- 订阅:新手可以订阅我的其他专栏。免费阶段订阅量1000+
python项目实战
Python编程基础教程系列(零基础小白搬砖逆袭)
- 说明:本专栏持续更新中,目前专栏免费订阅,在转为付费专栏前订阅本专栏的,可以免费订阅付费专栏,可报销(名额有限,先到先得)。
即将转为付费专栏,更多详细请看,五一或有优惠活动哦。文章来源:https://www.toymoban.com/news/detail-461802.html
关于专栏〖Python网络爬虫实战〗转为付费专栏的订阅说明文章来源地址https://www.toymoban.com/news/detail-461802.html
- 作者:
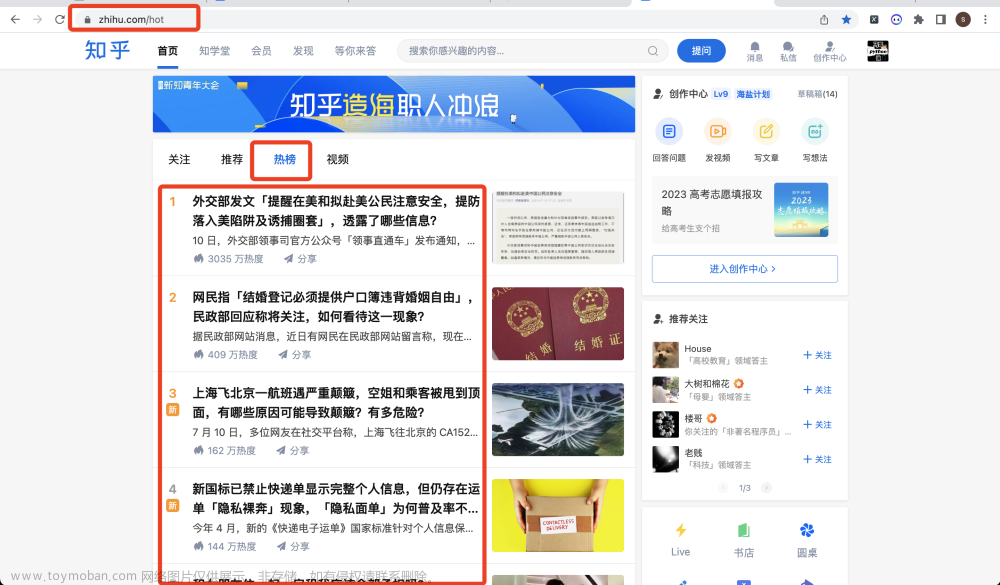
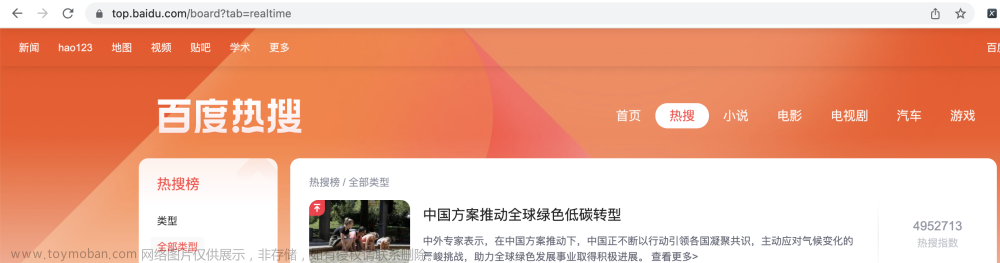
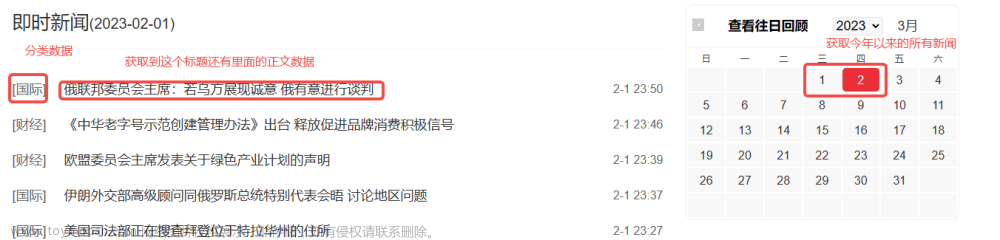
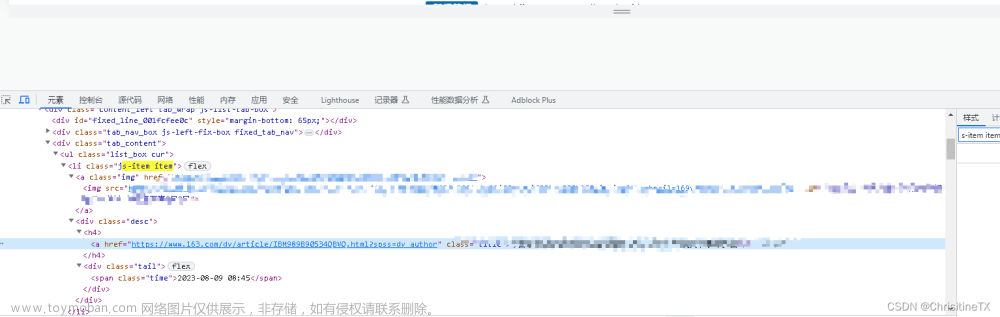
到了这里,关于〖Python网络爬虫实战㉕〗- Ajax数据爬取之Ajax 案例实战的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!