网络爬虫

网络爬虫是最常见和使用最广泛的数据收集方法。DIY网络爬虫确实需要一些编程知识,但整个过程比一开始看起来要简单得多。
当然,爬虫的有效性取决于许多因素,例如目标的难度、网站方的反爬虫措施等。如果将网络抓取用于专业目的,例如长期数据采集、定价情报或其它专业目的,就需要不断维护和管理。在本文中,我们将重点讲述构建网页抓取工具的基础知识以及新手可能遇到的常见问题。
网页抓取有什么用?
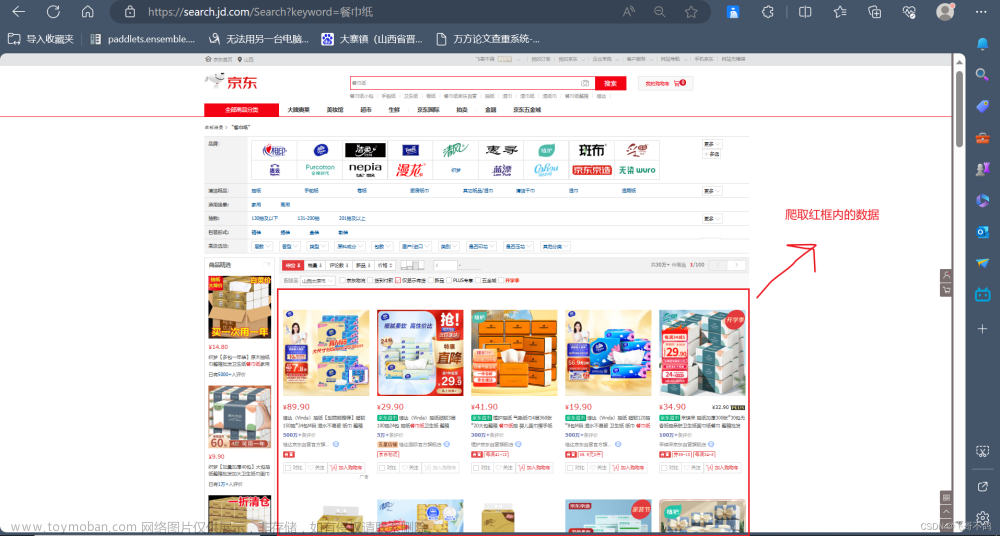
网络爬虫通常是数据采集过程的主要构成部分。通常,它们被用作自动从网络检索大量重要信息。网页抓取案例包括搜索引擎结果、电商网站或其它互联网资源。
以这种方式获取的数据可用于定价情报、股票市场分析、学术研究和许多其它目的。因为爬虫的数据收集方法几乎无限制,所以有许多网页抓取想法可供实践。
当用作数据收集方法时,网络抓取工具包含多个步骤:抓取路径、数据提取脚本、无头浏览器、代理以及最后的解析。让我们快速回顾一下每个步骤的内容:


这就是整个数据收集过程从头到尾的样子。然而,这个信息图只是揭示了表层的工作原理。要更深入地了解,请继续阅读整个过程。
开发基础网络爬虫
构建抓取路径
构建抓取路径是几乎所有数据收集方法的重要组成部分。抓取路径是要从中提取数据的URL库。虽然收集几十个URL看上去似乎很简单,但构建抓取路径实际上需要大量的关注和研究。
有时,创建抓取路径可能需要额外的工作量,因为需要抓取初始页面所需的URL。例如,电商网站有每个产品和产品详情页的URL。为电商网站中特定产品构建抓取路径的方式如下:
1.抓取搜索页面。
2.解析产品页面URL。
3.抓取这些新URL。
4.根据设定的标准进行解析。
因此,构建抓取路径可能不像创建一组易于访问的URL那样简单。通过开发自动化流程创建抓取路径可确保不会遗漏重要的URL。
所有解析和分析工作都将取决于抓取路径中URL获取的数据。当然,准确的动态定价还需要准确的关键来源筛选,因此需要一定的洞察力。如果缺少几个关键来源,动态定价的结果可能就会变得不准确,从而变得无参考价值。
建立爬取路径需要对整个行业和特定竞争对手有一定了解。只有当URL以谨慎和战略性的方式收集时,才能放心地开始数据获取过程。
此外,数据通常分两步存储——预解析(短期)和长期存储。当然,为了使数据收集有效,任何方法都需要不断更新。数据的好坏取决于方法是否更新。

