本文简单总结正则表达式的一些语法规则和给出相关示例。
更新: 2023 / 7 / 1
正则匹配作为专业的查找工具,在判断字符串中含有特定字串上效率相对较高。
正则表达式
基本内容
正则表达式修饰符 —— 可选标志
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR (|) 来指定。如 re.l | re.M 被设置成 l 和 M 标志 1。
| 修饰符 | 功能 | 全称 |
|---|---|---|
re.I |
匹配忽略大小写 | re.IGNORECASE |
re.L |
做本地化识别( locale-aware )匹配 |
|
re.M |
多行匹配,影响 ^ 和 $正则表达式中 ^ 表示匹配行的开头,默认模式下它只能匹配字符串的开头;而在多行模式下,它还可以匹配换行符 \n 后面的字符。NOTE:正则语法中 ^ 匹配行开头、\A 匹配字符串开头,单行模式下它两效果一致,多行模式下 \A 不能识别 \n) |
re.MULTILINE |
re.S |
使 . 匹配包括换行在内的所有字符( DOT 表示.,ALL 表示所有,连起来就是 . 匹配所有,包括换行符 \n。默认模式下 . 是不能匹配行符 \n 默认模式下,. 是不能匹配行符 \n 的)。 |
re.DOTALL |
re.U |
表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库 (与 ASCII 模式类似,匹配 unicode 编码支持的字符,但是 Python 3 默认字符串已经是 Unicode,所以有点冗余) |
re.UNICODE |
re.X |
增加可读性,忽略空格和 # 后面的注释 (默认模式下并不能识别正则表达式中的注释,而详细模式是可以识别的) |
re.VERBOSE |
re.A |
让 \w, \W, \b, \B, \d, \D, \s 和 \S
|
只匹配 ASCII,而不是Unicode
|
re.DEBUG |
显示编译时的 debug 信息 |
re.DEBUG |
正则表达式模式
模式字符串使用特殊的语法来表示一个正则表达式:
- 字母和数字表示它们自身。
-
多数字母和数字前加一个反斜杠时会有不同的涵义,比如
\n表示换行。 - 标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。
- 反斜杠本身需要使用反斜杠转义。
-
由于正则表达式通常都包含反斜杠,最好使用原始字符串来表示它们。模式元素(如
r\t等价于\\t)匹配相应的特殊字符。
下表列出了正则表达式模式语法中的特殊元素 2。如果使用模式的同时提供了可选的标志参数,某些模式元素的含义会被改变:
元字符
| 元字符 | 描述 |
|---|---|
\ |
将下一个字符标记符,或一个向后引用,或一个八进制转义符。例如,\\n 匹配 \n,\n 匹配换行符。序列 \\ 匹配 \\,而 \( 则匹配 (。例如, python\\.org,或 r’python.org‘ 匹配字符串 python.org。 |
^ |
匹配字符串的开头。 如果设置了 RegExp 对象的 multiline 属性,^ 也匹配 “\n” 或 “\r” 之后的位置。 |
$ |
匹配字符串的结尾。 如果设置了 RegExp 对象的 multiline 属性,$ 也匹配 \n 或 \r 之前的位置。 |
* |
匹配前面的子表达式任意次。例如,zo* 能匹配 z,也能匹配 zo 以及 zoo,* 等价于 {0, }。 |
? |
匹配前面的子表达式零次或一次。 例如, do(es)? 可以匹配 do 或者 does。? 等价于 {0,1}。 |
{n} |
n 是一个非负整数,匹配确定的 n 次,例如 o{2} 不能匹配 Bob 中的 o,但是能匹配 food 中的两个 o。 |
{n,} |
n 是一个非负整数,至少匹配 n 次。例如,o{2,} 不能匹配 Bob 中的 o,但是能匹配 food 中的两个 o
|
{n,m} |
m 和 n 均为非负整数,其中 n <= m,最少匹配 n 次且最多匹配 m 次。例如,o{1,3} 将匹配 foooood 中的前三个 o 为一组,后三个 o 为一组。o{0,1} 等价于 o?。请注意,在逗号和两个数之间不能有空格。 |
? |
当该字符紧跟在任何一个其他限制符(*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少地匹配所搜索的字符串,而默认的贪婪模式则尽可能多地匹配所搜索的字符串。例如,对于字符串 “oooo”,“o+" 将尽可能多地匹配 “o”,得到结果[“oooo”],而 “o+?” 将尽可能少地匹配 “o”,得到结果 [‘o’, ‘o’, ‘o’, ‘o’] |
. |
