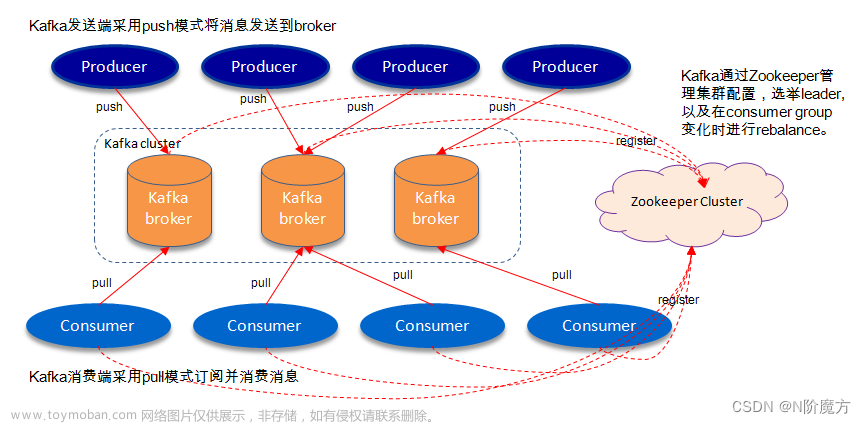
Kafka常见问题处理记录
一、kafka创建topic失败, Replication factor: 1 larger than available brokers: 0
1.创建语句如下所示,按照习惯在添加zookeeper参数的时候,指定了zxy:2181/kafka,但是却创建失败,Error while executing topic command : Replication factor: 1 larger than available brokers: 0.
[root@zxy bin]# kafka-topics.sh --create --topic tp1 --zookeeper zxy:2181/kafka --partitions 3 --replication-factor 1
Error while executing topic command : Replication factor: 1 larger than available brokers: 0.
[2023-03-27 17:15:46,605] ERROR org.apache.kafka.common.errors.InvalidReplicationFactorException: Replication factor: 1 larger than available brokers: 0.
(kafka.admin.TopicCommand$)
2.检查各个broker的server.properties文件
发现在配置参数的时候,zookeeper.connect指定的是zxy:2181,zxy:2182,zxy:2183
[root@zxy config]# cat server01.properties
broker.id=1
port=9091
listeners=PLAINTEXT://localhost:9091
log.dirs=/zxy/apps/kafkaCluster/kafkaLog01
zookeeper.connect=zxy:2181,zxy:2182,zxy:2183
3.指定zookeeper参数为zxy:2181,创建成功
[root@zxy bin]# kafka-topics.sh --create --topic tp1 --zookeeper zxy:2181 --partitions 3 --replication-factor 1
Created topic "tp1".
二、服务器Cannot allocate memory
问题:在使用服务器中遇到内存无法分配到问题导致启动不了Kafka
思路一:根据查找方法,最后将vm.overcommit_memory设为1,但是对我这个问题没有太大帮助
管理员下三种方案
1.编辑/etc/sysctl.conf ,改vm.overcommit_memory=1,然后sysctl -p使配置文件生效
2.sysctl vm.overcommit_memory=1
3.echo 1 > /proc/sys/vm/overcommit_memory,然后sysctl –p永久生效
思路二:然后通过修改为kafka分配的内存,还是没有解决问题
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi
修改为
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx256M -Xms128M"
fi
思路三:最后想到zookeeper已经启动了,是不是因为它分配的内存太多了,减少为zookeeper分配的内存
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx256M -Xms128M"
fi
三、Offset Explorer连接Kafka问题集合,(Timeout expired while fetching topic metadata),(Uable to find any brokers)
1. Timeout expired while fetching topic metadata
1.Offset Explorer配置好zookeeper的连接地址后

