深度学习领域常用的基于CPU/GPU的推理方式有OpenCV DNN、ONNXRuntime、TensorRT以及OpenVINO。这几种方式的推理过程可以统一用下图来概述。整体可分为模型初始化部分和推理部分,后者包括步骤2-5。

以GoogLeNet模型为例,测得几种推理方式在推理部分的耗时如下:

结论:
- GPU加速首选TensorRT;
- CPU加速,单图推理首选OpenVINO,多图并行推理可选择ONNXRuntime;
- 如果需要兼具CPU和GPU推理功能,可选择ONNXRuntime。
下一篇内容:【模型部署 02】Python实现GoogLeNet在OpenCV DNN、ONNXRuntime、TensorRT、OpenVINO上的推理部署
1. 环境配置
1.1 OpenCV DNN
【模型部署】OpenCV4.6.0+CUDA11.1+VS2019环境配置
1.2 ONNXRuntime
【模型部署】在C++和Python中配置ONNXRuntime环境
1.3 TensorRT
【模型部署】在C++和Python中搭建TensorRT环境
1.4 OpenVINO2022
【模型部署】在C++和Python中配置OpenVINO2022环境
2. PyTorch模型文件(pt/pth/pkl)转ONNX
2.1 pt/pth/pkl互转
PyTorch中支持导出三种后缀格式的模型文件:pt、pth和pkl,这三种格式在存储方式上并无区别,只是后缀不同。三种格式之间的转换比较简单,只需要创建模型并加载模型参数,然后再保存为其他格式即可。
以pth转pt为例:
import torch
import torchvision
# 构建模型
model = torchvision.models.googlenet(num_classes=2, init_weights=True)
# 加载模型参数,pt/pth/pkl三种格式均可
model.load_state_dict(torch.load("googlenet_catdog.pth"))
model.eval()
# 重新保存为所需要转换的格式
torch.save(model.state_dict(), 'googlenet_catdog.pt')
2.2 pt/pth/pkl转ONNX
PyTorch中提供了现成的函数torch.onnx.export(),可将模型文件转换成onnx格式。该函数原型如下:
export(model, args, f, export_params=True, verbose=False, training=TrainingMode.EVAL,
input_names=None, output_names=None, operator_export_type=None,
opset_version=None, do_constant_folding=True, dynamic_axes=None,
keep_initializers_as_inputs=None, custom_opsets=None,
export_modules_as_functions=False)
主要参数含义:
- model (torch.nn.Module, torch.jit.ScriptModule or torch.jit.ScriptFunction) :需要转换的模型。
-
args (tuple or torch.Tensor) :args可以被设置为三种形式:
- 一个tuple,这个tuple应该与模型的输入相对应,任何非Tensor的输入都会被硬编码入onnx模型,所有Tensor类型的参数会被当做onnx模型的输入。
args = (x, y, z)
- 一个Tensor,一般这种情况下模型只有一个输入。
args = torch.Tensor([1, 2, 3])
- 一个带有字典的tuple,这种情况下,所有字典之前的参数会被当做“非关键字”参数传入网络,字典中的键值对会被当做关键字参数传入网络。如果网络中的关键字参数未出现在此字典中,将会使用默认值,如果没有设定默认值,则会被指定为None。
args = (x, {'y': input_y, 'z': input_z})NOTE:一个特殊情况,当网络本身最后一个参数为字典时,直接在tuple最后写一个字典则会被误认为关键字传参。所以,可以通过在tuple最后添加一个空字典来解决。
# 错误写法: torch.onnx.export( model, (x, # WRONG: will be interpreted as named arguments {y: z}), "test.onnx.pb") # 纠正 torch.onnx.export( model, (x, {y: z}, {}), "test.onnx.pb")
- 一个tuple,这个tuple应该与模型的输入相对应,任何非Tensor的输入都会被硬编码入onnx模型,所有Tensor类型的参数会被当做onnx模型的输入。
- f:一个文件类对象或一个路径字符串,二进制的protocol buffer将被写入此文件,即onnx文件。
- export_params (bool, default False) :如果为True则导出模型的参数。如果想导出一个未训练的模型,则设为False。
- verbose (bool, default False) :如果为True,则打印一些转换日志,并且onnx模型中会包含doc_string信息。
-
training (enum, default TrainingMode.EVAL) :枚举类型包括:
- TrainingMode.EVAL - 以推理模式导出模型。
- TrainingMode.PRESERVE - 如果model.training为False,则以推理模式导出;否则以训练模式导出。
- TrainingMode.TRAINING - 以训练模式导出,此模式将禁止一些影响训练的优化操作。
- input_names (list of str, default empty list) :按顺序分配给onnx图的输入节点的名称列表。
- output_names (list of str, default empty list) :按顺序分配给onnx图的输出节点的名称列表。
-
operator_export_type (enum, default None) :默认为OperatorExportTypes.ONNX, 如果Pytorch built with DPYTORCH_ONNX_CAFFE2_BUNDLE,则默认为OperatorExportTypes.ONNX_ATEN_FALLBACK。枚举类型包括:
- OperatorExportTypes.ONNX - 将所有操作导出为ONNX操作。
- OperatorExportTypes.ONNX_FALLTHROUGH - 试图将所有操作导出为ONNX操作,但碰到无法转换的操作(如onnx未实现的操作),则将操作导出为“自定义操作”,为了使导出的模型可用,运行时必须支持这些自定义操作。支持自定义操作方法见链接。
- OperatorExportTypes.ONNX_ATEN - 所有ATen操作导出为ATen操作,ATen是Pytorch的内建tensor库,所以这将使得模型直接使用Pytorch实现。(此方法转换的模型只能被Caffe2直接使用)
- OperatorExportTypes.ONNX_ATEN_FALLBACK - 试图将所有的ATen操作也转换为ONNX操作,如果无法转换则转换为ATen操作(此方法转换的模型只能被Caffe2直接使用)。例如:
# 转换前: graph(%0 : Float): %3 : int = prim::Constant[value=0]() # conversion unsupported %4 : Float = aten::triu(%0, %3) # conversion supported %5 : Float = aten::mul(%4, %0) return (%5) # 转换后: graph(%0 : Float): %1 : Long() = onnx::Constant[value={0}]() # not converted %2 : Float = aten::ATen[operator="triu"](%0, %1) # converted %3 : Float = onnx::Mul(%2, %0) return (%3)
-
opset_version (int, default 9) :取值必须等于_onnx_main_opset或在_onnx_stable_opsets之内。具体可在torch/onnx/symbolic_helper.py中找到。例如:
_default_onnx_opset_version = 9 _onnx_main_opset = 13 _onnx_stable_opsets = [7, 8, 9, 10, 11, 12] _export_onnx_opset_version = _default_onnx_opset_version
- do_constant_folding (bool, default False) :是否使用“常量折叠”优化。常量折叠将使用一些算好的常量来优化一些输入全为常量的节点。
- example_outputs (T or a tuple of T, where T is Tensor or convertible to Tensor, default None) :当需输入模型为ScriptModule 或 ScriptFunction时必须提供。此参数用于确定输出的类型和形状,而不跟踪(tracing)模型的执行。
-
dynamic_axes (dict<string, dict<python:int, string>> or dict<string, list(int)>, default empty dict) :通过以下规则设置动态的维度:
- KEY(str) - 必须是input_names或output_names指定的名称,用来指定哪个变量需要使用到动态尺寸。
- VALUE(dict or list) - 如果是一个dict,dict中的key是变量的某个维度,dict中的value是我们给这个维度取的名称。如果是一个list,则list中的元素都表示此变量的某个维度。
代码实现:
import torch
import torchvision
weight_file = 'googlenet_catdog.pt'
onnx_file = 'googlenet_catdog.onnx'
model = torchvision.models.googlenet(num_classes=2, init_weights=True)
model.load_state_dict(torch.load(weight_file, map_location=torch.device('cpu')))
model.eval()
# 单输入单输出,固定batch
input = torch.randn(1, 3, 224, 224)
input_names = ["input"]
output_names = ["output"]
torch.onnx.export(model=model,
args=input,
f=onnx_file,
input_names=input_names,
output_names=output_names,
opset_version=11,
verbose=True)
通过netron.app可视化onnx的输入输出:

如果需要多张图片同时进行推理,可以通过设置export的dynamic_axes参数,将模型输入输出的指定维度设置为变量。
import torch
import torchvision
weight_file = 'googlenet_catdog.pt'
onne_file = 'googlenet_catdog.onnx'
model = torchvision.models.googlenet(num_classes=2, init_weights=True)
model.load_state_dict(torch.load(weight_file, map_location=torch.device('cpu')))
model.eval()
# 单输入单输出,动态batch
input = torch.randn(1, 3, 224, 224)
input_names = ["input"]
output_names = ["output"]
torch.onnx.export(model=model,
args=input,
f=onnx_file,
input_names=input_names,
output_names=output_names,
opset_version=11,
verbose=True,
dynamic_axes={'input': {0: 'batch'}, 'output': {0: 'batch'}})
动态batch的onnx文件输入输出在netron.app可视化如下,其中batch维度是变量的形式,可以根据自己需要设置为大于0的任意整数。

如果模型有多个输入和输出,按照以下形式导出:
# 模型有两个输入和两个输出,动态batch
input1 = torch.randn(1, 3, 256, 192).to(opt.device)
input2 = torch.randn(1, 3, 256, 192).to(opt.device)
input_names = ["input1", "input2"]
output_names = ["output1", "output2"]
torch.onnx.export(model=model,
args=(input1, input2),
f=opt.onnx_path,
input_names=input_names,
output_names=output_names,
opset_version=16,
verbose=True,
dynamic_axes={'input1': {0: 'batch'},
'input2': {0: 'batch'},
'output1': {0: 'batch'},
'output2': {0: 'batch'}})
3. OpenCV DNN部署GoogLeNet
3.1 推理过程及代码实现

整个推理过程可分为前处理、推理、后处理三部分。具体细节请阅读代码,包括单图推理、动态batch推理的实现。
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
#include <chrono>
#include <fstream>
using namespace std;
using namespace cv;
using namespace cv::dnn;
std::string onnxPath = "E:/inference-master/models/engine/googlenet-pretrained_batch.onnx";
std::string imagePath = "E:/inference-master/images/catdog";
std::string classNamesPath = "E:/inference-master/imagenet-classes.txt"; // 标签名称列表(类名)
cv::dnn::Net net;
std::vector<std::string> classNameList; // 标签名,可以从文件读取
int batchSize = 32;
int softmax(const cv::Mat& src, cv::Mat& dst)
{
float max = 0.0;
float sum = 0.0;
max = *max_element(src.begin<float>(), src.end<float>());