匹配除了换行符 \n 和 \r 之外的任何单个字符。要匹配包括 \n 和 \r 在内的任何字符,请使用像 [\s\S] 的模式 |
(pattern) |
匹配 pattern 并获取这一匹配。所获取的匹配可以从产生的 Matches 集合得到,在 VBScript 中使用 SubMatches 集合,在 JScript 中则使用 $0...$9 属性。 |
(?:pattern) |
非获取匹配,匹配 pattern 但不获取匹配结果,不进行存储供以后使用。这在使用或字符 (|) 来组合一个模式的各个部分时很有用。例如 "Industri(?:y |
(?=pattern) |
非获取匹配,正向肯定预查,在任何匹配 pattern 的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如,Windows(?=95|98|NT|2000) 能匹配 Windows2000 中的 Windows,但不能匹配 Windows3.1 中的 Windows,但不能匹配 Windows2000 中的 Windows。 |
(?!pattern) |
非获取匹配,正向否定预查。在任何不匹配 pattern 的字符串开始匹配查找字符串,该匹配不需要获取供以后使用,例如,Windows(?!95|98|NT|2000) 能匹配 Windows3.1 中的 Windows,但不能匹配 Windows2000 中的 Windows
|
a|b |
匹配 a 或 b例如, z|food 能匹配 z 或 food。[z|f]ood 则匹配 zood 或 food。 |
[xyz] |
字符集合。匹配所包含的任意一个字符。 例如, [abc] 可以匹配 plain 中的 a。[pj]ython 与 python 和 jython 都匹配。 |
[^xyz] |
负值字符集合。匹配未包含的任意字符。 例如, [^abc] 可以匹配 plan 中的 plin 任一字符。 |
[a-z] |
字符范围。匹配指定范围内的任意字符。例如,[a-z] 可以匹配 a 到 z 范围内的任意小写字母字符。注意:只有连字符在字符组内部时,并且出现在两个字符之间时,才能表示字符的范围;如果出字符组的开头,则只能表示连字符本身。 |
[^a-z] |
负值字符范围。匹配任何不在指定范围内的任意字符。例如,[^a-z] 可以匹配任何不在 a 到 z 范围内的任意字符。 |
\b |
匹配一个单词边界,也就是指单词和空格间的位置。 即正则表达式的 匹配 有2种概念,一种是匹配字符,一种是匹配位置,这里的 \b 就是匹配位置的。例如, er\b 可以匹配 never 中的 er,但不能匹配 verb 中的 er;\b1_ 可以匹配 1_23 中的 1_,但不能匹配 21_3 中的 1_。 |
\B |
匹配非单词边界,er\B 能匹配 verb 中的 er,但不能匹配 never 中的 er
|
\cx |
匹配由 x 知名的控制字符。例如,\cM 匹配一个 Control-M 或回车符,x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 c 字符。 |
\d |
匹配一个数字字符,等价于 [0-9]。grep 要加上 -P,perl 正则支持。 |
\D |
匹配一个非数字字符,等价于 [^0-9]。grep 要加上 -P,perl 正则支持。 |
\f |
匹配一个换页符。等价于 \x0c 和 \cL。 |
\n |
匹配一个换行符。等价于 \x0a 和 \cJ。 |
\r |
匹配一个回车符。等价于 \x0d 和 \cM。 |
\s |
匹配任何不可见字符,包括空格、制表符、换页符等等。等价于 \f\n\r\t\v。 |
\S |
匹配任何可见字符。等价于 ^ \f\n\r\t\v。 |
\t |
匹配一个制表符。等价于 \x09 和 \cl。 |
\v |
匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
\w |
匹配包括下划线的任何单词字符。类似但不等价于 [A-Za-z0-9],这里的单词字符使用 Unicode字符集。 |
\W |
匹配任何非单词字符。等价于 [^A-Za-z0-9_]
|
\xn |
匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,\x41 匹配 A。\x041 则等价于 x04&1。正则表达式中可以使用 ASCII 编码。 |
\num |
匹配 num,其中 num 是一个正整数。对所获取的匹配的引用,例如 (.)\1 匹配两个连续的相同字符。 |
\n |
标志一个八进制转义值或一个向后饮用,如果 \n 之前至少 n 个获取的子表达式,则 n 为向后引用,否则,如果 n 为八进制数字( 0-7 ),则 n 为一个八进制转义值。 |
