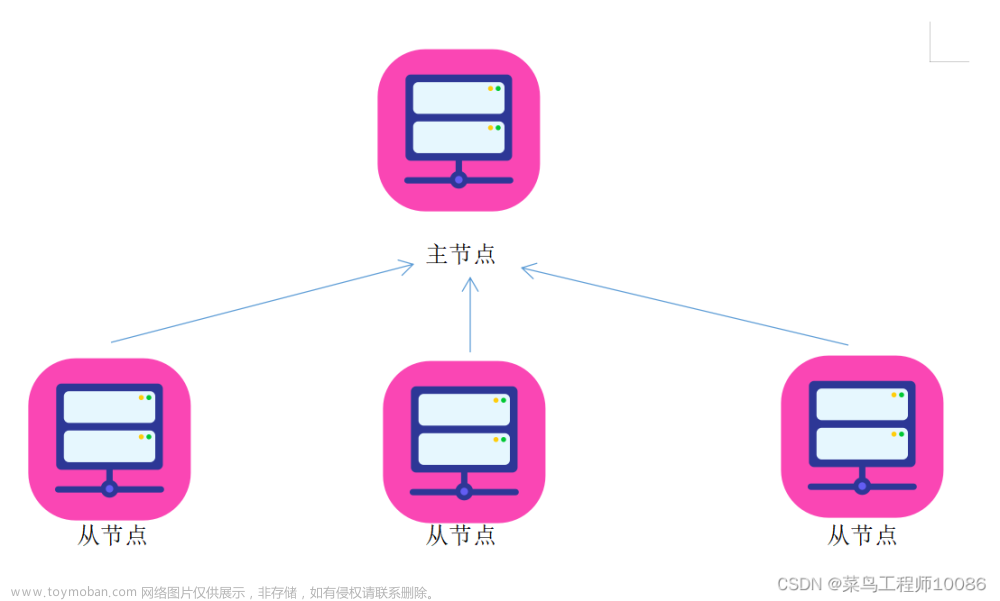
Hadoop分布式文件系统(HDFS)是Hadoop生态系统的核心组件之一,它是一个可扩展的分布式文件系统,用于存储大量数据。本文将对HDFS的源代码进行解析,以便更好地理解其工作原理。
HDFS的核心组件
HDFS由三个核心组件组成:NameNode,DataNode和客户端。NameNode是HDFS的主节点,负责管理文件系统的命名空间和客户端的元数据。DataNode是HDFS的从节点,负责存储实际的数据块。客户端是与HDFS交互的用户程序,它们可以读取或写入数据。
- NameNode启动流程
- 1.1 NameNode
- 1.2 启动流程main方法
-
startHttpServer 启动HTTPServer
-
loadNamesystem 加载元数据 todo
- 从磁盘上加载FSFSImage到内存中合并元数据
- JournalSet的成员变量journals List根据配置读取到NameNode的路径本地和JournalNode路径远程,生成FileJournalnodeManager和QuorumJournalManager
- Fsimage合并后写入到磁盘上
- 打开editLog开始写日志,初始化两个流用于写入日志使用 QuorumJournalManager-》QuorumOutputStream FileJournalManager -》 EditLogFileOutputStream
-
createRpcServer
- 创建ServiceRPCServer
- 创建ClientRpcServer
-
startCommonServices 公共服务启动
- 检查是否有足够的磁盘存储元数据
- 通过扫描core-site.xml hdfs-site.xml知道哪些磁盘用于存储元数据
- 遍历磁盘如果磁盘空间小于100M就返回false
- 安全模式检查
- 如果datanode累计汇报的block的数目小于0.999(默认)*总的block个数,进入安全模式
- 如果存活的datanode小于某个阈值的时候也会进入安全模式且阈值不等于零,进入安全模式,默认阈值为零
- 存放元数据的空间是否大于100M如果不大于100M也会进入安全模式
- 启动管理心跳的服务 HeartbeatManager的一个监听心跳的一个成员变量线程,并启动这个线程,跳转到3
- 检查是否有足够的磁盘存储元数据
-
如果是NameNode(Secondry)还会启动EditLogTailer线程从Journalnode上同步元数据,启动StandbyCheckpointer用于检测NameNode的EditLog和FsImage的数据是否需要合并
-
- DateNode启动流程
-
2.1 DateNode
-
2.2 启动流程main方法
- createDataNode
- initDataXceiver
- 实例化 DataXceiverServer 线程用于DataNode用来接收客户端和其他DataNode传过来数据的服务
- startInfoServer 启动http服务
- initIpcServer 启动RPC服务
- 创建了BlockPoolManager
- 一个联邦只有一个BlackPool,对应一个BPOfferService
- 一个联邦一般有两个NameNode(avtive和standBy)会启动两个BPServiceActor线程用于DataNode向NameNode(一个是NameNode active 一个是NameNode standBy)进行注册
-
2.3 向NameNode进行注册
- 首先获取到NameNode的代理,校验NameSpace、clusterId、BlockPoolId的信息。
- 创建注册信息,通过NameNode的NameNodeRpcServer的registerDatanode向NameNode进行注册
- 通过NameNodeRpcServer的FSNamesystem成员变量获取DataNodeManager往DataNodeManager的各种内存结构里面添加各种信息
- 把注册上来的DataNode加入到HeartbeatManager中用于心跳管理
-
2.4 向NameNode发送心跳
- 每隔3秒钟通过NameNodeRpcServer服务向NameNode进行注册,从DataNodeManager中获取注册DataNode的注册信息,主要更改心跳时间,并回调带回来一些NameNode的发送过来的指令。
-
2.5 启动blockPoolManager、dataXceiverServer、ipcServer守护线程
- NameNode和DataNode心跳管理
- NameNode启动公共服务 startCommonServices的时候会启动一个HeartbeatMananger的的线程服务用来检查DataNode的心跳信息,判断是否死去,查看HeartbeatManger的run方法。
- 每隔30s或者五分钟执行一次心态检查,如果10分三十秒还没有检测到心跳,那么就将这个DataNode设置为死亡状态,从DatanodeManager里面将各种DataNode各种注册信息移除掉。