cv::exp((src - max), dst);
sum = cv::sum(dst)[0];
dst /= sum;
return 0;
}
// GoogLeNet模型初始化
void ModelInit(string onnxPath)
{
net = cv::dnn::readNetFromONNX(onnxPath);
// net = cv::dnn::readNetFromCaffe("E:/inference-master/2/deploy.prototxt", "E:/inference-master/2/default.caffemodel");
// 设置计算后台和计算设备
// CPU(默认)
// net.setPreferableBackend(cv::dnn::DNN_BACKEND_OPENCV);
// net.setPreferableTarget(cv::dnn::DNN_TARGET_CPU);
// CUDA
net.setPreferableBackend(cv::dnn::DNN_BACKEND_CUDA);
net.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA);
// 读取标签名称
ifstream fin(classNamesPath.c_str());
string strLine;
classNameList.clear();
while (getline(fin, strLine))
classNameList.push_back(strLine);
fin.close();
}
// 单图推理
bool ModelInference(cv::Mat srcImage, std::string& className, float& confidence)
{
auto start = chrono::high_resolution_clock::now();
cv::Mat image = srcImage.clone();
// 预处理(尺寸变换、通道变换、归一化)
cv::cvtColor(image, image, cv::COLOR_BGR2RGB);
cv::resize(image, image, cv::Size(224, 224));
image.convertTo(image, CV_32FC3, 1.0 / 255.0);
cv::Scalar mean(0.485, 0.456, 0.406);
cv::Scalar std(0.229, 0.224, 0.225);
cv::subtract(image, mean, image);
cv::divide(image, std, image);
// blobFromImage操作顺序:swapRB交换通道 -> scalefactor比例缩放 -> mean求减 -> size进行resize;
// mean操作时,ddepth不能选取CV_8U;
// crop=True时,先等比缩放,直到宽高之一率先达到对应的size尺寸,另一个大于或等于对应的size尺寸,然后从中心裁剪;
// 返回4-D Mat维度顺序:NCHW
// cv::Mat blob = cv::dnn::blobFromImage(image, 1., cv::Size(224, 224), cv::Scalar(0, 0, 0), false, false);
cv::Mat blob = cv::dnn::blobFromImage(image);
// 设置输入
net.setInput(blob);
auto end1 = std::chrono::high_resolution_clock::now();
auto ms1 = std::chrono::duration_cast<std::chrono::microseconds>(end1 - start);
std::cout << "PreProcess time: " << (ms1 / 1000.0).count() << "ms" << std::endl;
// 前向推理
cv::Mat preds = net.forward();
auto end2 = std::chrono::high_resolution_clock::now();
auto ms2 = std::chrono::duration_cast<std::chrono::microseconds>(end2 - end1);
std::cout << "Inference time: " << (ms2 / 1000.0).count() << "ms" << std::endl;
// 结果归一化(每个batch分别求softmax)
softmax(preds, preds);
Point minLoc, maxLoc;
double minValue = 0, maxValue = 0;
cv::minMaxLoc(preds, &minValue, &maxValue, &minLoc, &maxLoc);
int labelIndex = maxLoc.x;
double probability = maxValue;
className = classNameList[labelIndex];
confidence = probability;
// std::cout << "class:" << className << endl << "confidence:" << confidence << endl;
auto end3 = std::chrono::high_resolution_clock::now();
auto ms3 = std::chrono::duration_cast<std::chrono::microseconds>(end3 - end2);
std::cout << "PostProcess time: " << (ms3 / 1000.0).count() << "ms" << std::endl;
auto ms = chrono::duration_cast<std::chrono::microseconds>(end3 - start);
std::cout << "opencv_dnn 推理时间:" << (ms / 1000.0).count() << "ms" << std::endl;
}
// 多图并行推理(动态batch)
bool ModelInference_Batch(std::vector<cv::Mat> srcImages, std::vector<string>& classNames, std::vector<float>& confidences)
{
auto start = chrono::high_resolution_clock::now();
// 预处理(尺寸变换、通道变换、归一化)
std::vector<cv::Mat> images;
for (size_t i = 0; i < srcImages.size(); i++)
{
cv::Mat image = srcImages[i].clone();
cv::cvtColor(image, image, cv::COLOR_BGR2RGB);
cv::resize(image, image, cv::Size(224, 224));
image.convertTo(image, CV_32FC3, 1.0 / 255.0);
cv::Scalar mean(0.485, 0.456, 0.406);
cv::Scalar std(0.229, 0.224, 0.225);
cv::subtract(image, mean, image);
cv::divide(image, std, image);
images.push_back(image);
}
cv::Mat blob = cv::dnn::blobFromImages(images);
auto end1 = std::chrono::high_resolution_clock::now();
auto ms1 = std::chrono::duration_cast<std::chrono::microseconds>(end1 - start);
std::cout << "PreProcess time: " << (ms1 / 1000.0).count() << "ms" << std::endl;
// 设置输入
net.setInput(blob);
// 前向推理
cv::Mat preds = net.forward();
auto end2 = std::chrono::high_resolution_clock::now();
auto ms2 = std::chrono::duration_cast<std::chrono::microseconds>(end2 - end1) / 100.0;
std::cout << "Inference time: " << (ms2 / 1000.0).count() << "ms" << std::endl;
int rows = preds.size[0]; // batch
int cols = preds.size[1]; // 类别数(每一个类别的得分)
for (int row = 0; row < rows; row++)
{
cv::Mat scores(1, cols, CV_32FC1, preds.ptr<float>(row));
softmax(scores, scores); // 结果归一化
Point minLoc, maxLoc;
double minValue = 0, maxValue = 0;
cv::minMaxLoc(scores, &minValue, &maxValue, &minLoc, &maxLoc);
int labelIndex = maxLoc.x;
double probability = maxValue;
classNames.push_back(classNameList[labelIndex]);
confidences.push_back(probability);
}
auto end3 = std::chrono::high_resolution_clock::now();
auto ms3 = std::chrono::duration_cast<std::chrono::microseconds>(end3 - end2);
std::cout << "PostProcess time: " << (ms3 / 1000.0).count() << "ms" << std::endl;
auto ms = chrono::duration_cast<std::chrono::microseconds>(end3 - start);
std::cout << "opencv_dnn batch" << rows << " 推理时间:" << (ms / 1000.0).count() << "ms" << std::endl;
}
int main(int argc, char** argv)
{
// 模型初始化
ModelInit(onnxPath);
// 读取图像
vector<string> filenames;
glob(imagePath, filenames);
// 单图推理测试
for (int n = 0; n < filenames.size(); n++)
{
// 重复100次,计算平均时间
auto start = chrono::high_resolution_clock::now();
cv::Mat src = imread(filenames[n]);
std::string classname;
float confidence;
for (int i = 0; i < 101; i++) {
if (i==1)
start = chrono::high_resolution_clock::now();
ModelInference(src, classname, confidence);
}
auto end = chrono::high_resolution_clock::now();
auto ms = chrono::duration_cast<std::chrono::microseconds>(end - start) / 100;
std::cout << "opencv_dnn 平均推理时间:---------------------" << (ms / 1000.0).count() << "ms" << std::endl;
}
// 批量(动态batch)推理测试
std::vector<cv::Mat> srcImages;
for (int n = 0; n < filenames.size(); n++)
{
cv::Mat image = imread(filenames[n]);
srcImages.push_back(image);
if ((n + 1) % batchSize == 0 || n == filenames.size() - 1)
{
// 重复100次,计算平均时间
auto start = chrono::high_resolution_clock::now();
for (int i = 0; i < 101; i++) {
if (i == 1)
start = chrono::high_resolution_clock::now();
std::vector<std::string> classNames;
std::vector<float> confidences;
ModelInference_Batch(srcImages, classNames, confidences);
}
srcImages.clear();
auto end = chrono::high_resolution_clock::now();
auto ms = chrono::duration_cast<std::chrono::microseconds>(end - start) / 100;
std::cout << "opencv_dnn batch" << batchSize << " 平均推理时间:---------------------" << (ms / 1000.0).count() << "ms" << std::endl;
}
}
return 0;
}
3.2 选择CPU/GPU
OpenCV DNN切换CPU和GPU推理,只需要通过下边两行代码设置计算后台和计算设备。
CPU推理
net.setPreferableBackend(cv::dnn::DNN_BACKEND_OPENCV); net.setPreferableTarget(cv::dnn::DNN_TARGET_CPU);
GPU推理
net.setPreferableBackend(cv::dnn::DNN_BACKEND_CUDA); net.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA);
以下两点需要注意:
- 在不做任何设置的情况下,默认使用CPU进行推理。
- 在设置为GPU推理时,如果电脑没有搜索到CUDA环境,则会自动转换成CPU进行推理。
3.3 多输出模型推理
当模型有多个输出时,使用forward的重载方法,返回Mat类型的数组:
// 模型多输出 std::vector<cv::Mat> preds; net.forward(preds); cv::Mat pred1 = preds[0]; cv::Mat pred2 = preds[1];
4. ONNXRuntime部署GoogLeNet
4.1 推理过程及代码实现

代码:
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