\nm |
标识一个八进制转义值或一个向后饮用。如果 \nm 之前至少有 nm 个获得子表达式,则 nm 为向后引用。如果 nm 之前至少有 n 个获取,则 n 为一个后跟文字 m 的向后引用。如果前面的条件都不满足,若 n 和 m 均为八进制数字( 0-7 ),则 \nm 将匹配八进制转义值 nm。 |
nml |
如果 n 为八进制数字( 0-7 ),且 m 和 l 均为八进制数字( 0-7 ),则匹配八进制转义值 nml。 |
un |
匹配 n,其中 n 是一个用四个十六进制数字表示的 Unicode 字符。例如,\u00A9 匹配版权符号 (©)。 |
\p{P} |
小写 p 是 property 的意思,表示 Unicode 属性,用于 Unicode 正表达式的前缀。中括号内的 P 表示 Unicode 字符集七个字符属性之一:标点字符。其他六个属性: L:字母;M:标记符号(一般不会单独出现);Z:分隔符(比如空格、换行等)S:符号(比如数字符号、货币符号等);N:数字(比如阿拉伯数字、罗马数字等);C:其他字符。注:此语法部分语言不支持,例如 javascript。 |
\<,\>
|
匹配词( word )的开始 (\<) 和结束 (\>)。例如正则表达式 \<the>\ 能够匹配字符串 for the wise 中的 the,但是不能匹配字符串 overwise 中的 the。注意:这个元字符不是所有的软件都支持。 |
() |
将(和)之间的表达式定义为 组( group ),并且将匹配这个表达式的字符保存到一个临时区域(一个正则表达式中最多可以保存 9 个),它们可以用 \1 到 \9 的符号来引用。 |
| |
将两个匹配条件进行逻辑 或( or )运算。例如正则表达式( him|her )匹配 it belongs to him 和 it belongs to her,但是不能匹配 it belongs to them.注意:这个元字符不是所有的软件都支持的。 |
字符
| 字符 | 描述 |
|---|---|
. |
匹配除了 \n 以外的任何字符,并且只与一个字符相匹配,并且只与一个字符匹配。例如,正则表达式 .ython 与字符串 Python 匹配,不与 cpython 或 ython 匹配。 |
[] |
匹配 [] 中列举的字符 |
[^...] |
匹配不在 [] 中列举的字符 |
\d |
匹配数字,0 到 9
|
\D |
匹配非数字 |
\s |
匹配空白,就是空格和 tab
|
\S |
匹配非空白 |
\w |
匹配字母数字或下划线字符,a-z,A-Z,0-9,_
|
\W |
匹配非字母数字或下划线字符 |
- |
匹配范围,比如 [a-f]
|
数量
| 字符 | 描述 |
|---|---|
* |
前面的字符出现了 0 次或无限次,即可有可无 |
+ |
前面的字符出现了 1 次或无限次,即最少一次 |
? |
前面的字符出现了 0 次或 1 次,要么不出现,要么只出现一次 |
{m} |
前一个字符出现 m 次 |
{m,} |
前一个字符至少出现 m 次 |
{m,n} |
前一个字符出现 m 到 n 次 |
边界
| 字符 | 描述 |
|---|---|
^ |
字符串开头 |
$ |
字符串结尾 |
\b |
匹配一个单词边界,也就是指单词和空格间的位置。 即正则表达式的 匹配 有2种概念,一种是匹配字符,一种是匹配位置,这里的 \b 就是匹配位置的。例如, er\b 可以匹配 never 中的 er,但不能匹配 verb 中的 er;\b1_ 可以匹配 1_23 中的 1_,但不能匹配 21_3 中的 1_。 |
\B |
匹配非单词边界,er\B 能匹配 verb 中的 er,但不能匹配 never 中的 er
|
\A |
匹配字符串的开始位置 |
\Z |
匹配字符串的结束位置 |
分组
用 () 表示的就是要提取的分组,一般用于提取子串。
比如 ^(\d{3})-(\d{3,8})$,从匹配的字符串中提取出区号和本地号码。
| 字符 | 描述 |
|---|---|
| |
匹配左右任意一个表达式 |
(re) |
匹配括号内的表达式,也表示一个组 |
(?:re) |
同上,但是不表示一个组 |
(?P<name>) |
分组起别名,group 可以根据别名取出,比如 (?P<first>\d) match后的结果调 m.group('first) 可以拿到第一个分组中匹配的记过。 |
(?=re) |
前向肯定断言,如果当前包含的正则表达式在当前位置成功匹配则代表成功,否则失败。一旦该部分正则表达式被匹配引擎尝试过,就不会继续进行匹配了;剩下的模式在此断言开始的地方继续尝试。 |
(?!re) |
前向否定断言,作用于上面的相反 |
(?<=re) |
后向肯定断言,作用和 (?=re) 相同,只是方向相反。 |