- 元数据管理流程
- 场景驱动FileTest类创建目录
- DistributedFileSystem mkdirs 调用RpcNameNodeServer mkdirs
- 首先更新NameNode 的内存中的目录树结构
- 创建日志对象,并将日志对象记录
- 将数据先写入到内存的缓冲区中,交换内存的缓冲数据,将数据写入到NameNode的本地磁盘中。
- 将数据先写入到内存的缓冲区中,交换内存的缓冲数据,同时将数据发送到journalNode
- 异步获取到每一个journalNode的JournalNodeRpcServerd的journal方法,通过rpc服务将数据写入到journalNode的本地磁盘中
- SeconderyNameNode的EditLogTailer线程会同步Journal的元数据到StandByNameNode上面去
- 当SeconderyNameNode启动后就会启动EditLogTailer线程从JournalNode来同步元数据到StandByNameNode上
- 首先加载当前自己的元数据日志,并获取当前的元数据日志的最后一条日志的事务ID,通过Http请求去JournalNode上读取日志,并将获取到的元数据作用到自己的内存的元数据目录树里面里面
- SeconderyNameNode的StandByCheckPointer线程的checkpoint (EditLogTailerh和StandByCheckPointer都是NameNode启动的时候会启动),StandByNameNode会往NameNodeHttpServer的imagetransfer(ImageServlet的put方法)发送元数据
- SeconderyNameNode启动的时候会启动一个StandByCheckPointer线程每隔60秒检验是否需要Checkpoint
- 先获取到当前的最新的日志的事务Id,然后获取到上一次CheckPoint的事务Id,两者相减如果大于等于100万条就需要做checkpoint
- 获取到当前时间和上一次CheckPonit的时间,两者相减如果>=1个小时没有做CheckPoint,那么就需要做一次checkpoint
- 如果满足CheckPoint的其中一个条件,就开始做CheckPoint.
- 开启一个线程将SeconderyNameNode的元数据持久化到磁盘上面
- 开启一个异步的线程将SeconderyNameNode,通过Http请求的put方式将数据发送到activeNameNode的imagetransfer这个路由上面
- activeNameNode的ImageServlet的doPut方法不断获取到输入流,保存文件到本地,并将fsimage_N.ckpt重命名为fsimage_N这个文件
- HDFS写数据流程
- 5.1 场景驱动FileTest类写数据 的create()
- DFSOutputStream.newStreamForCreate首先客户端获取到NameNodeRpcServer的create的方法
- 调用RpcNameNodeServer服务往NameNode的文件目录树添加INodeFile,并将元数据写入本地磁盘和JournalNode中
- NameNode leaseManger.addLease()添加契约 将数据放入到一个可排序(按照时间倒叙)的数据结构中,并添加契约的时间。
- NameNode启动的时候会启动一个LeaseManager的监听线程,每隔两秒钟就会从可排序的数据结构中,拿出第一个契约,如果第一个契约没有过期就直接return,否则再看后续的契约是否过期。如果有过期的数据就从各种数据结构中移除数据。
- 客户端DFSOutputStream创建并启动DataStreamer线程是写数据的重要对象
- 当开始启动DataStreamer线程的时候,由于dataQueue里面没有数据会阻塞住线程,只有客户端调用write方法真正开始写数据的时候,该线程才会继续运行
- 当队列中有了数据DataStreamer就会被唤醒并运行
- 首先向NameNode申请Block
- 调用NameNodeRpcServer选择存放Block的DataNode目标主机数组
- 修改内存里面的目录树信息,将block信息记录到内存的目录树中
- 并将元数据写入到磁盘中
- 客户端通过Socket请求连接到第一个DataNode的目标主机,创建输出流
- 启动一个ResponseProcessor线程来监听发送的状态,读取下游的结果,如果发送成功就把ackQueue里面的packet移除。
- 从dataQueue把要发送的这个packet移除出去,然后往ackQueue里面添加这个packet
- 通过输出流把数据写出去
- 写数据异常
- 把ackQueue的数据写入到dataQueue,清空ackQueue队列
- 重新建立数据管道
- 如果有一半以上的都有问题,重新构建新的数据管道
- 如果只有一个出问题,就将剩余的重新构建数据管道,然后同步数据即可,后面NameNode会检测到DataNode少了副本就会通知DataNode处理
- 当管道建立成功之后就重新开始写数据
- 首先向NameNode申请Block
