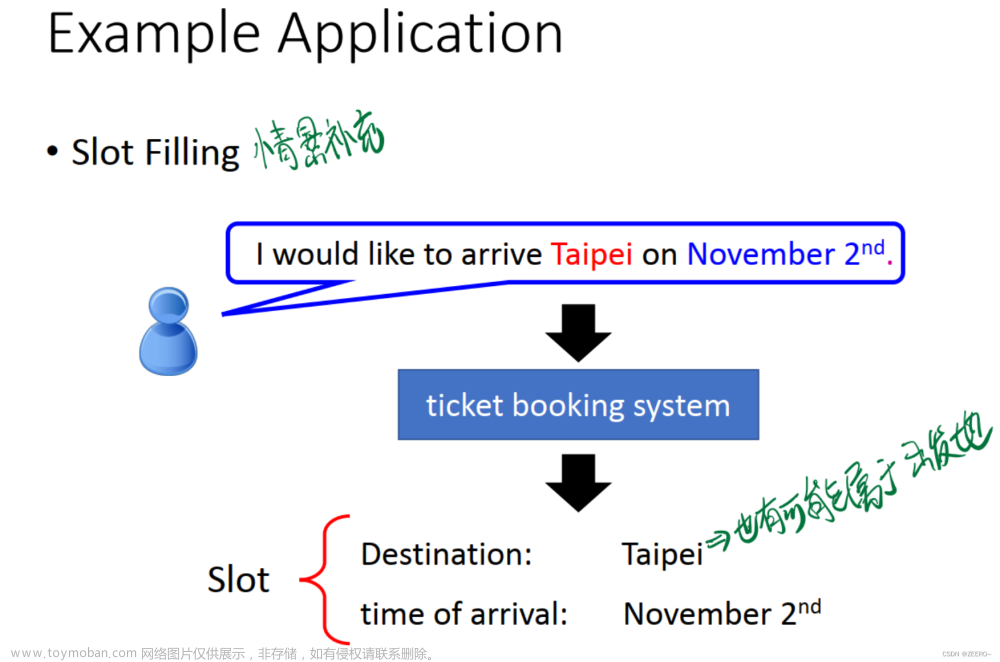
【笔记整理】图神经网络学习
一、GNN简介
参考
- 用于分析结构化数据的图神经网络 (GNN) 简介
- Graph Neural Networks: Methods, Applications, and Opportunities
- 图神经网络(Graph Neural Networks,GNN)综述
- 如何通俗地解释欧氏空间?
- 2021_金融智能下的图机器学习实践
- 2021_图神经网络加速芯片:人工智能 “认知智能”阶段起飞的推进剂
- A Gentle Introduction to Graph Neural Networks
1、图结构 & 图基础算法
- 图是一种数据结构,用来定义nodes集合以及这些节点的关系,常用于研究社交网络和物理相互作用。
- 图常应用于生活中的方方面面,可以用来描绘人为感知不到的结构:比如原子,分子,生态系统等。图结构特征表示常应用在社交网络,搜索引擎数据库,街道地图,分子,高能物理,生物化,化学混合物中。
- 图由实体和相互关系构成,可用于推理、交互、关系确定和市场研究等。
- 深度学习技术虽然能够通过不同的非线性变换和梯度下降,在计算机视觉,自然语言处理等领域取得不错的性能。但是他们缺乏对关系、原因的推理,因此在DNN中引入图结构的特征表示,因此称该网络为GNN。
- 在NLP, CV上取得不错性能的深度学习技术,通常是将数据表征到欧氏空间上,而对于有些域,它们遵循非欧几里得空间,这时图就可以作为理想的数据表征,来表示这些不同实体间的依赖和相互关系
1)引言(“非欧几何, 处理图数据的NN”)
参考图神经网络(Graph Neural Networks,GNN)综述
在过去的几年中,神经网络的兴起与应用成功推动了模式识别和数据挖掘的研究。许多曾经严重依赖于手工提取特征的机器学习任务(如目标检测、机器翻译和语音识别),如今都已被各种端到端的深度学习范式(例如卷积神经网络(CNN)、长短期记忆(LSTM)和自动编码器)彻底改变了。曾有学者将本次人工智能浪潮的兴起归因于三个条件,分别是:
- 计算资源的快速发展(如GPU)
- 大量训练数据的可用性
- 深度学习从欧氏空间数据中提取潜在特征的有效性
近年来,人们对深度学习方法在图上的扩展越来越感兴趣。在多方因素的成功推动下,研究人员借鉴了卷积网络、循环网络和深度自动编码器的思想,定义和设计了用于处理图数据的神经网络结构,由此一个新的研究热点——“图神经网络(Graph Neural Networks,GNN)”应运而生。
参考如何通俗地解释欧氏空间?
尽管传统的深度学习方法被应用在提取欧氏空间数据的特征方面取得了巨大的成功,但许多实际应用场景中的数据是从非欧式空间生成的,传统的深度学习方法在处理非欧式空间数据上的表现却仍难以使人满意。
例如,在电子商务中,一个基于图(Graph)的学习系统能够利用用户和产品之间的交互来做出非常准确的推荐,但图的复杂性使得现有的深度学习算法在处理时面临着巨大的挑战。这是因为图是不规则的,每个图都有一个大小可变的无序节点,图中的每个节点都有不同数量的相邻节点,导致一些重要的操作(例如卷积)在图像(Image)上很容易计算,但不再适合直接用于图。
此外,现有深度学习算法的一个核心假设是数据样本之间彼此独立。然而,对于图来说,情况并非如此,图中的每个数据样本(节点)都会有边与图中其他实数据样本(节点)相关,这些信息可用于捕获实例之间的相互依赖关系。
Note:欧氏空间 vs 非欧空间
欧氏空间是在内积空间上推广出来的,在实数域上进行有限维数的向量表现:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UqPpER8g-1685295716639)(file://D:\桌面\temp\temp\图神经网络\img\v2-820f1a2e7aa093e1a372565747b185ed_720w.jpg?msec=1685295711941)]
常见的非欧空间有:罗氏空间,黎曼空间(球面几何)
古希腊数学家欧几里得的《几何原本》提出了五条公设):
从一点向另一点可以引一条直线。
任意线段能无限延伸成一条直线。
给定任意线段,可以以其一个端点作为圆心,该线段作为半径作一个圆。
所有直角都相等。
若两条直线都与第三条直线相交,并且在同一边的内角之和小于两个直角,则这两条直线在这一边必定相交;
或者是,给定一条直线,通过此直线外的任何一点,有且只有一条直线与之平行;
或者是,若平面上有一条直线R和线外的一点P,则存在唯一的一条线满足通过P点且不与R相交(第五公设 - 平行公设)。
长期以来,数学家们发现第五公设和前四个公设比较起来,显得文字叙述冗长,而且也不那么显而易见。有些数学家还注意到欧几里得在《几何原本》一书中直到第29个命题中才用到,而且以后再也没有使用。也就是说,在《几何原本》中可以不依靠第五公设而推出前28个命题。因此,一些数学家提出,第五公设能不能不作为公设,而作为定理?能不能依靠前四个公设来证明第五公设?这就是几何发展史上最著名的,争论了长达两千多年的关于**“平行线理论”**的讨论。由于证明第五公设的问题始终得不到解决,人们逐渐怀疑证明的路子走的对不对?第五公设到底能不能证明?
按几何特性(曲率是几何体不平坦程度的一种衡量,该点的曲率半径是该点曲率的倒数),现存非欧几何的类型可以概括如下:
坚持第五公设,引出**欧几里得几何**。
以“至少可以引最少两条平行线”为新公设,引出**罗氏几何**(双曲几何)。
到目前为止,数学家对双曲几何中平行线的定义尚未有共识,不同的作者会给予不同的定义。这里定义两条逐渐靠近的线为渐近线,它们互相渐进(渐近线定义为如果曲线上的一点沿着趋于无穷远时,该点与某条直线的距离趋于零,则称此条直线为曲线的渐近线);两条有共同垂直线的线为超平行线,它们互相超平行,并且两条线为平行线代表它们互相渐进或互相超平行。
以“一条平行线也不能引”为新公设,引出**黎曼几何**(球面几何)。
球面几何:在平面几何(二维平面)中,基本的观念是点和线。在球面上,点的观念和定义依旧不变,但线不再是“直线”,而是两点之间最短的距离,称为测地线。在球面上,最短线是大圆的弧,所以平面几何中的线在球面几何中被大圆所取代。同样的,在球面几何中的角被定义在两个大圆之间。
这三种几何学,都是常曲率空间中的几何学,分别对应曲率为0、负常数和正常数的情况。
2)图基本概念 & 分类(“邻接矩阵, 图结构分类”)
用于分析结构化数据的图神经网络 (GNN) 简介
图是由两个部分组成的数据结构:顶点和边。它用作数学结构来分析对象和实体之间的成对关系。通常,图定义为 G = ( V , E ) G=(V, E) G=(V,E),其中 V 是一组节点,E 是它们之间的边。
图通常由邻接矩阵 A 表示。如果图有 N 个节点,则 A 的维数为 ( N × N N \times N N×N)。人们有时会提供另一个特征矩阵来描述图中的节点。如果每个节点有 F 个特征,则特征矩阵 X 的维度为 ( N × F N \times F N×F)。
不同的邻接矩阵反映不同的图


