消息中间件是现代分布式系统中不可或缺的组件之一,它提供了高可靠性、高吞吐量的消息传递机制。Kafka作为一种开源的分布式消息队列系统,广泛应用于各行各业。本篇博客将介绍在实践中使用Kafka的一些技巧和最佳实践,帮助开发人员更好地利用Kafka构建可靠的消息传递系统。
1. Kafka简介
在正式探讨使用技巧之前,让我们先来了解一下Kafka的基本概念和特性。
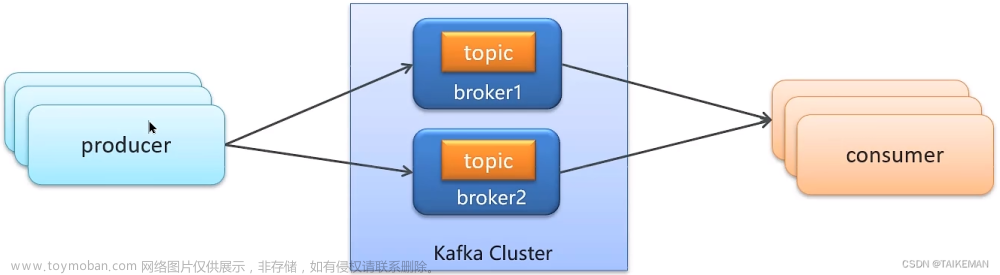
Kafka是一个高性能、可扩展、分布式的发布-订阅消息系统。它主要由以下几个核心组件组成:
- Producer: 生产者,负责将消息发布到Kafka的Topic中。
- Consumer: 消费者,从Kafka的Topic中订阅消息并进行处理。
- Broker: Kafka的中间节点,负责存储和复制消息,同时提供高可用性和容错性。
- Topic: 消息的分类,生产者将消息发布到特定的Topic中,消费者从Topic中订阅消息。
- Partition: Topic的分区,每个Topic可以分为多个分区,用于实现数据的并行处理和负载均衡。
- Consumer Group: 消费者组,多个消费者可以组成一个消费者组,共同消费一个Topic的消息。
Kafka的特点包括高吞吐量、持久性、可扩展性和容错性,使其成为构建大规模分布式系统的理想选择。
2. 使用技巧
2.1 合理设置分区数
在创建Topic时,需要考虑合理的分区数。分区数的选择应根据预期的吞吐量和并行处理需求进行权衡。较少的分区数可能会限制并行性能,而较多的分区数可能会增加系统管理的复杂性。根据实际情况选择适当的分区数,以满足性能和管理需求。
详细说明:
在使用Kafka时,一个重要的设计考虑是合理设置Topic的分区数。分区是Kafka中实现数据并行处理和负载均衡的基本单位。较少的分区数可能会导致消息处理能力不足,而较多的分区数则会增加系统的管理复杂性。
为了确定合适的分区数,需要考虑以下几个因素:
- 预期的吞吐量: 根据预期的消息流量和处理能力需求,选择足够的分区数以支持并行处理。如果分区数过少,可能无法充分利用集群中的消费者和处理能力。
- 消息的有序性要求: 如果消息的顺序对业务逻辑非常重要,那么分区数应与消费者数量相等,以确保每个消费者只消费一个分区的消息。这样可以保证每个消费者处理的消息是有序的。
- 系统管理的复杂性: 分区数过多会增加系统管理的复杂性,包括备份和恢复、数据迁移、监控等方面的工作。因此,需要在满足性能需求的前提下,权衡系统管理的成本和复杂性。
假设我们有一个名为"orders"的Topic,用于处理订单数据。根据业务需求和系统负载情况,我们需要设置合适的分区数。
如果我们预计每秒有数千条订单数据产生,并且希望能够实现高并发处理,我们可以选择将"orders" Topic设置为10个分区。这样可以将负载分散到多个分区上,并充分利用集群中的消费者和处理能力。
另一方面,如果订单数据的有序性对业务非常重要,我们可以选择与消费者数量相等的分区数,例如设置为5个分区。这样每个消费者只需要处理一个分区的数据,保证了消息的有序性。
需要注意的是,分区数的调整可能涉及到Kafka Topic的重新分配和数据迁移,因此在生产环境中需要谨慎操作,并充分考虑系统管理的复杂性。
2.2 生产者端性能优化
在使用Kafka的生产者时,可以采取一些优化策略来提高性能和可靠性。
Kafka生产者的性能和可靠性对于系统的整体效果非常重要。下面是一些优化策略,可以帮助提高生产者端的性能:
-
批量发送: 考虑将消息批量发送到Kafka,而不是每条消息单独发送。批量发送可以减少网络开销,并提高吞吐量。可以通过设置
batch.size和linger.ms**参数来控制批量发送的大小和等待时间。 - 异步发送: 使用异步发送方式可以提高生产者的吞吐量。通过将消息放入发送缓冲区并异步发送,可以避免等待响应的时间开销,从而提高发送速度。
- 消息压缩: 对于大量的数据,考虑启用消息压缩功能。Kafka支持多种压缩算法,可以根据数据特点选择合适的压缩算法,减少网络传输的数据量。
- 错误处理和重试: 在发送消息时,要考虑错误处理和重试机制。可以设置适当的重试次数和重试间隔,以处理发送过程中可能出现的错误和异常情况。
假设我们有一个名为"orders"的Topic,用于处理订单数据。我们的生产者需要将订单信息发送到Kafka。
首先,我们可以设置批量发送的参数。通过设置batch.size为500,linger.ms**为5,可以将消息批量发送,每次发送500条消息,并等待5毫秒以充分填满批次。
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("batch.size", 500);
props.put("linger.ms", 5);
Producer<String, String> producer = new KafkaProducer<>(props);
其次,我们可以启用消息压缩功能,以减少数据传输的大小。可以选择使用GZIP压缩算法,将消息压缩成gzip格式。
props.put("compression.type", "gzip");
另外,我们需要实现错误处理和重试机制。在发送消息时,可以捕获可能出现的异常,并进行重试操作。
try {
producer.send(new ProducerRecord<>("orders", key, value)).get();
} catch (Exception e) {
// 错误处理逻辑
// 进行重试操作
}
需要根据具体业务需求和系统负载情况,调整这些参数和策略,以获得最佳的性能和可靠性。
结论
Kafka作为一种高性能、可靠性强的消息中间件,广泛应用于各个领域。通过合理设置分区数、优化生产者端性能和进行消费者组管理,可以充分发挥Kafka的优势,并构建可靠的消息传递系统。文章来源:https://www.toymoban.com/news/detail-462693.html
本篇博客介绍了在实践中使用Kafka的一些技巧和最佳实践。通过深入理解Kafka的原理和灵活运用相关功能,开发人员可以更好地应用Kafka,并解决实际项目中的挑战。文章来源地址https://www.toymoban.com/news/detail-462693.html
到了这里,关于你在项目中是如何使用kafka的?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!