(?<!re) |
后向肯定断言,作用于 (?!re) 相同,只是方向相反。 |
常见表达式函数
正则表达式是一个特殊的字符序列,可以方便的检查一个字符串是否与某种模式匹配。Python 自带的 re 模块使 Python 语言拥有全部的正则表达式功能。
Python 常用的正则表达式函数如下:
| 功能分类 | 函数 | 功能 |
|---|---|---|
| 查找一个匹配项 | re.search | 查找任意位置的匹配项 |
| re.match | 必须从字符串开头匹配 | |
| re.fullmatch | 整个字符串与正则完全匹配 | |
| 查找多个匹配项 | re.findall | 从字符串任意位置查找,返回一个列表 |
| re.finditer | 从字符串任意位置查找,返回一个迭代器 | |
| 分割 | re.split | 用正则表达式将某字符串分割成多段 |
| 替换 | re.sub | 替换掉某字符串中被正则表达式匹配的字符,返回替换后的字符串,替换可以是字符串 也可以是 函数 |
| re.subn | 替换掉某字符串中被正则表达式匹配的字符,返回替换后的字符串 和 替换次数 | |
| 编译正则对象 | re.compile | 将正则表达式的样式编译为一个 正则表达式对象 (正则对象Pattern) |
| re.template | 将正则表达式的样式编译为一个 正则表达式对象 ,并添加re.TEMPLATE模式 | |
| 其他 | re.escape | 可以转义正则表达式中具有特殊含义的字符,比如: . 或者 * |
| re.purge | 清除正则表达式缓存 |
查找一个匹配项
re.match
语法
re.match(pattern, string, flags=0)
| 参数 | 说明 |
|---|---|
pattern |
匹配的正则表达式 |
string |
要匹配的字符串 |
flags |
标志位,用于控制正则表达式的匹配方式。如,是否区分大小写,多行匹配等等。 |
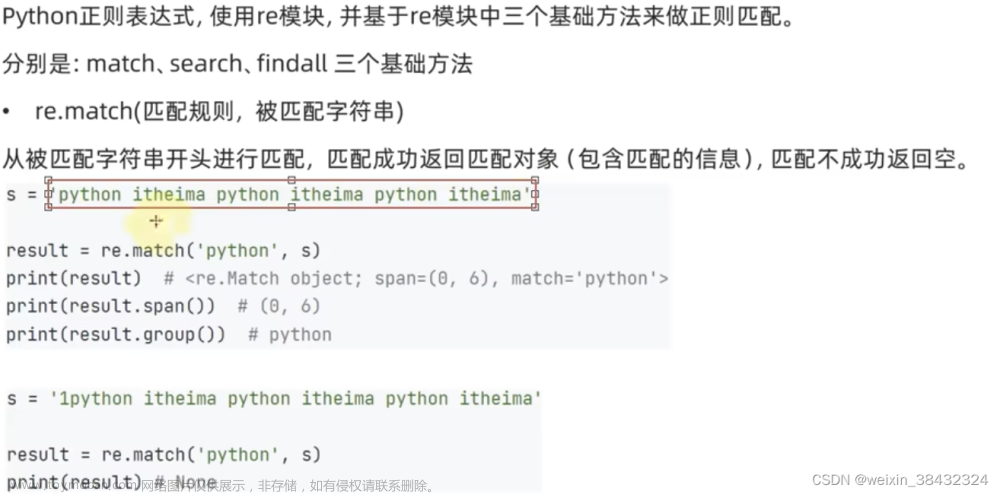
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match() 就返回 none;如果匹配成功的话可以使用 group(num) 或 groups() 匹配对象函数来获取匹配表达式。
| 匹配对象方法 | 描述 |
|---|---|
group(num=0) |
匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组 |
groups() |
返回一个包含所有小组字符串的元组,从 1 到所含的小组号0:表示正则表达式中符合条件的字符串;1:表示正则表达式中符合条件的字符串中的第一个 () 中的字符串;2:表示正则表达式中符合条件的字符串中的第二个 () 中的字符串。 |
示例
s = 'name:alice,result:89'
result = re.match('\w+:(\w+).\w+:(.\d+)', s)
print(result)
# <re.Match object; span=(0, 20), match='name:alice,result:89'>
print(result.group(0))
# name:alice,result:89
print(result.group(1))
# alice
print(result.group(2))
# 89
print(result.group())
# name:alice,result:89
从结果可以看出,re.match() 方法返回一个匹配的对象,而不是匹配的内容。通过调用 span() 可以获得匹配结果的位置。而如果从起始位置开始没有匹配成功,即便其他部分包含需要匹配的内容,re.match() 也会返回 None。可以使用 group() 来提取每组匹配到的字符串。
group() 会返回一个包含所有小组字符串的元组,从 0 到所含的小组号。
注意,如果在运用正则表达式做匹配的过程中没有匹配到元素,之后又调用了 group(),会报错:AttributeError: 'NoneType' object has no attribute 'group'。
如果出现这种报错,可以将 match 改成 search() 就可以避开这类问题了。search 函数是先扫描全部的代码块,再进行提取的。
re.search
语法
re.search(pattern, string, flags=0)
参数同 re.match()。
在给定字符串中查找第一个与正则表达式匹配的子串,如果找到则返回 MatchObject 对象(结果为真),否则返回 None(结果为假),参数 pattern 为正则表达式,string 为要匹配的字符串,flags 为标志位,控制是否区分大小写等等。
