Linux为什么要有大页内存?为什么DPDK必须要设置大页内存?这都是由系统架构决定的。一开始为了解决一个问题,设计了对应的方案,随着事物的发展,无法满足新的需求,就在原来的基础上改进,慢慢的变成了现在的样子。
物理内存 Physical address
物理内存就是电脑的内存条,上面的每一个方块就是存储芯片,芯片中还有颗粒。访问数据的时候,会使用各种技术,尽可能从多个内存条,每个内存条的多个存储芯片获取数据,这样多通道,并发大,速度更快。
虚拟内存 Linear address (also known as virtual address)
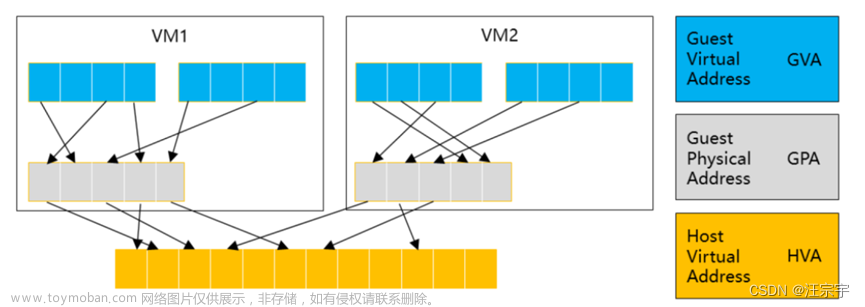
程序运行在操作系统上,不可能直接访问物理内存。一是太复杂,需要自己管理内存,哪些被其他进程占用了,哪些可以用,如果连续空间不够,如何拼接等;二是不安全,用户可以直接访问到其他进程的数据。所以操作系统在后续增加了虚拟内存的概念。
每个进程看到的都是整个可用内存,比如4G,所有进程看到的都是4G,自己进程维护一张表,当进程访问内存时,只能访问到虚拟内存表,由操作系统再映射到具体的物理内存。这样的好处除了解决了上面的问题,还有几个优点:一是系统同一管理,更合理,可以做更多优化,比如同一块数据多个进程读取,只需要在内存保存一份即可,节省了空间(类库的加载);二是程序申请内存,并不一定会使用,或者说不会立马使用,那么系统可以不分配物理内存,当程序真正访问内存时,触发中断,系统再映射到物理内存,节省资源;三是程序访问的都是连续资源,具体内存分配是由系统管理,简化了开发。
MMU Memory Management Unit 内存管理单元
用来把虚拟内存地址转化为物理内存地址的硬件,提供物理内存数据访问和权限控制。
页表 虚拟内存表
虚拟内存向物理内存映射时,需要创建数据结构保存对应的数据,如果完全一一映射,肯定会需要很多资源,所以为了减少内存空间的消耗,又提出了新的方案:把内存分为一块块的数据(每块称作为一页数据),然后映射这些块,这样就可以减少映射条目,降低内存占用。虚拟内存往往称作页;物理内存按照同样大小分割,有时候称作块或者帧(frame)
MMU存储的针对这些内存页的表,称作为页表。页表中每一条数据保存了映射的物理内存页的位置和在该页内数据的偏移,这样就能找到具体的内存单元了。
除了这种使用页表的页式管理方式,还有段式和段页式两种。
多级分页
使用页表后,数据量还是很大,比如32G的内存,使用4K作为一页,那么需要8,388,608个页表条目。为了进一步减少资源消耗,我们发现大部分程序是不需要全部内存的,一个应用运行起来,并不是必须要32G的内存,有可能只有几百兆。多级分页就做了进一步优化:
<
比如32G,每级页表按照1G分,有32条记录;1G再按照10M分,就有100条记录,以此类推。开始只创建第一张表,后续需要的时候,再动态创建其他的表,大大减少了页表的记录数。
Translation Lookaside Buffer TLB
多级分页后,数据量少了,但是增加了一个问题,就是访问效率,原来直接访问内存,只需要一次;增加了页表后,需要两次,先访问页表,再访问物理内存;多级页表,需要多次。这相当于成倍的增加了访问内存的时间。TLB就是为了解决这个问题的,把常用的页表,放到CPU的高速缓存,避免访问内存,直接在缓存中获取,提高效率。
大页内存
我们知道,计算机中每个硬件的运算速度是不一样的,其顺序就是:硬盘/网络(IO) < 内存 < 内存缓存(如果有) < CPU L3(CPU3级缓存) < CPU L2 < CPU L1 < CPU,每个之间的差距都是几倍甚至几十上百倍的,同样其空间大小也是相差数量级的,只不过正好反过来。硬盘可以做到TB甚至PB,内存常见的只有几十GB或者几百GB,而CPU的缓存,3级的可能有几十兆,而1级的往往只有字节级别的了。由于这个原因,TLB是不可能把所有的页表都映射到缓存中,那么在CPU缓存中的TLB命中率越高,性能提升越大。如果命中率很低,不仅没有提升,还额外增加了缓存的访问,反而降低了效率。
