支持向量机(SVM)
支持向量机(Support Vector Machine),是机器学习中最流行、最强大的算法模型,没有之一。
但是其背后的模型思想、数学原理较为晦涩难懂,所以本篇文章尽量使用通俗的语言讲解支持向量机的运行原理与数学推导。
直观的本质理解
我们都知道,支持向量机(SVM)大部分的应用场景均为分类问题,即如何有效地分开两种不同的类别。
首先,我们来分析下图,其中绿色、黄色分别为不同类别的数据点,如何画一条直线能够分开这两类数据呢? 假如再添加新的数据点,该直线是否还可以正确地划分呢?

可以有以下的三种画法,都可以正确区分这两类数据点,当有新数据继续加入时,我们该选择哪种画法呢?

假如我们选择直线1区分两种类别数据,可能会出现以下这种情况:

其中新添加的点的真实类别为黄色,但是根据直线1的划分方式预测新添加点类别为绿色,这样就会造成预测错误,所以以直线1的方式切分是不合理的。
同理,采用直线3的划分方式也是不科学的。故我们选用直线2的划分方式。

这类问题也可以推广到3维空间,甚至是高维空间, 如下图3维空间中我们采用以下划分方式

这类问题的本质就是在一个n维的数据样本中,我们该如何设计一个最优化的n-1维超平面( W 1 X 1 + W 2 X 2 + . . . + W n X n + B = 0 W_{1}X_{1} + W_{2}X_{2} + ... + W_{n}X_{n} + B = 0 W1X1+W2X2+...+WnXn+B=0)去划分不同类别的数据。
之后预测样本数据时,通过符号函数 s i g n ( W 1 X 1 + W 2 X 2 + . . . + W n X n + B ) sign(W_{1}X_{1} + W_{2}X_{2} + ... + W_{n}X_{n} + B) sign(W1X1+W2X2+...+WnXn+B)对样本数据进行分类。
几个基础概念
首先来说明一些概念,这样可能更有利于逐渐理解模型的工作原理。

决策超平面
决策超平面(Decision Hyperplane),如上图,就是用来区分不同类别数据的超平面(在2维数据中即为直线)。
正超平面
满足( W 1 X 1 + W 2 X 2 + . . . + W n X n + B > = 1 W_{1}X_{1} + W_{2}X_{2} + ... + W_{n}X_{n} + B >= 1 W1X1+W2X2+...+WnXn+B>=1)所有点位于正超平面, 在该超平面内的数据点所属类别均为一个类别。
负超平面
满足( W 1 X 1 + W 2 X 2 + . . . + W n X n + B < = − 1 W_{1}X_{1} + W_{2}X_{2} + ... + W_{n}X_{n} + B <= -1 W1X1+W2X2+...+WnXn+B<=−1)所有点位于负超平面, 在该超平面内的数据点所属类别均为另一类别。
决策边界
在具有两个类的统计分类问题中,决策边界(Decision Boundary)或决策表面是超曲面,其将基础向量空间划分为两个集合,一个集合。 分类器(SVM) 将决策边界一侧的所有点分类为属于一个类,而将另一侧的所有点分类为属于另一个类。(百度百科)
支持向量
支持向量(Support Vector)是位于决策边界上的样本数据点,决定间隔距离,其距离超平面最近。
在支持向量机中,距离超平面最近的且满足一定条件的几个训练样本点被称为支持向量。
硬间隔
硬间隔(Hard Margin),即两个决策边界之间的距离,本质上求解的最优超平面就是寻找一个具备 最大硬间隔(Max Hard Margin) 的问题。
硬间隔不允许出现异常的点,即不允许出现落在决策边界与决策超平面之内的点,通常来讲这种情况是理想状态下的,与之相对的是软间隔。
软间隔

软间隔(Soft Margin),具备一定的容错率,能够允许数据样本中异常值的出现,它试图在间隔距离和错误大小之间寻找一个平衡。
可以把硬间隔想象为收入,异常数据(损失loss)想象为成本,那么软间隔就为 收入 - 成本 = 利润,它试图寻找最大利润值,即最大软间隔(Max Soft Margin)。
决策超平面的求解(SVM模型的推导)
由以上可知,SVM的核心问题就是寻找最优超平面问题,也即寻找决策边界的最大间隔问题。
求解 硬间隔(Hard Margin) 下的决策超平面(软间隔类似)后,决策超平面( W 1 X 1 + W 2 X 2 + . . . + W n X n + B = 0 W_{1}X_{1} + W_{2}X_{2} + ... + W_{n}X_{n} + B = 0 W1X1+W2X2+...+WnXn+B=0)便可以利用符号函数对样本进行预测分类。
最大硬间隔的寻找与公式构建
首先,我们先选取两个支持向量 x n , x m x_n, x_m xn,xm,分别代表两个不同的类别,如下图

因为该两点均在决策边界上,故必定满足以下方程式
{ w 1 x 1 m + w 2 x 2 m + b = 1 ( 1 ) w 1 x 1 n + w 2 x 2 n + b = − 1 ( 2 ) \begin{cases} w_{1}x_{1m} + w_{2}x_{2m} + b = 1\qquad\qquad\qquad\left (1)\right.\\ w_{1}x_{1n} + w_{2}x_{2n} + b = -1\qquad\qquad\qquad\left (2)\right. \end{cases} {w1x1m+w2x2m+b=1(1)w1x1n+w2x2n+b=−1(2)
将等式(1) - 等式(2),可得等式(3)如下