#include <onnxruntime_cxx_api.h>
#include <vector>
#include <fstream>
#include <chrono>
using namespace std;
using namespace cv;
using namespace Ort;
// C++表示字符串的方式:char*、string、wchar_t*、wstring、字符串数组
const wchar_t* onnxPath = L"E:/inference-master/models/GoogLeNet/googlenet-pretrained_batch1.onnx";
std::string imagePath = "E:/inference-master/images/catdog";
std::string classNamesPath = "E:/inference-master/imagenet-classes.txt"; // 标签名称列表(类名)
std::vector<std::string> classNameList; // 标签名,可以从文件读取
int batchSize = 1;
Ort::Env env{ nullptr };
Ort::SessionOptions* sessionOptions;
Ort::Session* session;
size_t inputCount;
size_t outputCount;
std::vector<const char*> inputNames;
std::vector<const char*> outputNames;
std::vector<int64_t> inputShape;
std::vector<int64_t> outputShape;
// 对数组元素求softmax
std::vector<float> softmax(std::vector<float> input)
{
float total = 0;
for (auto x : input)
total += exp(x);
std::vector<float> result;
for (auto x : input)
result.push_back(exp(x) / total);
return result;
}
int softmax(const cv::Mat& src, cv::Mat& dst)
{
float max = 0.0;
float sum = 0.0;
max = *max_element(src.begin<float>(), src.end<float>());
cv::exp((src - max), dst);
sum = cv::sum(dst)[0];
dst /= sum;
return 0;
}
// 前(预)处理(通道变换、标准化等)
void PreProcess(cv::Mat srcImage, cv::Mat& dstImage)
{
// 通道变换,BGR->RGB
cvtColor(srcImage, dstImage, cv::COLOR_BGR2RGB);
resize(dstImage, dstImage, Size(224, 224));
// 图像归一化
dstImage.convertTo(dstImage, CV_32FC3, 1.0 / 255.0);
cv::Scalar mean(0.485, 0.456, 0.406);
cv::Scalar std(0.229, 0.224, 0.225);
subtract(dstImage, mean, dstImage);
divide(dstImage, std, dstImage);
}
// 模型初始化
int ModelInit(const wchar_t* onnxPath, bool useCuda, int deviceId)
{
// 读取标签名称
std::ifstream fin(classNamesPath.c_str());
std::string strLine;
classNameList.clear();
while (getline(fin, strLine))
classNameList.push_back(strLine);
fin.close();
// 环境设置,控制台输出设置
env = Ort::Env(ORT_LOGGING_LEVEL_WARNING, "GoogLeNet");
sessionOptions = new Ort::SessionOptions();
// 设置线程数
sessionOptions->SetIntraOpNumThreads(16);
// 优化等级:启用所有可能的优化
sessionOptions->SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_ALL);
if (useCuda) {
// 开启CUDA加速,需要cuda_provider_factory.h头文件
OrtSessionOptionsAppendExecutionProvider_CUDA(*sessionOptions, deviceId);
}
// 创建session
session = new Ort::Session(env, onnxPath, *sessionOptions);
// 获取输入输出数量
inputCount = session->GetInputCount();
outputCount = session->GetOutputCount();
std::cout << "Number of inputs = " << inputCount << std::endl;
std::cout << "Number of outputs = " << outputCount << std::endl;
// 获取输入输出名称
Ort::AllocatorWithDefaultOptions allocator;
const char* inputName = session->GetInputName(0, allocator);
const char* outputName = session->GetOutputName(0, allocator);
inputNames = { inputName };
outputNames = { outputName };
std::cout << "Name of inputs = " << inputName << std::endl;
std::cout << "Name of outputs = " << outputName << std::endl;
// 获取输入输出维度信息,返回类型std::vector<int64_t>
inputShape = session->GetInputTypeInfo(0).GetTensorTypeAndShapeInfo().GetShape();
outputShape = session->GetOutputTypeInfo(0).GetTensorTypeAndShapeInfo().GetShape();
std::cout << "Shape of inputs = " << "(" << inputShape[0] << "," << inputShape[1] << "," << inputShape[2] << "," << inputShape[3] << ")" << std::endl;
std::cout << "Shape of outputs = " << "(" << outputShape[0] << "," << outputShape[1] << ")" << std::endl;
return 0;
}
// 单图推理
void ModelInference(cv::Mat srcImage, std::string& className, float& confidence)
{
auto start = chrono::high_resolution_clock::now();
// 输入图像预处理
cv::Mat image;
//PreProcess(srcImage, image); // 这里使用调用函数的方式,处理时间莫名变长很多,很奇怪
// 通道变换,BGR->RGB
cvtColor(srcImage, image, cv::COLOR_BGR2RGB);
resize(image, image, Size(224, 224));
// 图像归一化
image.convertTo(image, CV_32FC3, 1.0 / 255.0);
cv::Scalar mean(0.485, 0.456, 0.406);
cv::Scalar std(0.229, 0.224, 0.225);
subtract(image, mean, image);
divide(image, std, image);
cv::Mat blob = cv::dnn::blobFromImage(image);
auto end1 = std::chrono::high_resolution_clock::now();
auto ms1 = std::chrono::duration_cast<std::chrono::microseconds>(end1 - start);
std::cout << "PreProcess time: " << (ms1 / 1000.0).count() << "ms" << std::endl;
// 创建输入tensor
auto memoryInfo = Ort::MemoryInfo::CreateCpu(OrtAllocatorType::OrtArenaAllocator, OrtMemType::OrtMemTypeDefault);
std::vector<Ort::Value> inputTensors;
inputTensors.emplace_back(Ort::Value::CreateTensor<float>(memoryInfo,
blob.ptr<float>(), blob.total(), inputShape.data(), inputShape.size()));
// 推理
auto outputTensors = session->Run(Ort::RunOptions{ nullptr },
inputNames.data(), inputTensors.data(), inputCount, outputNames.data(), outputCount);
auto end2 = std::chrono::high_resolution_clock::now();
auto ms2 = std::chrono::duration_cast<std::chrono::microseconds>(end2 - end1);
std::cout << "Inference time: " << (ms2 / 1000.0).count() << "ms" << std::endl;
// 获取输出
float* preds = outputTensors[0].GetTensorMutableData<float>(); // 也可以使用outputTensors.front();
int64_t numClasses = outputShape[1];
cv::Mat output = cv::Mat_<float>(1, numClasses);
for (int j = 0; j < numClasses; j++) {
output.at<float>(0, j) = preds[j];
}
Point minLoc, maxLoc;
double minValue = 0, maxValue = 0;
cv::minMaxLoc(output, &minValue, &maxValue, &minLoc, &maxLoc);
int labelIndex = maxLoc.x;
double probability = maxValue;
className = classNameList[1];
confidence = probability;
auto end3 = std::chrono::high_resolution_clock::now();
auto ms3 = std::chrono::duration_cast<std::chrono::microseconds>(end3 - end2);
std::cout << "PostProcess time: " << (ms3 / 1000.0).count() << "ms" << std::endl;
auto ms = chrono::duration_cast<std::chrono::microseconds>(end3 - start);
std::cout << "onnxruntime单图推理时间:" << (ms / 1000.0).count() << "ms" << std::endl;
}
// 单图推理
void ModelInference_Batch(std::vector<cv::Mat> srcImages, std::vector<string>& classNames, std::vector<float>& confidences)
{
auto start = chrono::high_resolution_clock::now();
// 输入图像预处理
std::vector<cv::Mat> images;
for (size_t i = 0; i < srcImages.size(); i++)
{
cv::Mat image = srcImages[i].clone();
// 通道变换,BGR->RGB
cvtColor(image, image, cv::COLOR_BGR2RGB);
resize(image, image, Size(224, 224));
// 图像归一化
image.convertTo(image, CV_32FC3, 1.0 / 255.0);
cv::Scalar mean(0.485, 0.456, 0.406);
cv::Scalar std(0.229, 0.224, 0.225);
subtract(image, mean, image);
divide(image, std, image);
images.push_back(image);
}
// 图像转blob格式
cv::Mat blob = cv::dnn::blobFromImages(images);
auto end1 = std::chrono::high_resolution_clock::now();
auto ms1 = std::chrono::duration_cast<std::chrono::microseconds>(end1 - start);
std::cout << "PreProcess time: " << (ms1 / 1000.0).count() << "ms" << std::endl;
// 创建输入tensor
std::vector<Ort::Value> inputTensors;
auto memoryInfo = Ort::MemoryInfo::CreateCpu(OrtAllocatorType::OrtArenaAllocator, OrtMemType::OrtMemTypeDefault);
inputTensors.emplace_back(Ort::Value::CreateTensor<float>(memoryInfo,
blob.ptr<float>(), blob.total(), inputShape.data(), inputShape.size()));
// 推理