如果程序频繁的访问一块很大的内存,并且是无序的,比如频繁搜索一个100G的无规律的文本数据,这个时候就会导致CPU中的缓存频频失效,因为CPU缓存的页表条目有限,程序使用的条目超出了缓存TLB的范围,就会不断的删除旧的,加入新的,实际上如果缓存足够大,会发现刚删除的条目又被加了进来。
还有种情况,比如程序需要保存的数据都比较大,每次申请都是2M,而系统默认是4K,需要2048/4=512个条目映射,如果把内存颗粒度设为2M,那么只需要一个,大大减少了查找的次数。
如何解决呢?就是提高命中率,怎样提高命中率呢?就是TLB中保存的数据条目虽然固定,但是其解析内存可以扩展,扩展到可以包含程序访问的空间大小,这样,不管程序如何乱序访问,因为页表都保存在TLB中了,都可以命中。比如原来TLB保存100条,由于一页4K,按照最简单计算,就是400K的空间。我把一页设置为4M,那就可以表示400M的空间,如果程序访问的内存在400M以内,就可以完全命中。
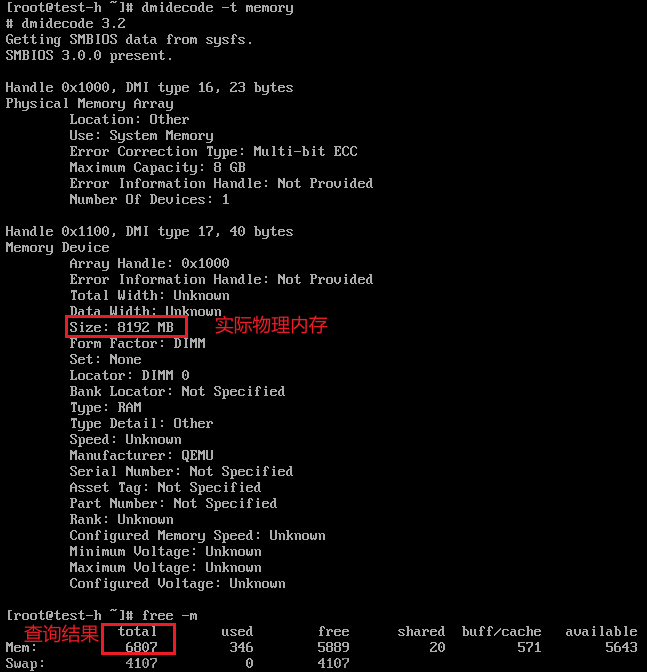
Linux大页内存有两种2MB和1GB。2MB默认支持,1GB可以通过cat /proc/cpuinfo|grep pdpe1gb查看是否支持。实际上大页内存的支持与CPU架构有关,x86_64支持的是2MB和1GB。
查看大页内存
cat /proc/meminfo|grep -i huge
AnonHugePages: 4096 kB
ShmemHugePages: 0 kB
HugePages_Total: 4
HugePages_Free: 2
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 1048576 kB
Hugetlb: 4194304 kB
HugePages_Total和Hugepagesize都大于0,就表示配置了大页内存,从字面意思也很好理解:HugePages_Total表示大页内存的个数;Hugepagesize表示一个大页内存的大小。同样Hugetlb大于0也表示配置了大页内存,这个是计算下来的总数。不过有的系统可能没有这个字段。
配置大页内存 方法一 修改grub
直接修改(不建议)
grub的文件位置在/boot目录下,大部分有如下两个地方,一个是Legacy,一个是UEFI,不同系统可能有细微区别:/boot/grub2/grub.cfg /boot/efi/EFI/openEuler/grub.cfg。打开文件,找到如下位置
menuentry 'openEuler (4.19.90-2003.4.0.0036.oe1.x86_64) 20.03 (LTS)' --class openeuler --class gnu-linux --class gnu --class os --unrestricted $menuentry_id_option 'gnulinux-4.19.90-2003.4.0.0036.oe1.x86_ 64-advanced-db3b87ac-c948-4347-b1a4-e8ca943688b6' {
load_video
set gfxpayload=keep
insmod gzio
insmod part_msdos
insmod ext2
set root='hd0,msdos1'
if [ x$feature_platform_search_hint = xy ]; then
search --no-floppy --fs-uuid --set=root --hint-bios=hd0,msdos1 --hint-efi=hd0,msdos1 --hint-baremetal=ahci0,msdos1 --hint='hd0,msdos1' 75039a04-9431-47c8-923c-795ba2b37e3e
else
search --no-floppy --fs-uuid --set=root 75039a04-9431-47c8-923c-795ba2b37e3e
fi
linux /vmlinuz-4.19.90-2003.4.0.0036.oe1.x86_64 root=/dev/mapper/openeuler-root ro resume=/dev/mapper/openeuler-swap rd.lvm.lv=openeuler/root rd.lvm.lv=openeuler/swap rhgb quiet quiet crashkernel=51 default_hugepagesz=1G hugepagesz=1G hugepages=4