无/有向图:
无向图是常见的数据结构,常用于数据表征,其中无向边放映两节点的关系,不包含边的方向信息。但是有向边能够提供节点间的类别等级信息。
异质图(异构图):
异质图是指图中有不同类型的节点。对于这种类型的图通常使用one-hot编码将每个节点进行唯一表示。知识图谱就是一个异质图。
异质性是异质图的一个内在属性,即各种类型的节点和边。例如,不同类型的节点具有不同的特征,其特征可能落在不同的特征空间中。仍以IMDB 为例,演员的特征可能涉及性别、年龄和国籍。另一方面,电影的特征可能涉及到情节和演员。如何处理这些复杂的结构信息,同时保留不同的特征信息,是一个亟待解决的问题。
参考2021_金融智能下的图机器学习实践
早期的图机器学习研究主要针对比较简单的同质图(homogenous graph),即不区分节点和边的类型的图。但是在复杂的金融场景中,我们获得的图数据的节点或边的类型往往是多样的,我们称之为 异质图(heterogenous graph)。异质图从不同方面极大地丰富了图数据的语义信息。此外,金融场景还有丰富的事实数据,往往会通过一种特殊的异质图, 即知识图谱(knowledge graph)进行刻画。相比于一般的异质图,知识图谱除了强调实体间的拓扑关系,也强调本体层面的语义关系,其表达学习和应 用是金融场景下图机器学习的研究重点。
参考异构图注意力网络
动态图:
动态图是指图结构会随着时间而变化,它们的输入也许是动态的,节点和边在图中是不停更新的。
一般是对nodes进行添加和删除操作,而对应的节点的edges不是创建就是更新。
属性图:
属性图:graphs中的边包含权重和类型等额外信息。这些knowledge能够推进框架的发展,比如G2S编码器和关系GCN。
3)传统的图分析方法(“搜索, 路径, 生成树, 聚类”)
传统的方法大多是基于算法的,例如:
- 搜索算法,例如 BFS、DFS
- 最短路径算法,例如 Dijkstra’s algorithm, Nearest Neighbor
- 生成树算法,例如 Prim 算法
- 聚类方法,例如高度连接的组件,k-mean
这种算法的局限性在于,我们需要以一定的置信度获得图的先验知识,然后才能应用该算法。换句话说,它没有为我们研究图形本身提供任何手段。最重要的是,没有办法执行图级分类。
2、GNN处理的数据 & 应用
1)GNN能做什么(“基本分类, NLP, CV…”)
GNN 解决的问题大致可以分为三类:
节点分类(node预测):
在节点分类中,任务是预测图中每个节点的节点嵌入(类别用嵌入描述)。这种类型的问题通常以半监督的方式训练,其中只有部分图被标记。节点分类的典型应用包括引文网络、Reddit 帖子、Youtube 视频和 Facebook 好友关系。[跳转](#2)结构化数据分析(“结构化 vs 半/非结构化, 类别编码 vs 实体嵌入”))
链接预测(边预测):
在链接预测中,任务是理解图中实体之间的关系,并预测两个实体之间是否存在连接。例如,推荐系统可以被视为链接预测问题,其中模型被赋予一组用户对不同产品的评论,任务是预测用户的偏好并调整推荐系统以根据用户推送更多相关产品兴趣。跳转
图分类(全局预测):
在图分类中,任务是将整个图分类为不同的类别。它类似于图像分类,但目标变为图域。可以应用图分类的工业问题范围很广,例如,在化学、生物医学、物理学中,模型被赋予分子结构并要求将目标分类为有意义的类别。它加速了原子、分子或任何其他结构化数据类型的分析。跳转)
自然语言处理中的 GNN
GNN 广泛用于自然语言处理 (NLP)。实际上,这也是 GNN 最初开始的地方。如果你们中的一些人在 NLP 方面有经验,你一定认为文本应该是一种序列或时间数据,可以用 RNN 或 LTSM 最好地描述。好吧,GNN 从一个完全不同的角度来解决这个问题。GNN 利用单词或文档的内部关系来预测类别。例如,引文网络试图预测网络中每篇论文由论文引文关系给出的标签以及其他论文中引用的词。它还可以通过查看句子的不同部分来构建句法模型,而不是像 RNN 或 LTSM 那样完全按顺序进行。
计算机视觉中的 GNN
许多基于 CNN 的方法在图像中的对象检测方面取得了最先进的性能,但我们还不知道对象之间的关系。GNN 在 CV 中的一个成功应用是使用图来模拟由基于 CNN 的检测器检测到的对象之间的关系。从图像中检测到对象后,将它们送入 GNN 推理以进行关系预测。GNN 推理的结果是生成的图,该图对不同对象之间的关系进行建模。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QTUMXttw-1685295716643)(file://D:\桌面\temp\temp\图神经网络\img\v2-26b458f6adf32e29af5c7c85e56886f3_720w.jpg?msec=1685295711941)]
CV 中另一个有趣的应用是从图形描述中生成图像。这可以解释为几乎与上述应用程序相反。传统的图像生成方式是使用 GAN 或自动编码器生成文本到图像。与使用文本进行图像描述不同,图到图像生成提供了有关图像语义结构的更多信息。