std::vector<Ort::Value> outputTensors = session->Run(Ort::RunOptions{ nullptr },
inputNames.data(), inputTensors.data(), inputCount, outputNames.data(), outputCount);
auto end2 = std::chrono::high_resolution_clock::now();
auto ms2 = std::chrono::duration_cast<std::chrono::microseconds>(end2 - end1)/100;
std::cout << "inference time: " << (ms2 / 1000.0).count() << "ms" << std::endl;
// 获取输出
float* preds = outputTensors[0].GetTensorMutableData<float>(); // 也可以使用outputTensors.front();
// cout << preds[0] << "," << preds[1] << "," << preds[1000] << "," << preds[1001] << endl;
int batch = outputShape[0];
int numClasses = outputShape[1];
cv::Mat output(batch, numClasses, CV_32FC1, preds);
int rows = output.size[0]; // batch
int cols = output.size[1]; // 类别数(每一个类别的得分)
for (int row = 0; row < rows; row++)
{
cv::Mat scores(1, cols, CV_32FC1, output.ptr<float>(row));
softmax(scores, scores); // 结果归一化
Point minLoc, maxLoc;
double minValue = 0, maxValue = 0;
cv::minMaxLoc(scores, &minValue, &maxValue, &minLoc, &maxLoc);
int labelIndex = maxLoc.x;
double probability = maxValue;
classNames.push_back(classNameList[labelIndex]);
confidences.push_back(probability);
}
auto end3 = std::chrono::high_resolution_clock::now();
auto ms3 = std::chrono::duration_cast<std::chrono::microseconds>(end3 - end2);
std::cout << "PostProcess time: " << (ms3 / 1000.0).count() << "ms" << std::endl;
auto ms = chrono::duration_cast<std::chrono::microseconds>(end3 - start);
std::cout << "onnxruntime单图推理时间:" << (ms / 1000.0).count() << "ms" << std::endl;
}
int main(int argc, char** argv)
{
// 模型初始化
ModelInit(onnxPath, true, 0);
// 读取图像
std::vector<std::string> filenames;
cv::glob(imagePath, filenames);
// 单图推理测试
for (int i = 0; i < filenames.size(); i++)
{
// 每张图重复运行100次,计算平均时间
auto start = chrono::high_resolution_clock::now();
cv::Mat srcImage = imread(filenames[i]);
std::string className;
float confidence;
for (int n = 0; n < 101; n++) {
if (n == 1)
start = chrono::high_resolution_clock::now();
ModelInference(srcImage, className, confidence);
}
// 显示
cv::putText(srcImage, className + ":" + std::to_string(confidence),
cv::Point(10, 20), FONT_HERSHEY_SIMPLEX, 0.6, cv::Scalar(0, 0, 255), 1, 1);
auto end = chrono::high_resolution_clock::now();
auto ms = chrono::duration_cast<std::chrono::microseconds>(end - start) / 100;
std::cout << "onnxruntime 平均推理时间:---------------------" << (ms / 1000.0).count() << "ms" << std::endl;
}
// 批量推理测试
std::vector<cv::Mat> srcImages;
for (int i = 0; i < filenames.size(); i++)
{
cv::Mat image = imread(filenames[i]);
srcImages.push_back(image);
if ((i + 1) % batchSize == 0 || i == filenames.size() - 1)
{
// 重复100次,计算平均时间
auto start = chrono::high_resolution_clock::now();
for (int n = 0; n < 101; n++) {
if (n == 1)
start = chrono::high_resolution_clock::now(); // 首次推理耗时很久
std::vector<std::string> classNames;
std::vector<float> confidences;
ModelInference_Batch(srcImages, classNames, confidences);
}
srcImages.clear();
auto end = chrono::high_resolution_clock::now();
auto ms = chrono::duration_cast<std::chrono::microseconds>(end - start) / 100;
std::cout << "onnxruntime batch" << batchSize << " 平均推理时间:---------------------" << (ms / 1000.0).count() << "ms" << std::endl;
}
}
return 0;
}
注意:ORT支持多图并行推理,但是要求转出onnx的时候batch就要使用固定数值。动态batch(即batch=-1)的onnx文件是不支持推理的。
4.2 选择CPU/GPU
使用GPU推理,只需要添加一行代码:
if (useCuda) {
// 开启CUDA加速
OrtSessionOptionsAppendExecutionProvider_CUDA(*sessionOptions, deviceId);
}
4.3 多输入多输出模型推理
推理步骤和单图推理基本一致,需要在输入tensor中依次添加所有的输入。假设模型有两个输入和两个输出:
// 创建session
session2 = new Ort::Session(env1, onnxPath, sessionOptions1);
// 获取模型输入输出信息
inputCount2 = session2->GetInputCount();
outputCount2 = session2->GetOutputCount();
// 输入和输出各有两个
Ort::AllocatorWithDefaultOptions allocator;
const char* inputName1 = session2->GetInputName(0, allocator);
const char* inputName2 = session2->GetInputName(1, allocator);
const char* outputName1 = session2->GetOutputName(0, allocator);
const char* outputName2 = session2->GetOutputName(1, allocator);
intputNames2 = { inputName1, inputName2 };
outputNames2 = { outputName1, outputName2 };
// 获取输入输出维度信息,返回类型std::vector<int64_t>
inputShape2_1 = session2->GetInputTypeInfo(0).GetTensorTypeAndShapeInfo().GetShape();
inputShape2_2 = session2->GetInputTypeInfo(1).GetTensorTypeAndShapeInfo().GetShape();
outputShape2_1 = session2->GetOutputTypeInfo(0).GetTensorTypeAndShapeInfo().GetShape();
outputShape2_2 = session2->GetOutputTypeInfo(1).GetTensorTypeAndShapeInfo().GetShape();
...
// 创建输入tensor
auto memoryInfo = Ort::MemoryInfo::CreateCpu(OrtAllocatorType::OrtArenaAllocator, OrtMemType::OrtMemTypeDefault);
std::vector<Ort::Value> inputTensors;
inputTensors.emplace_back(Ort::Value::CreateTensor<float>(memoryInfo,
blob1.ptr<float>(), blob1.total(), inputShape2_1.data(), inputShape2_1.size()));
inputTensors.emplace_back(Ort::Value::CreateTensor<float>(memoryInfo,
blob2.ptr<float>(), blob2.total(), inputShape2_2.data(), inputShape2_2.size()));
// 推理
auto outputTensors = session2->Run(Ort::RunOptions{ nullptr },
intputNames2.data(), inputTensors.data(), inputCount2, outputNames2.data(), outputCount2);
// 获取输出
float* preds1 = outputTensors[0].GetTensorMutableData<float>();
float* preds2 = outputTensors[1].GetTensorMutableData<float>();
5. TensorRT部署GoogLeNet
TRT推理有两种常见的方式:
- 通过官方安装包里边的提供的trtexec.exe工具,从onnx文件转换得到trt文件,然后执行推理;
- 由onnx文件转化得到engine文件,再执行推理。
两种方式原理一样,这里我们只介绍第二种方式。推理过程可分为两阶段:使用onnx构建推理engine和加载engine执行推理。
5.1 构建推理引擎(engine文件)
engine的构建是TensorRT推理至关重要的一步,它特定于所构建的确切GPU模型,不能跨平台或TensorRT版本移植。举个简单的例子,如果你在RTX3060上使用TensorRT 8.2.5构建了engine,那么推理部署也必须要在RTX3060上进行,且要具备TensorRT 8.2.5环境。engine构建的大致流程如下:

engine的构建有很多种方式,这里我们介绍常用的三种。我一般会选择直接在Python中构建,这样模型的训练、转onnx、转engine都在Python端完成,方便且省事。
方法一:在Python中构建
import os
import sys
import logging
import argparse
import tensorrt as trt
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
# 延迟加载模式,cuda11.7新功能,设置为LAZY有可能会极大的降低内存和显存的占用
os.environ['CUDA_MODULE_LOADING'] = 'LAZY'
logging.basicConfig(level=logging.INFO)
logging.getLogger("EngineBuilder").setLevel(logging.INFO)
log = logging.getLogger("EngineBuilder")
class EngineBuilder:
"""
Parses an ONNX graph and builds a TensorRT engine from it.
"""
def __init__(self, batch_size=1, verbose=False, workspace=8):
"""
:param verbose: If enabled, a higher verbosity level will be set on the TensorRT logger.
:param workspace: Max memory workspace to allow, in Gb.
"""
# 1. 构建builder
self.trt_logger = trt.Logger(trt.Logger.INFO)
if verbose:
self.trt_logger.min_severity = trt.Logger.Severity.VERBOSE
trt.init_libnvinfer_plugins(self.trt_logger, namespace="")
self.builder = trt.Builder(self.trt_logger)
self.config = self.builder.create_builder_config() # 构造builder.config
self.config.max_workspace_size = workspace * (2 ** 30) # workspace分配
self.batch_size = batch_size
self.network = None
self.parser = None
def create_network(self, onnx_path):
"""
Parse the ONNX graph and create the corresponding TensorRT network definition.
:param onnx_path: The path to the ONNX graph to load.
