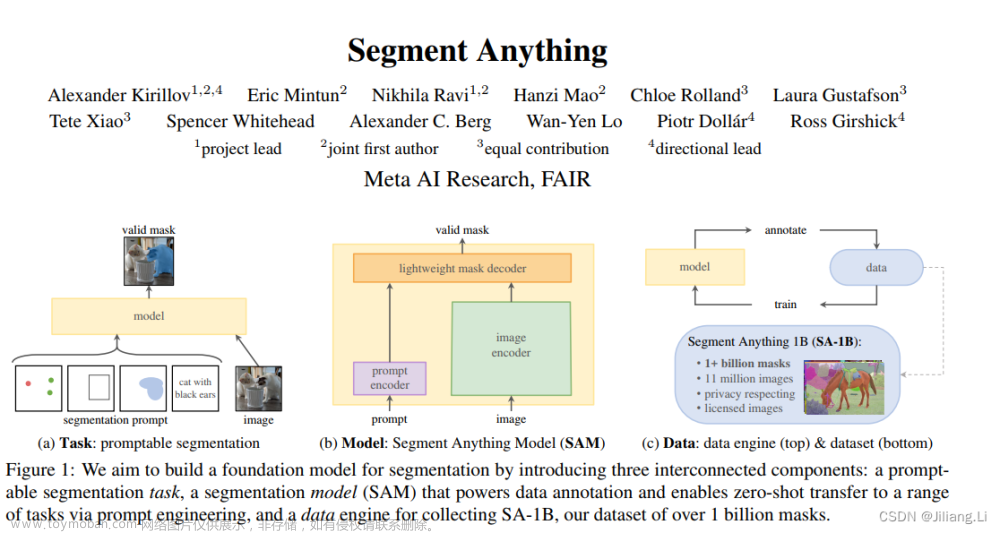
论文地址
代码下载
官网
关于Segment Anything的理解
1.人工标注过程
使用公开数据集训练,并且让人工标注团队进行标注预测的mask,该过程总共进行6次,并产生430万个mask
2.半自动标注过程
模型产生的置信度相对较高的mask,不需要人工标注,而置信度相对不高的mask,由人工完成标注。举个例子,模型分割一张图片,总共产生了10个mask,其中有5个分割得很好,这部分就作为自动标注的mask,另外5个效果不好,就进行人工标注。该过程总共进行5次,产生590万个mask
3.全自动过程
让模型完成全自动的标注。通过IoU过滤置信度不高的mask,并且进行去重操作,产生11亿的mask
关于数据集SA-1B
数据集相当大,尝试下载一个tar,大概10个G,压缩包总共可能有10T
SA-1B数据下载
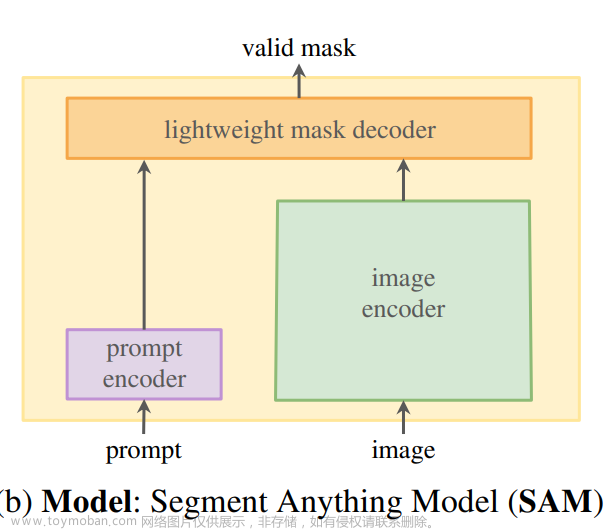
关于网络模型