其他领域的 GNN
GNN 的更多实际应用包括人类行为检测、交通控制、分子结构研究、推荐系统、程序验证、逻辑推理、社会影响预测和对抗性攻击预防。下面显示了一个图表,它对社交网络中的人们的关系进行建模。GNN 可用于将人们聚类到不同的社区群体中。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NUoogt3g-1685295716644)(file://D:\桌面\temp\temp\图神经网络\img\v2-6a086c613cee58c9a527f17459e56e14_720w.jpg?msec=1685295711940)]
2)结构化数据分析(“结构化 vs 半/非结构化, 类别编码 vs 实体嵌入”)
参考
-
如何用深度学习处理结构化数据?
-
用于分析结构化数据的图神经网络 (GNN) 简介
-
https://blog.csdn.net/weixin_33293612/article/details/113326092
-
https://zhidao.baidu.com/question/1862145110038725227.html
- 结构化的数据是指可以使用关系型数据库表示和存储,表现为二维形式的数据。一般特点是:数据以行为单位,一行数据表示一个实体的信息,每一行数据的属性是相同的。结构化的数据的存储和排列是很有规律的,这对查询和修改等操作很有帮助。
- 半结构化数据属于同一类实体可以有不同的属性,即使他们被组合在一起,这些属性的顺序并不重要。常见的半结构化数据有XML和JSON。
- 非结构化数据,顾名思义,就是没有固定结构的数据。各种文档、图片、视频/音频等都属于非结构化数据。对于这类数据,我们一般直接整体进行存储,而且一般存储为二进制的数据格式。
结构化数据偏爱树结构的原因:
在处理结构化数据时,人们往往更偏爱基于树的方法,而不是神经网络。原因为何?这可以从算法的角度理解——算法究竟是如何对待和处理我们的数据的。
人们对结构化数据和非结构化数据的处理方式是不同的。非结构化数据虽然是「非常规的」,但我们通常处理的是单位量的单个实体,比如像素、体素、音频频率、雷达反向散射、传感器测量结果等等。而对于结构化数据,我们往往需要处理多种不同的数据类型;这些数据类型分为两大类:数值数据和类别数据。类别数据需要在训练之前进行预处理,因为包含神经网络在内的大多数算法都还不能直接处理它们。
编码变量有很多可选的方法,比如标签/数值编码和 one-hot 编码。神经网络的连续性本质(!!!)限制了它们在类别变量上的应用。因此,用整型数表示类别变量然后就直接应用神经网络,不能得到好的结果。
结构化数据如何在神经网络中使用:
基于树的算法不需要假设类别变量是连续的,因为它们可以按需要进行分支来找到各个状态,但神经网络不是这样的。实体嵌入(entity embedding)可以帮助解决这个问题。实体嵌入可用于将离散值映射到多维空间中,其中具有相似函数输出的值彼此靠得更近。比如说,如果你要为一个销售问题将各个省份嵌入到国家这个空间中,那么相似省份的销售就会在这个投射的空间相距更近。因为我们不想在我们的类别变量的层次上做任何假设,所以我们将在欧几里得空间中学习到每个类别的更好表示。这个表示很简单,就等于 one-hot 编码与可学习的权重的点积。
嵌入在 NLP 领域有非常广泛的应用,其中每个词都可表示为一个向量。Glove 和 word2vec 是其中两种著名的嵌入方法。尽管人们对「实体嵌入」有不同的说法,但它们与我们在词嵌入上看到的用例并没有太大的差异。毕竟,我们只关心我们的分组数据有更高维度的向量表示;这些数据可能是词、每星期的天数、国家等等。
我们将一步步探索如何在神经网络中学习这些特征。定义一个全连接的神经网络,然后将数值变量和类别变量分开处理。
对于每个类别变量:
- 初始化一个随机的嵌入矩阵 m × D m \times D m×D:
m:类别变量的不同层次(星期一、星期二……)的数量
D:用于表示的所需的维度,这是一个可以取值 1 到 m-1 的超参数(取 1 就是标签编码,取 m 就是 one-hot 编码)
- 然后,对于神经网络中的每一次前向通过,我们都在该嵌入矩阵中查询一次给定的标签(比如为「dow」查询星期一),这会得到一个 1 × D 1 \times D 1×D 的嵌入向量。
- 将这个 1 × D 1 \times D 1×D 的向量附加到我们的输入向量(数值向量)上。你可以把这个过程看作是矩阵增强,其中我们为每一个类别都增加一个嵌入向量,这是通过为每一特定行执行查找而得到的。
- 在执行反向传播的同时,我们也以梯度的方式来更新这些嵌入向量,以最小化我们的损失函数。
输入一般不会更新,但对嵌入矩阵而言有一种特殊情况,其中我们允许我们的梯度反向流回这些映射的特征,从而优化它们。
我们可以将其看作是一个让类别嵌入在每次迭代后都能进行更好的表示的过程。



