我们都知道爬虫时是需要代理地址介入的。使用代理可以隐藏你的真实IP地址,防止被网站封禁或限制访问。此外,代理还可以帮助你绕过地理限制,访问被封锁的网站或服务。但是请注意,使用代理也可能会带来一些风险,例如代理服务器可能会记录你的访问数据,或者代理服务器本身可能存在安全漏洞。因此,在选择代理时,请务必选择可信的、安全的代理服务提供商。
爬虫在访问目标网站时可能会面临反爬虫机制的限制,例如 IP 限制、验证码限制等等。这时候就需要使用代理来解决这些问题。
代理服务器是一种位于客户端和目标服务器之间的计算机,它可以代替客户端发出请求到目标服务器并返回响应数据。使用代理可以隐藏客户端的真实 IP 地址,从而规避针对特定 IP 地址或用户的限制。此外,使用代理还可以轮换 IP,增加访问成功率和延长爬虫过程中的存活周期。
具体来说,使用代理的优点如下:
隐藏真实IP
使用代理可以隐藏自己的真实 IP,保护个人隐私。
规避限制
某些网站可能根据 IP 地址进行限制,使用代理可以通过更换 IP 地址规避这些限制。
增加成功率
使用代理可以增加成功率,防止被目标网站识别为垃圾流量或异常流量而被拒绝访问。
防止封禁
使用代理可以轮换 IP,减少被目标网站封禁的风险,增加爬取存活周期。
需要注意的是,在使用代理时也会存在一些问题或可能引发新的反爬虫机制,例如代理质量不佳、过快的请求频率、过于集中地区的代理服务器等。因此,在使用代理时需要选择高质量的代理服务提供商,并根据实际情况合理调整请求频率和轮换代理策略。
爬虫使用代理详细教程
使用代理进行爬虫开发,可以通过以下步骤实现:
了解代理类型和工作原理:代理分为 HTTP 代理和 SOCKS 代理两种类型。HTTP 代理只能用于 HTTP 协议通信,而 SOCKS 代理支持各种应用层协议(如 HTTP、FTP、SMTP 等)。代理服务器作为客户端和目标服务器之间的中介,每次请求时会将客户端 IP 替换成代理服务器 IP,从而隐藏客户端真实身份。
获取代理IP地址:可以购买高质量的商业代理服务或者使用免费的公共代理 API;也可以自己搭建代理服务器并使用。
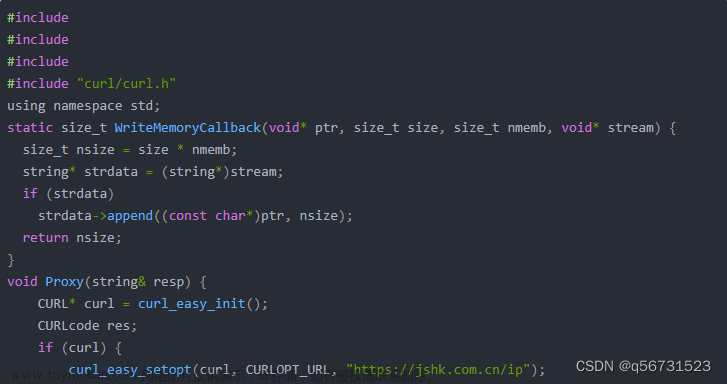
设置代理IP和端口号:在 Python 中,可以在 requests 库中设置 proxies 参数来指定代理 IP 和端口号。例如,使用 HTTP 代理的方式如下所示:
proxies = {
'http': 'http://127.0.0.1:8888', # 可以被替换成实际的代理 IP 和端口号
'https': 'https://127.0.0.1:8888'
}
response = requests.get(url, proxies=proxies)
使用随机代理:为了规避被目标网站针对特定 IP 的反爬虫玩法,可以使用多个代理 IP 在不同请求中交替使用。可以通过使用代理池等方式来实现。
proxies = get_random_proxy() # 随机获取可用的代理 IP
response = requests.get(url, proxies=proxies)
监测代理运行状态:由于代理是一个中介,多层之间链式传递,因此可能会根据不同系统或网络环境产生多种错误或异常。可以在开发过程中对代理进行测试和监测,并针对问题及时调整配置或切换代理。文章来源:https://www.toymoban.com/news/detail-463597.html
在使用代理进行爬虫开发时,请注意遵守相关法律法规,并确保使用合法、稳定和高质量的代理服务。文章来源地址https://www.toymoban.com/news/detail-463597.html
到了这里,关于爬虫时为什么需要代理?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!