w 1 x 1 m − w 1 x 1 n + w 2 x 2 m − w 2 x 2 n = 2 w_{1}x_{1m} - w_{1}x_{1n} + w_{2}x_{2m} - w_{2}x_{2n} = 2 w1x1m−w1x1n+w2x2m−w2x2n=2
( w 1 x 1 m + w 2 x 2 m ) − ( w 1 x 1 n + w 2 x 2 n ) = 2 (w_{1}x_{1m} + w_{2}x_{2m}) -(w_{1}x_{1n} + w_{2}x_{2n}) = 2 (w1x1m+w2x2m)−(w1x1n+w2x2n)=2
转化为向量乘积形式(点积公式),即可得公式(3)
w ⃗ ⋅ x m ⃗ − w ⃗ ⋅ x n ⃗ = w ⃗ ⋅ ( x m ⃗ − x n ⃗ ) = 2 ( 3 ) \vec{ w } \cdot \vec{x_m} - \vec{w} \cdot \vec{x_n} = \vec{ w } \cdot (\vec{x_m} - \vec{x_n}) = 2\qquad\qquad\qquad(3) w⋅xm−w⋅xn=w⋅(xm−xn)=2(3)
将其可视化表示,即为

我们再次选择两个点 x p , x o x_p,x_o xp,xo,如下图

其中 x p , x o x_{p}, x_{o} xp,xo均在决策超平面上,故必满足以下等式
{ w 1 x 1 p + w 2 x 2 p + b = 0 ( 4 ) w 1 x 1 o + w 2 x 2 o + b = 0 ( 5 ) \begin{cases} w_1x_{1p} + w_2x_{2p} + b = 0\qquad\qquad\qquad(4)\\ w_1x_{1o} + w_2x_{2o} + b = 0\qquad\qquad\qquad(5) \end{cases} {w1x1p+w2x2p+b=0(4)w1x1o+w2x2o+b=0(5)
再另公式(4) - 公式(5),可得公式(6)如下
w 1 x 1 p − w 1 x 1 o + w 2 x 2 p − w 2 x 2 o = 0 w_1x_{1p} - w_1x_{1o} + w_2x_{2p} - w_2x_{2o} = 0 w1x1p−w1x1o+w2x2p−w2x2o=0
( w 1 x 1 p + w 2 x 2 p ) − ( w 1 x 1 o + w 2 x 2 o ) = 0 (w_1x_{1p} + w_2x_{2p}) - (w_1x_{1o} + w_2x_{2o}) = 0 (w1x1p+w2x2p)−(w1x1o+w2x2o)=0
转化为向量乘积形式(点积公式),即可得公式(6)
w ⃗ ⋅ x p ⃗ − w ⃗ ⋅ x o ⃗ = w ⃗ ⋅ ( x p ⃗ − x o ⃗ ) = 0 ( 6 ) \vec{ w } \cdot \vec{x_p} - \vec{w} \cdot \vec{x_o} = \vec{ w } \cdot (\vec{x_p} - \vec{x_o}) = 0\qquad\qquad\qquad(6) w⋅xp−w⋅xo=w⋅(xp−xo)=0(6)
把该公式可视化表现出来,即为

由公式(6)可知,向量 w ⃗ \vec{w} w与向量 x o ⃗ − x p ⃗ \vec{x_o} - \vec{x_p} xo−xp的内积为0,由向量的内积定理可知,内积为0,两向量垂直。
又因为向量 x o ⃗ 、 x p ⃗ \vec{x_o} 、 \vec{x_p} xo、xp在决策超平面上,故向量 w ⃗ \vec{w} w垂直于决策超平面。
我们把公式(3)和公式(6)的向量运算进行可视化,如下
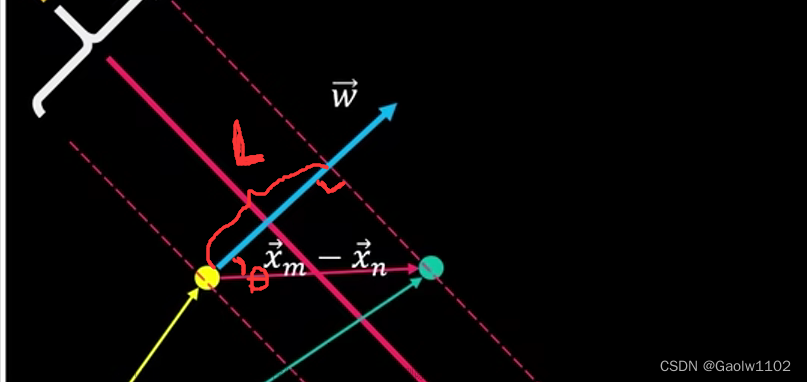
由公式(6)可知,向量 w ⃗ \vec{w} w垂直于决策超平面,故设最大间隔距离为 L, 则 L = ∣ ∣ x m ⃗ − x n ⃗ ∣ ∣ ∗ cos θ ||\vec{x_m} - \vec{x_n}|| * \cos{\theta} ∣∣xm−xn∣∣∗cosθ,则此时 L 即为最大间隔。
又因为公式(3)为 w ⃗ ⋅ ( x m ⃗ − x n ⃗ ) = 2 \vec{ w } \cdot (\vec{x_m} - \vec{x_n}) = 2 w⋅(xm−xn)=2,即为 ∣ ∣ w ⃗ ∣ ∣ ∗ cos θ ∗ ∣ ∣ x m ⃗ − x n ⃗ ∣ ∣ ||\vec{ w }|| * \cos{\theta} * ||\vec{x_m} - \vec{x_n}|| ∣∣w∣∣∗cosθ∗∣∣xm−xn∣∣ = 2,即 cos θ ∗ ∣ ∣ x m ⃗ − x n ⃗ ∣ ∣ = 2 ∣ ∣ w ⃗ ∣ ∣ \cos{\theta} * ||\vec{x_m} - \vec{x_n}|| = \frac{2}{||\vec{ w }||} cosθ∗∣∣xm−xn∣∣=∣∣w∣∣2。
综上,可以得到 最大间隔距离为
L = 2 ∣ ∣ w ⃗ ∣ ∣ L = \frac{2}{||\vec{ w }||} L=∣∣w∣∣2
不妨转化一下思路,求 max L = 2 ∣ ∣ w ⃗ ∣ ∣ \max{L = \frac{2}{||\vec{ w }||}} maxL=∣∣w∣∣2,即为求
min ∣ ∣ w ⃗ ∣ ∣ \min{||\vec{w}||} min∣∣w∣∣
再来看约束条件,又因为所有正超平面上的数据点均满足 W 1 X 1 + W 2 X 2 + . . . + W n X n + B > = 1 W_{1}X_{1} + W_{2}X_{2} + ... + W_{n}X_{n} + B >= 1 W1X1+W2X2+...+WnXn+B>=1,且对应的类别 Y i = 1 Y_i = 1 Yi=1