这些步骤是任何网络爬虫的框架
数据提取脚本
构建数据提取脚本当然需要一些事先的编码知识。大多数基本的数据提取脚本都会用Python编译,但还有更多其它工具供选择。Python在从事网页抓取的开发人员中很受欢迎,因为它有许多有用的库,使提取、解析和分析变得更加容易。
数据提取脚本的开发一般要经历几个阶段:
1.确定要提取的数据类型(例如定价或产品数据)。
2.查找数据嵌套的位置和方式。
3.导入和安装所需的库(例如,用于解析的BeautifulSoup,用于输出的JSON或CSV)。
4.编写数据提取脚本。
在大多数情况下,第一步从一开始就很明确。第二步会比较有趣。不同类型的数据将以不同的方式显示(或编码)。在最好的情况下,跨不同URL的数据将始终存储在同一类中,并且不需要显示任何脚本。通过使用每个浏览器提供的检查元素功能,可以轻松找到类和标签。然而,定价数据通常更难获得。
定价或其他数据可能隐藏在Javascript元素中,不存在于初始响应地代码中。通常,这些无法使用常规数据收集方法进行抓取。如果没有其他工具,用于XML和HTML数据抓取和解析的Python库(BeautifulSoup、LXML等)无法访问Javascript元素。你需要一个无头浏览器来抓取这些元素。
无头浏览器
无头浏览器是用于抓取放置在JS元素中的数据的主要工具。或者,也可以使用网络驱动程序,因为最广泛使用的浏览器都提供了这些驱动。网络驱动程序比无头浏览器慢很多,因为它们以与常规网络浏览器类似的方式加载页面。这意味着在每种情况下,抓取结果可能略有不同。测试两个选项并为每个项目找到最佳选项可能是有好处的。

运行中的无头浏览器
代码来源: https://github.com/SimpleBrowserDotNet/SimpleBrowser#example
由于两个最流行的浏览器现在提供无头选项,因此有很多选择。无论是Chrome还是Firefox(68.60%和浏览器市场份额的8.17%)都有无头模式可用。在主流选项之外,PhantomJS和Zombie.JS是网络爬虫中的流行选择。此外,无头浏览器需要自动化工具才能运行网页抓取脚本。Selenium是最流行的网页抓取框架。
数据解析
数据解析是使先前获取的数据变得可理解和可用的过程。大多数数据收集方法收集到的数据都较难理解。因此,解析和转化成让人易懂的结果显得尤为重要。
如前所述,由于易于访问和优化的库,Python是一种流行的定价情报获取语言。BeautifulSoup、LXML和其他选择是数据解析的流行选择。
解析允许开发人员通过搜索HTML或XML文件的特定部分来对数据进行排序。BeautifulSoup之类的解析器带有内置的对象和命令,使过程更容易。大多数解析库通过将search或print命令附加到常见的HTML/XML文档元素,使导航大量数据变得更加容易。
数据存储
数据存储程序通常取决于容量和类型。虽然建议为定价情报(和其他连续项目)构建专用数据库,但对于较短或一次性的项目,将所有内容存储在几个CSV或JSON文件中不会有什么坏处。
数据存储是一个相当简单的步骤,几乎没有问题,尽管要始终牢记一件事–数据的整洁。从错误索引的数据库中检索存储的数据就会变得很麻烦。从正确的方向出发并从一开始就遵循相同的方案,甚至可以在大多数数据存储问题开始之前就解决它们。
长期的数据存储是整个采集过程的最后一步。编写数据提取脚本、找到所需的目标、解析和存储数据是较为简单的部分。避免反爬虫检测算法和IP地址封禁才是真正的挑战。
代理管理
到目前为止,网页抓取可能看起来很简单。创建脚本,找到合适的库并将获取的数据导出到CSV或JSON文件中。然而,大多数网页所有者并不热衷于向任何人提供大量数据。
现在大多数网页都可以检测到类似爬虫的活动,并简单地阻止有问题的IP地址(或整个网络)。数据提取脚本的行为与爬虫完全一样,因为它们通过访问URL列表连续执行循环过程。因此,通过网页抓取来收集数据通常会导致IP地址封禁。
代理用于保持对相同URL的连续访问并绕过IP封锁,使其成为任何数据采集项目的关键组件。使用此数据收集技术创建特定于目标的代理策略对于项目的成功至关重要。
住宅代理是数据收集项目中最常用的类型。这些代理允许他们的用户从常规机器发送请求,从而避免地理或任何其他限制。此外,只要数据收集脚本是以模仿此类活动的方式编写的,它们就会认为是普通互联网用户。

