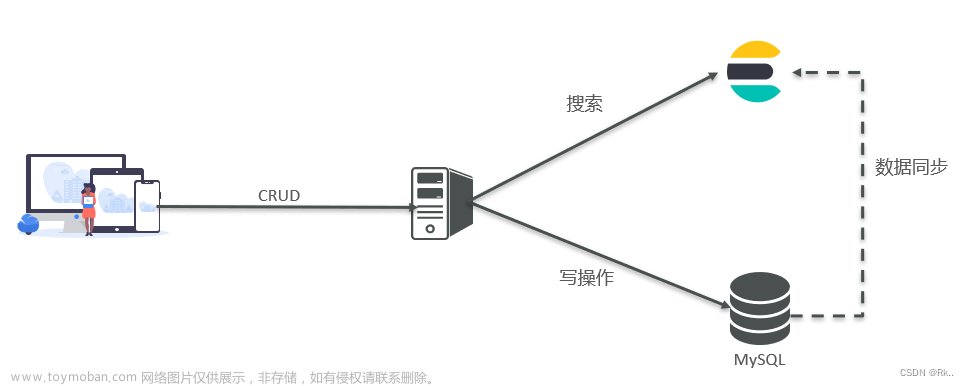
背景
《搜索引擎onesearch1.0-设计与实现.docx》介绍了1.0特性,表达式搜索,搜索schema,agg,映射等,同时附录介绍未来规划,其主要特性是文档索引,随着分布式dataX完成,技术基础已完备。
本文介绍分布式文档索引,包括tika的原理源码分析
关键词
Tika原理源码分析,内容类型识别,内容抓取,分布式datax
参考资料
《搜索引擎onesearch 1.0-设计与实现.docx》
《分布式dataX架构设计》
《分布式dataX详细(落地)设计》
规划特性与发布计划
M1 大规模/分布式文件索引
文档抓取
文档内容抓取组件,metadata(base+extras)+content
抓取组件隔离机制
索引引擎,基于分布式dataX,支持批量/增量
M2 精确搜索/多元搜索
装配/映射 增加支持query,目前已支持映射为filter
full text查询映射策略
match
match_phrase
query_string
。。。
高亮 (已有,未测试)
返回字段,目前全返回
批量操作,引擎层已实现
nested查询, nested索引已支持
springboot starter
M3 智能搜索
搜索权限,搜出就能看到
联想词
自动纠正
自动补全
onesearch总体架构

schema模块,定义索引字段,索引策略,搜索策略等,管理索引及其搜索特性
聚合搜索(agg)模块,基于schema模块,支持xml定义agg,零编码增加agg主题
查询模块,负责构建通用表达式(如,((f1=‘a’or f2=’b’)and f3=‘c’)),作为搜索输入条件
映射引擎,映射通用表达式为最优的es dsl,支持=,!=,like,in,range,prefix,not/and/or,大小括号,点(.)等操作符映射,解决es dsl难使用,难复用的痛点
抽象搜索引擎接口,无缝接入不同的搜索引擎,如,elasticsearch,opensearch,solrcloud等,更可同时使用多种引擎
同步,全量同步/增量同步,接入分布式dataX
索引组件架构
下图是面向索引组件的架构视图

索引组件实现为dataX的reader/writer,接入分布式dataX,实现高吞吐,分布式的文档索引
内容抓取组件文档遍历/内容抓取,引入tika
搜索引擎支持批量操作的索引服务,自定义索引策略,索引模式
内容抓取组件
内容抓取是索引的第一步,抓取文档属性和内容
tika分析
引入tika作为内容抓取引擎,分析一下tika原理

下面详细介绍各个模块
配置(config)
TikaConfig 两个职责,配置容器(xml格式);Detector,Parser等组件的构建工厂
TikaConfig提供默认即可用的配置,同时支持用户自定义配置
TikaConfig构建的Detector,Parser都是Composite类型对象,Composite类型对象聚合不同的实现,使用规则,策略调用具体的探测器和分析器,尽可能提高成功率

XmlLoader 对应TikaConfig的两个职能,配置容器和对象构造
XmlLoader 构建组件,特别地,支持构建复合类型组件,4个主要的方法
loadOverall 读取输入的配置,调用loadOne构建单个(非复合类型)组件;调用createComposite,传入组件集合,构建组件复合类型的实例
loadOne 构建单个组件,实际可能返回复合类型,loadOverall方法有判断处理
createComposite 具体组件具体实现,利用反射,构造函数构建对象实例
createDefault 没有输入配置,默认构建方法,使用ServiceLoader载入组件类型,构建复合类型实例
类型(mime)
Tika内容类型数据库,支持自定义;
内容类型识别,文件名模式;针对xml类型文档的root xml;magic code

MediaType 封装最原始的类型定义,type/subtype;name=value
MimeType 包装MediaType,支持不同方式识别类型,如,RootXML,Magic,扩展名
MediaTypeRegistry MediaType容器,同时管理MediaType的层次关系和别名
MimeTypes 自身是Detector实现,MimeType管理和识别
MimeTypesReader 构建MimeTypes,该类使用SAX解释处理mime xml,同时构建MediaTypeRegistry;构建Magic
MediaType层次关系作用,当该内容类型没有找到具体的分析器,可以使用上级的类型对应的分析器,尽可能分析出元数据和内容

