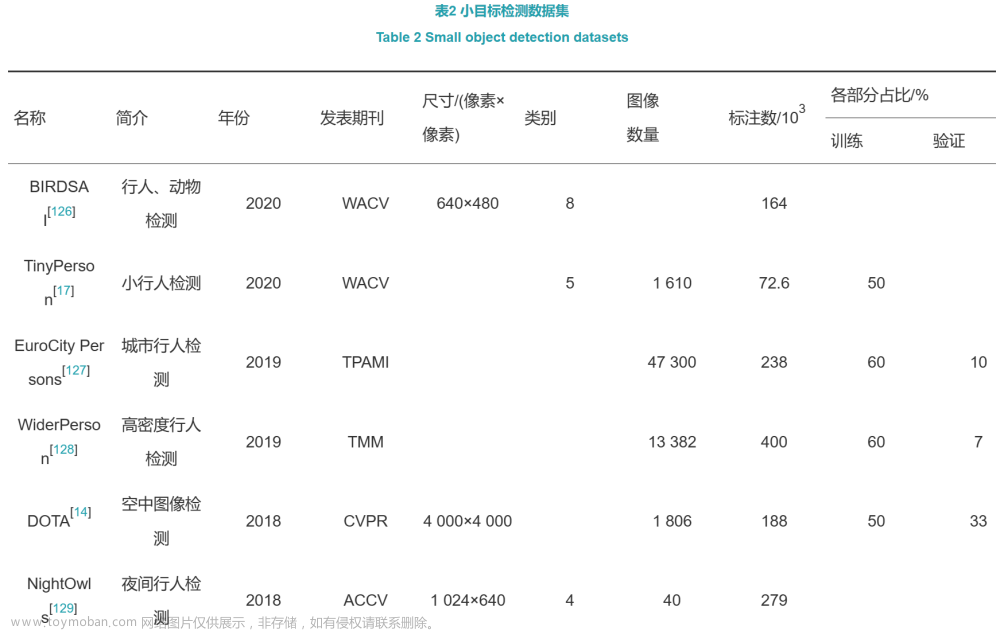
相对其他计算机视觉任务,目标检测算法的数据格式更为复杂。为了对数据进行统一的处理,目标检测数据一般都会做成VOC或者COCO的格式。
VOC和COCO都是既支持检测也支持分割的数据格式,本文主要分析PASCAL VOC和COCO数据集中物体识别相关的内容,并学习如何制作自己的数据集。
一、VOC格式
目录结构
VOC格式数据集一般有着如下的目录结构:
VOC_ROOT #根目录
├── JPEGImages # 存放源图片
│ ├── aaaa.jpg
│ ├── bbbb.jpg
│ └── cccc.jpg
├── Annotations # 存放xml文件,与JPEGImages中的图片一一对应,解释图片的内容等等
│ ├── aaaa.xml
│ ├── bbbb.xml
│ └── cccc.xml
└── ImageSets
└── Main
├── train.txt # txt文件中每一行包含一个图片的名称
└── val.txt
其中JPEGImages目录中存放的是源图片的数据,(当然图片并不一定要是.jpg格式的,只是规定文件夹名字叫JPEGImages);
Annotations目录中存放的是标注数据,VOC的标注是xml格式的,文件名与JPEGImages中的图片一一对应;
ImageSets/Main目录中存放的是训练和验证时的文件列表,每行一个文件名(不包含扩展名),例如train.txt是下面这种格式的:
# train.txt
aaaa
bbbb
ccccXML标注格式
xml格式的标注格式如下:
<annotation>
<folder>VOC_ROOT</folder>
<filename>aaaa.jpg</filename> # 文件名
<size> # 图像尺寸(长宽以及通道数)
<width>500</width>
<height>332</height>
<depth>3</depth>
</size>
<segmented>1</segmented> # 是否用于分割(在图像物体识别中无所谓)
<object> # 检测到的物体
<name>horse</name> # 物体类别
<pose>Unspecified</pose> # 拍摄角度,如果是自己的数据集就Unspecified
<truncated>0</truncated> # 是否被截断(0表示完整)
<difficult>0</difficult> # 目标是否难以识别(0表示容易识别)
<bndbox> # bounding-box(包含左下角和右上角xy坐标)
<xmin>100</xmin>
<ymin>96</ymin>
<xmax>355</xmax>
<ymax>324</ymax>
</bndbox>
</object>
<object> # 检测到多个物体
<name>person</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>198</xmin>
<ymin>58</ymin>
<xmax>286</xmax>
<ymax>197</ymax>
</bndbox>
</object>
</annotation>制作自己的VOC数据集
制作自己数据集的步骤为:
① 新建一个JPEGImages的文件夹,把所有图片放到这个目录。(或者使用ln -s把图片文件夹软链接到JPEGImages);
② 由原来的数据格式生成xml,其中pose,truncated和difficult没有指定时使用默认的即可。bounding box的格式是[x1,y1,x2,y2],即[左上角的坐标, 右下角的坐标]。x是宽方向上的,y是高方向上的。
③ 随机划分训练集和验证集,训练集的文件名列表存放在ImageSets/Main/train.txt,验证集的文件名列表存放在ImageSets/Main/val.txt。
参考代码文章来源:https://www.toymoban.com/news/detail-462603.html
附一个由csv转voc格式的脚本:
# encoding=utf-8
import os
from collections import defaultdict
import csv
import cv2
import ipdb
import misc_utils as utils # pip3 install utils-misc==0.0.5 -i https://pypi.douban.com/simple/
import json
utils.color_print('建立JPEGImages目录', 3)
os.makedirs('Annotations', exist_ok=True)
utils.color_print('建立Annotations目录', 3)
os.makedirs('ImageSets/Main', exist_ok=True)
utils.color_print('建立ImageSets/Main目录', 3)
files = os.listdir('train')
files.sort()
mem = defaultdict(list)
confirm = input('即将生成annotations,大约需要3-5分钟,是否开始(y/n)? ')
if confirm.lower() != 'y':
utils.color_print(f'Aborted.', 3)
exit()
with open('train.csv', 'r') as f:
csv_file = csv.reader(f)
'''
读取的csv_file是一个iterator,每个元素代表一行
'''
for i, line in enumerate(csv_file):
if i == 0:
continue
filename, width, height, bbox, _ = line
x1, y1, x2, y2 = json.loads(bbox)
x1, y1, x2, y2 = int(x1), int(y1), int(x2), int(y2)
x2 += x1
y2 += y1
mem[filename].append([x1, y1, x2, y2])
for i, filename in enumerate(mem):
utils.progress_bar(i, len(mem), 'handling...')
img = cv2.imread(os.path.join('train', filename))
# height, width, _ = img.shape
with open(os.path.join('Annotations', filename.rstrip('.jpg')) + '.xml', 'w') as f:
f.write(f"""<annotation>
<folder>train</folder>
<filename>{filename}.jpg</filename>
<size>
<width>1024</width>
<height>1024</height>
<depth>3</depth>
</size>
<segmented>0</segmented>\n""")
for x1, y1, x2, y2 in mem[filename]:
f.write(f""" <object>
<name>wheat</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>{x1}</xmin>
<ymin>{y1}</ymin>
<xmax>{x2}</xmax>
<ymax>{y2}</ymax>
</bndbox>
</object>\n""")
f.write("</annotation>")
files = list(mem.keys())
files.sort()
f1 = open('ImageSets/Main/train.txt', 'w')
f2 = open('ImageSets/Main/val.txt', 'w')
train_count = 0
val_count = 0
with open('ImageSets/Main/all.txt', 'w') as f:
for filename in files:
# filename = filename.rstrip('.jpg')
f.writelines(filename + '\n')
if utils.gambling(0.1): # 10%的验证集
f2.writelines(filename + '\n')
val_count += 1
else:
f1.writelines(filename + '\n')
train_count += 1
f1.close()
f2.close()
utils.color_print(f'随机划分 训练集: {train_count}张图,测试集:{val_count}张图', 3)
二、COCO格式
目录结构
COCO格式数据集的目录结构如下:
COCO_ROOT #根目录
├── annotations # 存放json格式的标注
│ ├── instances_train2017.json
│ └── instances_val2017.json
└── train2017 # 存放图片文件
│ ├── 000000000001.jpg
│ ├── 000000000002.jpg
│ └── 000000000003.jpg
└── val2017
├── 000000000004.jpg
└── 000000000005.jpg
这里的train2017和val2017称为set_name,annnotations文件夹中的json格式的标注文件名要与之对应并以instances_开头,也就是instances_{setname}.json。
json标注格式
与VOC一个文件一个xml标注不同,COCO所有的目标框标注都是放在一个json文件中的。
这个json文件解析出来是一个字典,格式如下:
{
"info": info,
"images": [image],
"annotations": [annotation],
"categories": [categories],
"licenses": [license],
}制作自己的数据集的时候info和licenses是不需要的。只需要中间的三个字段即可。
其中images是一个字典的列表,每个图片的格式如下:
# json['images'][0]
{
'license': 4,
'file_name': '000000397133.jpg',
'coco_url': 'http://images.cocodataset.org/val2017/000000397133.jpg',
'height': 427,
'width': 640,
'date_captured': '2013-11-14 17:02:52',
'flickr_url': 'http://farm7.staticflickr.com/6116/6255196340_da26cf2c9e_z.jpg',