所有负超平面上的数据点均满足 W 1 X 1 + W 2 X 2 + . . . + W n X n + B < = − 1 W_{1}X_{1} + W_{2}X_{2} + ... + W_{n}X_{n} + B <= -1 W1X1+W2X2+...+WnXn+B<=−1,且对应的类别 Y i = − 1 Y_i = -1 Yi=−1
所以简化的约束表达式为
y i ∗ ( w ⃗ ⋅ x ⃗ + b ) > = 1 y_i * (\vec{w}\cdot\vec{x} + b) >= 1 yi∗(w⋅x+b)>=1
所以现在我们的终极目标出现了!就是求约束条件下的最小值 ∣ ∣ w ⃗ ∣ ∣ ||\vec{w}|| ∣∣w∣∣问题,即求
{ min ∣ ∣ w ⃗ ∣ ∣ y i ∗ ( w ⃗ ⋅ x ⃗ + b ) > = 1 , 其中 i = 1 , 2 , . . . , S ( S 为全部样本数 ) \begin{cases} \min{||\vec{w}||}\\ y_i * (\vec{w}\cdot\vec{x} + b) >= 1, 其中 i = 1, 2, ... , S(S为全部样本数) \end{cases} {min∣∣w∣∣yi∗(w⋅x+b)>=1,其中i=1,2,...,S(S为全部样本数)
拉格朗日乘数法的应用
我们把这个极值问题进行稍微变换下,其中 ∣ ∣ w ⃗ ∣ ∣ = w 1 2 + w 2 2 ||\vec{w}|| = \sqrt{w_1^2 + w_2^2} ∣∣w∣∣=w12+w22,可以对其先平方再除2,并不影响最小值的求解,此时问题可变化为
{ min ∣ ∣ w ⃗ ∣ ∣ 2 2 y i ∗ ( w ⃗ ⋅ x ⃗ + b ) > = 1 , 其中 i = 1 , 2 , . . . , S ( S 为全部样本数 ) \begin{cases} \min{\frac{||{\vec{w}}||^2}{2}}\\ y_i * (\vec{w}\cdot\vec{x} + b) >= 1, 其中 i = 1, 2, ... , S(S为全部样本数) \end{cases} {min2∣∣w∣∣2yi∗(w⋅x+b)>=1,其中i=1,2,...,S(S为全部样本数)
再对该条件进行进一步转化
{ min ∣ ∣ w ⃗ ∣ ∣ 2 2 y i ∗ ( w ⃗ ⋅ x ⃗ + b ) − 1 > = 0 , 其中 i = 1 , 2 , . . . , S ( S 为全部样本数 ) \begin{cases} \min{\frac{||{\vec{w}}||^2}{2}}\\ y_i * (\vec{w}\cdot\vec{x} + b)-1 >= 0, 其中 i = 1, 2, ... , S(S为全部样本数) \end{cases} {min2∣∣w∣∣2yi∗(w⋅x+b)−1>=0,其中i=1,2,...,S(S为全部样本数)
设定 p i 2 p_i^2 pi2 >= 0,将约束的不等式转化为等式约束条件,从而使用拉格朗日乘子法求解极值。
此时在约束条件下的极值问题转化为
{ min ∣ ∣ w ⃗ ∣ ∣ 2 2 y i ∗ ( w ⃗ ⋅ x ⃗ + b ) − 1 = p i 2 , 其中 i = 1 , 2 , . . . , S ( S 为全部样本数 ) \begin{cases} \min{\frac{||{\vec{w}}||^2}{2}}\\ y_i * (\vec{w}\cdot\vec{x} + b)-1 = p_i^2, 其中 i = 1, 2, ... , S(S为全部样本数) \end{cases} {min2∣∣w∣∣2yi∗(w⋅x+b)−1=pi2,其中i=1,2,...,S(S为全部样本数)
此时就可以应用拉格朗日乘数法了,先构建拉格朗日乘数法公式如下:
L ( w , b , λ i , p i 2 ) = ∣ ∣ w ⃗ ∣ ∣ 2 2 − ∑ i = 1 s λ i ∗ ( y i ∗ ( w ⃗ ⋅ x ⃗ + b ) − 1 − p i 2 ) L(w,b,\lambda_i, p_i^2) = \frac{||{\vec{w}}||^2}{2} - \sum\limits_{i = 1}^s{\lambda_i} * (y_i * (\vec{w}\cdot\vec{x} + b) -1 - p_i^2) L(w,b,λi,pi2)=2∣∣w∣∣2−i=1∑sλi∗(yi∗(w⋅x+b)−1−pi2)
为了求拉格朗日方程式的极值,我们对 w、b、 λ i 、 p i \lambda_i、p_i λi、pi求偏导并令其为0,可得
( 1 ) δ L δ w = w ⃗ − ∑ i = 1 s λ i ∗ y i ⋅ x ⃗ = 0 \quad(1)\qquad\frac{\delta{L}}{\delta{w}} = \vec{w} - \sum\limits_{i=1}^s{\lambda_i} * y_i \cdot \vec{x} = 0 (1)δwδL=w−i=1∑sλi∗yi⋅x=0
( 2 ) δ L δ b = − ∑ i = 1 s λ i ∗ y i = 0 \quad(2)\qquad\frac{\delta{L}}{\delta{b}} = -\sum\limits_{i=1}^s{\lambda_i} * y_i = 0 (2)δbδL=−i=1∑sλi∗yi=0