网络总共有三个部分:image_encoder、prompt_encoder和mask_decoder。个人感觉网络模型还是很大的,下面是细化的网络模型也是代码结构
image_encoder部分:

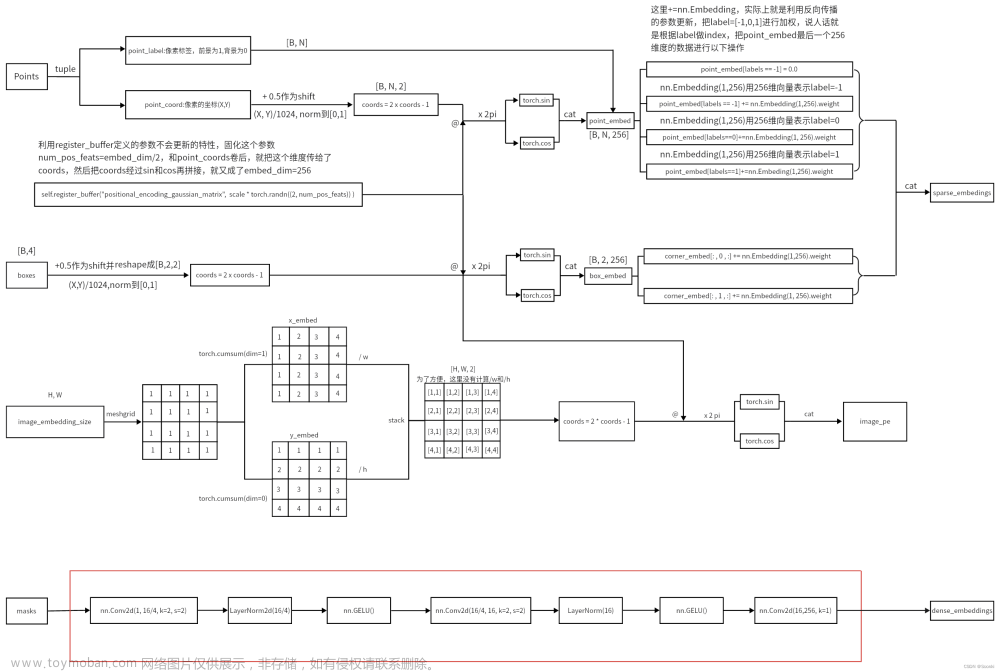
prompt_encoder部分:
 文章来源:https://www.toymoban.com/news/detail-463097.html
文章来源:https://www.toymoban.com/news/detail-463097.html
mask_decoder部分:
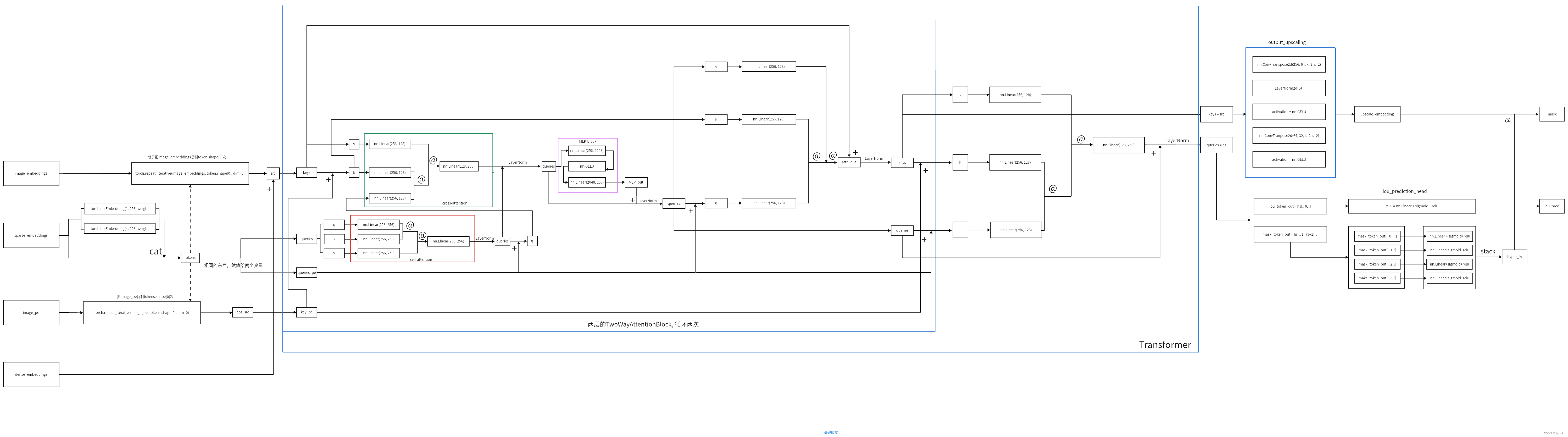 文章来源地址https://www.toymoban.com/news/detail-463097.html
文章来源地址https://www.toymoban.com/news/detail-463097.html
到了这里,关于Segment Anything模型结构解读的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!