代理是任何网页抓取想法的关键组成部分
当然,爬虫检测算法也适用于代理。获取和管理高级代理是任何成功的数据获取项目的一部分。避免IP封锁的一个关键组成部分是地址轮换。
然而,代理轮换代理轮换问题并未就此结束。爬虫检测算法将因目标而异。大型电商网站或搜索引擎具有复杂的反爬虫措施,需要使用不同的抓取策略。
代理的艰辛
如前所述,轮换代理是任何成功数据收集方法(包括网页抓取)的关键。如果您想避免IP被封锁,维护普通互联网用户的形象是必不可少的。
然而需要更改代理的频率、应该使用哪种类型的代理等的确切细节在很大程度上取决于抓取目标、数据提取的频率和其它因素。这些复杂性使代理管理成为网页抓取中最困难的部分。
虽然每个业务案例都是独一无二的,需要特定的解决方案,但为了以最高效率使用代理,必须遵循指导方针。在数据收集行业经验丰富的公司对爬虫检测算法有最深入的了解。根据他们的案例研究,代理和数据收集工具提供商制定了避免IP地址被封锁的指南。
如前所述,维护普通互联网用户的形象是避免IP封锁的重要部分。虽然有许多不同的代理类型,但没有人能比住宅代理更好地完成这项特定任务。住宅代理是附加到真实机器并由互联网服务提供商分配的IP。从正确的方向出发,为电商数据收集选择住宅代理,使整个过程变得更加容易。
电商的住宅代理

住宅代理是大多数网页抓取想法的最常见选择
住宅代理用于电商数据收集,因为其中大多数数据采集需要维护特定身份。电商企业通常使用多种算法来计算价格,其中一些取决于消费者的属性。其他企业会主动阻止或向他们认为是竞争对手(或爬虫)的访问者显示不正确的信息。因此,切换IP和位置(例如从加拿大代理切换到德国代理)是至关重要的。
住宅代理是任何电商数据收集工具的第一道防线。随着网站实施更复杂的反抓取算法并轻松检测类似爬虫的活动,这些代理允许网页抓取工具重置网站收集到的对其行为的任何怀疑。然而,没有足够的住宅代理在每次请求后切换IP。因此,为了有效地使用住宅代理,需要实施某些策略。
代理轮换基础知识
制定避免IP封锁的策略需要时间和经验。每个目标在它认为是类似爬虫的活动方面的参数略有不同。因此,也需要相应地调整策略。
为代理轮换收集电商数据有几个基本步骤:
-
默认会话时间(Oxylabs的住宅代理将其设置为10分钟)通常就足够了。
-
如果目标流量很大(例如HTML本身就有1MB,没有任何其他内容),则建议延长会话时间。
-
不需要从头开始构建代理轮换器。FoxyProxy或Proxifier等第三方应用程序将完成基本数据收集任务。
-
每当抓取目标时,请考虑普通用户将如何浏览网站并在网站上采取行动。
-
作为默认的模仿策略,在主页上花一些时间然后在几个(5-10个)产品页面上也浏览一下,这样就不容易被怀疑。
请记住,每个目标都是不同的。一般来说,电商网站越先进、越大、越重要,越难通过网页抓取来解决。反复试验通常是创建有效的网页抓取策略的唯一方法。文章来源:https://www.toymoban.com/news/detail-462147.html
总结
想要构建您的第一个网页抓取工具吗?注册并开始使用Oxylabs的住宅代理!如果您想要更多细节或定制计划,可以与我们的团队预约!文章来源地址https://www.toymoban.com/news/detail-462147.html
到了这里,关于网络爬虫DIY解决电商数据收集难题的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!