文章搬运自本人知乎
VGG16网络结构介绍

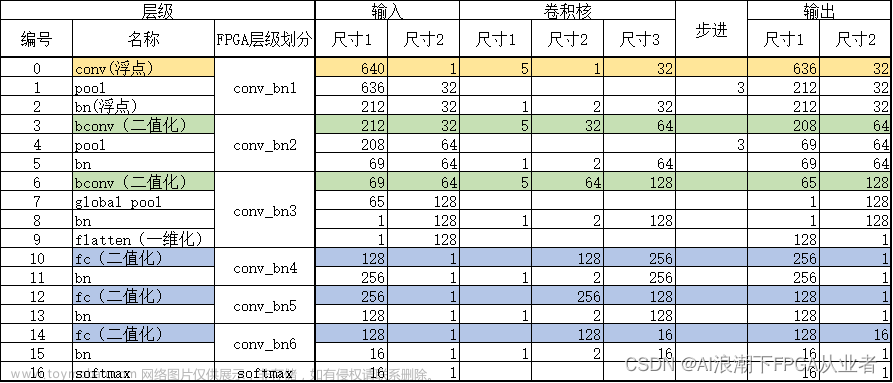
VGG在2014年由牛津大学Visual GeometryGroup提出,获得该年lmageNet竞赛中Localization Task(定位任务)第一名和 Classification Task (分类任务)第二名。与AlexNet相比,VGG使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5x5卷积核,从而在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。下表中,C即为VGG16的网络结构,其中,VGG16中的16是指该网络具有16个包含权重的网络层(卷积层和全连接层)。更具体地,VGG16由13个卷积层和3个全连接层构成,此外,VGG16还包含了5个2×2的最大池化层。
在原始的VGG16模型中,并未包含批归一化层(Batch Normalization,BN),这给VGG16的训练带来了难度。因此,在本文中,我们对VGG16进行了一些修改,如下所示:
- 在每一层卷积层后都加上批归一化层(BN层)。
- 将三个全连接层替换为一个全局平均池化层和一个全连接层。
修改后的网络结构可由pytorch代码描述如下:
import torch
import torch.nn as nn
# VGG16
class VGG16(nn.Module):
def __init__(self):
super(VGG16, self).__init__()
# 特征提取层
self.features = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=64,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(num_features=64),
nn.ReLU(),
nn.Conv2d(in_channels=64,out_channels=64,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(num_features=64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=128),
nn.ReLU(),
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=128),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=256),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=256),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=256),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
#
self.pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(in_features=512,out_features=5)
def forward(self,x):
x = self.features(x)
x = self.pool(x)
x = x.view(x.size(0),-1)
result = self.fc(x)
return result
if __name__=='__main__':
net=VGG16()
x=torch.randn(1,3,224,224)
print(net(x).size())
卷积BN融合
在模型训练完毕后,我们对卷积层和BN层的权重进行了BN融合操作,其原理也十分简单。由于该操作十分常见,因此本文不再赘述,详细可见博客。
基于FPGA的加速器设计
由于VGG16的绝大部分计算量均集中在卷积层,因此,我们仅设计针对卷积的硬件加速IP核。此外,考虑到卷积层后有时会紧接着一个池化层,因此,如需要进行池化操作,则该硬件加速IP会在卷积完成后立即进行池化操作,然后再写回片外存储器。这样做的好处是省去了不必要的片外访存开销,既降低了延迟又减少了功耗开销。
加速器的设计是平凡的,主要采用的优化方法包括:
循环分片(loop tiling):对卷积层输出特征图的高、宽以及卷积的输出和输入通道进行了分块操作,分块大小分别记为 T r T_r Tr, T c T_c Tc, T m T_m Tm, T n T_n Tn,目前其值分别取为14,14,4,48。
定点数量化:将32位浮点数量化为了16位的定点数,其中,小数部分占10位,整数部分占6位,最高位为符号位。在HLS代码中,该数据类型可以表示为ap_fixed<16,6,AP_RND,AP_SAT>。实验表明,16位定点数量化显著减少了加速器的硬件资源消耗(包括存储资源BRAM以及计算资源DSP),同时较好地保持了模型精度。(1个32位浮点数乘法需要消耗3个DSP48E1,而1个16位定点数乘法仅需消耗1个DSP48E1)
流水线:可以有效提升加速器的吞吐率。在HLS中可以简单的通过#pragma HLS PIPELINE II=1实现。
循环展开:所谓循环展开,体现在硬件层面,就是复制多个运算单元,并行执行循环中所需的运算。在本文中,我们在卷积层的输入和输出通道进行了展开,展开的大小等于分块的大小,即 P m = T m P_m=T_m Pm=Tm, P n = T n P_n=T_n Pn=Tn。在HLS中,循环展开可以通过#pragma HLS UNROLL实现。