initrd /initramfs-4.19.90-2003.4.0.0036.oe1.x86_64.img
}
要找对地方,这是启动系统的选项,还有一个是用作安全启动的。在倒数第二行增加default_hugepagesz=1G hugepagesz=1G hugepages=4,这三个字段分别表示默认大页内存大小,就是如果不配置,就用这个默认配置;配置的大页内存大小;配置的大页内存个数。重启系统,再次查看就可以看到大页内存信息。
注意 按照官方建议1GB的大页内存必须在grub设置,开机直接启用,不可在后续配置。
https://doc.dpdk.org/spp/setup/getting_started.html
修改/etc/default/grub
打开/boot/grub2/grub.cfg,找到GRUB_CMDLINE_LINUX,增加对应参数,执行grub2-mkconfig -o /boot/grub2/grub.cfg,重启系统。
挂载大页内存
#查看是否挂载
mount|grep hugetlbfs
hugetlbfs on /dev/hugepages type hugetlbfs (rw,relatime,pagesize=1024M)
nodev on /mnt/huge type hugetlbfs (rw,relatime,pagesize=1024M)
#挂载大页内存
mount -t hugetlbfs nodev /mnt/huge
mount -t hugetlbfs hugetlbfs /mnt/huge
#或者使用一条命令挂载
mount -t hugetlbfs nodev /mnt/huge
#也可以修改fstab,让系统启动时自动挂载
vim /etc/fstab
nodev /mnt/huge hugetlbfs pagesize=1GB 0 0
必须保证目录/mnt/huge存在,参数意义:-t指定挂载格式,hugetlbfs表示是大页内存,后面表示挂载设备,可以写hugetlbfs,也可以写nodev不挂载设备,最后是挂载目录。
NUMA
为什么需要了解NUMA呢?因为与上面的大页内存配置有关。了解NUMA,又需要先知道SMP(Symmetric Multi-Processor)对称多处理器结构。SMP就是指系统中多个CPU对称工作,每个CPU的优先级一样,访问资源(内存)速度一样,没有主次之分。SMP又叫做UMA(Uniform Memory Access)一致内存访问。
但是随着CPU的发展,内核越来越多,访问同一资源的竞争越来越大,导致CPU性能受到限制,所以推出了NUMA(Non Uniform Memory Access)非一致内存访问架构。
NUMA设计
SMP或者UMA,CPU统一经过北桥(内存控制器)访问内存。
NUMA,CPU把内存控制器做到CPU内部,一般一个CPU socket一个。每个CPU内部的内存控制器与一部分内存连接。CPU访问自己连接的内存,速度很快,叫做本地内存,可以通过QPI(Quick Path Interconnect)总线访问其他的内存,不过速度会慢。
Node Socket Core Processor
把多个core封装到一起,叫做一个CPU Socket,系统中根据Socket定义Node,也就是正常情况Node数量与Socket相同,或者一个是软件概念,一个是硬件概念。
Core就是物理CPU,原来是单CPU,性能不够,研发了多CPU架构,现在一个Core就相当于原来的一块CPU
Thread,也叫做逻辑CPU,或者Processor,是把core通过超线程记录模拟出来的处理单元。
lscpu
lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-11
Thread(s) per core: 1
Core(s) per socket: 6
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 45