MatchObject 对象包含与模式匹配的子串的信息,这些子串部分称为编组。编组就是放在圆括号内的子模式,根据左边的括号数变好,其中编组 0 指的是整个模式。
MatchObject 对象的几个重要方法:
-
groups返回一个包含所有编组字符串的元组,从1到所含的编组,不包含编组0. -
group[(group1, ...)]获取与给定子模式(编组)匹配的子串,没有指定编组号则默认为0。 -
start([group])返回与给定编组匹配的子串的起始位置; -
end([group])返回与给定编组匹配的子串的终止位置(与切片一样不包含终止位置) -
span([group])返回与给定编组匹配的子串的起始位置和终止位置
示例
-
re.match
s = 'class:1班,name:alice,result:89'
result = re.match('name:(\w+).result:(.\d+)', s)
print(result)
# None
print(result.group(0))
# Traceback (most recent call last):
# File "test.py", line 34, in <module>
# print(result.group(0))
# AttributeError: 'NoneType' object has no attribute 'group'
因为没有在起始位置匹配成功,则 re.match 返回 none。
-
re.search
s = 'class:1班,name:alice,result:89'
result = re.search('name:(\w+).result:(.\d+)', s)
print(result)
# <re.Match object; span=(9, 29), match='name:alice,result:89'>
if result:
print(result.groups())
# ('alice', '89')
print(result.group(0))
# name:alice,result:89
print(result.group(1))
# alice
print(result.start(1))
# 14
print(result.end(1))
# 19
print(result.span(1))
# (14, 19)
print(s[14:19])
# alice
print(result.group(2))
# 89
print(result.start(2))
# 27
print(result.end(2))
# 29
print(result.span(2))
# (27, 29)
print(s[27:29])
# 89
re.search 在整个字符串中进行匹配。
查找多个匹配项
re.findall
语法
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表。
如果有多个匹配模式,则返回元组列表;
如果没有找到匹配对象,则返回空列表;
注意:re.search 和 re.match 都是返回第一个匹配到的对象,而 re.findall 则返回所有的匹配对象。
示例
s = '../DataAnalysis/Jira/DataAnalysisWithJira_1.py'
result = re.findall('\d+', s)
print(result)
# ['1']
分割
语法
re.split(pattern, string[, maxsplit=0, flags=0])
根据模式来分割字符串,返回字符串。
示例
s = '/home/Desktop/string,numpy pandas'
result = re.split('[/ ,]', s)
# 以斜杠、逗号和空格为分隔符进行分割
print(result)
# ['', 'home', 'Desktop', 'string', 'numpy', 'pandas']
替换
re.sub
语法
re.sub(pattern, repl, string, count=0, flags=0)
将字符串中与模式 pattern 匹配的子串都替换为 repl 3
| 参数 | 说明 |
|---|---|
pattern |
必须参数:正则中的模式字符串 |
repl |
必须参数:替换的字符串,也可为一个函数 |
string |
必须参数:要被查找替换的原始字符串 |
count |
可选参数,模式匹配后替换的最大次数,默认 0 表示替换所有的匹配 |
flags |
可选参数,表示编译时用的匹配模式(入忽略大小写、多行模式等),数字形式,默认为 0。 |
示例
1.
