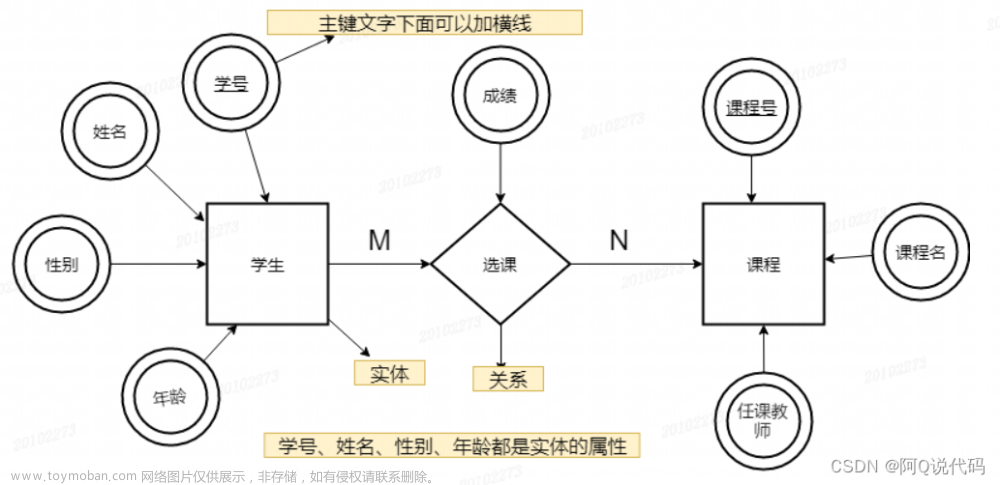
数据库三范式:
什么是范式
规则:想要设计一个好的关系,必须要满足一定的约束条件,有几个等级,一级比一级高
解决什么问题:让数据库设计更加简洁,结构更加清晰,否则容易造成数据冗余
数据库有哪些范式?
数据库有七大范式,常用的只有三个范式
**第一范式:**业务上属性不需要再分
**第二范式:**必须基于第一范式,非主属性都要全部主属性全部唯一确定,不可以由部分主属性就可以确定
主属性:表示唯一,可以有多个,不是主键的意思
非主属性:不是主属性的其他属性就是非主属性,也可以有多个
**不满足第二范式出现的问题:**数据冗余,表的设计可以如下:

企业级应用:用户表,角色表,权限表,角色权限中间表
第三范式::基于第二范式,非主属性都要由主属性才能唯一确认,不可以出现另一个或者另一些非主属性可以确认的情况(要求一个数据库表中不包含已在其他表中已包含的非主属性)
sql分类
1.DQL:查询语言
2.DDL:建库语言
3.DML:增删改
4.TCL:事务处理语言
set autocommit=0:非自动提交
set autocommit=1:自动提交
start transcation:表示开启事务–可以执行多条sql语句
commit:提交
rollback:回滚事务
5.DCL:数据库控制语言
mysql数据库自带一个user表
` host:表示访问当前数据库的ip地址,指定哪些ip可以访问
user:表示用户名
user@localhost
分配一个账号:
创建一个用户:create user ‘用户名’@‘ip’ identified by ‘密码’
首次创建一个账号之后,可以进行登录,有两个数据库,有一个测试库可以执行任何操作,不能看其他的数据库
给账号授权:
grant 权限列表 on 数据库名称.表 to ‘账号’@‘ip’
权限列表:有多个权限使用 “,” 进行分割
撤销权限
revoke 权限列表 on 数据库名称.表名 from ‘账号’@‘ip’
在linux服务器上更新权限之后,需要重新重启mysql或者执行flush privileges;
单表查询
distinct(消除重复记录)
过滤查询
1.字符串和日期使用单引号括起来
2.字符串可以使用binary关键字规定字符串大小写
空值:
不表示0或者空字符串
任意类型都可以支持空值
包括空值的任何算数表达式等于空
使用函数 **IFNULL(expr1,expr2)**对null值进行处理,例;ifnull(emp,0)
逻辑运算符
优先级规则:比较运算符>not>and>or
结果排序
asc:升序
desc:降序
order by:字句在select语句后面执行
order by不能使用引号的别名进行排序,无效果
多表查询
使用原因:查询的数据分散在多张表中,只能使用多表查询
隐式内连接:
select [distinct] * |字段名 from 表1,表2... where 条件 order by 排序字段 asc|desc
**注意:**当多个表的字段重名的时候,必须在列的名字前加上表名做为前缀,否则不能识别是哪一个表的字段
显示内连接(使用 join on):
SELECT table1.column, table2.column
FROM table1 [INNER] JOIN table2 ON table1.column1 =table2.column2 WHERE 条件
内连接弊端:不能查询不满足条件的数据
外连接作用:将两张表不匹配的数据使用null进行填充
左外连接(以左表为主 left join on):
select table1.colum,table2.cilum from table1 left join table2 on table1.colum=table2.colum;
右外连接(以右表为主 right join on):
SELECT table1.column, table2.column
FROM table1 [INNER] JOIN table2 ON table1.column1 = table2.column2
WHERE 条件
多行函数
count():求数据个数,里面可以写*,1等,与写的东西无关,
avg():求平均值
max():求最大值
min():求最小值
sum():求和
注:不能再where中使用分组函数
分组查询(group by)