接下来,重点分析一下Magic模型
下图是典型mime-typemagic配置

Magic 可包括多个magic匹配项match

MimeTypesReader 整个magic体系构建者,读取tika-mimetypes.xml构建MimeType/MimeTypes
Magic 属于MimeType;每个MimeType可有多个Magic;MimeTypesReader也给MimeTypes一份,即MimeTypes拥有所有的Magic
MinShouldMatchClause/OrClause/AndClause自身并不实际eval magic,负责逻辑连接Magic的所有match,分别实现最少匹配数,或,并连接逻辑,3者可复合嵌套;最终包装MagicMatch,执行MagicDetector
MagicMatch MagicDetector构建/选择器
MagicDetector 真正执行magic eval逻辑,每个MimeType对应一个
总述整个流程:
MimeTypes-->Magic-->[MinShouldMatchClause/OrClause/AndClause]-->MagicMatcher-->MagicDetector
穷举Magic找到匹配的
??? 有个优先级排除,不知道怎么定优先级
下面两图展示magic xml配置与对象关系对照,上下层and关系,同层or关系


从MimeType看,magic标签下,第一层每个match对应一个Magic,实质也是or关系


MimeTypes自身也是Detector实现,但并没有在SPI中,而是作为最后防线特定添加进默认Detector

Detector
Tika有3类探测器,内容类型探测(Detector),编码探测(EncodingDetector),语言探测(LangDetector)

与探测器类似,TaskConfig构建复合类型对象,默认实现使用ServiceLoader构建,自身也是复合类型
Metadata
Metadata文档内容属性,可以是文档自身属性,如word文档拥有者,创建日期等,也可以是taka分析获取的

Metadata 实质是key/多值map
Property 相当于DTO,传递metadata定义
Parser/SAX handler
分析器是内容抓取的核心,Detector检测到内容的具体类型,找到对应的parser,解释和抓取内容
统一的Parser接口,整体架构看,属于适配器架构模式,分析器使用对应的解释组件*,解释文档,解释结果装配为XHTML格式,client使用的SAX规范处理,使用ContentHandler处理XHTML内容
*pdf, PdfBox;office, POI;html, tagsoup

内容处理器使用装饰者模式(Decorator),被装饰者指派装饰者处理特定的xml事件,提高处理器的重用
重点分析一下主体内容处理器,BodyContentHandler
内容抓取主要关系主题内容,重点分析一下BodyContentHandler

BodyContentHandler 指派装饰者MatchingContentHandler处理sax事件,指派的sax事件类型由xpath匹配器,即Matcher确定
MatchingContentHandler 指派WriteOutContentHandler处理匹配matcher xpath的xml text,后者使用writer写入
!上面分析可知,如果文件文本量大的情况下,Writer是很关键的角色,如果使用内存缓存的实现,会出现内存溢出
Tika
Tika门面类(facade), 整合前面的组件,为用户提供开箱即用的tika
Paser库
tika提供覆盖广泛的分析器实现,从常见的html,text,到pdf,word,压缩类的,音视频类的,工业类的cad等
内容抓取组件
封装tika,分析返回metadata/content构建Document
索引组件
文档模型设计
文档模型使用metadata+内容设计,metadata遵循最大化和最细化原则
最大化:支持通用的搜索,如文件名称,创建时间,创建者,内容
最细化:支持特点类型文档专有属性搜索

对应的索引schema定义,extras文档类型特有属性,定义为nested类型索引,content定义为Text类型索引
索引器设计
搜索引擎实现索引服务,索引模式(Index Schema)+属性getter
索引器整合抓取器和索引服务即可
集成分布式dataX
文档分片遍历
接入分布式dataX,需要分片的策略,无重复无遗漏的遍历所有的文档
数据库分片
数据表的分片
b) 目录分支分片
节点分配一个分支(路径),该策略简单,但容易出现分配倾斜
c) 文件名哈希
所有节点遍历整个文档目录,只处理分派给自身的hash分片,该策略分配比较均衡,需要完整统一的文件名hash实现,能处理不同语言,特殊字符的hash计算
Reader
Reader 抓取器-》Record
Writer
Writer elasticsearch写入组件,索引服务
增量模式
支持数据表(CDC)和文件目录变更监控,另外,文件变更无关联,可多线程并行处理
技术架构
下图分布式索引技术架构

client 负责写入任务组分片;触发 worker 执行;client 可集成到管理台;作业监管,检测作业完成,清理作业环境
watcher 作业统计,输出统计;按作业分片观测和聚合计算; watcher 可集成到管理台
worker 分配分片;任务(组)执行,任务组执行统计
架构质量
高并发 高可用 高吞吐 伸缩性 健壮性
高并发/高可用/高吞吐/伸缩性 分布式dataX提供保障
健壮性 运行实例宕机,切换节点运行(failover),数据不丢失,少重复
分两个场景
数据库,文档在数据库记录
数据库分片即分页,分页合理大小,failover后整个分片重新处理;也可以使用可靠channel,failover后断点继续处理,但对存在大量大文件的情况,channel需缓存大量数据
2) 目录,文档没有数据库记录,直接读取目录
目前版本不考虑该场景
部署架构
参考技术架构,部署组件包括:
分布式调度平台,其包括zookeeper集群
redis集群
管理台,内含分布式调度平台管理api和client,其中client是dataX的Engine文章来源:https://www.toymoban.com/news/detail-463904.html
除单点,管理台部署集群即可文章来源地址https://www.toymoban.com/news/detail-463904.html
到了这里,关于搜索引擎onesearch 2.0分布式文档索引设计+tika原理源码分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!