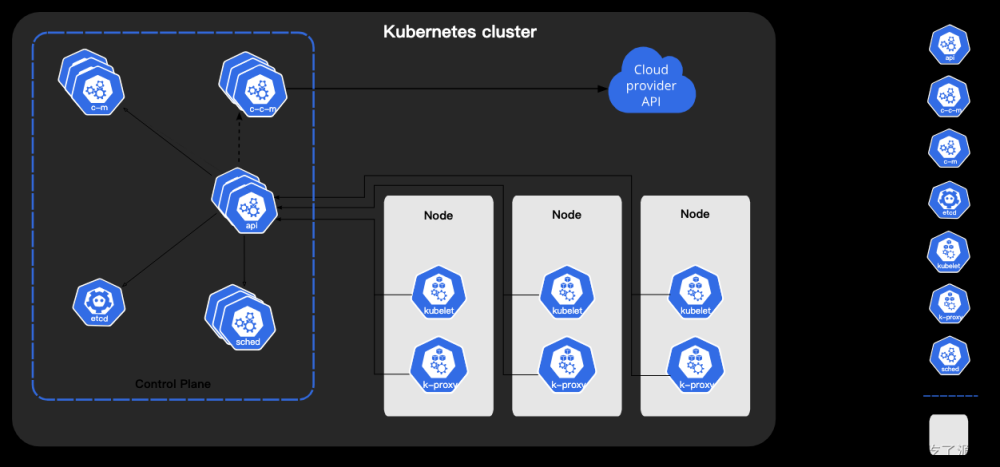
闲来无事,搭一个k8s集群玩玩
环境准备
最近一次搭建:全过程耗时1.5H
新建3个虚拟机,详情见:虚拟机新建
主机硬件配置说明
最低要求:2c2g
| 需求 | CPU | 内存 | 硬盘 | 角色 | 主机名 |
|---|---|---|---|---|---|
| 值 | 4C | 8G | 100GB | master | master01 |
| 值 | 4C | 8G | 100GB | worker(node) | worker01 |
| 值 | 4C | 8G | 100GB | worker(node) | worker02 |
主机配置
1.主机名配置
由于本次使用3台主机完成kubernetes集群部署,其中1台为master节点,名称为master01;其中2台为worker节点,名称分别为:worker01及worker02
#master节点,名称为master1
hostnamectl set-hostname master01
#worker1节点,名称为worker1
hostnamectl set-hostname worker01
#worker2节点,名称为worker2
hostnamectl set-hostname worker02
2.查看ip配置,所有主机均需要操作
#修改ip为静态ip
#都需要改:
BOOTPROTO="none"
#master:
IPADDR="192.168.182.134"
PREFIX="24"
GATEWAY="192.168.182.2"
DNS1="119.29.29.29"
#worker01
IPADDR="192.168.182.135"
PREFIX="24"
GATEWAY="192.168.182.2"
DNS1="119.29.29.29"
#worker02
IPADDR="192.168.182.136"
PREFIX="24"
GATEWAY="192.168.182.2"
DNS1="119.29.29.29"
#修改完成之后重启网络
systemctl restart network
3.主机名与IP地址解析,所有主机均需要操作
192.168.182.134 master01
192.168.182.135 worker01
192.168.182.136 worker02
4.防火墙配置,所有主机均需要操作
关闭现有防火墙firewalld
systemctl disable firewalld
systemctl stop firewalld
firewall-cmd --state
#提示:not running
5.SELINUX配置,所有主机均需要操作。修改SELinux配置需要重启操作系统。
sed -ri 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
6.时间同步配置,所有主机均需要操作。最小化安装系统需要安装ntpdate软件。
which ntpdate
crontab -e #编辑定时任务
0 */1 * * * /usr/sbin/ntpdate time1.aliyun.com
crontab -l #查看现存定时任务
7.升级操作系统内核,所有主机均需要操作。
导入elrepo gpg key
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
安装elrepo YUM源仓库
yum -y install https://www.elrepo.org/elrepo-release-7.0-4.el7.elrepo.noarch.rpm
yum repolist
安装kernel-ml版本,ml为长期稳定版本,lt为长期维护版本
yum --enablerepo="elrepo-kernel" -y install kernel-ml.x86_64
设置grub2默认引导为0
grub2-set-default 0
重新生成grub2引导文件
grub2-mkconfig -o /boot/grub2/grub.cfg
更新后,需要重启,使用升级的内核生效。
reboot
重启后,需要验证内核是否为更新对应的版本
uname -r
8.配置内核转发及网桥过滤,所有主机均需要操作。
添加网桥过滤及内核转发配置文件
cat /etc/sysctl.d/k8s.conf #提示没有这个文件
vim /etc/sysctl.d/k8s.conf
添加如下内容:
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
vm.swappiness = 0
加载br_netfilter模块
modprobe br_netfilter
sysctl -p
查看是否加载
lsmod | grep br_netfilter
br_netfilter 22256 0
bridge 151336 1 br_netfilter
9.安装ipset及ipvsadm,所有主机均需要操作。主要用于实现service转发。
安装ipset及ipvsadm
yum -y install ipset ipvsadm
yum repolist
配置ipvsadm模块加载方式
添加需要加载的模块
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack
EOF
授权、运行、检查是否加载
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack
10.关闭SWAP分区,所有主机均需要操作,修改完成后需要重启操作系统,如不重启,可临时关闭,命令为swapoff -a
临时关闭,不建议使用:
swapoff -a
查看是否关闭:
free -m
永远关闭swap分区,需要重启操作系统
vi /etc/fstab
......