语法
SELECT [DISTINCT] *|分组字段1 [别名] [, 分组字段2 [别名] ,…] | 统计函数
FROM 表名称 [别名], [表名称 [别名] , …]
[WHERE 条件(s)]
[GROUP BY 分组字段1 [, 分组字段2 ,…]]
having分组限定:
不能在where字句中使用统计函数,having字句可以使用统计函数
select deptno,avg(sal) from emp group by deptno having avg(sal)>2000;
注意:
1.在group中出现的字段,可以不出现在select列表中
2.使用group by多列分组的时候,结果会按照分组字段的顺序进行排序显示
子查询
一个 查询之中嵌套了若干个其他的查询
子查询可以放到where之后:
select * from table where expr=(select expr from table
)
子查询在输出列表中;
SELECT dept_name, (SELECT COUNT(*) FROM employee WHERE employee.dept_id = department.dept_id) AS employee_count
FROM department;
子查询放在from后面:
SELECT department.dept_name, AVG(employee.salary) AS avg_salary
FROM (
SELECT employee.employee_id
FROM employee INNER JOIN department ON employee.department_id=department.department_id
) AS employee
GROUP BY department.department_id;
in里面可以是一个表达式,不仅仅是一个个值
SELECT firstname, lastname FROM employees WHERE salary IN (SELECT MAX(salary) FROM employees);
单行单列:
where中返回的结果只有一行数据
SELECT * FROM emp WHERE sal > (SELECT sal FROM emp WHERE ename = 'MARTIN')
多行单列:
where中返回的结果有多行或者零行
-
IN:与列表中的任意一个值相等 -
ANY:与子查询返回的任意一个值比较 -
=ANY:此时和 IN 操作符相同 -
>ANY:大于子查询中最小的数据 -
<ANY:小于子查询中最大的数据 -
ALL:与子查询返回的每一个值比较 -
>ALL:大于子查询中最大的数据 -
<ALL:小于子查询中最小的数据
select * from emp where sal >any(select sal from emp where sal>2957);
查询满足工资大于(查询结果大于2957)的员工所有信息文章来源:https://www.toymoban.com/news/detail-461831.html
多行多列;
子查询的结果是多行多列,一般将子查询返回的结果当一个临时表,此时必须设置一个临时表文章来源地址https://www.toymoban.com/news/detail-461831.html
于子查询中最大的数据
-
ALL:与子查询返回的每一个值比较 -
>ALL:大于子查询中最大的数据 -
<ALL:小于子查询中最小的数据
select * from emp where sal >any(select sal from emp where sal>2957);
查询满足工资大于(查询结果大于2957)的员工所有信息
多行多列;
子查询的结果是多行多列,一般将子查询返回的结果当一个临时表,此时必须设置一个临时表
到了这里,关于mysql加强小结 203446的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!



![[MySQL]数据库原理1,三大范式,E-R图,DataBase,数据库管理系统(DBMS),Relationship,实体、属性、联系 映射基数,关系型数据库,联系的度数等——喵喵期末不挂科](https://imgs.yssmx.com/Uploads/2024/02/766862-1.png)