( 3 ) δ L δ λ i = − ( y i ∗ ( w ⃗ ⋅ x ⃗ + b ) − 1 − p i 2 ) = ( y i ∗ ( w ⃗ ⋅ x ⃗ + b ) − 1 − p i 2 ) = 0 \quad(3)\qquad\frac{\delta{L}}{\delta{\lambda_i}} = -(y_i * (\vec{w}\cdot\vec{x} + b) - 1 - p_i^2) = (y_i * (\vec{w}\cdot\vec{x} + b) - 1 - p_i^2) =0 (3)δλiδL=−(yi∗(w⋅x+b)−1−pi2)=(yi∗(w⋅x+b)−1−pi2)=0
( 4 ) δ L δ p i = − 2 p i λ i = 0 \quad(4)\qquad\frac{\delta{L}}{\delta{p_i}} = -2p_i\lambda_i = 0 (4)δpiδL=−2piλi=0
公式(4)也可以转化为 λ i p i 2 = 0 \lambda_ip_i^2 = 0 λipi2=0,
将公式(3)代入到公式(4)后可得, λ i ∗ ( y i ∗ ( w ⃗ ⋅ x ⃗ + b ) − 1 ) = 0 \lambda_i * (y_i * (\vec{w}\cdot\vec{x} + b) - 1) = 0 λi∗(yi∗(w⋅x+b)−1)=0
由于 y i ∗ ( w ⃗ ⋅ x ⃗ + b ) − 1 > = 0 y_i * (\vec{w}\cdot\vec{x} + b) - 1 >= 0 yi∗(w⋅x+b)−1>=0,我们便有了以下的猜想:
- 当 λ i = 0 \lambda_i = 0 λi=0时, y i ∗ ( w ⃗ ⋅ x ⃗ + b ) − 1 > = 0 y_i * (\vec{w}\cdot\vec{x} + b)-1 >= 0 yi∗(w⋅x+b)−1>=0明显成立。
- 当 λ i ≠ 0 \lambda_i \neq 0 λi=0时, y i ∗ ( w ⃗ ⋅ x ⃗ + b ) − 1 = 0 y_i * (\vec{w}\cdot\vec{x} + b)-1 = 0 yi∗(w⋅x+b)−1=0明显成立。
- 当
λ
i
<
0
\lambda_i < 0
λi<0时,且
y
i
∗
(
w
⃗
⋅
x
⃗
+
b
)
−
1
<
0
y_i * (\vec{w}\cdot\vec{x} + b)-1 < 0
yi∗(w⋅x+b)−1<0不满足约束条件时,则
∑
i
=
1
s
λ
i
∗
(
y
i
∗
(
w
⃗
⋅
x
⃗
+
b
)
−
1
−
p
i
2
)
>
0
\sum\limits_{i = 1}^s{\lambda_i} * (y_i * (\vec{w}\cdot\vec{x} + b) -1 - p_i^2) > 0
i=1∑sλi∗(yi∗(w⋅x+b)−1−pi2)>0,
L ( w , b , λ i , p i 2 ) = ∣ ∣ w ⃗ ∣ ∣ 2 2 − ∑ i = 1 s λ i ∗ ( y i ∗ ( w ⃗ ⋅ x ⃗ + b ) − 1 − p i 2 ) L(w,b,\lambda_i, p_i^2) = \frac{||{\vec{w}}||^2}{2} - \sum\limits_{i = 1}^s{\lambda_i} * (y_i * (\vec{w}\cdot\vec{x} + b) -1 - p_i^2) L(w,b,λi,pi2)=2∣∣w∣∣2−i=1∑sλi∗(yi∗(w⋅x+b)−1−pi2)会变得更小,这等同于变相鼓励违反约束去获得更小值,这显然是不符合常理的
所以只能 λ i > = 0 \lambda_i >= 0 λi>=0成立,那么最后我们已经得到了5个条件,也就是KKT条件(不懂可以戳这里),如下
( 1 ) w ⃗ − ∑ i = 1 s λ i y i ⋅ x ⃗ = 0 \quad(1)\qquad\vec{w} - \sum\limits_{i=1}^s{\lambda_i} y_i \cdot \vec{x} = 0 (1)w−i=1∑sλiyi⋅x=0
( 2 ) − ∑ i = 1 s λ i y i = 0 \quad(2)\qquad-\sum\limits_{i=1}^s{\lambda_i} y_i = 0 (2)−i=1∑sλiyi=0
( 3 ) y i ∗ ( w ⃗ ⋅ x ⃗ + b ) − 1 > = 0 \quad(3)\qquad y_i * (\vec{w}\cdot\vec{x} + b) - 1 >= 0 (3)yi∗(w⋅x+b)−1>=0
( 4 ) λ i ( y i ∗ ( w ⃗ ⋅ x ⃗ + b ) − 1 ) = 0 \quad(4)\qquad \lambda_i (y_i * (\vec{w}\cdot\vec{x} + b) - 1 )= 0 (4)λi(yi∗(w⋅x+b)−1)=0
( 5 ) λ i > = 0 \quad(5)\qquad \lambda_i >= 0 (5)λi>=0
基于KKT条件,我们就可以求解最终的决策超平面了,不过在SVM模型中,为了更方便地使用核技巧 Kernel Trick,我们通常使用原问题的对偶问题来进行求解。
因为该极值问题满足 KKT条件,故属于强对偶问题(充要条件),可直接使用对偶问题解决。
使用对偶问题求解
我们再次回到最初构建的极值问题表达式中
{ min ∣ ∣ w ⃗ ∣ ∣ 2 2 y i ∗ ( w ⃗ ⋅ x ⃗ + b ) − 1 > = 0 , 其中 i = 1 , 2 , . . . , S ( S 为全部样本数 ) \begin{cases} \min{\frac{||{\vec{w}}||^2}{2}}\\ y_i * (\vec{w}\cdot\vec{x} + b)-1 >= 0, 其中 i = 1, 2, ... , S(S为全部样本数) \end{cases} {min2∣∣w∣∣2yi∗(w⋅x+b)−1>=0,其中i=1,2,...,S(S为全部样本数)