"""
network_flags = (1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
self.network = self.builder.create_network(network_flags)
self.parser = trt.OnnxParser(self.network, self.trt_logger)
onnx_path = os.path.realpath(onnx_path)
with open(onnx_path, "rb") as f:
if not self.parser.parse(f.read()):
log.error("Failed to load ONNX file: {}".format(onnx_path))
for error in range(self.parser.num_errors):
log.error(self.parser.get_error(error))
sys.exit(1)
# 获取网络输入输出
inputs = [self.network.get_input(i) for i in range(self.network.num_inputs)]
outputs = [self.network.get_output(i) for i in range(self.network.num_outputs)]
log.info("Network Description")
for input in inputs:
self.batch_size = input.shape[0]
log.info("Input '{}' with shape {} and dtype {}".format(input.name, input.shape, input.dtype))
for output in outputs:
log.info("Output '{}' with shape {} and dtype {}".format(output.name, output.shape, output.dtype))
assert self.batch_size > 0
self.builder.max_batch_size = self.batch_size
def create_engine(self, engine_path, precision):
"""
Build the TensorRT engine and serialize it to disk.
:param engine_path: The path where to serialize the engine to.
:param precision: The datatype to use for the engine, either 'fp32', 'fp16' or 'int8'.
"""
engine_path = os.path.realpath(engine_path)
engine_dir = os.path.dirname(engine_path)
os.makedirs(engine_dir, exist_ok=True)
log.info("Building {} Engine in {}".format(precision, engine_path))
inputs = [self.network.get_input(i) for i in range(self.network.num_inputs)]
if precision == "fp16":
if not self.builder.platform_has_fast_fp16:
log.warning("FP16 is not supported natively on this platform/device")
else:
self.config.set_flag(trt.BuilderFlag.FP16)
with self.builder.build_engine(self.network, self.config) as engine, open(engine_path, "wb") as f:
log.info("Serializing engine to file: {:}".format(engine_path))
f.write(engine.serialize())
def main(args):
builder = EngineBuilder(args.batch_size, args.verbose, args.workspace)
builder.create_network(args.onnx)
builder.create_engine(args.engine, args.precision)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("-o", "--onnx", default=r'googlenet-pretrained_batch8.onnx', help="The input ONNX model file to load")
parser.add_argument("-e", "--engine", default=r'googlenet-pretrained_batch8_from_py_3080_FP16.engine', help="The output path for the TRT engine")
parser.add_argument("-p", "--precision", default="fp16", choices=["fp32", "fp16", "int8"],
help="The precision mode to build in, either 'fp32', 'fp16' or 'int8', default: 'fp16'")
parser.add_argument("-b", "--batch_size", default=8, type=int, help="batch number of input")
parser.add_argument("-v", "--verbose", action="store_true", help="Enable more verbose log output")
parser.add_argument("-w", "--workspace", default=8, type=int, help="The max memory workspace size to allow in Gb, "
"default: 8")
args = parser.parse_args()
main(args)
生成fp16模型:参数precision设置为fp16即可。int8模型生成过程比较复杂,且对模型精度影响较大,用的不多,这里暂不介绍。
parser.add_argument("-p", "--precision", default="fp16", choices=["fp32", "fp16", "int8"],
help="The precision mode to build in, either 'fp32', 'fp16' or 'int8', default: 'fp16'")
方法二:在C++中构建
#include "NvInfer.h"
#include "NvOnnxParser.h"
#include "cuda_runtime_api.h"
#include "logging.h"
#include <fstream>
#include <map>
#include <chrono>
#include <cmath>
#include <opencv2/opencv.hpp>
#include <fstream>
using namespace nvinfer1;
using namespace nvonnxparser;
using namespace std;
using namespace cv;
std::string onnxPath = "E:/inference-master/models/engine/googlenet-pretrained_batch.onnx";
std::string enginePath = "E:/inference-master/models/engine/googlenet-pretrained_batch_from_cpp.engine"; // 通过C++构建
static const int INPUT_H = 224;
static const int INPUT_W = 224;
static const int OUTPUT_SIZE = 1000;
static const int BATCH_SIZE = 25;
const char* INPUT_BLOB_NAME = "input";
const char* OUTPUT_BLOB_NAME = "output";
static Logger gLogger;
// onnx转engine
void onnx_to_engine(std::string onnx_file_path, std::string engine_file_path, int type) {
// 创建builder实例,获取cuda内核目录以获取最快的实现,用于创建config、network、engine的其他对象的核心类
nvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(gLogger);
const auto explicitBatch = 1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
// 创建网络定义
nvinfer1::INetworkDefinition* network = builder->createNetworkV2(explicitBatch);
// 创建onnx解析器来填充网络
nvonnxparser::IParser* parser = nvonnxparser::createParser(*network, gLogger);
// 读取onnx模型文件
parser->parseFromFile(onnx_file_path.c_str(), 2);
for (int i = 0; i < parser->getNbErrors(); ++i) {
std::cout << "load error: " << parser->getError(i)->desc() << std::endl;
}
printf("tensorRT load mask onnx model successfully!!!...\n");
// 创建生成器配置对象
nvinfer1::IBuilderConfig* config = builder->createBuilderConfig();
builder->setMaxBatchSize(BATCH_SIZE); // 设置最大batch
config->setMaxWorkspaceSize(16 * (1 << 20)); // 设置最大工作空间大小
// 设置模型输出精度,0代表FP32,1代表FP16
if (type == 1) {
config->setFlag(nvinfer1::BuilderFlag::kFP16);
}
// 创建推理引擎
nvinfer1::ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
// 将推理引擎保存到本地
std::cout << "try to save engine file now~~~" << std::endl;
std::ofstream file_ptr(engine_file_path, std::ios::binary);
if (!file_ptr) {
std::cerr << "could not open plan output file" << std::endl;
return;
}
// 将模型转化为文件流数据
nvinfer1::IHostMemory* model_stream = engine->serialize();
// 将文件保存到本地
file_ptr.write(reinterpret_cast<const char*>(model_stream->data()), model_stream->size());
// 销毁创建的对象
model_stream->destroy();
engine->destroy();
network->destroy();
parser->destroy();
std::cout << "convert onnx model to TensorRT engine model successfully!" << std::endl;
}
int main(int argc, char** argv)
{
// onnx转engine
onnx_to_engine(onnxPath, enginePath, 0);
return 0;
}
方法三:使用官方安装包bin目录下的trtexec.exe工具构建
trtexec.exe --onnx=googlenet-pretrained_batch.onnx --saveEngine=googlenet-pretrained_batch_from_trt_trt853.engine --shapes=input:25x3x224x224
fp16模型:在后边加--fp16即可
trtexec.exe --onnx=googlenet-pretrained_batch.onnx --saveEngine=googlenet-pretrained_batch_from_trt_trt853.engine --shapes=input:25x3x224x224 --fp16
5.2 读取engine文件并部署模型

推理代码:
#include "NvInfer.h"
#include "NvOnnxParser.h"
#include "cuda_runtime_api.h"
#include "logging.h"
#include <fstream>
#include <map>
#include <chrono>
#include <cmath>
#include <opencv2/opencv.hpp>
#include "cuda.h"
#include "assert.h"
#include "iostream"
using namespace nvinfer1;
using namespace nvonnxparser;
using namespace std;
using namespace cv;
#define CHECK(status) \
do\
{\
auto ret = (status);\
if (ret != 0)\
{\
std::cerr << "Cuda failure: " << ret << std::endl;\
abort();\
}\
} while (0)
std::string enginePath = "E:/inference-master/models/GoogLeNet/googlenet-pretrained_batch1_from_py_3080_FP32.engine";
std::string imagePath = "E:/inference-master/images/catdog";
std::string classNamesPath = "E:/inference-master/imagenet-classes.txt"; // 标签名称列表(类名)
std::vector<std::string> classNameList; // 标签名列表
static const int INPUT_H = 224;
static const int INPUT_W = 224;
static const int CHANNEL = 3;
static const int OUTPUT_SIZE = 1000;
static const int BATCH_SIZE = 1;
const char* INPUT_BLOB_NAME = "input";
const char* OUTPUT_BLOB_NAME = "output";
static Logger gLogger;
IRuntime* runtime;
ICudaEngine* engine;
IExecutionContext* context;
void* gpu_buffers[2];
cudaStream_t stream;
const int inputIndex = 0;
const int outputIndex = 1;
