看图聊天
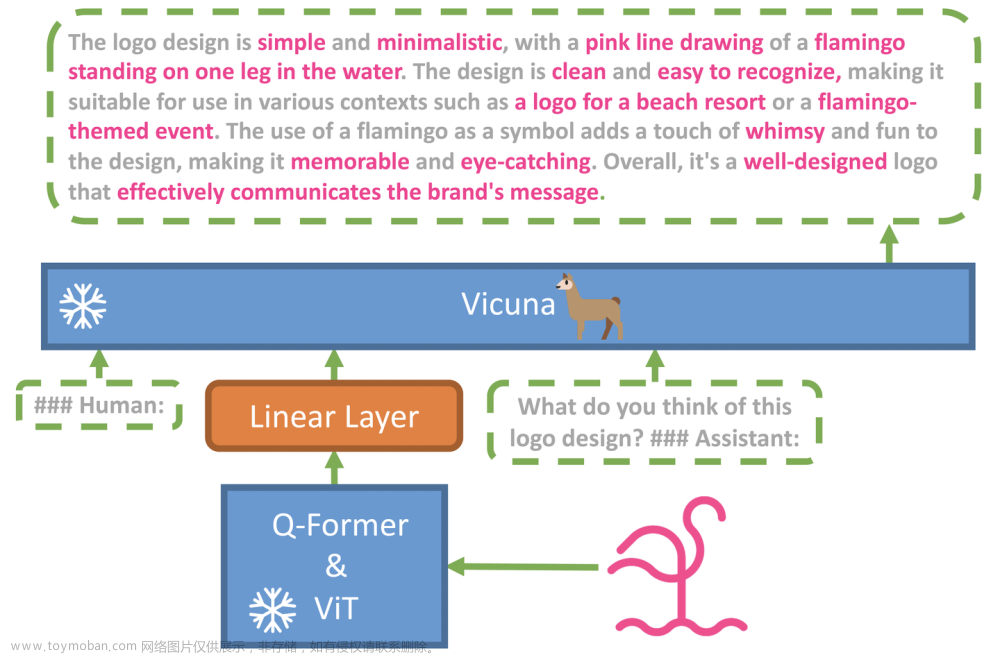
BLIP2 是 salesforce 公司开源的多模态模型,其大致的原理,可以类比看图写作,当前 AI 在文生图模式之外,也支持图生文模式,可以将照片中的核心元素识别出来。然后把这些元素作为上下文,交给 ChatGPT 类似的大语言模型进行扩展写作和对话。
BLIP2 在线试用地址为:https://huggingface.co/spaces/Salesforce/BLIP2,在线 demo 使用 BLIP2-OPT-6.7B 模型来获取图片信息,使用 BLIP2-FlanT5xxl 模型来支持文本聊天。
我们用两个实际的小任务,来测试一下 BLIP2 的能力,也顺带通过任务过程,介绍它的原理。
PPT 修改建议
某天,小辛很苦恼,在制作 PPT 时觉得 ChatGPT 只能提供内容建议,不能帮助格式优化。而他又很难把格式优化的需求通过纯文本的方式描述清楚。小辛更想直接手指着屏幕说:"这个地方和这个地方怎么对不齐啊?"
这其实就是一个多模态的内容理解和生成。我们把过程拆解一下:
- 要从截图中识别出来这是一个 PPT,并且其中有若干个挂件。
- 要从问题文本中理解出来问的是两个挂件和对齐。
- 要把两个模态的信息关联起来:问的是截图里 PPT 的哪两个挂件的对齐。
- 从 PPT 知识中推理出最终回答。
这里第一步是 CV 的图像识别能力,第二步是 NLP 的语义分析能力,第四步是 LLM 的对话能力,只要第三步能合理的生成 LLM 的 prompt,就可以构建出完整的多模态能力。
我们在 BLIP2 的在线 demo 上做一次实验。我把自己一份 PPT 截图,上传到 demo 上,开始询问PPT 上两个图表是否对齐?BLIP2 回答:没有。再第二轮问答,询问:应该如何让图表对齐呢?BLIP2 回答:把左边的图表往下挪。

全过程如截图所示,可以说表现非常惊艳。如果加强第四步,引入 ChatGPT 能力,没准还能具体介绍 PPT 操作中,左边的图表往下挪时,出现红色对齐线就算真正对齐了吧。
竞争情报分析
第二个例子,我们用一个更实际的场景。作为产品经理,竞对分析和市场情报收集是非常重要的工作。某天,我们发现友商公众号上,发布了他们公司年会的全员大合影。数出来全体员工的数量,将有助于我们推断友商的竞争投入力度。
人脸识别其实是已经非常完善的领域,直接在微信平台中,我们都能找到现成的"帮你数"小程序完成这次统计。不过这次,用完"帮你数"以后,我们打算再考验一次 BLIP2 的水准:

有趣的现象发生了:多次重复运行,BLIP2 面对"图中有多少人"这种直接询问时,都只能给出"大于 100 人"这种模糊的回答。
这到底是是 CV 阶段的问题,还是 Chat 阶段的问题?我们引入 CLIP Interrogator 这个目前最主流的图生文工具来看看。CLIP Interrogator 在主流的 stable-diffusion webui 里有内置页面可用,也可以直接使用在线 demo:https://huggingface.co/spaces/pharma/CLIP-Interrogator。将图片加载到 CLIP Interrogator 中,得到的图像是:
看起来确实不会数数?
我们换一个思路,这次给 BLIP2 的新问题是:"图中的人数是否大于 125",BLIP2 却很直接表示:NO。再问:"图中人数是否大于 120",BLIP2 也很直接表示:YES!
我们可以看到,BLIP2 实际上获取了比 CLIP-interrogator 输出更丰富的信息,但需要一定的文本输入引导,才会正确的说出来。文章来源:https://www.toymoban.com/news/detail-464476.html
可惜的是,T5 是谷歌开源的上一代大语言模型,文本生成对话能力和 ChatGPT 有较大差距。让我们期待 ChatGPT 接入图生文能力的那天吧。到时候,甚至我们可以想象,让 ChatGPT 把对话再转换成 DallE2 prompt,然后自动生成应答图片。人机之间,愉快的斗图~文章来源地址https://www.toymoban.com/news/detail-464476.html
到了这里,关于多模态应用展望——看图聊天、BLIP2的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![[BLIP]-多模态Language-Image预训练模型](https://imgs.yssmx.com/Uploads/2024/02/451104-1.png)