它的对偶问题为(这里现在我也不是很清楚呜呜呜,需要的数学功底太深厚了呜呜呜,慢慢搞懂了会补上来,有兴趣的小伙伴可自行百度)
m a x ( q ( λ i ) ) = m a x ( m i n ( ∣ ∣ w ⃗ ∣ ∣ 2 2 − ∑ i = 1 s λ i ∗ ( y i ∗ ( w ⃗ ⋅ x i ⃗ + b ) − 1 ) ) ) , λ i > = 0 , i = 1 , 2 , . . . , s max(q(\lambda_i)) = max(min(\frac{||{\vec{w}}||^2}{2} - \sum\limits_{i = 1}^s{\lambda_i} * (y_i * (\vec{w}\cdot\vec{x_i} + b) -1))), \lambda_i>= 0, \qquad i=1,2,...,s max(q(λi))=max(min(2∣∣w∣∣2−i=1∑sλi∗(yi∗(w⋅xi+b)−1))),λi>=0,i=1,2,...,s
代入我们已经求得的 KKT 条件,进行简化(此处用到了公式(1、2))
m a x ( q ( λ i ) ) = m a x ( m i n ( ∣ ∣ w ⃗ ∣ ∣ 2 2 − ∑ i = 1 s λ i ∗ ( y i ∗ ( w ⃗ ⋅ x i ⃗ + b ) − 1 ) ) ) max(q(\lambda_i)) = max(min(\frac{||{\vec{w}}||^2}{2} - \sum\limits_{i = 1}^s{\lambda_i} * (y_i * (\vec{w}\cdot\vec{x_i} + b) -1))) max(q(λi))=max(min(2∣∣w∣∣2−i=1∑sλi∗(yi∗(w⋅xi+b)−1)))
= m a x ( m i n ( ∑ i = 1 s λ i y i ⋅ x i ⃗ ∗ ∑ j = 1 s λ j y j ⋅ x j ⃗ 2 − ∑ i = 1 s λ i ∗ y i ∗ ( w ⃗ ⋅ x i ⃗ ) + ∑ i = 1 s λ i ) ) = max(min(\frac{\sum\limits_{i=1}^s{\lambda_i} y_i \cdot \vec{x_i} * \sum\limits_{j=1}^s{\lambda_j} y_j \cdot \vec{x_j}}{2} - \sum\limits_{i = 1}^s{\lambda_i} * y_i * (\vec{w}\cdot\vec{x_i}) + \sum\limits_{i = 1}^s{\lambda_i})) =max(min(2i=1∑sλiyi⋅xi∗j=1∑sλjyj⋅xj−i=1∑sλi∗yi∗(w⋅xi)+i=1∑sλi))
= m a x ( ∑ i = 1 s λ i y i ⋅ x i ⃗ ∗ ∑ j = 1 s λ j y j ⋅ x j ⃗ 2 − ∑ i = 1 s λ i ∗ y i ∗ ( ∑ j = 1 s λ j y j ⋅ x j ⃗ ⋅ x i ⃗ ) + ∑ i = 1 s λ i ) = max(\frac{\sum\limits_{i=1}^s{\lambda_i} y_i \cdot \vec{x_i} * \sum\limits_{j=1}^s{\lambda_j} y_j \cdot \vec{x_j}}{2} - \sum\limits_{i = 1}^s{\lambda_i} * y_i * (\sum\limits_{j=1}^s{\lambda_j} y_j \cdot \vec{x_j}\cdot\vec{x_i}) + \sum\limits_{i = 1}^s{\lambda_i}) =max(2i=1∑sλiyi⋅xi∗j=1∑sλjyj⋅xj−i=1∑sλi∗yi∗(j=1∑sλjyj⋅xj⋅xi)+i=1∑sλi)
= m a x ( − ∑ i = 1 s λ i y i ⋅ x i ⃗ ∗ ∑ j = 1 s λ j y j ⋅ x j ⃗ 2 + ∑ i = 1 s λ i ) = max(-\frac{\sum\limits_{i=1}^s{\lambda_i} y_i \cdot \vec{x_i} * \sum\limits_{j=1}^s{\lambda_j} y_j \cdot \vec{x_j}}{2} + \sum\limits_{i = 1}^s{\lambda_i}) =max(−2i=1∑sλiyi⋅xi∗j=1∑sλjyj⋅xj+i=1∑sλi)
= m a x ( − ∑ i = 1 s ∑ j = 1 s λ i λ j y i y j ∗ x i ⃗ ⋅ x j ⃗ 2 + ∑ i = 1 s λ i ) = max(-\frac{\sum\limits_{i=1}^s\sum\limits_{j=1}^s{\lambda_i}{\lambda_j} y_i y_j * \vec{x_i} \cdot \vec{x_j}}{2} + \sum\limits_{i = 1}^s{\lambda_i}) =max(−2i=1∑sj=1∑sλiλjyiyj∗xi⋅xj+i=1∑sλi)
以上之所以能够去除 min 最小值符号,是因为已经将拉格朗日乘数法求出的极小值时的参数结果代入,该值即为最小值。
最后我们又得到了一个极大值问题,其中它也具备以下约束条件
∑ i = 1 s λ i y i = 0 , K K T 公式 ( 2 ) \sum\limits_{i=1}^s \lambda_i y_i = 0, \qquad KKT公式(2) i=1∑sλiyi=0,KKT公式(2)