'id': 397133} 自己的数据集只需要写file_name,height,width和id即可。id是图片的编号,在annotations中也要用到,每张图是唯一的。
categories表示所有的类别,格式如下:
[
{'supercategory': 'person', 'id': 1, 'name': 'person'},
{'supercategory': 'vehicle', 'id': 2, 'name': 'bicycle'},
{'supercategory': 'vehicle', 'id': 3, 'name': 'car'},
{'supercategory': 'vehicle', 'id': 4, 'name': 'motorcycle'},
{'supercategory': 'vehicle', 'id': 5, 'name': 'airplane'},
{'supercategory': 'vehicle', 'id': 6, 'name': 'bus'},
{'supercategory': 'vehicle', 'id': 7, 'name': 'train'},
{'supercategory': 'vehicle', 'id': 8, 'name': 'truck'},
{'supercategory': 'vehicle', 'id': 9, 'name': 'boat'}
# ....
] annotations是检测框的标注,一个bounding box的格式如下:
{'segmentation': [[0, 0, 60, 0, 60, 40, 0, 40]],
'area': 240.000,
'iscrowd': 0,
'image_id': 289343,
'bbox': [0., 0., 60., 40.],
'category_id': 18,
'id': 1768} 其中segmentation是分割的多边形,如果不知道直接填写[[x1, y1, x2, y1, x2, y2, x1, y2]]就可以了,area是分割的面积,bbox是检测框的[x, y, w, h]坐标,category_id是类别id,与categories中对应,image_id图像的id,id是bbox的id,每个检测框是唯一的。
参考代码
附一个VOC转COCO格式的参考代码文章来源地址https://www.toymoban.com/news/detail-462603.html
voc_dataset = VOCTrainValDataset(voc_root,
class_names,
split=train_split,
format=img_format,
transforms=preview_transform)
output_file = f'instances_{train_split[:-4]}.json'
for i, sample in enumerate(voc_dataset):
utils.progress_bar(i, len(voc_dataset), 'Drawing...')
image = sample['image']
bboxes = sample['bboxes'].cpu().numpy()
labels = sample['labels'].cpu().numpy()
image_path = sample['path']
h, w, _ = image.shape
global_image_id += 1
coco_dataset['images'].append({
'file_name': os.path.basename(image_path),
'id': global_image_id,
'width': int(w),
'height': int(h)
})
for j in range(len(labels)):
x1, y1, x2, y2 = bboxes[j]
x1, y1, x2, y2 = float(x1), float(y1), float(x2), float(y2),
category_id = int(labels[j].item()) + 1
# label_name = class_names[label]
width = max(0, x2 - x1)
height = max(0, y2 - y1)
area = width * height
global_annotation_id += 1
coco_dataset['annotations'].append({
'id': global_annotation_id,
'image_id': global_image_id,
'category_id': category_id,
'segmentation': [[x1, y1, x2, y1, x2, y2, x1, y2]],
'area': float(area),
'iscrowd': 0,
'bbox': [x1, y1, width, height],
})
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(coco_dataset, f, ensure_ascii=False)
print(f'Done. coco json file has been saved to `{output_file}`')
到了这里,关于VOC和COCO数据集讲解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!