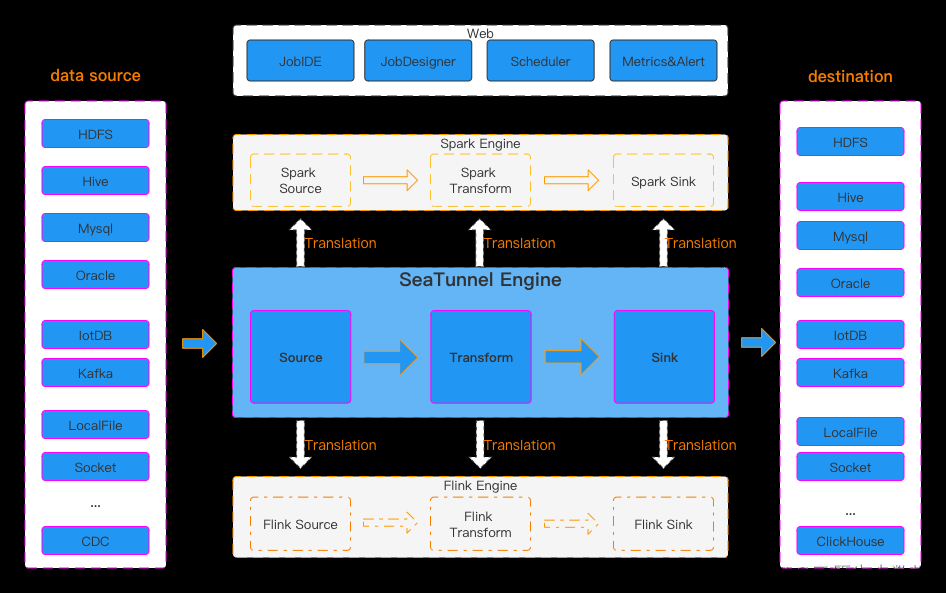
在上一篇文章中,我们介绍了如何下载安装部署SeaTunnel Zeta服务(3分钟部署SeaTunnel Zeta单节点Standalone模式环境),接下来我们介绍一下SeaTunnel支持的第一个同步场景:离线批量同步。顾名思意,离线批量同步需要用户定义好SeaTunnel JobConfig,选择批处理模式,作业启动后开始同步数据,当数据同步完成后作业完成退出。
下面以MySQL离线同步到StarRocks为例,介绍如何使用SeaTunnel进行离线同步作业的定义和运行。
1. 定义作业配置文件
SeaTunnel使用配置文件来定义作业,在这个示例中,作业的配置文件如下,文件保存路径~/seatunnel/apache-seatunnel-incubating-2.3.1/config/mysql_to_sr.config
#定义一些作业的运行参数,具体可以参考 https://seatunnel.apache.org/docs/2.3.1/concept/JobEnvConfig
env {
job.mode="BATCH" #作业的运行模式,BATCH=离线批同步,STREAMING=实时同步
job.name="SeaTunnel_Job"
checkpoint.interval=10000 #每10000ms进行一次checkpoint,后面会详细介绍checkpoint对JDBC Source和StarRocks Sink这两个连接器的影响
}
source {
Jdbc {
parallelism=5 # 并行度,这里是启动5个Source Task来并行的读取数据
partition_column="id" # 使用id字段来进行split的拆分,目前只支持数字类型的主键列,而且该列的值最好是离线的,自增id最佳
partition_num="20" # 拆分成20个split,这20个split会被分配给5个Source Task来处理
result_table_name="Table9210050164000"
query="SELECT `id`, `f_binary`, `f_blob`, `f_long_varbinary`, `f_longblob`, `f_tinyblob`, `f_varbinary`, `f_smallint`, `f_smallint_unsigned`, `f_mediumint`, `f_mediumint_unsigned`, `f_int`, `f_int_unsigned`, `f_integer`, `f_integer_unsigned`, `f_bigint`, `f_bigint_unsigned`, `f_numeric`, `f_decimal`, `f_float`, `f_double`, `f_double_precision`, `f_longtext`, `f_mediumtext`, `f_text`, `f_tinytext`, `f_varchar`, `f_date`, `f_datetime`, `f_timestamp` FROM `sr_test`.`test1`"
password="root@123"
driver="com.mysql.cj.jdbc.Driver"
user=root
url="jdbc:mysql://st01:3306/sr_test?enabledTLSProtocols=TLSv1.2&rewriteBatchedStatements=true"
}
}
transform {
# 在本次示例中我们不需要做任务的Transform操作,所以这里为空,也可以将transform整个元素删除
}
sink {
StarRocks {
batch_max_rows=10240 #
source_table_name="Table9210050164000"
table="test2"
database="sr_test"
base-url="jdbc:mysql://datasource01:9030"
password="root"
username="root"
nodeUrls=[
"datasource01:8030" #写入数据是通过StarRocks的Http接口
]
}
}
2. 作业配置说明
在这个作业定义文件中,我们通过env定义了作业的运行模式是BATCH离线批处理模式,同时定义了作业的名称是"SeaTunnel_Job"。checkpoint.interval参数用来定义该作业过程中多久进行一次checkpoint,那什么是checkpoint,以及checkpoint在Apache SeaTunnel中的作用是什么呢?