λ i > = 0 , K K T 公式 ( 5 ) \lambda_i >= 0, \qquad KKT公式(5) λi>=0,KKT公式(5)
为了符合常理,我们把最终的 λ \lambda λ 最大值问题转化为最小值问题,即
m a x ( q ( λ ) ) = m a x ( − ∑ i = 1 s ∑ j = 1 s λ i λ j y i y j ∗ x i ⃗ ⋅ x j ⃗ 2 + ∑ i = 1 s λ i ) = m i n ( ∑ i = 1 s ∑ j = 1 s λ i λ j y i y j ∗ x i ⃗ ⋅ x j ⃗ 2 − ∑ i = 1 s λ i ) max(q(\lambda)) = max(-\frac{\sum\limits_{i=1}^s\sum\limits_{j=1}^s{\lambda_i}{\lambda_j} y_i y_j * \vec{x_i} \cdot \vec{x_j}}{2} + \sum\limits_{i = 1}^s{\lambda_i}) = min(\frac{\sum\limits_{i=1}^s\sum\limits_{j=1}^s{\lambda_i}{\lambda_j} y_i y_j * \vec{x_i} \cdot \vec{x_j}}{2} - \sum\limits_{i = 1}^s{\lambda_i}) max(q(λ))=max(−2i=1∑sj=1∑sλiλjyiyj∗xi⋅xj+i=1∑sλi)=min(2i=1∑sj=1∑sλiλjyiyj∗xi⋅xj−i=1∑sλi)
即我们终于得到最终的约束条件极值问题:
{ q ( λ i ) = m i n ( ∑ i = 1 s ∑ j = 1 s λ i λ j y i y j ∗ x i ⃗ ⋅ x j ⃗ 2 − ∑ i = 1 s λ i ) , ∑ i = 1 s λ i y i = 0 , λ i > = 0 , i = 1 , 2 , . . . , s \begin{cases} q(\lambda_i) = min(\frac{\sum\limits_{i=1}^s\sum\limits_{j=1}^s{\lambda_i}{\lambda_j} y_i y_j * \vec{x_i} \cdot \vec{x_j}}{2} - \sum\limits_{i = 1}^s{\lambda_i}),\\ \sum\limits_{i=1}^s \lambda_i y_i = 0,\\ \lambda_i >= 0, \qquad i=1,2,...,s \end{cases} ⎩ ⎨ ⎧q(λi)=min(2i=1∑sj=1∑sλiλjyiyj∗xi⋅xj−i=1∑sλi),i=1∑sλiyi=0,λi>=0,i=1,2,...,s
使用拉格朗日乘数法解出 λ i \lambda_i λi,再根据 KKT(公式1) 解出 w ⃗ \vec{w} w,再根据决策超平面 y i ∗ ( w ⃗ ⋅ x i ⃗ + b ) − 1 = 0 y_i*(\vec{w}\cdot\vec{x_i} + b) - 1 = 0 yi∗(w⋅xi+b)−1=0求出b,如下
w ⃗ = ∑ i = 1 s λ i y i ⋅ x i ⃗ \vec{w} = \sum\limits_{i=1}^s{\lambda_i}{y_i}\cdot\vec{x_i} w=i=1∑sλiyi⋅xi
b = 1 y i − w ⃗ ⋅ x i ⃗ b = \frac{1}{y_i} - \vec{w}\cdot\vec{x_i} b=yi1−w⋅xi
即可构建决策超平面
w ⃗ ⋅ x ⃗ + b = 0 \vec{w} \cdot \vec{x} + b = 0 w⋅x+b=0
并获得分类决策函数
f ( x i ) = s i g n ( w ⃗ ⋅ x ⃗ + b ) f(x_i) = sign(\vec{w} \cdot \vec{x} + b) f(xi)=sign(w⋅x+b)
一个小例子(求解决策超平面与决策函数)
前面推导了这么多公式原理,可能有些小伙伴依然没有能够理解,包括我自己也是晕晕乎乎的,还需再三再四地看可能才能记住。
现在我们以一个小栗子作为结尾,希望能对大家有所帮助。
现在有3个数据点分别为 X 1 ( 1 , 1 ) , X 2 ( 3 , 2 ) , X 3 ( 2 , 4 ) X_1(1, 1), X_2(3,2), X_3(2,4) X1(1,1),X2(3,2),X3(2,4) ,他们的实际分类为 y 1 = 1 , y 2 = 1 , y 3 = − 1 y_1 = 1,y_2 = 1,y_3 = -1 y1=1,y2=1,y3=−1,请你使用 支持向量机算法(SVM) 求出决策超平面 w ⃗ ⋅ x ⃗ + b = 0 \vec{w} \cdot \vec{x} + b = 0 w⋅x+b=0 (此处为直线),并预测数据点 X ( 2 , 1 ) X(2, 1) X(2,1)的值。
答:
我们先将所有数据样本 X 1 , X 2 , X 3 , y 1 , y 2 , y 3 X_1, X_2, X_3, y_1, y_2, y_3 X1,X2,X3,y1,y2,y3代入最终的支持向量机极值公式 q ( λ i ) = m i n ( ∑ i = 1 s ∑ j = 1 s λ i λ j y i y j ∗ x i ⃗ ⋅ x j ⃗ 2 − ∑ i = 1 s λ i ) q(\lambda_i) = min(\frac{\sum\limits_{i=1}^s\sum\limits_{j=1}^s{\lambda_i}{\lambda_j} y_i y_j * \vec{x_i} \cdot \vec{x_j}}{2} - \sum\limits_{i = 1}^s{\lambda_i}) q(λi)=min(2i=1∑sj=1∑sλiλjyiyj∗xi⋅xj−i=1∑sλi),得