Stepping: 7
CPU MHz: 1200.000
BogoMIPS: 3999.47
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 15360K
NUMA node0 CPU(s): 0-5
NUMA node1 CPU(s): 6-11
CPU(s) 表示逻辑CPU个数Thread(s) per core 表示一个core可以实现的超线程数Core(s) per socket 表示一个socket上的core数Socket(s) 表示socket的个数NUMA node(s) 表示NUMA的结点数
这里如何计算呢?首先一块中央处理器(CPU),有多个插槽socket,每个socket中又有多个core,每个core又可以使用超线程技术模拟出多个线程(这个是逻辑CPU)。所以CPU(s)=SOckets * Cores * Threads
numactl
numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7
node 0 size: 15516 MB
node 0 free: 11705 MB
node 1 cpus: 8 9 10 11 12 13 14 15
node 1 size: 16100 MB
node 1 free: 1386 MB
node distances:
node 0 1
0: 10 21
1: 21 10
CPU分为两个node,也就是有两个CPU socket。
第一个node包含0-7号cpu,第二个node包含8-15个cpu
第一个node直连的内存是15516MB,第二个node直连的内存是161000MB
第一个node直连的内存空闲是11705MB,第二个node直连的内存是1386MB
node distances表示每个node访问对应的内存的距离,比如node0访问node0的距离是10,访问node1的距离是21。
numactl还有其他作用,比如绑定程序在哪一个node上执行,指定在哪个node上分配内存等。
numastat
numastat
node0 node1
numa_hit 18743091 9973793
numa_miss 0 0
numa_foreign 0 0
interleave_hit 101249 101451
local_node 18656240 9048143
other_node 86851 925650
numa_hit 在node关联的内存上申请的内存数量numa_miss 不在node关联的内存上申请的内存数量numa_foreign 在其他node关联的内存上申请的内存数量interleave_hit 采用interleave策略申请的内存数量local_node 该node上的进程在该node关联的内存上申请的内存数量other_node 该node上的进程在其他node关联的内存上申请的内存数量
关闭开启NUMA
在上面配置大页内存的一行加上numa=off,会关闭numa,理论上删除该字段,默认是开启。
调优经验
linux分配内存的策略是优先在自己node上分配内存,如果不够再考虑其他node上的内存,这是合理的。不过如果程序绑定的node内存不够,可以考虑绑定到其他node或者给程序运行的node多分配一些内存。
查看Node上的大页内存
上面我们介绍了,现代CPU都是有很多Node的,在NUMA架构下,配置在grub.cfg中的大页内存是被多个Node平分的。
比如我机器上按照上面配置了4个1G的大页内存,查看每个Node上的信息,Node0和Node1上各两个。
$ cat /sys/devices/system/node/node0/hugepages/hugepages-1048576kB/nr_hugepages
2
$ cat /sys/devices/system/node/node1/hugepages/hugepages-1048576kB/nr_hugepages
2
大页内存配置目录介绍