2.1 checkpoint
查看官方文档中对Apache SeaTunnel Zeta引擎checkpoint的介绍: https://seatunnel.apache.org/docs/2.3.1/seatunnel-engine/checkpoint-storage#introduction 发现checkpoint是用来使运行在Apache SeaTunnel Zeta中的作业能定期的将自己的状态以快照的形式保存下来,当任务意外失败时,可以从最近一次保存的快照中恢复作业,以实现任务的失败恢复,断点续传等功能。其实checkpoint的核心是分布式快照算法:Chandy-Lamport 算法,是广泛应用在分布式系统,更多是分布式计算系统中的一种容错处理理论基础。这里不详细介绍Chandy-Lamport 算法,接下来我们重点说明在本示例中checkpoint对这个同步任务的影响。
Apache SeaTunnel Zeta引擎在作业启动时会启动一个叫CheckpointManager的线程,用来管理这个作业的checkpoint。SeaTunnel Connector API提供了一套checkpoint的API,用于在引擎触发checkpoint时通知具体的Connector进行相应的处理。SeaTunnel的Source和Sink连接器都是基于SeaTunnel Connector API开发的,只是不同的连接器对checkpoint API的实现细节不同,所以能实现的功能也不同。
2.1.1 checkpoint对JDBC Source的影响
在本示例中我们通过JDBC Source连接器的官方文档https://seatunnel.apache.org/docs/2.3.1/connector-v2/source/Jdbc 可以发现如下内容:

这说明JDBC Source连接器实现了checkpoint相关的接口,通过源码我们可以得知,当checkpoint发生时,JDBC Source会将自己还未处理的split做为状态的快照发送给CheckpointManager进行持久化保存。这样当作业失败并恢复时,JDBC Source会从最近一次保存的快照中读取哪些split还未处理,然后接着处理这些split。
在该作业中通过partition_num=20,会将query参数中指定的sql语句的结果分成20个split进行处理,每个split会生成读取它负责的数据的sql,这个sql是由query中指定的sql再加上一些where过滤条件组成的。这20个split会被分配给5个Source Task进行处理,理想情况下,每个Source Task会分配到4个split。假设在一次checkpoint时每个Source Task都只剩下一个split没有处理,这个split的信息会被保存下来,如果这之后作业挂掉了,作业会自动进行恢复,恢复时每个Source Task都会获取到那个还未处理的split,并接着进行处理。如果作业不再报错,这些split都处理完成后,作业运行完成。如果作业还是报错(比如目标端StarRocks挂了,无法写入数据),最终作业会以失败状态结束。
断点续传:
如果在作业失败后,我们修复了问题,并且希望该作业接着之前的进度运行,只处理那些之前没有被处理过的split,可以使用 sh seatunnel.sh -r jobId来让作业ID为jobId的作业从断点中恢复。
回到主题,checkpoint.interval=10000对于从Mysql中读取数据意味着每过10s,SeaTunnel Zeta引擎就会触发一次checkpoint操作,然后JDBC Source Task会被要求将自己还未处理的split信息保存下来,这里需求注意的是,JDBC Source Task读取数据是以split为单位的,如果checkpoint触发时一个split中的数据正在被读取还未完全发送给下游的StarRocks,它会等到这个split的数据处理完成之后才会响应这次checkpoint操作。这里一定要注意,如果MySQL中的数据量比较大,一个split的数据需要很长的时候才能处理完成,可能会导致checkpoint超时。关于checkpoint的超时时长可以参数https://seatunnel.apache.org/docs/2.3.1/seatunnel-engine/checkpoint-storage, 默认是1分钟。
2.1.2 checkpoint对StarRocks Sink的影响
在Sink连接器的文档上,我们也能看到如下图中的标识:

这个标识代表该Sink连接器是否实现了精确处理一次的语义,如果该标识被选中,说明这个Sink连接器能保证发给它的数据它只会往目标端写入一次,不会漏掉导致目标端数据丢失 ,也不会重复往目标端写入。这一功能常见的实现方式是两阶段提交,支持事务的连接器一般会先开启事务进行数据的写入。当checkpoint发生时,将事务ID返回给CheckManager进行持久化,当作业中的所有Task都响应了CheckManager的checkpoint请求后,第一阶段完成。然后Apache SeaTunnel Zeta引擎会调用AggregateCommit的方法让Sink对其事务进行提交,这个过程被称为第二阶段,第二阶段完成后该次checkpoint完成。如果第二阶段提交失败,作业会失败,然后自动恢复,恢复后会再次从第二阶段开始,要求对事务进行提交,直到该事务提交完成,如果事务一直失败,作业也将失败。
并不是只有实现了exactly-once特性的Sink连接器才能保证目标端的数据不丢失不重复,如果目标端的数据库支持以主键去重,那只要Sink连接器保证发送给它的数据至少往目标端写入一次,无论重复写入多少次,最终都不会导致目标端数据丢失或重复。在该示例中StarRocks Sink连接器即是使用了这种方式,StarRocks Sink连接器会将收到的数据先缓存在内存中,当缓存的行数达到batch_max_rows设置的10240行,就会发起一次写入请求,将数据写入到StarRocks中。如果MySQL中的数据量很小,达不到10240行,那就会在checkpoint触发时进行StarRocks的写入。
3. 运行作业
我们使用Apache SeaTunnel Zeta引擎来运行该作业
cd ~/seatunnel/apache-seatunnel-incubating-2.3.1
sh bin/seatunnel.sh --config config/mysql_to_sr.config
作业运行完成后可以看到如下信息,说明作业状态为FINISHED,读取20w行数据,写入StarRocks也是20w行数据,用时6s。文章来源:https://www.toymoban.com/news/detail-460025.html
 文章来源地址https://www.toymoban.com/news/detail-460025.html
文章来源地址https://www.toymoban.com/news/detail-460025.html
到了这里,关于一文教会你用Apache SeaTunnel Zeta离线把数据从MySQL同步到StarRocks的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!