概述
Kafka是一个分布式的消息队列系统,它的出现解决了传统消息队列系统的吞吐量瓶颈问题。
Kafka的高吞吐量、低延迟和可扩展性使得它成为了很多公司的首选消息队列系统。
在Kafka中,消息被分成了不同的主题(Topic),每个主题又被分成了不同的分区(Partition)。
生产者(Producer)将消息发送到指定的主题中,而消费者(Consumer)则从指定的主题中读取消息。
接下来我们将介绍Kafka消费者相关的知识。
Kafka消费者的工作原理
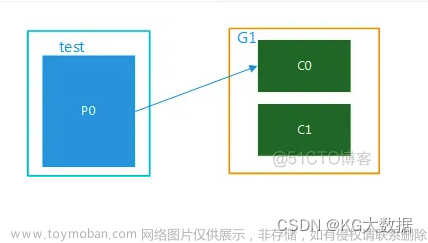
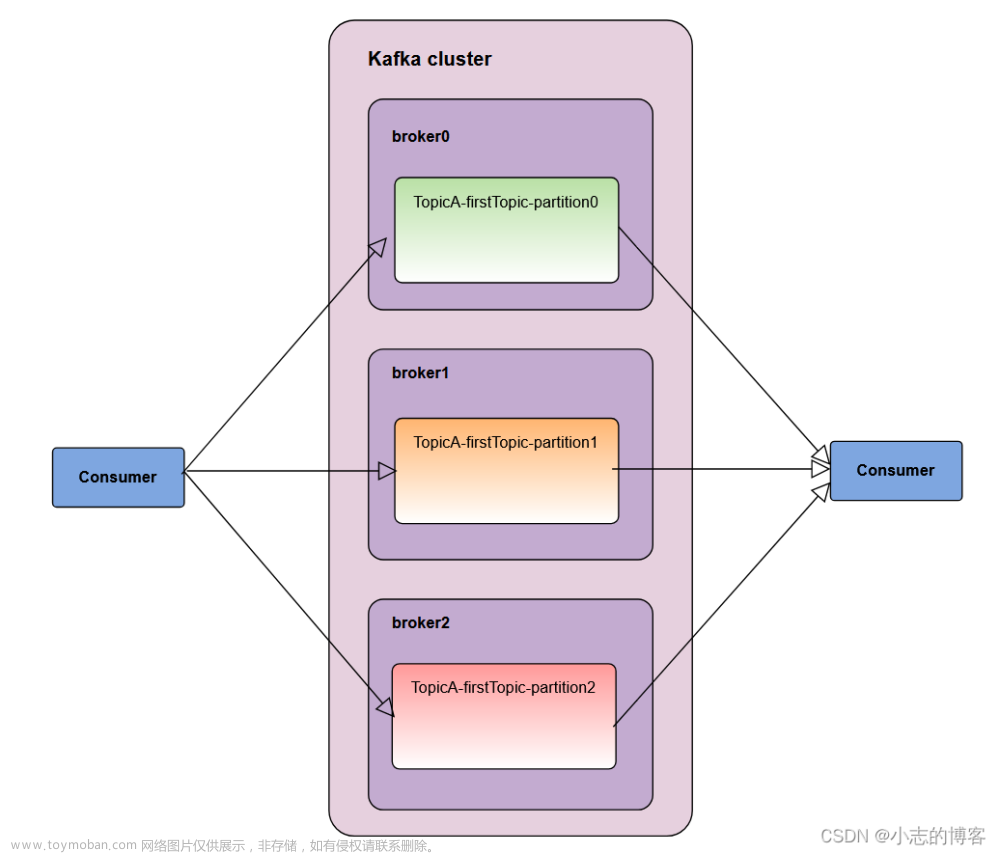
Kafka消费者从指定的主题中读取消息,消费者组(Consumer Group)则是一组消费者的集合,它们共同消费一个或多个主题。在一个消费者组中,每个消费者都会独立地读取主题中的消息。当一个主题有多个分区时,每个消费者会读取其中的一个或多个分区。消费者组中的消费者可以动态地加入或退出,这样就可以实现消费者的动态扩展。
Kafka消费者通过轮询(Polling)方式从Kafka Broker中读取消息。当一个消费者从Broker中读取到一条消息后,它会将该消息的偏移量(Offset)保存在Zookeeper或Kafka内部主题中。消费者组中的消费者会协调并平衡分区的分配,保证每个消费者读取的分区数量尽可能均衡。
Kafka消费者的配置
-
bootstrap.servers
该参数用于指定Kafka集群中的broker地址,多个地址以逗号分隔。消费者会从这些broker中获取到集群的元数据信息,以便进行后续的操作。
-
group.id
该参数用于指定消费者所属的消费组,同一消费组内的消费者共同消费一个主题的消息。如果不指定该参数,则会自动生成一个随机的group.id。
-
enable.auto.commit
该参数用于指定是否启用自动提交offset。如果设置为true,则消费者会在消费消息后自动提交offset;如果设置为false,则需要手动提交offset。
-
auto.commit.interval.ms
该参数用于指定自动提交offset的时间间隔,单位为毫秒。只有当enable.auto.commit设置为true时,该参数才会生效。
-
session.timeout.ms
该参数用于指定消费者与broker之间的会话超时时间,单位为毫秒。如果消费者在该时间内没有发送心跳包,则会被认为已经失效,broker会将其从消费组中移除。
-
max.poll.records
该参数用于指定每次拉取消息的最大条数。如果一次拉取的消息数量超过了该参数指定的值,则消费者需要等待下一次拉取消息。
-
auto.offset.reset
该参数用于指定当消费者第一次加入消费组或者offset失效时,从哪个位置开始消费。可选值为latest和earliest,分别表示从最新的消息和最早的消息开始消费。
-
max.poll.interval.ms
该参数用于指定两次poll操作之间的最大时间间隔,单位为毫秒。如果消费者在该时间内没有进行poll操作,则被认为已经失效,broker会将其从消费组中移除。
-
fetch.min.bytes
该参数用于指定每次拉取消息的最小字节数。如果一次拉取的消息数量不足该参数指定的字节数,则消费者需要等待下一次拉取消息。