s = 'name:alice,result:89'
res1 = re.sub(pattern=r'\d+', repl='90', string=s)
print(res1)
# name:alice,result:90
如果 repl 是一个函数,如下:
def change(matched):
print(matched)
# <re.Match object; span=(18, 20), match='89'>
print(matched.group('value'))
# 89
print(type(matched.group('value')))
# <class 'str'>
value = int(matched.group('value'))
print(str(value + 1))
# 90
print(type(str(value + 1)))
# <class 'str'>
return str(value + 1)
s = 'name:alice,result:89'
# result = re.findall('(?P<value>\d+)', s)
# print(result)
# # ['89']
res1 = re.sub('(?P<value>\d+)', change, s)
print(res1)
# name:alice,result:90
2.
s = 'abc123def'
result = re.sub(r'\D', '-', 'abc123def')
print(result)
编译正则对象
re.compile
语法
re.compile(pattern, flags)
re.compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象。它单独使用就没有任何意义,需要和 findall(),search() 和 match() 搭配使用 1。
re 模块的一般使用步骤是:
- 使用
compile函数将正则表达式的字符串形式编译为一个Pattern对象; - 通过
Pattern对象提供的一系列方法对文本进行匹配查找,获得匹配结果(一个Match对象); - 最后使用
Match对象提供的属性和方法获得信息,根据需要进行其他的操作里是引用;
示例
s = 'www.python.org'
pattern = re.compile(r'python')
result = pattern.search(s)
if result:
print(result)
# < re.Match object; span = (4, 10), match = 'python' >
print(result.group(0))
# python
print(result.span())
# python
print(s[4:10])
# python
技巧总结
| 数据 | 分类 | 表达式 |
|---|---|---|
| 数字 | 整数 | -?\d+ |
| 正整数 | \d+ | |
| 负整数 | -\d+ | |
| 浮点数 | -?\d+\.\d | |
| 字母 | 大写字母 | [A-Z]+ |
| 小写字母 | [a-z]+ | |
| 字符 | 汉字 | [\u3400-\u4dbf\u4e00-\u9fff\uf900-\ufaff] |
示例
数字
s = 'name:alice,math:89.3,english:42,chemistry:-30.5,chinese:56,physics:-59'
result = re.findall('-\d+', s)
# ['-30', '-59']
result = re.findall('\d+', s)
# ['89', '3', '42', '30', '5', '56', '59']
result = re.findall('[0-9]+', s)
# ['89', '3', '42', '30', '5', '56', '59']
result = re.findall('-?\d+\.\d+', s)
# ['89.3', '-30.5']
日期
s = 'name:alice,page:http://baidu.com/, birth date: 11/06/1997'
result = re.search('(0?[1-9]|1[012])[- /.](0?[1-9]|[12][0-9]|3[01])[- /.](19|20)?[0-9]{2}', s)
print(result.group())
# 11/06/1997
s = 'name:alice,page:http://baidu.com/, birth date: 1997/11/06'
result = re.search('(19|20)?[0-9]{2}[- /.](0?[1-9]|1[012])[- /.](0?[1-9]|[12][0-9]|3[01])', s)
print(result.group())
# 1997/11/06
字母
s = 'Name:alice, Result:Math:89.3;English:42;Chemistry:-30.5;Chinese:56;Physics:-59'
result = re.findall('[A-Z]+', s)
print(result)
# ['N', 'R', 'M', 'E', 'C', 'C', 'P']
result = re.findall('[a-z]+', s)
print(result)
# ['ame', 'alice', 'esult', 'ath', 'nglish', 'hemistry', 'hinese', 'hysics']
数字 + 字母
邮箱
参考 4
s = 'name:alice,mail:alice.zhang_0521@hotmail.com'
result = re.findall('mail:([a-zA-Z0-9._%-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,4})', s)
# ['alice.zhang_0521@hotmail.com']
result = re.findall(r'mail:(\S+@\S+)', s)
# ['alice.zhang_0521@hotmail.com']
result = re.findall(r'mail:(\S+)@(\S+)', s)
# [('alice.zhang_0521', 'hotmail.com')]
网址
s = 'name:alice,page:http://baidu.com/'
result = re.findall('([a-zA-z]+://[^\s]*)', s)
# ['http://baidu.com/']
s = 'link: https://www.baidu.com/s?wd=%E6%8E%A8%E5%8A%A8%E4%B8%AD%E5%9B%BD%E4%B8%AD%E4%BA%9A%E5%85%B3%E7%B3%BB%E8%A1%8C%E7%A8%B3%E8%87%B4%E8%BF%9C&sa=fyb_n_homepage&rsv_dl=fyb_n_homepage&from=super&cl=3&tn=baidutop10&fr=top1000&rsv_idx=2&hisfilter=1,yes?'
