Hadoop集群安装和搭建(从零开始超级超级详细的过程)(上)
前言
本文直接从最最最开始安装Hadoop开始讲解,省略了虚拟机安装的这部分,这里我就默认学过Liunx的各位小伙伴们已经有相关环境了。
下半部分在这里~
Hadoop集群安装和搭建(从零开始超级超级详细的过程)(下)
一、Hadoop项目结构
| 组件 | 功能 |
|---|---|
| HDFS | 分布式文件系统 |
| MapReduce | 分布式并行编程模型 |
| YARN | 运行在YARN之上的下一代Hadoop查询处理框架 |
| Hive | Hadoop上的数据仓库 |
| HBase | Hadoop上的非关系型的分布式数据库 |
| Pig | 一个基于Hadoop的大规模数据分析平台,提供类似SQL的查询语言Pig Latin |
| Sqoop | 用于在Hadoop与传统数据库之间进行数据传递 |
| Oozie | Hadoop上的工作流管理系统 |
| Zookeeper | 提供分布式协调一致性服务 |
| Storm | 流计算框架 |
| Flume | 一个高可用,高可靠的,分布式的海量日志采集、聚合和传统的系统 |
| Ambari | Hadoop快速部署工具,支持Apache Hadoop集群的供应、管理和监控 |
| Kafka | 一种高吞吐量的分布式发布订阅消息系统,可以处理消费者规模的网站中的所有动作流数据 |
| Spark | 类似于Hadoop MapReduce的通用并行框架 |
二、Hadoop安装方式
这里我们用分布式模式安装
- 单机模式:Hadoop默认模式为非分布式模式(本地模式),无需进行其他配置即可运行。访问的是本地磁盘,而不是HDFS。
- 伪分布式模式:Hadoop可以在单节点上以伪分布式的方式运行,节点既作为NameNode也作为DataNode,同时,读取的是HDFS中的文件。
- 分布式模式:使用多个节点构成集群环境来运行Hadoop。
三、VMware虚拟网络设置+Windows10的IP地址配置+CentOS7静态IP设置
(1)VMware虚拟网络设置
下面我更改了两部分地址
1)子网IP:192.168.88.0(自己原来的地址)改为192.168.10.0
2)NAT设置网关IP:192.168.88.2改为192.168.10.2







(2) Window10的IP地址配置

找到VMnet8
将IP地址改为静态地址


这里取消勾选自动获得IP地址改为静态IP
默认网关:192.168.10.2
DNS服务器改为:192.168.10.2
备用DNS服务器改为:8.8.8.8(国外DNS)或者114.114.114.114(国内DNS)
注意:有时候8.8.8.8不行就换成114.114.114.114


(3)CentOS(hadoop 100)静态IP设置
在cenntos7输入startx命令进入图形界面(安不安装图形界面都可以,为了便于后续使用我还是安装上了)
startx


进入配置文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33

进入后将DHCP协议改为静态的,并添加网关

添加刚刚配置的DNS地址解析、Hadoop100的ip地址、子网掩码
注意!!!!
这里的IP地址一定要写对,我这里写错了!!!
写错IP导致后面连接XSHell的时候浪费了好多时间找错
这里的IP应该是192.168.10.100
IPADDR=192.168.10.100

正确的IP

配置名称(别忘了配Hadoop的名字,我这里之前忘记配了,后面才想起来配,要不然后面分不清谁是谁了)
vim /etc/hostname


(5)设置名字解析
为了方便后续更改IP地址,这里配置Linux克隆机主机名称映射hosts文件
配置映射host文件
hosts文件是Linux系统中负责IP地址与域名快速解析的文件,需要配置其他的几个节点“主机名”和“IP地址”可达到快速访问集群中其他节点的效果。
vim /etc/hosts


重启虚拟机,使配置生效

重启后验证:


四、XSHELL7远程访问工具+XFTP7文件传输
(1)分别下好XSHELL7和XFTP7
因为这里我使用的是老师给的旧版本工具(和书上一样的版本,后续课程中方便使用)
如果要下载最新版本可以去官网下载

 然后分别安装:
然后分别安装:
1)先安装Xshell
这个步骤很简单,一路默认就行





2)打不开Xshell7的解决方法
如果和我一样安装的老旧版本,那就看看下面我的解决方法吧。
安装成功后一直提示“您已经在系统上安装了最新版本的Xshell 7”

解决方法:
右击我的电脑/计算机–管理

找到【flexnet licensing service】服务然后停止,右击属性,把启动类型改成禁止就可以了。


如果上面的方法还是没能解决你的问题!!!
再看看下面这个方法吧,一定可以解决!!(我试了上一个方法没成功,但是网上好多人成功了,建议小试一下)
1、试试把系统时间改成2017年(因为版本老旧,把时间改旧一点就行了,2017年以前的时间就可以,这个方法好用!!!)


