reSize();
}
}
/**
* 当扩容的时候,key的映射关系不同了,所以需要重新构建哈希桶
*/
private void reSize() {
Node[] newArray = new Node[2*array.length];
for(int i = 0; i < array.length; i++) {
Node cur = array[i];
while(cur != null) {
int index = cur.key % newArray.length;
Node curNext = cur.next;
cur.next = newArray[index];
newArray[index] = cur;
cur = curNext;
}
}
array = newArray;
}
private double calculateLoadFactor(int usedSize) {
return usedSize * 1.0 / array.length;
}
public int get(int key) {
int index = key % array.length;
Node cur = array[index];
while(cur != null) {
if(cur.key == key) {
return cur.value;
}
cur = cur.next;
}
return -1;
}
4.公共溢出区法
当发生了散列冲突的时候,我们另外创建一个公共溢出区来存放冲突的数据。

这种方法在冲突数据很少的时候的速度是很快的。文章来源:https://www.toymoban.com/news/detail-459704.html
散列表的查找
查找的时候只用根据哈希(散列)函数找到对应的散列地址就行了,查询速度非常快。文章来源地址https://www.toymoban.com/news/detail-459704.html
到了这里,关于哈希表(散列表)详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!