result = re.findall('([a-zA-z]+://[^\s]*),yes?', s)
# ['https://www.baidu.com/s?wd=%E6%8E%A8%E5%8A%A8%E4%B8%AD%E5%9B%BD%E4%B8%AD%E4%BA%9A%E5%85%B3%E7%B3%BB%E8%A1%8C%E7%A8%B3%E8%87%B4%E8%BF%9C&sa=fyb_n_homepage&rsv_dl=fyb_n_homepage&from=super&cl=3&tn=baidutop10&fr=top1000&rsv_idx=2&hisfilter=1']
字符
汉字
s = '名字:唐_@伯虎; name: tang_bohu;'
result = re.findall('[\u3400-\u4dbf\u4e00-\u9fff\uf900-\ufaff]', s)
# ['名', '字', '唐', '伯', '虎']
pattern
1.
s = 'WindowsXP, Windows97, Windows2000'
result = re.findall('Windows(?=95|98|XP|2000)', s)
# ['Windows', 'Windows']
### 匹配的是 `Windows97` 和 `Windows2000` 中的 `Windows`
s = 'WindowsXP, Windows97, Windows2000'
result = re.findall('Windows(?!95|98|XP|2000)', s)
# ['Windows']
### 匹配的是 `WindowsXP` 中的 `Windows`
2.
s = 'never ever stop running.'
result = re.findall(r'\w+ver\b', s)
# ['never', 'ever']
result = re.findall(r'\bnev\w+', s)
# ['never']
result = re.findall(r'\w+ing\b', s)
# ['running']
去除特殊字符
去空格
s = ' No pain, no gain ...'
result = re.findall('\S', s)
# ['N', 'o', 'p', 'a', 'i', 'n', ',', 'n', 'o', 'g', 'a', 'i', 'n', '.', '.', '.']
result = ''.join(result)
# Nopain,nogain...
去斜杠等
s = './PycharmProjects/DataAnalysis/test_1.py'
x = re.findall('\w+', s)
# ['PycharmProjects', 'DataAnalysis', 'test_1', 'py']
x = '-'.join(x)
# PycharmProjects-DataAnalysis-test_1-py
s = './PycharmProjects/DataAnalysis/file.list'
result = re.findall(r'\w+\.?\w+', s)
# ['PycharmProjects', 'DataAnalysis', 'file.list']
result = re.sub(r'\w+\.?\w+', '..', s)
# ./../../..
去特殊字符
s = './PycharmPro!#@&jects/DataAnalysis/test_1.py'
symbol = re.findall('[!#@^$&)+]+?', s)
# ['!', '#', '@', '&']
s = re.sub('[!#@^$&)+]+?', "", s)
# ./PycharmProjects/DataAnalysis/test_1.py
参考链接
-
【python】使用正则匹配判断字符串中含有某些特定子串 及 正则表达式详解 ↩︎ ↩︎
-
Python正则表达式最强整理(速查手册,记得收藏) ↩︎
-
Python 的正则操作与获取指定目录下的文件 ↩︎文章来源:https://www.toymoban.com/news/detail-462068.html
-
如何在 Python 和 Pandas 中使用正则表达式 ↩︎文章来源地址https://www.toymoban.com/news/detail-462068.html
到了这里,关于python | 巧用正则表达式的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!