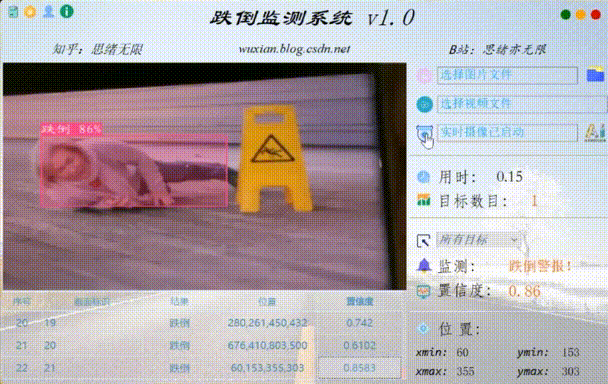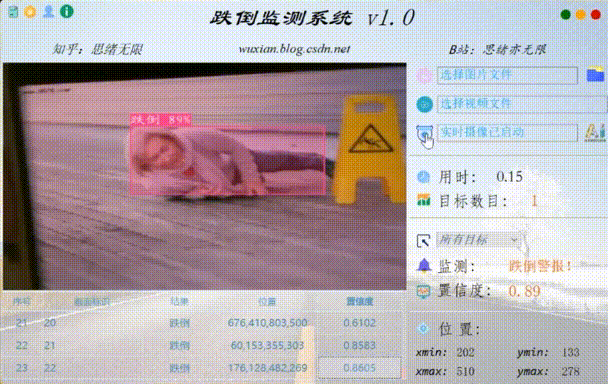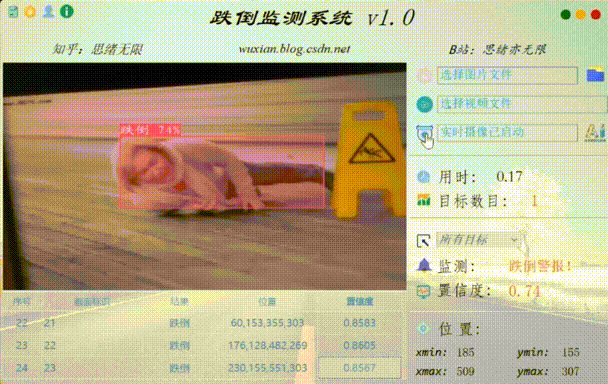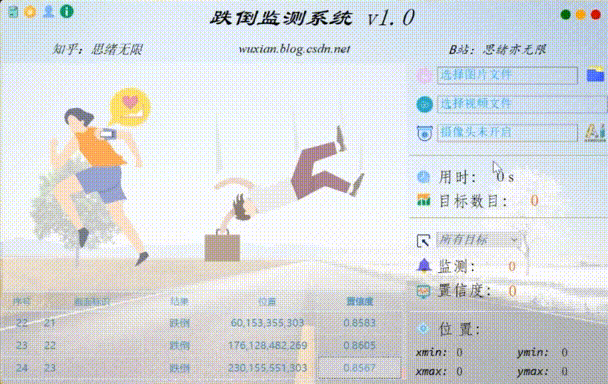
数据和源码见文末
1.任务概述
数据集使用的是东北大学收集的一个钢材缺陷检测数据集,需要检测出钢材表面的6种划痕。同时,数据集格式是VOC格式,需要进行转化,上传的源码中的数据集是经过转换格式的版本。
2.数据与标签配置方法
在数据集目录下,train文件夹下有训练集数据及YOLO标签,valid文件夹下是验证集数据及YOLO标签。data.yaml是数据的配置文件,需要在训练和测试时进行指定。
train目录

valid目录

data.yaml是数据的配置文件,里面指定了训练集和验证集数据的目录,这里是使用的相对路径,如果容易报错的话,可以改为绝对路径。nc是类别数,names是类别名称。
3.标签转换脚本
原始标注文件格式是voc格式,但是YOLO并不支持这种格式的文件。因此需要使用一个脚本对标签进行转换。
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import glob
classes = ["crazing", "inclusion", "patches", "pitted_surface", "rolled-in_scale", "scratches"]
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_name):
in_file = open('./ANNOTATIONS/'+image_name[:-3]+'xml')
out_file = open('./LABELS/'+image_name[:-3]+'txt','w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
print(cls)
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
if __name__ == '__main__':
for image_path in glob.glob("./IMAGES/*.jpg"):
image_name = image_path.split('\\')[-1]
#print(image_path)
convert_annotation(image_name)4.YOLOv5的项目参数配置
我们只选取重要的参数进行详细的说明
--weights是指定预训练权重。
--cfg指定模型,我们可以根据自己的需要,指定不同计算量的模型。

--hyp是超参数的配置文件,一般不需要进行修改
进行训练,最重要的参数还有--epochs(训练的轮次),--batch-size(批量大小),--cos-lr是否使用余弦调度。
其中,参数我们可以在Anaconda的命令行中指定,也可以在Pycharm进行配置

以下只是示例,参数需要根据自己的需要进行指定

参数的含义:
--weights:初始权重
--cfg:模型配置文件
--data:数据配置文件
--hyp:学习率等超参数文件
--epochs:迭代次数
-imgsz:图像大小
--rect:长方形训练策略,不resize成正方形,使用灰条进行图片填充,防止图片失真
--resume:恢复最近的培训,从last.pt开始
--nosave:只保存最后的检查点
--noval:仅在最后一次epochs进行验证
--noautoanchor:禁用AutoAnchor
--noplots:不保存打印文件
--evolve:为x个epochs进化超参数
--bucket:上传操作,这个参数是 yolov5 作者将一些东西放在谷歌云盘,可以进行下载
--cache:在ram或硬盘中缓存数据
--image-weights:测试过程中,图像的那些测试地方不太好,对这些不太好的地方加权重
--single-cls:单类别标签置0
--device:gpu设置
--multi-scale:改变img大小+/-50%,能够被32整除
--optimizer:学习率优化器
--sync-bn:使用SyncBatchNorm,仅在DDP模式中支持,跨gpu时使用
--workers:最大 dataloader 的线程数 (per RANK in DDP mode)
--project:保存文件的地址
--name:保存日志文件的名称
--exist-ok:对项目名字是否进行覆盖
--quad:在dataloader时采用什么样的方式读取我们的数据,1280的大图像可以指定
--cos-lr:余弦学习率调度
--label-smoothing:
--patience:经过多少个epoch损失不再下降,就停止迭代
--freeze:迁移学习,冻结训练
--save-period:每x个周期保存一个检查点(如果<1,则禁用)
--seed:随机种子
--local_rank:gpu编号
--entity:可视化访问信息
--quad:
四元数据加载器是我们认为的一个实验性功能,它可能允许在较低 --img 尺寸下进行更高 --img 尺寸训练的一些好处。
此四元整理功能会将批次从 16x3x640x640 重塑为 4x3x1280x1280,这不会产生太大影响 本身,因为它只是重新排列批次中的马赛克,
但有趣的是允许批次中的某些图像放大 2 倍(每个四边形中的 4 个马赛克中的一个放大 2 倍,其他 3 个马赛克被删除)配置好环境指定参数就可以进行训练了。文章来源:https://www.toymoban.com/news/detail-460798.html
数据和源码链接:https://pan.baidu.com/s/1EaJT5Rganfy-Ph5S1gvyQg?pwd=uu48
提取码:uu48 文章来源地址https://www.toymoban.com/news/detail-460798.html
到了这里,关于基于YOLOV5的钢材缺陷检测的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!