// 提前申请内存,可节省推理时间
static float mydata[BATCH_SIZE * CHANNEL * INPUT_H * INPUT_W];
static float prob[BATCH_SIZE * OUTPUT_SIZE];
// 逐行求softmax
int softmax(const cv::Mat & src, cv::Mat & dst)
{
float max = 0.0;
float sum = 0.0;
cv::Mat tmpdst = cv::Mat::zeros(src.size(), src.type());
std::vector<cv::Mat> srcRows;
// 逐行求softmax
for (size_t i = 0; i < src.rows; i++)
{
cv::Mat tmpRow;
cv::Mat dataRow = src.row(i).clone();
max = *std::max_element(dataRow.begin<float>(), dataRow.end<float>());
cv::exp((dataRow - max), tmpRow);
sum = cv::sum(tmpRow)[0];
tmpRow /= sum;
srcRows.push_back(tmpRow);
cv::vconcat(srcRows, tmpdst);
}
dst = tmpdst.clone();
return 0;
}
// onnx转engine
void onnx_to_engine(std::string onnx_file_path, std::string engine_file_path, int type) {
// 创建builder实例,获取cuda内核目录以获取最快的实现,用于创建config、network、engine的其他对象的核心类
nvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(gLogger);
const auto explicitBatch = 1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
// 创建网络定义
nvinfer1::INetworkDefinition* network = builder->createNetworkV2(explicitBatch);
// 创建onnx解析器来填充网络
nvonnxparser::IParser* parser = nvonnxparser::createParser(*network, gLogger);
// 读取onnx模型文件
parser->parseFromFile(onnx_file_path.c_str(), 2);
for (int i = 0; i < parser->getNbErrors(); ++i) {
std::cout << "load error: " << parser->getError(i)->desc() << std::endl;
}
printf("tensorRT load mask onnx model successfully!!!...\n");
// 创建生成器配置对象
nvinfer1::IBuilderConfig* config = builder->createBuilderConfig();
builder->setMaxBatchSize(BATCH_SIZE); // 设置最大batch
config->setMaxWorkspaceSize(16 * (1 << 20)); // 设置最大工作空间大小
// 设置模型输出精度
if (type == 1) {
config->setFlag(nvinfer1::BuilderFlag::kFP16);
}
if (type == 2) {
config->setFlag(nvinfer1::BuilderFlag::kINT8);
}
// 创建推理引擎
nvinfer1::ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
// 将推理引擎保存到本地
std::cout << "try to save engine file now~~~" << std::endl;
std::ofstream file_ptr(engine_file_path, std::ios::binary);
if (!file_ptr) {
std::cerr << "could not open plan output file" << std::endl;
return;
}
// 将模型转化为文件流数据
nvinfer1::IHostMemory* model_stream = engine->serialize();
// 将文件保存到本地
file_ptr.write(reinterpret_cast<const char*>(model_stream->data()), model_stream->size());
// 销毁创建的对象
model_stream->destroy();
engine->destroy();
network->destroy();
parser->destroy();
std::cout << "convert onnx model to TensorRT engine model successfully!" << std::endl;
}
// 模型推理:包括创建GPU显存缓冲区、配置模型输入及模型推理
void doInference(IExecutionContext& context, const void* input, float* output, int batchSize)
{
//auto start = chrono::high_resolution_clock::now();
// DMA input batch data to device, infer on the batch asynchronously, and DMA output back to host
CHECK(cudaMemcpyAsync(gpu_buffers[inputIndex], input, batchSize * 3 * INPUT_H * INPUT_W * sizeof(float), cudaMemcpyHostToDevice, stream));
// context.enqueue(batchSize, buffers, stream, nullptr);
context.enqueueV2(gpu_buffers, stream, nullptr);
//auto end1 = std::chrono::high_resolution_clock::now();
//auto ms1 = std::chrono::duration_cast<std::chrono::microseconds>(end1 - start);
//std::cout << "推理: " << (ms1 / 1000.0).count() << "ms" << std::endl;
CHECK(cudaMemcpyAsync(output, gpu_buffers[outputIndex], batchSize * OUTPUT_SIZE * sizeof(float), cudaMemcpyDeviceToHost, stream));
//size_t dest_pitch = 0;
//CHECK(cudaMemcpy2D(output, dest_pitch, buffers[outputIndex], batchSize * sizeof(float), batchSize, OUTPUT_SIZE, cudaMemcpyDeviceToHost));
cudaStreamSynchronize(stream);
//auto end2 = std::chrono::high_resolution_clock::now();
//auto ms2 = std::chrono::duration_cast<std::chrono::microseconds>(end2 - start)/100.0;
//std::cout << "cuda-host: " << (ms2 / 1000.0).count() << "ms" << std::endl;
}
// 结束推理,释放资源
void GpuMemoryRelease()
{
// Release stream and buffers
cudaStreamDestroy(stream);
CHECK(cudaFree(gpu_buffers[0]));
CHECK(cudaFree(gpu_buffers[1]));
// Destroy the engine
context->destroy();
engine->destroy();
runtime->destroy();
}
// GoogLeNet模型初始化
void ModelInit(std::string enginePath, int deviceId)
{
// 设置GPU
cudaSetDevice(deviceId);
// 从本地读取engine模型文件
char* trtModelStream{ nullptr };
size_t size{ 0 };
std::ifstream file(enginePath, std::ios::binary);
if (file.good()) {
file.seekg(0, file.end); // 将读指针从文件末尾开始移动0个字节
size = file.tellg(); // 返回读指针的位置,此时读指针的位置就是文件的字节数
file.seekg(0, file.beg); // 将读指针从文件开头开始移动0个字节
trtModelStream = new char[size];
assert(trtModelStream);
file.read(trtModelStream, size);
file.close();
}
// 创建推理运行环境实例
runtime = createInferRuntime(gLogger);
assert(runtime != nullptr);
// 反序列化模型
engine = runtime->deserializeCudaEngine(trtModelStream, size, nullptr);
assert(engine != nullptr);
// 创建推理上下文
context = engine->createExecutionContext();
assert(context != nullptr);
delete[] trtModelStream;
// Create stream
CHECK(cudaStreamCreate(&stream));
// Pointers to input and output device buffers to pass to engine.
// Engine requires exactly IEngine::getNbBindings() number of buffers.
assert(engine.getNbBindings() == 2);
// In order to bind the buffers, we need to know the names of the input and output tensors.
// Note that indices are guaranteed to be less than IEngine::getNbBindings()
const int inputIndex = engine->getBindingIndex(INPUT_BLOB_NAME);
const int outputIndex = engine->getBindingIndex(OUTPUT_BLOB_NAME);
// Create GPU buffers on device
CHECK(cudaMalloc(&gpu_buffers[inputIndex], BATCH_SIZE * 3 * INPUT_H * INPUT_W * sizeof(float)));
CHECK(cudaMalloc(&gpu_buffers[outputIndex], BATCH_SIZE * OUTPUT_SIZE * sizeof(float)));
// 读取标签名称
ifstream fin(classNamesPath.c_str());
string strLine;
classNameList.clear();
while (getline(fin, strLine))
classNameList.push_back(strLine);
fin.close();
}
// 单图推理
bool ModelInference(cv::Mat srcImage, std::string& className, float& confidence)
{
auto start = chrono::high_resolution_clock::now();
cv::Mat image = srcImage.clone();
// 预处理(尺寸变换、通道变换、归一化)
cv::cvtColor(image, image, cv::COLOR_BGR2RGB);
cv::resize(image, image, cv::Size(224, 224));
image.convertTo(image, CV_32FC3, 1.0 / 255.0);
cv::Scalar mean(0.485, 0.456, 0.406);
cv::Scalar std(0.229, 0.224, 0.225);
cv::subtract(image, mean, image);
cv::divide(image, std, image);
// cv::Mat blob = cv::dnn::blobFromImage(image);
// 下边代码比上边blobFromImages速度更快
for (int r = 0; r < INPUT_H; r++)
{
float* rowData = image.ptr<float>(r);
for (int c = 0; c < INPUT_W; c++)
{
mydata[0 * INPUT_H * INPUT_W + r * INPUT_W + c] = rowData[CHANNEL * c];
mydata[1 * INPUT_H * INPUT_W + r * INPUT_W + c] = rowData[CHANNEL * c + 1];
mydata[2 * INPUT_H * INPUT_W + r * INPUT_W + c] = rowData[CHANNEL * c + 2];
}
}
// 模型推理
// doInference(*context, blob.data, prob, BATCH_SIZE);
doInference(*context, mydata, prob, BATCH_SIZE);
// 推理结果后处理
cv::Mat preds = cv::Mat(BATCH_SIZE, OUTPUT_SIZE, CV_32FC1, (float*)prob);
softmax(preds, preds);
Point minLoc, maxLoc;
double minValue = 0, maxValue = 0;
cv::minMaxLoc(preds, &minValue, &maxValue, &minLoc, &maxLoc);
int labelIndex = maxLoc.x;
double probability = maxValue;
className = classNameList[labelIndex];
confidence = probability;
std::cout << "class:" << className << endl << "confidence:" << confidence << endl;
auto end = chrono::high_resolution_clock::now();
auto ms = chrono::duration_cast<std::chrono::microseconds>(end - start);
std::cout << "Inference time by TensorRT:" << (ms / 1000.0).count() << "ms" << std::endl;
return 0;
}
// GoogLeNet模型推理