# /dev/mapper/centos-swap swap swap defaults 0 0
在上一行中行首添加#
reboot
docker安装
所有集群主机均需操作。
1.获取YUM源
#使用阿里云开源软件镜像站。
wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo
yum repolist
2 查看可安装版本
yum list docker-ce.x86_64 --showduplicates | sort -r
3 安装指定版本并设置启动及开机自启动
yum -y install --setopt=obsoletes=0 docker-ce-20.10.9-3.el7
#设置开机自启动
systemctl enable docker ; systemctl start docker
4 修改cgroup方式
在/etc/docker/daemon.json添加如下内容
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
5 重启docker
systemctl restart docker
集群部署
1.集群软件及版本说明
2 kubernetes YUM源准备,所有集群主机均需操作
谷歌YUM源
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg
https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
EOF
yum check-update #清除yum缓存
阿里云:
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
yum check-update #清除yum缓存
华为云:具体见:https://www.huaweicloud.com/zhishi/Kubernetes.html
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://repo.huaweicloud.com/kubernetes/yum/repos/kubernetes-el7-$basearch
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://repo.huaweicloud.com/kubernetes/yum/doc/yum-key.gpg https://repo.huaweicloud.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
yum check-update #清除yum缓存
执行完成之后 需要刷新yum源
yum repolist
此处使用阿里云
发现报错:
https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/repodata/repomd.xml: [Errno -1] repomd.xml signature could not be verified for kubernetes
正在尝试其它镜像。
修改上边的repo_gpgcheck=0跳过验证
vim /etc/yum.repos.d/kubernetes.repo
修改:
repo_gpgcheck=0
3 集群软件安装,所有集群主机均需操作
# 查看指定版本
yum list kubeadm.x86_64 --showduplicates | sort -r
yum list kubelet.x86_64 --showduplicates | sort -r
yum list kubectl.x86_64 --showduplicates | sort -r
# 安装指定版本
yum -y install --setopt=obsoletes=0 kubeadm-1.21.0-0 kubelet-1.21.0-0 kubectl-1.21.0-0
4 配置kubelet
为了实现docker使用的cgroupdriver与kubelet使用的cgroup的一致性,建议修改如下文件内容。
vim /etc/sysconfig/kubelet
加入:
KUBELET_EXTRA_ARGS="--cgroup-driver=systemd"
#设置kubelet为开机自启动即可,由于没有生成配置文件,集群初始化后自动启动
systemctl enable kubelet
5 集群镜像准备
kubeadm config images list --kubernetes-version=v1.21.0
k8s.gcr.io/kube-apiserver:v1.21.0
k8s.gcr.io/kube-controller-manager:v1.21.0
k8s.gcr.io/kube-scheduler:v1.21.0
k8s.gcr.io/kube-proxy:v1.21.0
k8s.gcr.io/pause:3.4.1
k8s.gcr.io/etcd:3.4.13-0
k8s.gcr.io/coredns/coredns:v1.8.0
创建下载脚本
# cat image_download.sh
#!/bin/bash
images_list='
k8s.gcr.io/kube-apiserver:v1.21.0
k8s.gcr.io/kube-controller-manager:v1.21.0
k8s.gcr.io/kube-scheduler:v1.21.0
k8s.gcr.io/kube-proxy:v1.21.0
k8s.gcr.io/pause:3.4.1
k8s.gcr.io/etcd:3.4.13-0
k8s.gcr.io/coredns/coredns:v1.8.0'
for i in $images_list
do
docker pull $i
done
docker save -o k8s-1-21-0.tar $images_list
由于国内网络下载失败,折腾了2天,各种重装vm,从别的地方down镜像,最终,这里过去了,安装calico没过去,然后我选了使用LetsVPN,下面是我的推广码
这是一个永远都能连上的梯子,上线三年来一直稳定没有被封过!
下载链接(推荐使用浏览器访问):https://bitbucket.org/letsgogo/letsgogo/src/master/
备用链接(推荐使用浏览器访问):https://github.com/LetsGo666/LetsGo_2
安装后打开填写我的ID:197983791 你能多得3天会员!