3)推荐系统(“链接预测”)
常见指标参考
- DCG, NDCG 公式及其实现
- NDCG
- 图神经网络(Graph Neural Networks,GNN)综述
- BPR推荐算法的简单实现
基于图的推荐系统以项目和用户为节点。通过利用项目与项目、用户与用户、用户与项目之间的关系以及内容信息,基于图的推荐系统能够生成高质量的推荐。推荐系统的关键是评价一个项目对用户的重要性。因此,可以将其转换为一个链路预测问题。目标是预测用户和项目之间丢失的链接。为了解决这个问题,有学者提出了一种基于GCN的图形自动编码器。还有学者结合GCN和RNN,来学习用户对项目评分的隐藏步骤。
推荐系统常用的指标:参考https://blog.csdn.net/shiaiao/article/details/109004341
命中率HR(Hits Ratio)
意义:关心用户想要的,我有没有推荐到,强调预测的“准确性”
H R = 1 N ∑ i = 1 N h i t s ( i ) HR = \frac{1}{N}\sum_{i = 1}^N hits(i) HR=N1i=1∑Nhits(i)
参数说明:
- N: 用户的总数量
- hits(i): 第i个用户访问的值是否在推荐列表中,是则为1,否则为0
归一化折损累计增益(Normalized Discounted Cumulative Gain,NDCG)
意义:关心找到的这些项目,是否放在用户更显眼的位置里,即强调“顺序性“
N D C G = 1 N ∑ i = 1 N 1 l o g 2 ( p i + 1 ) NDCG = \frac{1}{N} \sum_{i=1}^N \frac{1}{log_2(p_i + 1)} NDCG=N1i=1∑Nlog2(pi+1)1
参数说明:
- N:用户的总数量
- p i p_i pi : 第 i 个 用 户 的 真 实 访 问 值 在 推 荐 列 表 的 位 置 , 若 推 荐 列 表 不 存 在 该 值 , 则 p i → ∞ p_i → ∞ pi→∞
平均倒数排名(Mean Reciprocal Rank,MRR)
意义:关心找到的这些项目,是否放在用户更显眼的位置里,即强调“顺序性“
M R R = 1 N ∑ i = 1 N 1 p i MRR = \frac{1}{N} \sum_{i=1}^N \frac{1}{p_i} MRR=N1i=1∑Npi1
参数说明:
- N:用户的总数量
- p i p_i pi : 第 i 个 用 户 的 真 实 访 问 值 在 推 荐 列 表 的 位 置 , 若 推 荐 列 表 不 存 在 该 值 , 则 p i → ∞ p_i → ∞ pi→∞
4)风险控制(“金融智能”)
参考2021_金融智能下的图机器学习实践
3、GNN定义 & 比较
参考2021_图神经网络加速芯片:人工智能 “认知智能”阶段起飞的推进剂
1)GNN的应用和成果(“图计算算法 + 深度学习算法”)
深度学习已触及感知智能阶段的天花板,但仍然未具有推理能力。而超大规模图神经网络被认为是推动认知智能发展强有力的推理方法
图神经网络是近年来新兴的一种智能算法,其将深度学习算法和图计算算法相融合,取长补短,以达到更优的认知与问题处理等能力,被广泛应用于搜索、推荐、风险控制等重要领域。在发展早期,网络通常应用于图分类、节点分类和链路预测场景中。而随着学术界对图神经网络的重视程度和挖掘深度的不断提升,图神经网络开始用于解决自然语言处理、推荐、金融、集成电路等领域的问题。
阿里巴巴自主研发的大规模分布式图学习框架 Euler,已成功应用于阿里公司的营销、反作弊、广告排序等众多核心场景,大幅提升了业务效率。腾讯公司也于 2019 年开源了自研高性能图计算框架 Plato,致力于在有效时间和有限资源内完 成海量计算,已成功将 10 亿级节点超大规模图的 计算时间降至分钟级别。Euler 和 Plato 的研发团队 均在人工智能领域的顶会中发表了多篇有关图神经网络在推荐、风控等业务中应用的高水平论文。
2)GNN的定义 & 消息传递 + MLP
图神经网络能够备受学术界和工业界的青睐, 归功于其强大的数据理解能力和认知能力。
- 第一, 传统神经网络处理的图片、序列等,为欧几里得空间的数据,结构十分规则 ;而图神经网络的处理对象则为结构极其不规则的非欧几里得空间的图数据,图数据具有比图片、序列更强的数据和知识表示能力,不仅能表示样本(节点)的独立特性,还能表达相同类型甚至不同类型样本之间的联系(链接)。
- 第二,相对于深度学习算法,图神经网络能够高效地利用样本实例之间的结构性特征。图结构数据蕴含着丰富的信息,节点通过边相连接,将不同样本之间的关系等信息进行有效和充分的表达,从而最大化利用 现实图的结构性特征。
- 第三,无法有效进行关系推理是制约深度学习发展的核心因素之一,而具有处理各种关系能力的图神经网络算法则能胜任关系推理, 从而造就了图神经网络强大的认知能力。