bool ModelInference_Batch(std::vector<cv::Mat> srcImages, std::vector<std::string>& classNames, std::vector<float>& confidences)
{
auto start = std::chrono::high_resolution_clock::now();
if (srcImages.size() != BATCH_SIZE) return false;
// 预处理(尺寸变换、通道变换、归一化)
std::vector<cv::Mat> images;
for (size_t i = 0; i < srcImages.size(); i++)
{
cv::Mat image = srcImages[i].clone();
cv::cvtColor(image, image, cv::COLOR_BGR2RGB);
cv::resize(image, image, cv::Size(224, 224));
image.convertTo(image, CV_32FC3, 1.0 / 255.0);
cv::Scalar mean(0.485, 0.456, 0.406);
cv::Scalar std(0.229, 0.224, 0.225);
cv::subtract(image, mean, image);
cv::divide(image, std, image);
images.push_back(image);
}
// 图像转blob格式
// cv::Mat blob = cv::dnn::blobFromImages(images);
// 下边代码比上边blobFromImages速度更快
for (int b = 0; b < BATCH_SIZE; b++)
{
cv::Mat image = images[b];
for (int r = 0; r < INPUT_H; r++)
{
float* rowData = image.ptr<float>(r);
for (int c = 0; c < INPUT_W; c++)
{
mydata[b * CHANNEL * INPUT_H * INPUT_W + 0 * INPUT_H * INPUT_W + r * INPUT_W + c] = rowData[CHANNEL * c];
mydata[b * CHANNEL * INPUT_H * INPUT_W + 1 * INPUT_H * INPUT_W + r * INPUT_W + c] = rowData[CHANNEL * c + 1];
mydata[b * CHANNEL * INPUT_H * INPUT_W + 2 * INPUT_H * INPUT_W + r * INPUT_W + c] = rowData[CHANNEL * c + 2];
}
}
}
auto end1 = std::chrono::high_resolution_clock::now();
auto ms1 = std::chrono::duration_cast<std::chrono::microseconds>(end1 - start);
std::cout << "PreProcess time: " << (ms1 / 1000.0).count() << "ms" << std::endl;
// 执行推理
doInference(*context, mydata, prob, BATCH_SIZE);
auto end2 = std::chrono::high_resolution_clock::now();
auto ms2 = std::chrono::duration_cast<std::chrono::microseconds>(end2 - end1);
std::cout << "Inference time: " << (ms2 / 1000.0).count() << "ms" << std::endl;
// 推理结果后处理
cv::Mat result = cv::Mat(BATCH_SIZE, OUTPUT_SIZE, CV_32FC1, (float*)prob);
softmax(result, result);
for (int r = 0; r < BATCH_SIZE; r++)
{
cv::Mat scores = result.row(r).clone();
cv::Point minLoc, maxLoc;
double minValue = 0, maxValue = 0;
cv::minMaxLoc(scores, &minValue, &maxValue, &minLoc, &maxLoc);
int labelIndex = maxLoc.x;
double probability = maxValue;
classNames.push_back(classNameList[labelIndex]);
confidences.push_back(probability);
}
auto end3 = std::chrono::high_resolution_clock::now();
auto ms3 = std::chrono::duration_cast<std::chrono::microseconds>(end3 - end2);
std::cout << "PostProcess time: " << (ms3 / 1000.0).count() << "ms" << std::endl;
auto ms = std::chrono::duration_cast<std::chrono::microseconds>(end3 - start);
std::cout << "TensorRT batch" << BATCH_SIZE << " 推理时间:" << (ms / 1000.0).count() << "ms" << std::endl;
return true;
}
int main(int argc, char** argv)
{
// onnx转engine
// onnx_to_engine(onnxPath, enginePath, 0);
// 模型初始化
ModelInit(enginePath, 0);
// 读取图像
vector<string> filenames;
cv::glob(imagePath, filenames);
// 单图推理测试
for (int n = 0; n < filenames.size(); n++)
{
// 重复100次,计算平均时间
auto start = chrono::high_resolution_clock::now();
cv::Mat src = imread(filenames[n]);
std::string className;
float confidence;
for (int i = 0; i < 101; i++) {
if (i == 1)
start = chrono::high_resolution_clock::now();
ModelInference(src, className, confidence);
}
auto end = chrono::high_resolution_clock::now();
auto ms = chrono::duration_cast<std::chrono::microseconds>(end - start) / 100;
std::cout << "TensorRT 平均推理时间:---------------------" << (ms / 1000.0).count() << "ms" << std::endl;
}
// 批量(动态batch)推理测试
std::vector<cv::Mat> srcImages;
int okNum = 0, ngNum = 0;
for (int n = 0; n < filenames.size(); n++)
{
cv::Mat image = imread(filenames[n]);
srcImages.push_back(image);
if ((n + 1) % BATCH_SIZE == 0 || n == filenames.size() - 1)
{
// 重复100次,计算平均时间
auto start = chrono::high_resolution_clock::now();
for (int i = 0; i < 101; i++) {
if (i == 1)
start = chrono::high_resolution_clock::now();
std::vector<std::string> classNames;
std::vector<float> confidences;
ModelInference_Batch(srcImages, classNames, confidences);
for (int j = 0; j < classNames.size(); j++)
{
if (classNames[j] == "0")
okNum++;
else
ngNum++;
}
}
srcImages.clear();
auto end = chrono::high_resolution_clock::now();
auto ms = chrono::duration_cast<std::chrono::microseconds>(end - start) / 100;
std::cout << "TensorRT " << BATCH_SIZE << " 平均推理时间:---------------------" << (ms / 1000.0).count() << "ms" << std::endl;
}
}
GpuMemoryRelease();
std::cout << "all_num = " << filenames.size() << endl << "okNum = " << okNum << endl << "ngNum = " << ngNum << endl;
return 0;
}
5.3 fp32、fp16模型对比测试
fp16模型推理结果几乎和fp32一致,但是却较大的节约了显存和内存占用,同时推理速度也有明显的提升。
6. OpenVINO部署GoogLeNet
6.1 推理过程及代码

代码:
/* 推理过程
* 1. Create OpenVINO-Runtime Core
* 2. Compile Model
* 3. Create Inference Request
* 4. Set Inputs
* 5. Start Inference
* 6. Process inference Results
*/
#include <opencv2/opencv.hpp>
#include <openvino/openvino.hpp>
#include <inference_engine.hpp>
#include <chrono>
#include <fstream>
using namespace std;
using namespace InferenceEngine;
using namespace cv;
std::string onnxPath = "E:/inference-master/models/GoogLeNet/googlenet-pretrained_batch1.onnx";
std::string imagePath = "E:/inference-master/images/catdog";
std::string classNamesPath = "E:/inference-master/imagenet-classes.txt"; // 标签名称列表(类名)
ov::InferRequest inferRequest;
std::vector<std::string> classNameList; // 标签名,可以从文件读取
int batchSize = 1;
// softmax,输入输出为数组
std::vector<float> softmax(std::vector<float> input)
{
float total = 0;
for (auto x : input)
total += exp(x);
std::vector<float> result;
for (auto x : input)
result.push_back(exp(x) / total);
return result;
}
// softmax,输入输出为Mat
int softmax(const cv::Mat& src, cv::Mat& dst)
{
float max = 0.0;
float sum = 0.0;
max = *max_element(src.begin<float>(), src.end<float>());
cv::exp((src - max), dst);
sum = cv::sum(dst)[0];
dst /= sum;
return 0;
}
// 模型初始化
void ModelInit(string onnxPath)
{
// Step 1: 创建一个Core对象
ov::Core core;
// 打印当前设备
std::vector<std::string> availableDevices = core.get_available_devices();
for (int i = 0; i < availableDevices.size(); i++)
printf("supported device name: %s\n", availableDevices[i].c_str());
// Step 2: 读取模型
std::shared_ptr<ov::Model> model = core.read_model(onnxPath);
// Step 3: 加载模型到CPU
ov::CompiledModel compiled_model = core.compile_model(model, "CPU");
// 设置推理实例并发数为5个
//core.set_property("CPU", ov::streams::num(10));
// 设置推理实例数为自动分配
//core.set_property("CPU", ov::streams::num(ov::streams::AUTO));
// 推理实例数按计算资源平均分配
//core.set_property("CPU", ov::streams::num(ov::streams::NUMA));
// 设置推理实例的线程并发数为10
// core.set_property("CPU", ov::inference_num_threads(20));
// Step 4: 创建推理请求
inferRequest = compiled_model.create_infer_request();
// 读取标签名称
ifstream fin(classNamesPath.c_str());
string strLine;
classNameList.clear();
while (getline(fin, strLine))
classNameList.push_back(strLine);
fin.close();
}
// 单图推理
void ModelInference(cv::Mat srcImage, std::string& className, float& confidence )
{
auto start = chrono::high_resolution_clock::now();
// Step 5: 将输入数据填充到输入tensor
// 通过索引获取输入tensor
ov::Tensor input_tensor = inferRequest.get_input_tensor(0);
// 通过名称获取输入tensor
// ov::Tensor input_tensor = infer_request.get_tensor("input");
// 预处理
cv::Mat image = srcImage.clone();
cv::cvtColor(image, image, cv::COLOR_BGR2RGB);
resize(image, image, Size(224, 224));
image.convertTo(image, CV_32FC3, 1.0 / 255.0);
Scalar mean(0.485, 0.456, 0.406);
Scalar std(0.229, 0.224, 0.225);
subtract(image, mean, image);
divide(image, std, image);
// HWC -> NCHW