也可以修改为:
#!/bin/bash
images_list='
docker pull v5cn/kube-apiserver:v1.21.0
docker pull v5cn/kube-controller-manager:v1.21.0
docker pull v5cn/kube-scheduler:v1.21.0
docker pull v5cn/kube-proxy:v1.21.0
docker pull v5cn/pause:3.4.1
docker pull v5cn/etcd:3.4.13-0
docker pull v5cn/coredns:v1.8.0'
for i in $images_list
do
docker pull $i
done
docker tag v5cn/kube-apiserver:v1.21.0 k8s.gcr.io/kube-apiserver:v1.21.0
docker tag v5cn/kube-controller-manager:v1.21.0 k8s.gcr.io/kube-controller-manager:v1.21.0
docker tag v5cn/kube-scheduler:v1.21.0 k8s.gcr.io/kube-scheduler:v1.21.0
docker tag v5cn/kube-proxy:v1.21.0 k8s.gcr.io/kube-proxy:v1.21.0
docker tag v5cn/pause:3.4.1 k8s.gcr.io/pause:3.4.1
docker tag v5cn/etcd:3.4.13-0 k8s.gcr.io/etcd:3.4.13-0
docker tag v5cn/coredns:v1.8.0 k8s.gcr.io/coredns/coredns:v1.8.0
docker rmi v5cn/kube-apiserver:v1.21.0
docker rmi v5cn/kube-controller-manager:v1.21.0
docker rmi v5cn/kube-scheduler:v1.21.0
docker rmi v5cn/kube-proxy:v1.21.0
docker rmi v5cn/pause:3.4.1
docker rmi v5cn/etcd:3.4.13-0
docker rmi v5cn/coredns:v1.8.0
6.集群初始化
#主节点初始化
kubeadm init --kubernetes-version=v1.21.0 \ #指定安装k8adm版本
--apiserver-advertise-address=192.168.182.134 \ #指定主节点的ip地址
--pod-network-cidr=10.244.0.0/16 #pod网络的地址段
提示:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.182.134:6443 --token nngtph.7cznqp33ja6lxekp \
--discovery-token-ca-cert-hash sha256:87d70eb2dc2c91f8967e95c9862b2f30d97d36aa1cc210261652668c16cb1b12
7 集群应用客户端管理集群文件准备
根据上方提示新建
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
export KUBECONFIG=/etc/kubernetes/admin.conf
ls /root/.kube/
8 集群网络准备
查看现在节点
kubectl get nodes
查看所有pods
kubectl get pods -n kube-system
我们发现 master01和coredns相关的都没起来,原因时我我们能现在没有网络
使用calico部署集群网络
安装参考网址:https://projectcalico.docs.tigera.io/about/about-calico
选择kubernetes
选择quickstart
确保设备满足:
接下来按照教程走就行
我的使用步骤:文章来源:https://www.toymoban.com/news/detail-460414.html
1.安装 Tigera Calico 运算符和自定义资源定义。
kubectl create -f https://projectcalico.docs.tigera.io/manifests/tigera-operator.yaml
会提示:Warning: policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
不需要理会
2.通过创建必要的自定义资源来安装 Calico
cd /usr/local
mkdir calicodir
cd calicodir
wget https://projectcalico.docs.tigera.io/manifests/custom-resources.yaml
报错:要以不安全的方式连接至 projectcalico.docs.tigera.io,使用“--no-check-certificate”。
使用:
wget https://projectcalico.docs.tigera.io/manifests/custom-resources.yaml --no-check-certificate
vi custom-resources.yaml
修改文件第13行,修改为使用kubeadm init ----pod-network-cidr对应的IP地址段
修改其中 cidr为init时使用的pod-network-cidr 即:10.244.0.0/16 #pod网络的地址段
应用资源清单文件
kubectl apply -f custom-resources.yaml
kubectl get ns
显示已将创建了一个calico-system的命名空间
NAME STATUS AGE
calico-system Active 32s
default Active 74m
kube-node-lease Active 74m
kube-public Active 74m
kube-system Active 74m
tigera-operator Active 10m
# kubectl get pods -n calico-system
查看其中的pods 显示其中的pods正在创建中、初始化中。。。
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-7f87b64bd9-bdscp 0/1 Pending 0 97s
calico-node-dj8rh 0/1 Init:0/2 0 97s
calico-typha-678cc757b7-jn8g7 0/1 ContainerCreating 0 97s
3.使用以下命令确认所有 pod 都在运行。
等到每个 pod 都有STATUSof Running。
watch kubectl get pods -n calico-system
用上vpn之后贼快已经全部准备就绪
kubectl get pods -n calico-system
4。删除 master 上的 taint(污点)
kubectl taint nodes --all node-role.kubernetes.io/master-
kubectl get pods -n calico-system
5.使用以下命令确认您现在在集群中有一个节点。
kubectl get nodes -o wide