q ( λ 1 , λ 2 , λ 3 ) = 1 2 ( λ 1 2 ∗ 1 ∗ 2 + λ 1 λ 2 ∗ 1 ∗ 5 + λ 1 λ 3 ∗ ( − 1 ) ∗ 6 + λ 2 λ 1 ∗ 1 ∗ 5 + λ 2 2 ∗ 1 ∗ 13 + λ 2 λ 3 ∗ ( − 1 ) ∗ 14 + λ 3 λ 1 ∗ ( − 1 ) ∗ 6 + λ 3 λ 2 ∗ ( − 1 ) ∗ 14 + λ 3 2 ∗ 1 ∗ 20 ) − ( λ 1 + λ 2 + λ 3 ) \begin {aligned} q(\lambda_1,\lambda_2,\lambda_3) = \frac{1}{2}(\lambda_1^2*1*2 + \lambda_1 \lambda_2*1*5 + \lambda_1 \lambda_3*(-1)*6 + \lambda_2 \lambda_1*1*5 + \lambda_2^2*1*13 + \lambda_2 \lambda_3*(-1)*14 \\ + \lambda_3 \lambda_1*(-1)*6 + \lambda_3 \lambda_2*(-1)*14 + \lambda_3^2*1*20) - (\lambda_1 + \lambda_2 + \lambda_3) \end {aligned} q(λ1,λ2,λ3)=21(λ12∗1∗2+λ1λ2∗1∗5+λ1λ3∗(−1)∗6+λ2λ1∗1∗5+λ22∗1∗13+λ2λ3∗(−1)∗14+λ3λ1∗(−1)∗6+λ3λ2∗(−1)∗14+λ32∗1∗20)−(λ1+λ2+λ3)
稍作化简,可得
q ( λ 1 , λ 2 , λ 3 ) = 1 2 ( 2 λ 1 2 + 13 λ 2 2 + 20 λ 3 2 + 10 λ 1 λ 2 − 12 λ 1 λ 3 − 28 λ 2 λ 3 ) − ( λ 1 + λ 2 + λ 3 ) \begin {aligned} q(\lambda_1,\lambda_2,\lambda_3) = \frac{1}{2}(2\lambda_1^2 + 13\lambda_2^2 + 20\lambda_3^2 + 10\lambda_1 \lambda_2 - 12\lambda_1 \lambda_3 - 28 \lambda_2 \lambda_3) - (\lambda_1 + \lambda_2 +\lambda_3) \end {aligned} q(λ1,λ2,λ3)=21(2λ12+13λ22+20λ32+10λ1λ2−12λ1λ3−28λ2λ3)−(λ1+λ2+λ3)
又因为有约束条件 ∑ i = 1 s λ i y i = 0 \sum\limits_{i=1}^s \lambda_i y_i = 0 i=1∑sλiyi=0,可知
λ 1 + λ 2 − λ 3 = 0 \lambda_1 + \lambda_2 - \lambda_3 = 0 λ1+λ2−λ3=0
即
λ 1 + λ 2 = λ 3 \lambda_1 + \lambda_2 = \lambda_3 λ1+λ2=λ3
将该条件代入以上式子中,可得
q ( λ 1 , λ 2 ) = 1 2 ( 2 λ 1 2 + 13 λ 2 2 + 20 ( λ 1 + λ 2 ) 2 + 10 λ 1 λ 2 − 12 λ 1 ( λ 1 + λ 2 ) − 28 λ 2 ( λ 1 + λ 2 ) ) − 2 ( λ 1 + λ 2 ) = 1 2 ( 10 λ 1 2 + 5 λ 2 2 + 10 λ 1 λ 2 ) − 2 ( λ 1 + λ 2 ) \begin {aligned} q(\lambda_1,\lambda_2) &= \frac{1}{2}(2\lambda_1^2 + 13\lambda_2^2 + 20(\lambda_1 + \lambda_2)^2 + 10\lambda_1 \lambda_2 - 12\lambda_1 (\lambda_1 + \lambda_2) - 28 \lambda_2 (\lambda_1 + \lambda_2)) - 2(\lambda_1 + \lambda_2)\\ &= \frac{1}{2}(10\lambda_1^2 + 5\lambda_2^2 + 10\lambda_1 \lambda_2) - 2(\lambda_1 + \lambda_2) \end {aligned} q(λ1,λ2)=21(2λ12+13λ22+20(λ1+λ2)2+10λ1λ2−12λ1(λ1+λ2)−28λ2(λ1+λ2))−2(λ1+λ2)=21(10λ12+5λ22+10λ1λ2)−2(λ1+λ2)
接下来对 λ 1 , λ 2 \lambda_1,\lambda_2 λ1,λ2分别求偏导,并令其为 0,得
{ F λ 1 1 = 10 λ 1 + 5 λ 2 − 2 = 0 F λ 2 1 = 5 λ 1 + 5 λ 2 − 2 = 0 \begin{cases} F_{\lambda_1}^1 = 10\lambda_1 + 5\lambda_2 - 2 = 0\\ F_{\lambda_2}^1 = 5\lambda_1 + 5\lambda_2 - 2 = 0 \end{cases} {Fλ11=10λ1+5λ2−2=0Fλ21=5λ1+5λ2−2=0