在/sys/devices/system/node目录下,可以看到系统中每一个Node对应的目录。在每个Node目录下/sys/devices/system/node/node0/hugepages,有关于大页内存的配置信息,一般有两个目录hugepages-1048576kB hugepages-2048kB,这是Linux系统支持的两种大页,一个是1G,一个是2M。
在每个大页内存目录下有三个文件free_hugepages nr_hugepages surplus_hugepages,分别表示当前Node,当前大页内存中空闲的大页内存数、设定的大页内存数,超出使用的大页内存数。
方法二 临时设置大页内存
如果想临时修改某个Node的大页内存,可以直接向对应的nr_hugepages写入对应数字,比如 echo 2 > /sys/devices/system/node/node0/hugepages/hugepages-1048576kB/nr_hugepages
如果不想每个Node自己控制,可以向系统统一的大页内存文件写入数字 echo 2 > /sys/kernel/mm/hugepages/hugepages-1048576kB/nr_hugepages,这个目录与上面的目录不一样,保存的是整个系统的大页内存配置。
注意 按照官方建议1GB的大页内存必须在grub设置,开机直接启用,不可在后续配置。
https://doc.dpdk.org/spp/setup/getting_started.html
默认大页内存大小
https://access.redhat.com/documentation/zh-cn/red_hat_enterprise_linux/7/html/performance_tuning_guide/sect-red_hat_enterprise_linux-performance_tuning_guide-memory-configuring-huge-pages
上面说1GB的大页内存必须在grub中设置,开机分配,主要原因是怕后续分配没有这么大的连续空间,还有一个原因是系统默认分配的大页内存是2MB,开机之后,无法修改次默认配置(反正我试了很多方法),如果后续再分配1GB,dpdk会默认查找2MB的大页内存,发现没有会报错。
没有做任何大页内存配置时,查看cpu信息
cat /proc/meminfo|grep -i huge
AnonHugePages: 12288 kB
ShmemHugePages: 0 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
Hugetlb: 0 kB
可以看到除了大页内存大小是2MB,其他的都是0。这就说明系统默认配置了2MB的大页内存,但是没有配置数量。
通过mount也可以看到挂载的大页内存信息
mount|grep -i hugepages
hugetlbfs on /dev/hugepages type hugetlbfs (rw,relatime,pagesize=2M)
如果我们umount默认的大页内存,再通过动态分配1GB大页,再mount,都无法修改Hugepagesize,所以必须要在grub中配置,在开机时分配大页内存。
这里又有另外一个问题,开机分配大页内存,会被平均分配到每个numa node结点上。有时候网卡只在其中一个numa结点上,都分配,很明显浪费了空间,那么我们可以在配置grub的时候,把hugepages配置为0,其他配置为1GB,这样就可以默认挂载1GB大页内存,有不会额外分配空间,我们可以在系统启动后自动运行脚本按照需求在指定的numa结点上分配大页内存。文章来源:https://www.toymoban.com/news/detail-461076.html
https://www.kernel.org/doc/Documentation/vm/hugetlbpage.txt
Understanding Linux Kernel文章来源地址https://www.toymoban.com/news/detail-461076.html
到了这里,关于Linux 大页内存 Huge Pages 虚拟内存的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!