下载calico客户端
点击
下载二进制文件
curl -L https://github.com/projectcalico/calico/releases/download/v3.23.2/calicoctl-linux-amd64 -o calicoctl
安装calicoctl
mv calicoctl /usr/bin/
为calicoctl添加可执行权限
chmod +x /usr/bin/calicoctl
查看添加权限后文件
ls /usr/bin/calicoctl
显示
/usr/bin/calicoctl
查看calicoctl版本
calicoctl version
显示
Client Version: v3.21.4
Git commit: 220d04c94
Cluster Version: v3.21.4
Cluster Type: typha,kdd,k8s,operator,bgp,kubeadm
通过~/.kube/config连接kubernetes集群,查看已运行节点
DATASTORE_TYPE=kubernetes KUBECONFIG=~/.kube/config calicoctl get nodes
NAME
master01
9 集群工作节点添加
因容器镜像下载较慢,可能会导致报错,主要错误为没有准备好cni(集群网络插件),如有网络,请耐心等待即可。
将上边init之后生成的直接复制到工作节点执行即可
worker01、02分别执行:
kubeadm join 192.168.182.134:6443 --token nngtph.7cznqp33ja6lxekp \
--discovery-token-ca-cert-hash sha256:87d70eb2dc2c91f8967e95c9862b2f30d97d36aa1cc210261652668c16cb1b12
10 验证集群可用性
查看所有的节点
[root@master01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master01 Ready control-plane,master 169m v1.21.0
worker01 Ready <none> 28m v1.21.0
worker02 Ready <none> 28m v1.21.0
第二次搭建图:
查看集群健康情况,理想状态
[root@master01 ~]# kubectl get cs
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy {"health":"true"}
真实情况
# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused
controller-manager Unhealthy Get "http://127.0.0.1:10252/healthz": dial tcp 127.0.0.1:10252: connect: connection refused
etcd-0 Healthy {"health":"true"}
查看kubernetes集群pod运行情况
[root@master01 ~]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-558bd4d5db-4jbdv 1/1 Running 1 169m
coredns-558bd4d5db-pw5x5 1/1 Running 1 169m
etcd-master01 1/1 Running 1 170m
kube-apiserver-master01 1/1 Running 1 170m
kube-controller-manager-master01 1/1 Running 14 170m
kube-proxy-kbx4z 1/1 Running 1 169m
kube-proxy-rgtr8 1/1 Running 0 29m
kube-proxy-sq9xv 1/1 Running 0 29m
kube-scheduler-master01 1/1 Running 11 170m
第二次搭建图:
再次查看calico-system命名空间中pod运行情况。
[root@master01 ~]# kubectl get pods -n calico-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-666bb9949-dzp68 1/1 Running 3 70m
calico-node-jhcf4 1/1 Running 15 70m
calico-node-jxq9p 1/1 Running 0 30m
calico-node-kf78q 1/1 Running 0 30m
calico-typha-68b96d8d9c-7qfq7 1/1 Running 13 70m
calico-typha-68b96d8d9c-wz2zj 1/1 Running 0 20m
第二次搭建图:
至此K8s集群搭建完毕
最后附上所需所有镜像:
[root@master01 calicodir]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
quay.io/tigera/operator v1.27.7 973504463255 4 days ago 64.7MB
calico/typha v3.23.2 22336acac6bb 4 days ago 131MB
calico/kube-controllers v3.23.2 ec95788d0f72 4 days ago 135MB
calico/apiserver v3.23.2 6cba34c44d47 4 days ago 196MB
calico/cni v3.23.2 a87d3f6f1b8f 4 days ago 263MB
calico/pod2daemon-flexvol v3.23.2 b21e2d7408a7 4 days ago 18.8MB
calico/node v3.23.2 a3447b26d32c 4 days ago 221MB
k8s.gcr.io/kube-apiserver v1.21.0 4d217480042e 14 months ago 126MB
k8s.gcr.io/kube-proxy v1.21.0 38ddd85fe90e 14 months ago 122MB
k8s.gcr.io/kube-scheduler v1.21.0 62ad3129eca8 14 months ago 50.6MB
k8s.gcr.io/kube-controller-manager v1.21.0 09708983cc37 14 months ago 120MB
k8s.gcr.io/pause 3.4.1 0f8457a4c2ec 17 months ago 683kB
k8s.gcr.io/coredns/coredns v1.8.0 296a6d5035e2 20 months ago 42.5MB
k8s.gcr.io/etcd 3.4.13-0 0369cf4303ff 22 months ago 253MB
第一次写博客可能比较low,有问题可联系我,有问必答!!!文章来源地址https://www.toymoban.com/news/detail-460414.html
到了这里,关于kubernetes(k8s)安装详细教程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!