-
fetch.max.wait.ms
该参数用于指定拉取消息的最大等待时间,单位为毫秒。如果在该时间内没有获取到足够的消息,则返回已经获取到的消息。
Kafka消费者的实现
Kafka消费者的实现可以使用Kafka提供的高级API或者低级API。高级API封装了低级API,提供了更加简洁、易用的接口。下面分别介绍一下这两种API的使用方法。
高级API
使用高级API可以更加方便地实现Kafka消费者。下面是一个使用高级API实现Kafka消费者的示例代码:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test-group");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("test-topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
在上面的代码中,我们首先创建了一个Properties对象,用于存储Kafka消费者的配置信息。然后创建了一个KafkaConsumer对象,并指定了要消费的主题。最后使用poll方法从Broker中读取消息,并对每条消息进行处理。
低级API
使用低级API可以更加灵活地实现Kafka消费者。下面是一个使用低级API实现Kafka消费者的示例代码:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test-group");
props.put("enable.auto.commit", "fal VCC se");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("test-topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
consumer.commitSync(Collections.singletonMap(record.topicPartition(), new OffsetAndMetadata(record.offset() + 1)));
}
}
在上面的代码中,我们首先创建了一个Properties对象,用于存储Kafka消费者的配置信息。然后创建了一个KafkaConsumer对象,并指定了要消费的主题。最后使用poll方法从Broker中读取消息,并对每条消息进行处理。在处理完每条消息后,我们使用commitSync方法手动提交偏移量。
导图

总结
Kafka消费者是Kafka消息队列系统中的重要组成部分,它能够从指定的主题中读取消息,并进行相应的处理。在使用Kafka消费者时,需要注意消费者组ID、自动提交偏移量、偏移量重置策略以及消息处理方式等配置信息。文章来源:https://www.toymoban.com/news/detail-459883.html
 文章来源地址https://www.toymoban.com/news/detail-459883.html
文章来源地址https://www.toymoban.com/news/detail-459883.html
到了这里,关于Apache Kafka - 重识消费者的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!