GNN的定义 参考https://staging.distill.pub/2021/gnn-intro/
GNNs adopt a “graph-in, graph-out” architecture meaning that these model types accept a graph as input, with information loaded into its nodes, edges and global-context, and progressively transform these embeddings, without changing the connectivity of the input graph.
GNN的输入和输出都是图,GNN只对图的属性值进行更新,不会改变输入图的节点间的连接性(图的结构)。换句话说,GNN只修改关于所有节点的属性值(即特征矩阵),以及所有边的权重(即邻接矩阵,矩阵中的0仍然是0)

GNN的消息传递 参考https://staging.distill.pub/2021/gnn-intro/
GNN每一层的更新过程包括3步:聚合,变换,更新
- 1)聚合邻居节点(遍历过程),经过多层GNN层的传递,该节点可以学到K-近邻的图的全局信息,实现长距离的消息传递。
通用的GNN聚合表达式为:
- 2)对聚合节点的特征进行变换,该阶段涉及到节点,边,全局信息的消息传递过程




关于GNN的消息传递,其实最早要追溯到2017年的GCN(这里的GNN结构即为GCN结构)
图神经网络的一个最重要的分支是图卷积神经网络(Graph Convolutional Network, GCN),一般而言,图卷积神经网络采用邻域聚合方案,通过迭代聚合并变换其邻域节点的特征向量来为每个节点计算新的特征向量。图卷积神经网络的每次迭代都可以用如下公式进行表达。
其中 Aggregate 操作为每个节点进行邻居节点的遍历,聚合邻居节点的特征向量。
Combine 操作利用同一个多层感知机 (multilayer perceptron)模型对所有节点的特征向量进行变换。 N ( v ) N(v) N(v) 表示邻居节点集合, h u k h_u^k huk表示节点 u u u在第 k k k次迭代的特征向量, a v k a_v^k avk表示节点 v v v 在第 k k k 次迭代的聚合特征向量。
图卷积神经网络中的卷积过程可以理解成“feature propagation”阶段中当前节点和邻居节点的求和平均操作。参考论文Linking Attention-Based Multiscale CNN With Dynamical GCN for Driving Fatigue Detection,具体公式如下:


其中 H ( k − 1 ) H^{(k-1)} H(k−1)和 H ( k ) H^ {(k)} H(k)分别表示在第 k k k层的图卷积层的输入和输出; S = D − 1 / 2 A D − 1 / 2 S = D^{-1/2} A D^{-1/2} S=D−1/2AD−1/2,其中 A A A为图的邻接矩阵, D D D为 A A A的度矩阵(对角矩阵),$D = diag(d_1, d_2,…,d_n) , , ,d_i = \sum_j a_{ij}$。
H ‾ ( k ) = S H ( k − 1 ) \overline{H}^ {(k)} = SH^ {(k-1)} H(k)=SH(k−1)公式展开如下:
关于GNN的数学表达式为:
其中 Θ ( k ) \Theta^{(k)} Θ(k)表示MLP的线性变换层,对于多个节点来说权值 Θ ( k ) \Theta^{(k)} Θ(k)是共享的; σ \sigma σ是非线性变换层,在MLP完成对graph embedding的线性变换后(即 H ~ ( k ) = H ‾ ( k ) Θ ( k ) \tilde{H}^ {(k)} = \overline{H}^ {(k)} \Theta^{(k)} H~(k)=H(k)Θ(k))进行非线性变换(即 H ( k ) = σ ( H ~ ( k ) ) {H}^ {(k)} = \sigma(\tilde{H}^ {(k)}) H(k)=σ(H~(k))),完成当前图卷积层的graph embedding的更新。


图卷积神经网络可以用下图表示,在消息传递阶段通过带权边 * 邻居节点特征(neighbors embedding) + 当前目标节点(target embedding)的方式来提取局部特征(节点聚合即为卷积操作,可以获取图像中的局部特征),接着通过MLP来实现graph embedding的更新,接着又是下一层的图卷积层。
GNN中最主要的算子是利用图结构进行embedding传播,包括聚合邻居节点的embeddings(fusion操作)以及目标节点的embedding,并通过多个图卷积层来实现graph embeddings的更新。

GNN常用算子
因此,图神经网络包含两个主要的执行阶段, 第一个阶段是图遍历(!!)阶段,主要执行Aggregate 操作 ;第二个阶段是神经网络变换阶段,主要执行 Combine 操作。如图 2 所示,除了上述的两种主要操作,图神经网络还包含 Sample、Pool 和 Readout 这 3 种操作。
Sample 操作用于降低计算复杂度,从邻居节点集合中抽取一个子集作为新邻居节点集合;避免原图过大,经过多层GNN后,某个节点可能汇聚到1-近邻,2-近邻,…,k-近邻的整张图的全局信息,导致在信息传递时,需要保存大量的中间变量,使得梯度计算很费劲。
常见的采样有随机节点采样,随机游走等
Pool 操作用于将原始图转换为更小的图;
Readout 操作在最后一次迭代中进一步聚合所有节点的特征向量以获得整个图的表征向量。



3)图神经网络 vs 图计算算法(“遍历 + 更新, 元素更新细节不同”)
相同点:
图计算算法和图神经网络算法的相同点在于它们的每一次迭代或者层的执行都包含了遍历邻居和更新节点属性两个阶段 :
- 1)无论是图计算算法,还是新兴的图神经网络算法都通过遍历边收集 1-hop 或者多 hop 邻居节点的信息作为中间结果。
- 2)中间结果会被用于更新节点属性。
不同点:
图计算算法和图神经网络算法的不同有 3 点:
- 1)在图计算算法中,节点属性一般只有单个元素, 且在计算过程中只有值在变而元素数量不变 ;然而 在图神经网络算法中,节点属性一般是一个特征向量或者是更高维的张量数据,元素数量在数千个以 上。除此之外,不同图数据集的维度和元素个数也不尽相同,并且在执行过程中,由于神经网络的变 换,不仅节点的属性值在变,元素个数和维度也在变化(!!!)。
- 2)图计算算法收集的邻居信息是单个元素, 并对每个元素进行归约操作 ;而图神经网络算法收集的是向量或者更高维的数据,对每个元素进行 element-wise 的归约操作。
- 3)图计算算法的更新操作较为简单,一般是累加或者比较等操作,所以计算访存比低 ;然而在图神经网络算法中,每个节点的属性更新操作是进行神经网络变换,具有非常高的计算访存比。
4)图神经网络 vs 神经网络 (“输入数据,共享参数,计算规则”)
相同点:
传统神经网络算法与图神经网络算法的相同点在于两者都有训练和推断的过程。训练过程是对模型中使用的参数进行训练,利用测试样本不断对参数进行更新和校准,以获得更高的推断精度。推断过程是在获得模型的所有校准参数之后,将模型用于对新数据进行推断,以获得新数据的推断结果。
不同点:
传统神经网络与图神经网络的不同之处有如下两点 :
1)传统神经网络的输入数据一般是大小规则且结构规则的图片或者序列数据等,而图神经网络算法的输入数据通常为结构不规则的图数据。
2)传统神经网络只有使用批处理(batch)技术之后才能将神经网络的参数共享于多个样本,然而图神经网络算法天然地将同一个神经网络模型应用于所有节点的特征向量变换中。在执行过程中,模型参数具有非常高的复用率。
图神经网络的两个主要执行阶段的执行行为特征分析如下所述。图遍历阶段的执行行为极其不规则,即计算图不规则且访存不规则,主要受访存约束。而神经网络变换阶段的执行行为非常规则,即计算图规则且访存规则,主要受计算约束。
4、GNN基本分类
参考图学习综述(一):图神经网络技术与应用
1)GNN按图类型分类