解得, λ 1 = 0 , λ 2 = 0.4 , λ 3 = 0.4 \lambda_1 = 0,\lambda_2 = 0.4,\lambda_3 = 0.4 λ1=0,λ2=0.4,λ3=0.4(符合条件 λ i > = 0 \lambda_i >=0 λi>=0)
接下来根据该式子 w ⃗ = ∑ i = 1 s λ i y i ⋅ x i ⃗ \vec{w} = \sum\limits_{i=1}^s{\lambda_i}{y_i}\cdot\vec{x_i} w=i=1∑sλiyi⋅xi,求解 w ⃗ \vec{w} w,即
w ⃗ = ∑ i = 1 s λ i y i ⋅ x i ⃗ = λ 1 ∗ y 1 ⋅ x 1 ⃗ + λ 2 ∗ y 2 ⋅ x 2 ⃗ + λ 3 ∗ y 3 ⋅ x 3 ⃗ = 0.4 ∗ ( 3 , 2 ) − 0.4 ∗ ( 2 , 4 ) = ( 0.4 , − 0.8 ) \begin {aligned} \vec{w} &= \sum\limits_{i=1}^s{\lambda_i}{y_i}\cdot\vec{x_i}\\ &= \lambda_1 * y_1 \cdot \vec{x_1} + \lambda_2 * y_2 \cdot \vec{x_2} + \lambda_3 * y_3 \cdot \vec{x_3}\\ &= 0.4 * (3,2) - 0.4 * (2, 4)\\ &= (0.4, -0.8) \end {aligned} w=i=1∑sλiyi⋅xi=λ1∗y1⋅x1+λ2∗y2⋅x2+λ3∗y3⋅x3=0.4∗(3,2)−0.4∗(2,4)=(0.4,−0.8)
根据 b = 1 y i − w ⃗ ⋅ x i ⃗ b = \frac{1}{y_i} - \vec{w}\cdot\vec{x_i} b=yi1−w⋅xi求解b,可得(任意选i,其值b均相同)
b = 1 y 1 − w ⃗ ⋅ x 1 ⃗ = 1 − ( 0.4 , − 0.8 ) ⋅ ( 1 , 1 ) = 1.4 \begin {aligned} b &= \frac{1}{y_1} - \vec{w} \cdot \vec{x_1}\\ &= 1 - (0.4,-0.8) \cdot (1,1)\\ &= 1.4 \end {aligned} b=y11−w⋅x1=1−(0.4,−0.8)⋅(1,1)=1.4
所以,我们得到了决策超平面为
0.4 X 1 − 0.8 X 2 + 1.4 = 0 0.4X_1 - 0.8X_2 + 1.4 = 0 0.4X1−0.8X2+1.4=0
决策函数为
f ( x ) = s i g n ( 0.4 X 1 − 0.8 X 2 + 1.4 ) f(x) = sign(0.4X_1 - 0.8X_2 + 1.4) f(x)=sign(0.4X1−0.8X2+1.4)
现在预测点 X ( 2 , 1 ) X(2,1) X(2,1), 得
f ( X ) = s i g n ( 0.4 ∗ 2 − 0.8 ∗ 1 + 1.4 ) = s i g n ( 1.4 ) = 1 f(X) = sign(0.4*2 - 0.8*1 + 1.4) = sign(1.4) = 1 f(X)=sign(0.4∗2−0.8∗1+1.4)=sign(1.4)=1
我们可以将所有数据样本和决策超平面画出,判断预测结果是否正确

如图可见,预测结果正确。
仔细观察,可以发现一个小细节,即 X 2 , X 3 X_2,X_3 X2,X3作为支持向量,其对应的 λ 2 , λ 3 \lambda_2,\lambda_3 λ2,λ3不为0, X 1 X_1 X1不是支持向量,其对应的 λ 1 \lambda_1 λ1正好等于0。
正好对应了KKT条件中的 λ i ( y i ∗ ( w ⃗ ⋅ x ⃗ + b ) − 1 ) = 0 \lambda_i (y_i * (\vec{w}\cdot\vec{x} + b) - 1 )= 0 λi(yi∗(w⋅x+b)−1)=0公式,即
- 若 X i X_i Xi 不是支持向量, y i ∗ ( w ⃗ ⋅ x ⃗ + b ) − 1 ≠ 0 , λ i = 0 。 y_i * (\vec{w}\cdot\vec{x} + b) - 1 \neq 0,\lambda_i = 0。 yi∗(w⋅x+b)−1=0,λi=0。
- 若 X i X_i Xi 是支持向量, y i ∗ ( w ⃗ ⋅ x ⃗ + b ) − 1 = 0 , λ i ≠ 0 。 y_i * (\vec{w}\cdot\vec{x} + b) - 1 = 0,\lambda_i \neq 0。 yi∗(w⋅x+b)−1=0,λi=0。
换句话说, λ i \lambda_i λi 只会对支持向量起作用,所以支持向量机的决策超平面计算和模型构建效率不算太慢。
小结
由于本人数学水平有限,上文中许多概念也是一知半解,如拉格朗日乘数法、对偶问题等,希望小伙伴们指出不足之处。文章来源:https://www.toymoban.com/news/detail-460921.html
这篇文章的核心本质是讲解如何推出支持向量机的决策超平面方程以及决策函数,从而达到最优化分类的效果,希望能给大家带来帮助。文章来源地址https://www.toymoban.com/news/detail-460921.html
到了这里,关于支持向量机(SVM)----超详细原理分析讲解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!



![[学习笔记] [机器学习] 10. 支持向量机 SVM(SVM 算法原理、SVM API介绍、SVM 损失函数、SVM 回归、手写数字识别)](https://imgs.yssmx.com/Uploads/2024/02/487779-1.png)