乒乓操作:乒乓操作是一个常常应用于数据流控制的设计思想,典型的乒乓操作如下图所示,其处理流程为:输入数据流通过“输入数据选择单元”将数据流等时分配到两个“数据缓冲模块”, 数据缓冲模块可以为任何存储模块,比较常用的存储单元为双口RAM (DPRAM)、单口RAM (SPRAM)、FIFO等。 在第2个缓冲周期, 通过“输入数据选择单元”的切换,将输入的数据流缓存到“数据缓冲模块2”,同时将“数据缓冲模块1”缓存的第1个周期数据通过“输出数据选择单元”的选择,送到“数据流运算处理模块”进行运算处理。事实上,乒乓操作是一种粗粒度的流水线技术,它以硬件资源(或面积)为代价,提升了系统整体的吞吐率。
PS部分设计
HLS代码编写完毕后,可以通过C仿真、C/RTL协同仿真验证其正确性,然后通过C综合将它转化为RTL代码,最后导出为Vivado可用的IP核。在Vivado中,我们将该IP核与ZYNQ IP核通过AXI总线连接在一起,然后综合、实现、生成比特流文件。
上述步骤完毕后,我们便可以在Vitis中编写C/C++代码,通过调用挂载在ZYNQ上的加速器,实现对VGG16网络的加速。如下代码展示了如何在PS上调用FPGA部分的加速器。
void conv_and_pool_init(){
XStd_conv_Initialize(&hls_inst, 0);
}
void conv_and_pool_pl(short* in,short* weight,short* bias,short* out,int ch_in,int ch_out,int h,int w,int pool){
//Xil_DCacheFlushRange((u32)in,ch_in*h*w*sizeof(short));
XStd_conv_Set_in1_V(&hls_inst, (u32)in);
XStd_conv_Set_in2_V(&hls_inst, (u32)in);
XStd_conv_Set_in3_V(&hls_inst, (u32)in);
XStd_conv_Set_in4_V(&hls_inst, (u32)in);
//
XStd_conv_Set_w1_V(&hls_inst, (u32)weight);
XStd_conv_Set_w2_V(&hls_inst, (u32)weight);
XStd_conv_Set_w3_V(&hls_inst, (u32)weight);
XStd_conv_Set_w4_V(&hls_inst, (u32)weight);
//
XStd_conv_Set_bias_V(&hls_inst, (u32)bias);
XStd_conv_Set_out1_V(&hls_inst, (u32)out);
XStd_conv_Set_out2_V(&hls_inst, (u32)out);
XStd_conv_Set_out3_V(&hls_inst, (u32)out);
XStd_conv_Set_out4_V(&hls_inst, (u32)out);
//
XStd_conv_Set_ch_in(&hls_inst, (u32)ch_in);
XStd_conv_Set_ch_out(&hls_inst, (u32)ch_out);
XStd_conv_Set_fm_size(&hls_inst, (u32)h);
XStd_conv_Set_pool(&hls_inst, (u32)pool);
XStd_conv_Start(&hls_inst);
while(XStd_conv_IsDone(&hls_inst)==0);
//if(pool==1)
// Xil_DCacheInvalidateRange((u32)((unsigned int)out&0xffffffe0), 32*((ch_out*h*w/4*sizeof(short))/32+2));
//else
// Xil_DCacheInvalidateRange((u32)((unsigned int)out&0xffffffe0), 32*((ch_out*h*w*sizeof(short))/32+2));
}
其中,conv_and_pool_init函数用于初始化加速器,而conv_and_pool_pl函数用于调用加速器进行计算,其参数的含义解释如下:
in: 输入特征图在DDR中的的起始地址。
weight: 权重在DDR中的起始地址。
bias: 偏置在DDR中的起始地址。
out: 输出特征图在DDR中的起始地址。
ch_in: 卷积的输入通道数。
ch_out: 卷积的输出通道数。
h: 输入特征图的高度。
w: 输入特征图的宽度。
pool: 是否进行池化操作,为1表示需要进行池化操作,为0则表示无需进行池化操作。
上述两个函数中用到的驱动函数可在头文件xstd_conv.h中查询(如下图),这些驱动函数是由HLS工具自动生成的,可以大大简化程序员调用加速器的难度。
结果
实验的硬件平台为zynq7020开发板(xc7z020clg400-2),所用的vivado版本为2019.2。硬件加速器的资源、功耗情况(时钟频率130MHz)如下图所示。
由图可知,加速器的片上功耗为2.939W,共消耗了35874个LUTs,40766个FF以及220个DSP。可见,加速器的规模主要受限于DSP的数目(zynq7020的DSP总数仅为220个)。
推理测试

共测试了100张图片,精度为0.95,总共耗时约74000000us,故单张图片的推理延迟为0.74s,考虑到VGG16的计算量为15.5GMACs(15.5G乘累加操作),如果将一次乘累加操作算作2次运算,则VGG16的GOPs为31GOPs,因此,加速器的吞吐率为31/0.74=41.9GOP/s。
(CNN计算量的计算方法可以参见博客)文章来源:https://www.toymoban.com/news/detail-461487.html
附:整个工程有偿出售(包括Python代码,HLS代码以及Vitis代码),若有意向可私聊。文章来源地址https://www.toymoban.com/news/detail-461487.html
到了这里,关于基于FPGA的VGG16卷积神经网络加速器的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!