图神经网络模型的建模过程可参见上图。不同工业场景下的数据有着不同的拓扑结构,将图神经网络应用到工业场景,首先需要选取合适的图类型来对数据的拓扑结构进行表征。目前常用的图类型有:
1)普通图 / 二分图
2)有向图 / 无向图
3)同构图 / 异构图:异构图的处理手段包含meta-path-based(异构对应多条meta-path)、edge-based(对异构边进行采样聚合)、relational(异构类型数量太大,可使用循环神经网络处理)和multiplex(节点间存在多重关系)
4)静态图 / 动态图各图类型对应的图神经网络模型可参见如下:

2)GNN按各模块实例分类

-
传播模块
-
采样模块
-
池化模块
二、GNN分类
GNN可以很好地应用在不同领域中含图结构的数据集上,其中GNNs的学习方式可以分成3类:监督,半监督,自监督和无监督。
- 无监督的学习方法常基于自动编码器,对比学习和随机步(学习到的表征可以用于下游中任务的学习,比如节点分类和边的预测等)的概念;
- 半监督学习方法常基于特征的嵌入编码:浅层的图嵌入(因子分解,随机步)和深层的图嵌入(自编码器和GNN)
图神经网络划分为五大类别,分别是:图卷积网络(Graph Convolution Networks,GCN)、 图注意力网络(Graph Attention Networks,GAT)、图自编码器( Graph Autoencoders)、图生成网络( Graph Generative Networks) 和图时空网络(Graph Spatial-temporal Networks)
1、图卷积网络(GCN)
参考
- LightGCN:用于推荐任务的简化并增强的图卷积网络 SIGIR 2020
- 用于分析结构化数据的图神经网络 (GNN) 简介
1)频域图卷积
参考
- GNN学习—卷积图神经网络(谱域)
- 信号处理卷积及理解图像卷积操作的意义
根据卷积定理,两信号在空域(或时域)卷积的傅里叶变换等于这俩个信号在频域中的傅里叶变换的乘积:

也可以通过反变换的形式来表达:
s
i
g
m
o
i
d
(
R
(
1
×
2
d
)
×
R
(
2
d
×
1
)
)
sigmoid(R^{(1 \times 2d)} \times R^{(2d×1)})
sigmoid(R(1×2d)×R(2d×1))

具体来说, f 1 ( t ) f_1(t) f1(t) 定义为空域输入信号, f 2 ( t ) f_2(t) f2(t)定义为空域卷积核,那么卷积操作就可以这样定义:首先将空域上的信号 f 1 ( t ) f_1(t) f1(t)转换到频域信号 F 1 ( w ) F_1(w) F1(w), f 2 ( t ) f_2(t) f2(t)转换到频域 F 2 ( w ) F_2(w) F2(w),然后将频域信号相乘,再将相乘后的结果通过傅里叶反变换转回空域,这个就是谱域图卷积的实现思路(将空域转换到频域上处理,处理完再返回)。

那么为什么要这样转换呢?为什么要将空域上的信号转换到频域上处理,最后再转回到空域呢?回想一下前面所说的经典的卷积操作具有序列有序性和维数不变性的限制,使得经典卷积难以处理图数据,也就是说对于一个3x3的卷积核,它的形状是固定的,它的感受野的中心节点必须要有固定的邻域大小才能使用卷积核,但是图上的节点的领域节点是不确定的,此外图上节点的领域节点也是没有顺序的,这就不能直接在空域使用经典的卷积。但是当我们把数据从空域转换到频域,在频域处理数据时,只需要将每个频域的分量放大或者缩小就可以了,不需要考虑信号在空域上存在的问题,这个就是谱域图卷积的巧妙之处。
2)空域图卷积
参考【Graph Neural Network】GraphSAGE: 算法原理,实现和应用
GraphSAGE是GNN中的空域模型,全称为Graph SAmple and aggreGatE,通过采样目标节点的邻居节点,聚合它们的embeddings,并与target embedding合并进行target embedding的更新,其中Aggregate操作主要有MEAN,LSTM等。
先谈谈GraphSAGE出现的原因:
GCN是一种在图中结合拓扑结构和顶点属性信息学习顶点的embedding表示的方法。然而GCN要求在一个确定的图中去学习顶点的embedding,无法直接泛化到在训练过程没有出现过的顶点,即属于一种直推式(transductive)的学习。
GraphSAGE则是一种能够利用顶点的属性信息高效产生未知顶点embedding的一种归纳式(inductive)学习的框架。其核心思想是通过学习一个对邻居顶点进行聚合表示的函数来产生目标顶点的embedding向量。
GraphSAGE算法原理:
GraphSAGE 是Graph SAmple and aggreGatE的缩写,其运行流程如上图所示,可以分为三个步骤
1)对图中每个顶点邻居顶点进行采样( N ( v ) N(v) N(v)为邻居节点采样函数)
2)根据聚合函数聚合邻居顶点蕴含的信息(AGGREGATE邻居节点的embedding + CONCAT( h N ( v ) k , h ( k − 1 ) h^k_{N(v)},h^{(k-1)} hN(v)k,h(k−1) ) )
3)得到图中各顶点的向量表示供下游任务使用
这里K是网络的层数,也代表着每个顶点能够聚合的邻接点的跳数,如K=2的时候每个顶点可以最多根据其2跳邻接点的信息学习其自身的embedding表示。K=2的邻居节点的聚合表示结果如下图所示
这里关于邻居节点采样函数 N ( v ) N(v) N(v)存在的意义:
出于对计算效率的考虑,对每个顶点采样一定数量的邻居顶点作为待聚合信息的顶点。设采样数量为k,若顶点邻居数少于k, 则采用有放回的抽样方法,直到采样出k个顶点。若顶点邻居数大于k,则采用无放回的抽样。
当然,若不考虑计算效率,我们完全可以对每个顶点利用其所有的邻居顶点进行信息聚合,这样是信息无损的。