- beginFileLease()
- 客户端开启一个线程每隔一秒钟检查一次,如果超过三十秒没有续约,那么就调用NameNodeRpcServer续约契约的更新时间,移除老的数据结构,更新契约时间,将新的数据放入到数据结构里面。
- LeaseManager有个线程移除老的契约时间。
- 5.2 FileTest 写数据 的write()方法
- DFSOutputStream父类的write方法写入数据,最终调用DFSOutputStream的父方法FSOutputSummer的write方法
- HDFS文件 -》 Block文件块(128M) -》 2048 * packet(64K) = 127 * chunk -> chunk 512byte + chunksum 4byte = 516
- 开始以一个chunk的开始写,当写满一个packet或者写满一个Block,就会往dataQueue里面添加packte,然后唤醒DataStreamer的run方法,
- 如果没有写满的话,等到DataStreamer过了超时时间也会从dataQueue取数据,没有写满一个packet,会利用已有的数据创建一个packet来发送数据
- 当datanode获取到DataStreamer发送过来的数据后
- 每发送过来一个请求DataXceiverServer线程都会启动DataXceiver线程用于处理数据。
- 根据不同的请求的操作类型,我们这边是写数据,那么会启动BlockReceive线程,通过socket继续连接下游的datanode,建立通道
- 启动PacketResponder和 ResponseProcessor线程功能类似,是用于判断下游是否写数据成功,成功移除ackQueue
- 获取当前节点是否已经写入成功
- 获取下游节点的处理结果
- 往上游发送处理结果
- 获取到下游的处理结果,如果处理成功,就从当前的datanode节点的ackQueue队列中移除packet.
- 不断的接受数据
- 把packet写入到datanode的ackqueue队列中
- 通过上面连接的数据通道把当前的packet发送的下游的datanode节点
- 校验数据并将数据写入到本地。
- 往上游写回相应结果
NameNode源代码总结
NameNode是HDFS的核心组件之一,它负责管理文件系统的命名空间和客户端的元数据。以下是NameNode源代码的主要组成部分:
-
FsNamesystem:这是NameNode的核心组件之一,它负责管理文件系统的命名空间和客户端的元数据。它包含了文件系统的目录树和文件元数据,如文件大小、创建时间、修改时间等。
-
FSImage:这是文件系统镜像的核心组件,它是文件系统的元数据的持久化存储。它将文件系统的元数据保存在本地磁盘上,以便在NameNode重新启动时恢复文件系统的状态。
-
EditLog:这是文件系统编辑日志的核心组件,它记录了文件系统的所有修改操作。它将修改操作写入本地磁盘,以便在NameNode重新启动时重新应用这些操作。
-
NameNodeRpcServer:这是NameNode的RPC服务器,它处理客户端和DataNode之间的通信。它提供了一组RPC接口,用于管理文件系统的命名空间和元数据。
DataNod总结
DataNode是HDFS的从节点,它负责存储实际的数据块。以下是DataNode源代码的主要组成部分:
-
FsDatasetImpl:这是DataNode的核心组件之一,它负责存储实际的数据块。它包含了文件系统的数据块和元数据,如块大小、创建时间、修改时间等。
-
DataNodeRpcServer:这是DataNode的RPC服务器,它处理客户端和NameNode之间的通信。它提供了一组RPC接口,用于管理数据块和元数据。
-
BlockReceiver:这是DataNode接收数据块的核心组件。它负责接收数据块并将其写入本地磁盘。
客户端源代码总结
客户端是与HDFS交互的用户程序,它们可以读取或写入数据。以下是客户端源代码的主要组成部分:
-
DistributedFileSystem:这是客户端的核心组件之一,它提供了一组API,用于读取或写入数据。它将API调用转换为RPC请求,并将请求发送到NameNode或DataNode。
-
DFSClient:这是客户端的核心组件之一,它负责与NameNode和DataNode之间的通信。它将API调用转换为RPC请求,并将请求发送到NameNode或DataNode。
总结文章来源:https://www.toymoban.com/news/detail-460240.html
本文对HDFS的源代码进行了简要的解析,以便更好地理解其工作原理。HDFS的核心组件包括NameNode、DataNode和客户端,它们分别负责管理文件系统的命名空间和元数据、存储实际的数据块以及与HDFS交互。HDFS的源代码是Hadoop生态系统的核心组件之一,它为存储大量数据提供了可扩展的分布式文件系统。文章来源地址https://www.toymoban.com/news/detail-460240.html
到了这里,关于HDFS源码解析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!