2.在查看Topics的时候,报错Timeout expired while fetching topic metadata

3.排查发现应该是kafka的server.properties文件中的advertised.listeners问题
-
修改前是
advertised.listeners=PLAINTEXT://localhost:9091 -
修改后
advertised.listeners=PLAINTEXT://:9091
4.修改好配置文件后,重启Kafka即可
2.Uable to find any brokers
1.重新连接后,又遇到Uable to find any brokers问题,访问不到的原因是,Offset Explorer访问Kafka的时候,是因为Kafka tool是通过主机名访问的,所以要在windows的hosts文件中配置上Kafka服务器的IP映射,配置目录在C:\Windows\System32\drivers\etc

2.打开C:\Windows\System32\drivers\etc,修改配置文件hosts,添加Kafka主机的映射关系
C:\Windows\System32\drivers\etc\hosts
125.262.96.387 zxy
3.断开连接后,在Advanced的Bootstrap servers处配置好Kafka服务,重新连接即可

4.重新连接后,即可以看到已经可以正常看到Topics了

四、kafka数据到hudi丢失数据问题
1.报错问题
Caused by: java.lang.IllegalStateException: Cannot fetch offset 196 (GroupId: spark-kafka-source-6f1df211-fdcb-4bcc-813d-55c4f9661c9d-1732697149-executor, TopicPartition: news-0).
Some data may have been lost because they are not available in Kafka any more; either the
data was aged out by Kafka or the topic may have been deleted before all the data in the
topic was processed. If you don't want your streaming query to fail on such cases, set the
source option "failOnDataLoss" to "false".
at org.apache.spark.sql.kafka010.InternalKafkaConsumer$.org$apache$spark$sql$kafka010$InternalKafkaConsumer$$reportDataLoss0(KafkaDataConsumer.scala:642)
at org.apache.spark.sql.kafka010.InternalKafkaConsumer.org$apache$spark$sql$kafka010$InternalKafkaConsumer$$reportDataLoss(KafkaDataConsumer.scala:448)
at org.apache.spark.sql.kafka010.InternalKafkaConsumer$$anonfun$get$1.apply(KafkaDataConsumer.scala:269)
at org.apache.spark.sql.kafka010.InternalKafkaConsumer$$anonfun$get$1.apply(KafkaDataConsumer.scala:234)
at org.apache.spark.util.UninterruptibleThread.runUninterruptibly(UninterruptibleThread.scala:77)
at org.apache.spark.sql.kafka010.InternalKafkaConsumer.runUninterruptiblyIfPossible(KafkaDataConsumer.scala:209)
at org.apache.spark.sql.kafka010.InternalKafkaConsumer.get(KafkaDataConsumer.scala:234)
-
翻译结果
最终应用程序状态:失败,exitCode:15,(原因:用户类引发异常:org.apache.spark.sql.streaming.StreamingQueryException:由于阶段失败而中止作业:阶段2.0中的任务0失败4次,最近的失败:阶段2.0中的任务0.3丢失(TID 5,hadoop,executor 1):java.lang.IllegalStateException:无法获取偏移量196(GroupId:spark-kafka-source-e2868915-6d7a-4aef-99a8-3d1c5ef45147-1732697149-executor,主题分区:news-0)。
一些数据可能已经丢失,因为它们在卡夫卡不再可用;要么是数据被卡夫卡过时了,要么是主题在处理完主题中的所有数据之前被删除了。如果您不希望流式查询在这种情况下失败,请将源选项“failOnDataLoss”设置为“false”。文章来源:https://www.toymoban.com/news/detail-459973.html
2.根据提示添加配置文件 -> option(“failOnDataLoss”,“false”)
//5.读取Kafka源数据
val df: DataFrame = spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", params.brokerList)
.option("subscribe", params.topic)
.option("startingOffsets", "latest")
.option("kafka.consumer.commit.groupid", "action-log-group01")
.option("failOnDataLoss","false")
.load()
tips:认为添加这个配置不太妥当,但尚未找到适宜的方法
哪位博主知道的,希望可以指点指点文章来源地址https://www.toymoban.com/news/detail-459973.html
到了这里,关于《Kafka系列》Offset Explorer连接Kafka问题集合,Timeout expired while.. topic metadata,Uable to find any brokers的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!