目录
HTTP 协议是什么
抓包工具
Fiddler 的下载
使用Fiddler
HTTP 请求 (Request)
HTTP 请求格式
首行
请求头(Header)
Cookie
HTTP 协议是什么
还是老样子,在讲解http 之前我们先来了解以下什么叫做 http 。
HTTP(Hyper Text Transfer Protocol):超文本传输协议。这是一个应用非常广的协议,我们随便打开一个网站,基本全都是https 开头的;例如:

等等。
https 是基于 http 的,这个后面在讲。

我们来看上图, 可以看到,http 是应用层的协议。
很多应用层协议是需要“自定义协议” ,虽然是自定义,也不是全要让我们从零开始,那得多难受啊;这时就可以基于那些大佬设计好的协议进行修改。
http 是 " 一问一答 " 的这种形式的协议,一个请求 对应 一个应答。
举个栗子:
我们在 edge 浏览器搜索 csdn :

这时浏览器就会给 csdn 的服务器发送一个请求(浏览器也可以时看作一个 http 客户端),这是csdn 的服务器,收到这个请求就返回一个 响应,像我们这个 html 、 css 、js 就是通过这个响应返回到 edge 的页面上。
要想学好 http 就需要了解http 报文协议格式,要了解 http 报文格式就必须要用到 外部工具,将http 报文格式加载出来。
也就是抓包工具,这个有很多,有一个专门针对 http 包的叫做 " Fiddler " .
抓包工具
Fiddler 的下载
也就是下面这个玩意:

官网链接放在下面:
Fiddler | Web Debugging Proxy and Troubleshooting Solutions (telerik.com)

记得下载这个 Classic 的,因为它免费!!!!!
这整个安装过程就不说了,貌似是傻瓜式安装。
在下载过程中会弹出一个对话框,选上yes 就行了,这个对话框是让你安装一个 根证书。如果选错了就需要重新下载。
安装好了首次使用要开启https ,很少有网站是直接使用 http 的;
之后打开 tools 中的 Options :

全部勾选。
如果还是有问题,或者抓不到包,再去查一查其他大佬怎么说,这里就不一一举例了。
一般来说都没啥问题。
Fiddler 本质上是一个 代理 ;
既然是代理,也就是说:客户端的所有请求都要先经过Fiddler,然后转发到相应的服务器,反之,服务器端的所有响应,也都会先经过Fiddler然后发送到客户端,基于这个原因,Fiddler支持所有可以设置http代理为127.0.0.1:8888的浏览器和应用程序。
既然是个代码就会和 你电脑上的其他代理冲突,例如浏览器插件,加速器软件等等。
如果说根据其他人的文章还是解决不了问题,其实也没关系,抓包工具不只是只有这一个,还有其他的,例如很多学校用的 wireshark 这个抓的比较杂,什么 tcp 、udp 等等。
其实chrome 也内置了一个抓包工具:

按以下 F12 这里的网络就是用来抓包的,各个抓包工具效果都一样。
使用Fiddler
我来打开这个工具的页面:

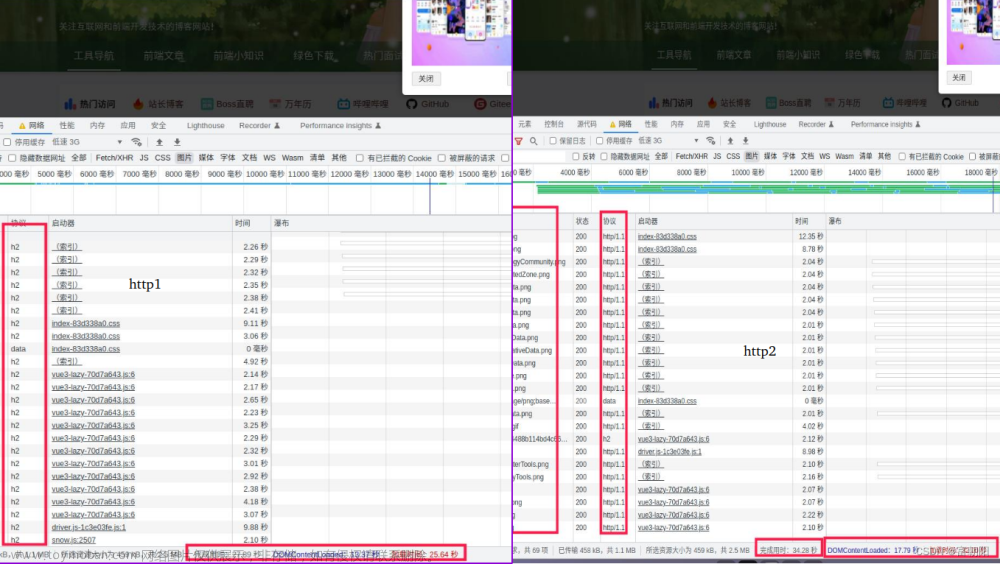
Fiddler 的左侧就是它抓到的包,这个列表是持续滚动的,其实这里我们就可以看到 浏览器(客户端)和服务器之间的请求不是一次就结束的,他们之间会交互 n 次。
我们电脑上的各个程序会偷偷的给服务器发送请求,这里会有跳出很多莫名其妙的包,看不懂很正常。
我们再重新让浏览器发送一个请求,我们点开来看看:
我们点开csdn 的注意,来看看会发送那些请求:

这里发送60 多条,那些是我们要的呢?
如何抓到我们想要的包
- 先看包的颜色,大部分的包都是黑色的,黑色的包响应的是普通的数据,蓝色的包是 html ,我们要进入csdn 的主页,所以就需要抓页面的包,也就是蓝色
- 看域名,www.csdn.net 的域名就是我们要的
- 看响应,一般都是数据长度比较大的,什么是数据长度,
就是这个bode 的大小。

我们就可以找到:

此时,我们来介绍页面的右边,右边分为两个部分,上部分是请求,下半部分是请求对应的响应。

我们点以下这个 Raw,就可以看到这个请求,我们再点一下 View in Notepad 我们放到记事本上去看。

这就是我们这次访问发出去的请求了。
我们这个请求不是天然看不懂的,我们只要理解清楚就能知道他说了啥,而那个响应是被压缩过的,这个是我们天然看不懂的。
我们再来看看请求的内容都有些啥?
HTTP 请求 (Request)
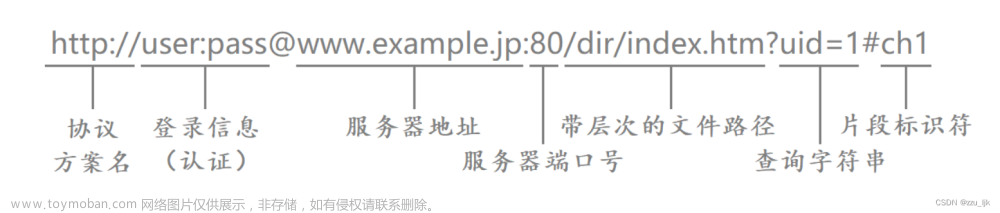
认识 url :
统一资源定位符(Uniform Resource Locator)”简称为URL。
互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它.URL 的详细规则由 因特网标准RFC1738 进行了约定:RFC 1738 - Uniform Resource Locators (URL)

HTTP 请求格式
接住了 Fiddler 抓包工具我们看到了http 的请求和响应的详细内容,我们再进一步研究这个格式的详细信息:

一个 http 请求分为了四个部分:
首行 、 header 、 空行 、body。
我们一个个来了解。
首行

下图是首行信息的含义。

http 方法不止有我们看到的 GET ,还有很多:

其中,使用的最多的就是 GET ,其次就是 POST ,余下的基本都不怎么用。
啥时候咱们能看到POST 呢?
- 登陆的时候
- 上传文件的时候
我们找个登录的包看看:

这个就是一个登录请求,为什么我密码不打码呢?
那是因为这个是加密过后的,其实呢我们国内的网络环境并不好,很多的网站都是不加密的,这样信息就不安全,跟在马路上裸奔是一个道理。
所以设置密码时最好不要老是使用一个密码,多设置几个密码更加安全。
回到正题,我们这个账号密码是不是和上面的空出了一行?
空行的后面就是 body 部分,账号密码就放在 body中,而之前的 GET 方法时没有 body 部分的(或者是说 body 为空)。
👺下面是个经典的面试题:
GET 方法 和 POST 方法 的区别:
首先需要盖棺定论:二者没有本质的区别;你非要在使用GET 的时候使用 POST 或者反过来,这搜可行(GET 的body 是空的这并不绝对,非要带个body 也ok)
但是在使用习惯上有区别:
- GET 习惯上用来获取一个数据;POST 习惯上用来提交一个数据
- GET 一般来说没有body ,携带的数据放在 URL 中,POST 一般有 body
- GET 一般设计为幂等的(只要输入一定,输出就一定),POST 没有这种要求
- GET 可缓存的(前提是幂等),而POST 不能
- GET 请求可以被浏览器收藏,POST 不能(这个是浏览器的一个优化)
我们来稍微讲讲这个可缓存的。
假设,我们客户端向浏览器发送一个 计算5 的阶层 是多少, 服务器计算完并把结果120 发送给客户端;客户端就将这个结果进行保存,下次再次请求计算这个结果的时候,我们就不需要把请求发送给服务器了,我们直接从本地中拿到(不确定是内存还是硬盘)。
为什么非要这个缓存呢?不要不可以吗?
对于一些我们常访问的网站:比如 csdn
我们这个网站上有很多css 样式吧,也有很多图片啊等等,我们把这些缓存在本地上,那么下次的时候是不是就可以不用重新加载了,css 样式等经常不会变的东西,每次都需要重新加载太浪费资源了,同时也可以减轻服务器的压力。
如果某些东西更新了,我们可以根据版本号来确定是否需要重新加载(具体的还得看人家公司是怎么写的)。
URL 上面介绍过了,就不重复了。
版本号:

如上图,左边是返回的响应,右边的是发出的请求;
我们最常见的就是 1.1 版本,除此之外还有 1.0 ; HTTP/2.0; HTTP/3.0。
但是1.1 是目前主流的,2.0,3.0的版本在此基础上做了很多拓展功能,但是可能还存在一些问题,用的人还不过多,这里就不介绍了。
请求头(Header)

我们在图可以看见很多键值对,每个键值对都占一行,每个键值对之间用 " : " 来分割;每个键值对可以有多行,会用空行表示结束,例如下图:

header 的键值对大都是HTTP规定好的,也可以是自定义的。(第一张就是规定好的,第二张应该自定义的,自定义的一般来说都是看不懂的,只有人家自己才看得懂)
Host
我们这里还有一个 Host 属性,表示请求要访问的位置,不仅仅是域名,也可以是端口号。

看看前面,我们之前的 URL 中不是已经写了域名了吗,为什么还要在请求中又写一次呢,这不是多此一举吗?
大多数情况下,URL 中的域名和Host 中的值是一致的,但又少数情况下是不一致的,
比如:
我们访问服务器,通过代理来访问就有可能两个域名不一样,URL 是当前目标,而Host 是最终目标。
Content-Length
表示 body 中的数据长度
Content-type
表示 body 中的数据格式。
常见格式如下:
- application/x-www-form-urlencoded: form,例如:

- multipart/form-data: form 表单提交的数据格式(在 form 标签中加上enctyped="multipart/form-data") . 通常用于提交图片/文件
- application/json: 数据为 json 格式,如:

如果是请求的Content-type 1 和 4 的格式最多,如果是作为响应还有其他的格式,这里就不一一举例了。
User-Agent (简称 UA)
表示浏览器/操作系统的属性.


Referer
表示这个页面是从哪个页面跳转过来的,例如:
https://v.bitedu.vip/login
如果直接在浏览器中输入URL, 或者直接通过收藏夹访问页面时是没有 Referer 的.
Cookie
Cookie 中存储了一个字符串, 这个数据可能是客户端(网页)自行通过 JS 写入的, 也可能来自于服务器(服务器在 HTTP 响应的 header 中通过 Set-Cookie 字段给浏览器返回数据).
往往可以通过这个字段实现 "身份标识" 的功能
每个不同的域名下都可以有不同的 Cookie, 不同网站之间的 Cookie 并不冲突
我们随便抓个cookie 来看看:

这个cookie 也是由键值对组成的,键值对之间是由" ; "隔开的,键与值之间是由 = 分割的。
这个键值对是由程序员自定义的,只有内部人员才能看得懂;http 很多地方是无法进行修改的,只有这些自定义的地方才是http 留给程序员拓展的东西。
cookie 的本质是浏览器在本地存储,用户自定义数据的一种关键机制
如何查看已经存储的cookie :

cookie 与服务器之间的关系:

我们前面说到cookie 的本质是浏览器存本地数据,储既然需要存储,那么如何存储呢?
直接让浏览器在本地进行存储肯定是不行的,如果是黑客入侵,就直接给你电脑夺舍了。
浏览器虽然禁止了直接访问硬盘,浏览器提供了Cookie 机制,允许网页往浏览器存储一些自定义的键值对;这些数据通过浏览器提供的api,写入特定的文件中。
不同的网站有不同的 cookie ,相同的网站共用一个 cookie。
cookie 从哪来
假设我们把一个cookie 删了,又要再次访问这个网站,此时浏览器就对该服务器发出一个请求,此时电脑上没有这个cookie ,那么请求中就会携带Set-Cookie 字段,服务器就会把cookie 的键值对返回给浏览器,再然后该cookie 就被保存在特定的文件夹中。
cookie 到哪去
cookie在浏览器中只是充当一个cache ,真正需要它发挥作用还是得在服务器,那么在下次发出请求的时候,就会把这个cookie 放在请求中发送出去。
cookie 的作用
cookie 是浏览器本地储存数据(可以是任何数据)的一种机制。
由于cookie 的存储空间有限,一般也不会太大。
cookie 最经典的作用就是存储用户信息,只要登录之后,就可以现实你的各个信息,这些信息值存储在服务器中的。文章来源:https://www.toymoban.com/news/detail-464939.html
我们来举个例子:就拿医院来说;去医院,医院会发就诊卡,办理这个就诊卡就需要用户信息;每次医生看病就会让你刷一下就诊卡,此时的就诊卡就相当于一个 cookie ,一刷卡就会显示你的基本信息,病例等等。 这些信息是存在医院的系统里的,就诊卡是存在用户自己手里的。此时,这里的 cookie 只是拿来验证一下,真正的信息还是在服务器中的!!文章来源地址https://www.toymoban.com/news/detail-464939.html
到了这里,关于网络原理(六):http 协议(上)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!