爬虫(又称网络爬虫,网页爬虫)是一种自动地访问网站的软件系统,它常常被用来爬取网站上的信息。爬虫可以在网站更新时自动发现新的网页,或者当网站搜索引擎索引需要更新时使用。
爬虫的工作流程通常如下:
从某个网页开始,爬虫会解析这个网页的 HTML 代码,并找出其中的链接。
爬虫会继续访问这些链接,并解析新网页的 HTML 代码,找出更多的链接。
重复这个过程,直到爬虫爬取了整个网站,或者直到达到终止条件为止。
下面是使用 Python 编写爬虫的简单教程:
安装 Python 和爬虫库。
要使用 Python 编写爬虫,首先需要安装 Python 解释器。可以在 Python 官网上下载安装包,或者使用系统自带的包管理器安装。
接下来,需要安装爬虫库。最常用的爬虫库是 Beautiful Soup,它可以方便地解析 HTML 和 XML 文档。可以使用以下命令安装 Beautiful Soup:
pip install beautifulsoup4导入库。
在 Python 代码中使用虫库之前,需要先导入库。在使用 Beautiful Soup 爬虫时,可以使用以下代码导入库:
from bs4 import BeautifulSoup获取 HTML 代码。
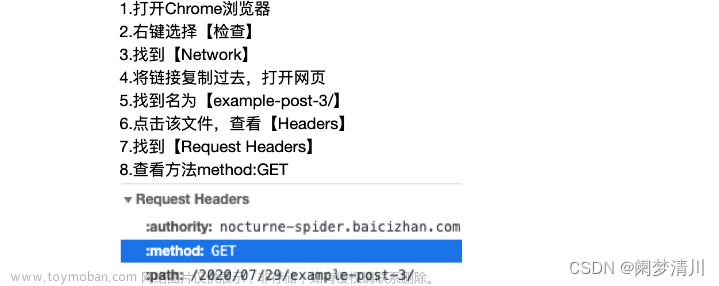
爬虫需要爬取的网页的 HTML 代码是存储在网络服务器上的。可以使用 Python 的 requests 库发送 HTTP 请求,获取网页的 HTML 代码。文章来源:https://www.toymoban.com/news/detail-462863.html
示例代码如下:文章来源地址https://www.toymoban.com/news/detail-462863.html
import requests
URL = "http://www.example.com"
page = requests.get(URL)
html_code = page.text到了这里,关于如何使用爬虫(Python篇)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![python爬取豆瓣电影排行前250获取电影名称和网络链接[静态网页]————爬虫实例(1)](https://imgs.yssmx.com/Uploads/2024/01/415693-1.png)