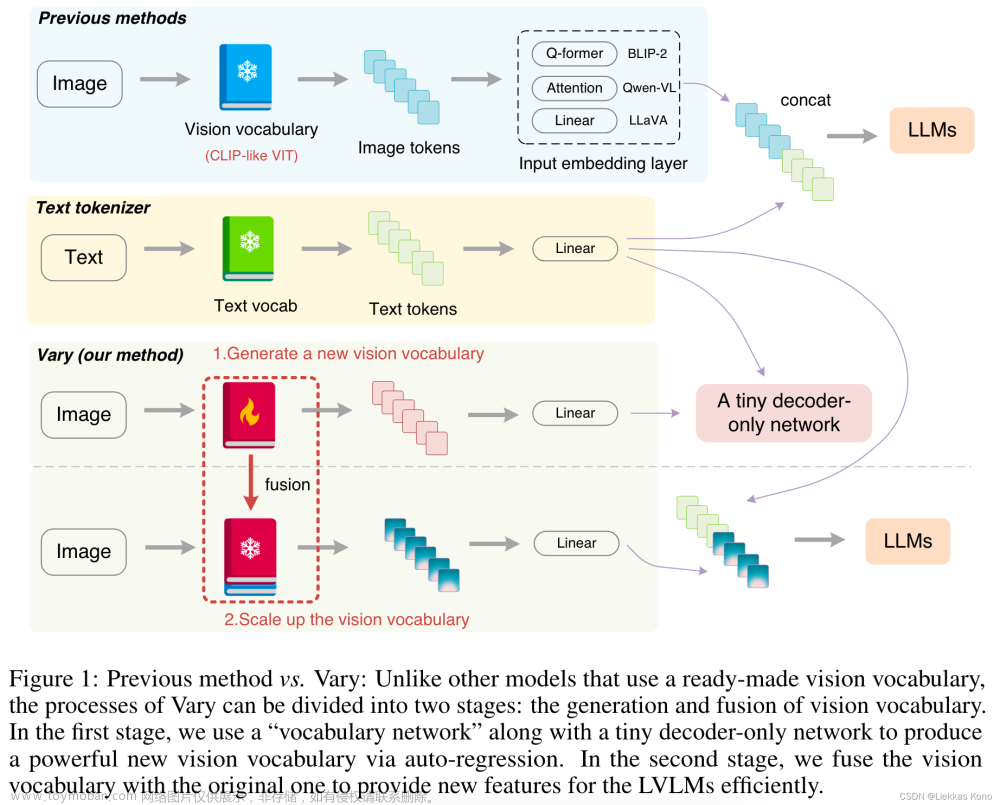
简介
主要相关阅读:文章来源:https://www.toymoban.com/news/detail-460626.html
- 油管视频 https://www.youtube.com/watch?v=whXTP08XMYA
- yuannnn的笔记 https://zhuanlan.zhihu.com/p/568878981
其它相关阅读&#文章来源地址https://www.toymoban.com/news/detail-460626.html
到了这里,关于GET3D 论文笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

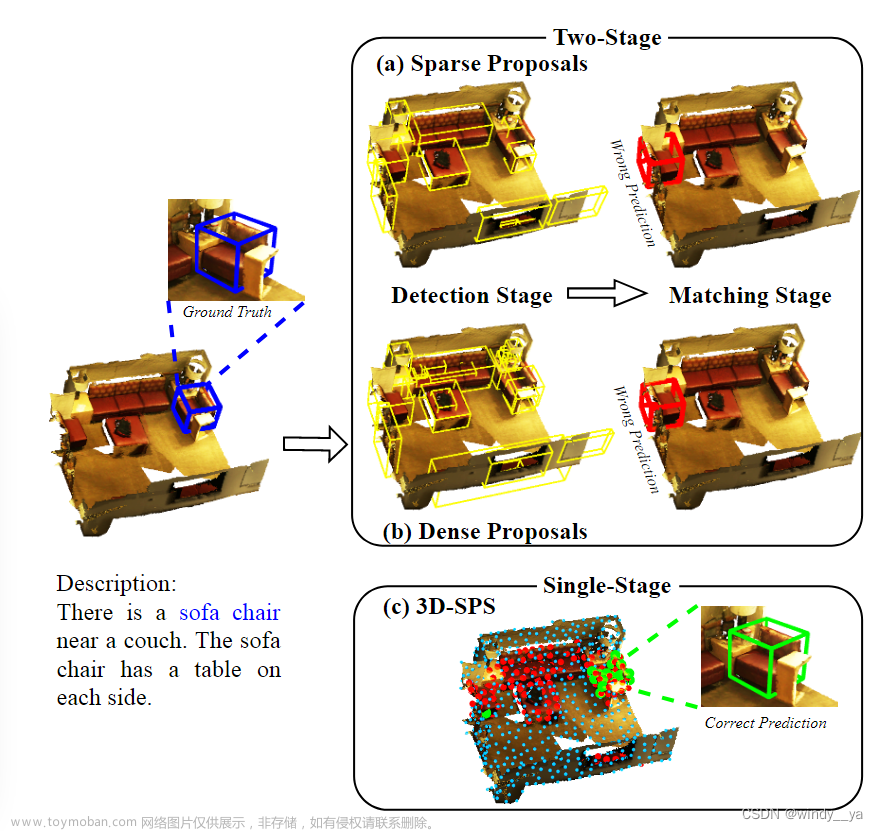

![[论文阅读]Multimodal Virtual Point 3D Detection](https://imgs.yssmx.com/Uploads/2024/02/778145-1.png)

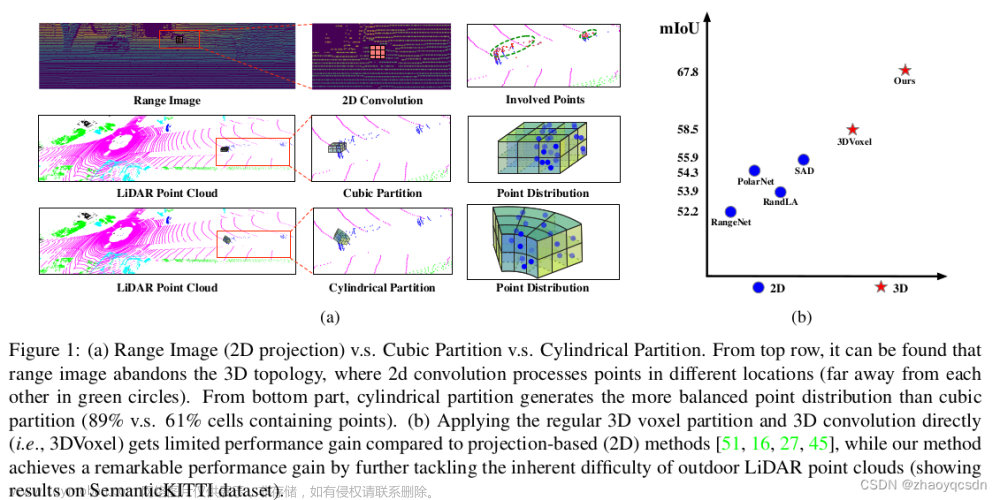
![[论文阅读]FCAF3D——全卷积无锚 3D 物体检测](https://imgs.yssmx.com/Uploads/2024/02/777827-1.png)