2、图注意力网络
参考
- GAT 图注意力网络 Graph Attention Network
图神经网络 GNN 把深度学习应用到图结构 (Graph) 中,其中的图卷积网络 GCN 可以在 Graph 上进行卷积操作。但是 GCN 存在一些缺陷:依赖拉普拉斯矩阵,不能直接用于有向图;模型训练依赖于整个图结构,不能用于动态图;卷积的时候没办法为邻居节点分配不同的权重。因此 2018 年图注意力网络 GAT (Graph Attention Network) 被提出,解决 GCN 存在的问题。
3、图自编码器
4、图生成网络
三、GNN发展历程
参考
- 图神经网络(GNN)与知识推理 - video
- 图神经网络(GNN)与知识推理 - ppt
1、前期知识
1)网络表示学习的发展
网络的表示学习最早可以追溯到Hinton提出的知识的分布式表示,即一个人的知识在大脑中是分布式地存储在各个区域。

2)机器学习在网络上的应用
- Node classification : Predict a type of a given node
- Link prediction : Predict whether two nodes are linked
- Community detection:Identify densely linked clusters of nodes
- Network similarity:How similar are two (sub)networks
2、图表示学习(“Shallow”)
这里提到的图(network embedding)表示学习还不是GNN,是shallow模型
不同的网络嵌入算法的本质可以统一成矩阵分解的形式,矩阵分解相较于随机游走的好处是,减少了数据集的噪声(特征值),让邻居节点能学到更鲁棒的表示。
1)DeepWalk
DeepWalk采用随机游走 + word2Vec,解决不同节点的邻居节点不平衡的问题
通过级联softmax来对滑动窗口中的多个节点的特征进行学习

存在的问题:
- 不适用于异构图
- random walk是unbaised(概率相同)
- Deepwalk是固定长的
2)LINE,PTE,Node2Vec,GATNE
LINE:有first-order,second-order的1阶,2阶相似度目标函数
PTE:是LINE的异构网络的实现
metapath2Vec:控制异构图的Deepwalk,避免生成无意义的path
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rnxQkfoA-1685295716658)(file://D:\桌面\temp\temp\图神经网络\img\Snipaste_2021-11-12_01-48-29.jpg?msec=1685295712007)]
- GATNE:节点异构,边也异构

不同的图表示学习类型,其中GATNE支持节点&边异构的网络

3)图表示学习的本质
图表示学习(网络嵌入)的本质是矩阵分解(SVD,稀疏矩阵分解等),均可以转换成 l o g ( ) − l o g b log() - logb log()−logb的形式。由下图可以发现,当Deepwalk中的T为1时,会退化成LINE模型,即LINE模型是DeepWalk的一个特例。

NetSMF进行稀疏矩阵S的分解(构造稀疏阵S来近似邻接矩阵A),可以在7000万个nodes的数据集上跑(线性复杂度)


Prone:sparse matrix分解 + spectral propagation = O ( ∣ V ∣ d 2 + K ∣ E ∣ ) O(|V|d^2 + K|E|) O(∣V∣d2+K∣E∣) 线性复杂度

3、图神经网络(“Deep”)

1)GCN
GCN(GNN)结构包含3个操作:邻居节点(包括自己)特征聚合,归一化,线性变换,非线性变换。


2)GraphSAGE,GAT
GraphSAGE

GAT:实际上,不同的邻居节点对于当前节点的影响程度不同

3)图神经网络的挑战
challenge:non-robust
4)图神经网络学习的本质
图神经网络的本质:对嵌入向量的传播过程使用拉普拉斯算子 L L L + 信号处理
- 在pre-propagation上乘上对角阵 Q Q Q,即 L Q LQ LQ;
- 中间阶段使用normalization( N N N);
- 在post-propagation上用激活函数 σ \sigma σ处理

4、附录
讲座笔记:文章来源:https://www.toymoban.com/news/detail-464559.html

 文章来源地址https://www.toymoban.com/news/detail-464559.html
文章来源地址https://www.toymoban.com/news/detail-464559.html
四、相关文档
- https://aip.scitation.org/doi/abs/10.1063/5.0056139
到了这里,关于【笔记整理】图神经网络学习的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!