打开了

2、bat文件 自动修改时间并在10秒后将日期恢复。(这个方法也行,要是觉得时间短可以把时间改久一点)
因为手动反复修改电脑日期麻烦。所以可以通过bat 文件进行修改。
新建bat文件:新建txt文件,右键重命名将“新建文本文档.txt ”改成"xshell.bat"即可。
编辑xshell.bat文件,然后复制下面的代码。
##################################begin####################
@echo off
%1 mshta vbscript:CreateObject("Shell.Application").ShellExecute("cmd.exe","/c%~s0::","","runas",1)(window.close)
title Xshell启动器
set atime=%date:~0,4%-%date:~5,2%-%date:~8,2%
#设置系统时间
date 2017-7-27
#改成你的xshell启动路径
start "" "D:\Xshell.exe"
echo 启动软件中...
ping 0.0.0.0 -n 10> null
echo 同步时间中,完成后自动关闭窗口...
date %atime%
exit
我不嫌麻烦我用的每次打开XShell手动改时间的方法,第二种方法我还没有试过,嫌麻烦或感兴趣的小伙伴可以试一试
3)新建XShell文件


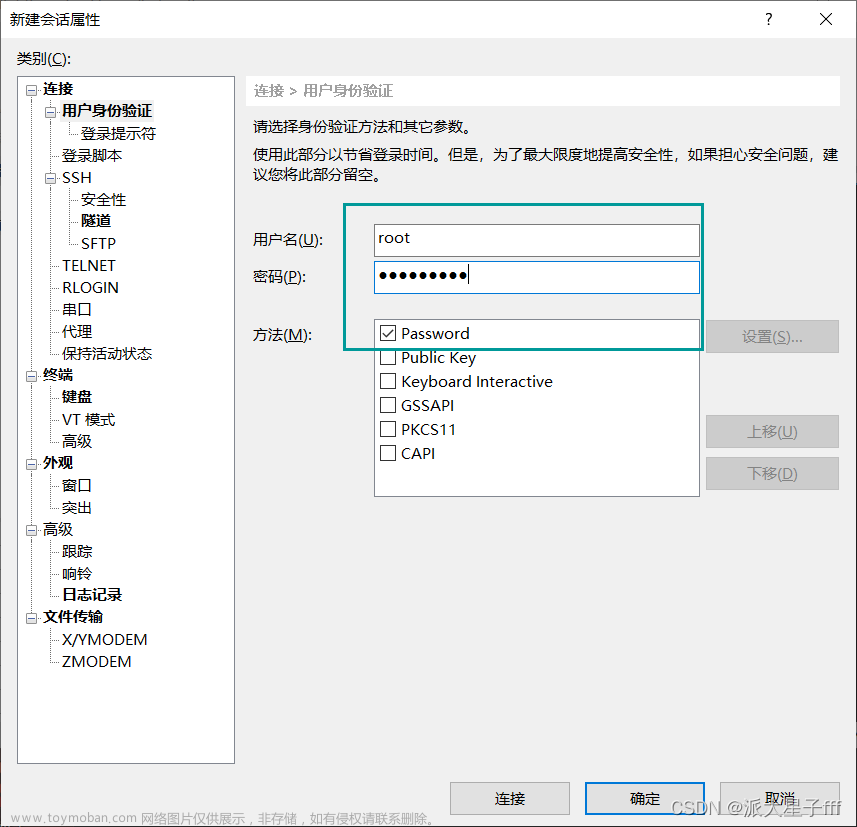

如果要进行传输
在没安装XFTP之前,点击传输

会出现以下情况

于是我们安装XFTP7
4)安装Xftp






安装好了(如果和XShell一样一直让你更新就把时间改一下就行了)

安装后即可出现此界面,可以将本机的东西传输到虚拟机里

五、基础信息配置
(1)关闭防火墙 ,关闭防火墙开机自启
关闭防火墙的命令:
systemctl stop firewalld
关闭防火墙开机自启的命令:
systemctl disable firewalld.service

(2)创建自己的新用户 ,并修改新用户的密码(这一步必须要做)
老师课上是直接创建了一个Hadoop账户,这里我随便创建一个
命令:
useradd fjr
passwd fjr
注:名字可以自定义,即
useradd newname
passwd newname

(3)卸载虚拟机自带的 JDK
发现centos7自带JDK:
java -version
 卸载原有的JDK
卸载原有的JDK
[root@hadoop100 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps

验证虚拟机自带的JDK是否删干净了,并重启(reboot)

六、克隆三台虚拟机
(1)首先关闭虚拟机才能克隆
在CentOS 7 上右键->管理->克隆:




同理克隆Hadoop103和Hadoop104

(2)配置克隆出来的虚拟机的IP地址,主机名称
分别执行以下三条命令:
vim /etc/sysconfig/network-scripts/ifcfg-ens33(Linux的网卡参数详解)
vim /etc/hostname
vim /etc/hosts




hadoop103和hadoop104配置同上,我就不一一截图了
(3)都配置好后重启,再ping百度

(4)三台克隆虚拟机都配置好了后,将XSHELL也配置好





 文章来源:https://www.toymoban.com/news/detail-463405.html
文章来源:https://www.toymoban.com/news/detail-463405.html
总结
以上就是今天要讲的内容,本文仅仅简单介绍Hadoop集群安装和搭建的上半部分,按照查找步骤和老师讲解相结合相信你也可以成功搭建Hadoop集群。文章来源地址https://www.toymoban.com/news/detail-463405.html
到了这里,关于Hadoop集群安装和搭建(从零开始超级超级详细的过程)(上)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![[Hadoop高可用集群]数仓工具之Hive的安装部署(超级详细,适用于初学者)](https://imgs.yssmx.com/Uploads/2024/02/752361-1.png)