ov::Shape tensor_shape = input_tensor.get_shape();
const size_t channels = tensor_shape[1];
const size_t height = tensor_shape[2];
const size_t width = tensor_shape[3];
float* image_data = input_tensor.data<float>();
for (size_t r = 0; r < height; r++) {
for (size_t c = 0; c < width * channels; c++) {
int w = (r * width * channels + c) / channels;
int mod = (r * width * channels + c) % channels; // 0,1,2
image_data[mod * width * height + w] = image.at<float>(r, c);
}
}
// --------------- Step 6: Start inference ---------------
inferRequest.infer();
// --------------- Step 7: Process the inference results ---------------
// model has only one output
auto output_tensor = inferRequest.get_output_tensor();
float* detection = (float*)output_tensor.data();
ov::Shape out_shape = output_tensor.get_shape();
int batch = output_tensor.get_shape()[0];
int num_classes = output_tensor.get_shape()[1];
cv::Mat result(batch, num_classes, CV_32F, detection);
softmax(result, result);
Point minLoc, maxLoc;
double minValue = 0, maxValue = 0;
cv::minMaxLoc(result, &minValue, &maxValue, &minLoc, &maxLoc);
int labelIndex = maxLoc.x;
double probability = maxValue;
auto end = chrono::high_resolution_clock::now();
auto ms = chrono::duration_cast<std::chrono::milliseconds>(end - start);
std::cout << "openvino单张推理时间:" << ms.count() << "ms" << std::endl;
}
// 多图并行推理(动态batch)
void ModelInference_Batch(std::vector<cv::Mat> srcImages, std::vector<string>& classNames, std::vector<float>& confidences)
{
auto start = chrono::high_resolution_clock::now();
// Step 5: 将输入数据填充到输入tensor
// 通过索引获取输入tensor
ov::Tensor input_tensor = inferRequest.get_input_tensor(0);
// 通过名称获取输入tensor
// ov::Tensor input_tensor = infer_request.get_tensor("input");
// 预处理(尺寸变换、通道变换、归一化)
std::vector<cv::Mat> images;
for (size_t i = 0; i < srcImages.size(); i++)
{
cv::Mat image = srcImages[i].clone();
cv::cvtColor(image, image, cv::COLOR_BGR2RGB);
cv::resize(image, image, cv::Size(224, 224));
image.convertTo(image, CV_32FC3, 1.0 / 255.0);
cv::Scalar mean(0.485, 0.456, 0.406);
cv::Scalar std(0.229, 0.224, 0.225);
cv::subtract(image, mean, image);
cv::divide(image, std, image);
images.push_back(image);
}
ov::Shape tensor_shape = input_tensor.get_shape();
const size_t batch = tensor_shape[0];
const size_t channels = tensor_shape[1];
const size_t height = tensor_shape[2];
const size_t width = tensor_shape[3];
float* image_data = input_tensor.data<float>();
// 图像转blob格式(速度比下边像素操作方式更快)
cv::Mat blob = cv::dnn::blobFromImages(images);
memcpy(image_data, blob.data, batch * 3 * height * width * sizeof(float));
// NHWC -> NCHW
//for (size_t b = 0; b < batch; b++){
// for (size_t r = 0; r < height; r++) {
// for (size_t c = 0; c < width * channels; c++) {
// int w = (r * width * channels + c) / channels;
// int mod = (r * width * channels + c) % channels; // 0,1,2
// image_data[b * 3 * width * height + mod * width * height + w] = images[b].at<float>(r, c);
// }
// }
//}
auto end1 = std::chrono::high_resolution_clock::now();
auto ms1 = std::chrono::duration_cast<std::chrono::microseconds>(end1 - start);
std::cout << "PreProcess time: " << (ms1 / 1000.0).count() << "ms" << std::endl;
// --------------- Step 6: Start inference ---------------
inferRequest.infer();
auto end2 = std::chrono::high_resolution_clock::now();
auto ms2 = std::chrono::duration_cast<std::chrono::microseconds>(end2 - end1)/100;
std::cout << "Inference time: " << (ms2 / 1000.0).count() << "ms" << std::endl;
// --------------- Step 7: Process the inference results ---------------
// model has only one output
auto output_tensor = inferRequest.get_output_tensor();
float* detection = (float*)output_tensor.data();
ov::Shape out_shape = output_tensor.get_shape();
int num_classes = output_tensor.get_shape()[1];
cv::Mat output(batch, num_classes, CV_32F, detection);
int rows = output.size[0]; // batch
int cols = output.size[1]; // 类别数(每一个类别的得分)
for (int row = 0; row < rows; row++)
{
cv::Mat scores(1, cols, CV_32FC1, output.ptr<float>(row));
softmax(scores, scores); // 结果归一化
Point minLoc, maxLoc;
double minValue = 0, maxValue = 0;
cv::minMaxLoc(scores, &minValue, &maxValue, &minLoc, &maxLoc);
int labelIndex = maxLoc.x;
double probability = maxValue;
classNames.push_back(classNameList[labelIndex]);
confidences.push_back(probability);
}
auto end3 = std::chrono::high_resolution_clock::now();
auto ms3 = std::chrono::duration_cast<std::chrono::microseconds>(end3 - end2);
std::cout << "PostProcess time: " << (ms3 / 1000.0).count() << "ms" << std::endl;
auto ms = chrono::duration_cast<std::chrono::milliseconds>(end3 - start);
std::cout << "openvino单张推理时间:" << ms.count() << "ms" << std::endl;
}
int main(int argc, char** argv)
{
// 模型初始化
ModelInit(onnxPath);
// 读取图像
vector<string> filenames;
glob(imagePath, filenames);
// 单图推理测试
for (int n = 0; n < filenames.size(); n++)
{
// 重复100次,计算平均时间
auto start = chrono::high_resolution_clock::now();
for (int i = 0; i < 101; i++) {
if (i == 1)
start = chrono::high_resolution_clock::now();
cv::Mat src = imread(filenames[n]);
std::string className;
float confidence;
ModelInference(src, className, confidence);
}
auto end = chrono::high_resolution_clock::now();
auto ms = chrono::duration_cast<std::chrono::microseconds>(end - start) / 100.0;
std::cout << "opencv_dnn 单图平均推理时间:---------------------" << (ms / 1000.0).count() << "ms" << std::endl;
}
std::vector<cv::Mat> srcImages;
for (int i = 0; i < filenames.size(); i++)
{
cv::Mat image = imread(filenames[i]);
srcImages.push_back(image);
if ((i + 1) % batchSize == 0 || i == filenames.size() - 1)
{
// 重复100次,计算平均时间
auto start = chrono::high_resolution_clock::now();
for (int i = 0; i < 101; i++) {
if (i == 1)
start = chrono::high_resolution_clock::now();
std::vector<std::string> classNames;
std::vector<float> confidences;
ModelInference_Batch(srcImages, classNames, confidences);
}
srcImages.clear();
auto end = chrono::high_resolution_clock::now();
auto ms = chrono::duration_cast<std::chrono::microseconds>(end - start) / 100;
std::cout << "openvino batch" << batchSize << " 平均推理时间:---------------------" << (ms / 1000.0).count() << "ms" << std::endl;
}
}
return 0;
}
注意:OV支持多图并行推理,但是要求转出onnx的时候batch就要使用固定数值。动态batch(即batch=-1)的onnx文件会报错。
6.2 遇到的问题
理论:OpenVINO是基于CPU推理最佳的方式。
实测:在测试OpenVINO的过程中,我们发现OpenVINO推理对于CPU的利用率远没有OpenCV DNN和ONNXRuntime高,这也是随着batch数量增加,OV在CPU上的推理速度反而不如DNN和ORT的主要原因。尝试过网上的多种优化方式,比如设置线程数并发数等等,未取得任何改善。如下图,在OpenVINO推理过程中,始终只有一半的CPU处于活跃状态;而OnnxRuntime或者OpenCV DNN推理时,所有的CPU均处于活跃状态。


7. 四种推理方式对比测试
深度学习领域常用的基于CPU/GPU的推理方式有OpenCV DNN、ONNXRuntime、TensorRT以及OpenVINO。这几种方式的推理过程可以统一用下图来概述。整体可分为模型初始化部分和推理部分,后者包括步骤2-5。
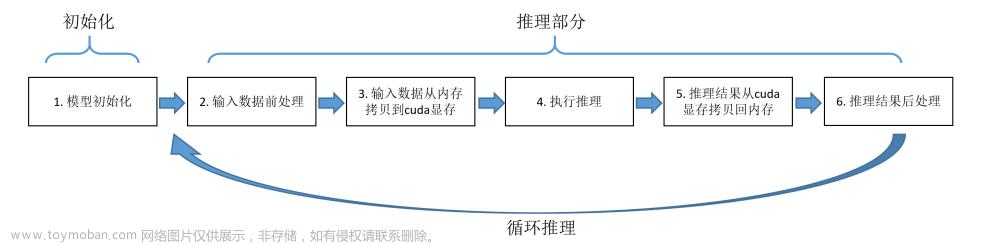
以GoogLeNet模型为例,测得几种推理方式在推理部分的耗时如下:

基于CPU推理:

基于GPU推理:

不论采用何种推理方式,同一网络的前处理和后处理过程基本都是一致的。所以,为了更直观的对比几种推理方式的速度,我们抛去前后处理,只统计图中实际推理部分,即3、4、5这三个过程的执行时间。
同样是GoogLeNet网络,步骤3-5的执行时间对比如下:

注:OpenVINO-CPU测试中始终只使用了一半数量的内核,各种优化设置都没有改善。
最终结论:
- GPU加速首选TensorRT;
- CPU加速,单图推理首选OpenVINO,多图并行推理可选择ONNXRuntime;
- 如果需要兼具CPU和GPU推理功能,可选择ONNXRuntime。
参考资料
1. openvino2022版安装配置与C++SDK开发详解
2. https://github.com/NVIDIA/TensorRT
3. https://github.com/wang-xinyu/tensorrtx文章来源:https://www.toymoban.com/news/detail-460341.html
4. 【TensorRT】TensorRT 部署Yolov5模型(C++)文章来源地址https://www.toymoban.com/news/detail-460341.html
到了这里,关于【模型部署 01】C++实现分类模型(以GoogLeNet为例)在OpenCV DNN、ONNXRuntime、TensorRT、OpenVINO上的推理部署的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!