前言
AI的风已经吹了有一阵子了。看着各种头条的AI图片,各种群里的惊艳美女,是不是和我一样也想自己去实操一番呢?说起AI生图领域,目前较火的应该是Midjourney和Stable Diffusion了吧。大概看了下两者区别,Midjourney只能在互联网上使用,而且除了有限的免费次数外就需要付费了。Stable Diffusion呢,可以本地部署,听着挺有吸引力,但一看配置,16G内存以上?!GPU?!看着配置明显不够的笔记本,有点劝退。还好,只要可以魔法上网还是有方案的。那就操练起来吧。
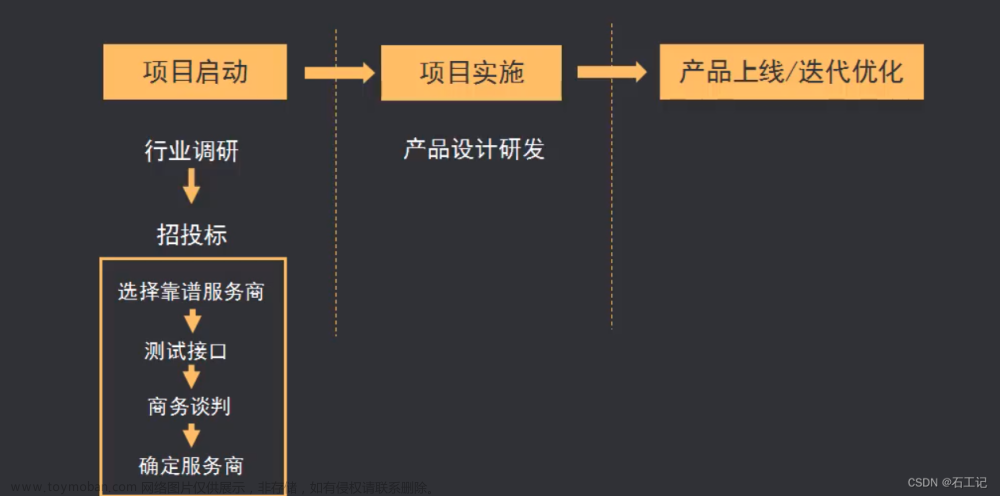
一、需要准备什么?
荐于本次完整实操的是基于colab的环境,需要魔法上网,当然准备好一个Google帐号就够了。
・google帐号(有了它使用colab无压力)
・Stable diffusion WebUI (实际使用的项目了,github上可查)
二、实操步骤
1. 打开colab
不知道colab的可以自行搜索,网址如下:
https://colab.research.google.com/?hl=cn
※不要在意界面的语言,如上网址本已指定ht=cn,但不知为何,界面语言没变过来,于是将其显示为英文了。相信即使是中文界面,聪明如你定能对照着可以操作下来的。
2. 新建Notebook
在colab主界面,我们选择 【Edit > New notebook】 来新建一个ipynb文件。
3. 设定里选择GPU
新建ipynb文件之后,通过【Edit > Notebook settings】来跳转到下一界面。
在下一画面内第一个下拉框从【None】变更成【GPU】点击【Save】保存。
4. 命令录入
上面操作完之后跳回到新建好的ipynb文件页面了,这时将命令录入到第一个代码框内即可。
具体的命令如下:
!git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
%cd /content/stable-diffusion-webui
!wget https://huggingface.co/nuigurumi/basil_mix/resolve/main/Basil_mix_fixed.safetensors -O /content/stable-diffusion-webui/models/Stable-diffusion/Basil_mix_fixed.safetensors
!wget https://huggingface.co/stabilityai/sd-vae-ft-mse-original/resolve/main/vae-ft-mse-840000-ema-pruned.safetensors -O /content/stable-diffusion-webui/models/VAE/vae-ft-mse-840000-ema-pruned.safetensors
!python launch.py --share --xformers --enable-insecure-extension-access
这些命令是在运行一个名为 “stable-diffusion-webui” 的Python项目。具体而言,它们执行以下操作:
・git clone:从GitHub上克隆名为 “stable-diffusion-webui” 的项目。
・%cd:将当前目录更改为 “stable-diffusion-webui” 目录。
・wget:从huggingface.co下载两个预先训练好的模型,其中一个称为 “Basil_mix_fixed.safetensors”,另一个称为 “vae-ft-mse-840000-ema-pruned.safetensors”,并将它们保存到特定目录下。
・python launch.py:启动Python脚本“launch.py”,它可以启动一个Web界面,用于探索这两个模型的图像生成能力。其中,参数–share用于启动共享模式,–xformers用于启用xFormers加速,–enable-insecure-extension-access用于允许不安全的扩展访问。
5. 启动执行
如上面简单几步就可以开始启动脚本了。点击上述代码左侧的按钮即可执行脚本。
执行需要一些时间,头一次时间长一点,不过还好不是很慢,一会儿就好了。
※如果点击执行后没有出现上述两个URL的话,看是不是和我的报错一样,一样的话请参照我后面的【三、故障排除】。
点击两个网址中的 public URL即下边那个网址,就会跳转到一个新画面。
6. 界面语言设定
由于此界面全是英文,可以考虑将其设定为指定的语言。在这里将其设定为中文简体。如果不需要变更界面语言的话,直接跳过本节。
・step1: 画面内在选择【Extensions】标签
・step2: 在下面变更后的显示标签中选择【Available】标签
・step3: 将【localization】复选框前的勾给勾掉
・step4: 再点击【Load from:】大按钮
・step5: 接下来 Ctrl + F 页面内查找【cn】找到中文包【Install】
・step6: 滚到最上面找到与【Extensions】标签页并列的【Settings】标签页,点击。
・step7: 在此Settings页内左侧点击【User interface】
・step8: 滚到最下面点击右下角的刷新按钮后,下拉框内选择【zh_CN】
・step9: 点击最上面的【Apply settings】
・step10: 然后关闭当前浏览器标签页,再如上一节点击public URL,再次进入后已经是中文界面了。
7. 选择模型
如最开始的命令,我们知道,我们下载了两个预先训练好的模型,我们这次想使用vae-ft-mse-840000-ema-pruned.safetensors,可以通过如下步骤选择模型。
・step1: 画面内在选择【设置】标签(※这时已经是中文界面了噢)
・step2: 左侧条目里选择【Stable Diffusion】
・step3: 同样刷新后模型的VAE(SD VAE)选择【vae-ft-mse-840000-ema-pruned.safetensors】保存设置
8. 咒语生成美少女
经如上设定,界面设定好了,模型也选择好了,我们可以生成美少女的图片了。
主界面切换到【文生图】标签页,录入咒语,点击【生成】按钮。
至于说是什么样的咒语,可以自行网上搜索,应该很多。以下两组咒语摘自网上,用于此次测试部署。
【提示词】
super fine illustration, an extremely cute and beautiful girl, highly detailed beautiful face and eyes, look at viewer, cowboy shot, beautiful long hair, solo, dynamic angle, beautiful detailed ice dress with frill, ice castle in background, blue tone
【反向提示词】
flat color, flat shading, nsfw, retro style, poor quality, bad face, bad fingers, bad anatomy, missing fingers, low res, cropped, signature, watermark, username, artist name, text
【提示词】
super fine illustration, an extremely cute and beautiful girl, highly detailed beautiful face and eyes, look at viewer, cowboy shot, beautiful hair, solo, dynamic angle, beautiful detailed long crystal dress with many frill, dark background, there are many luminous crystals in background, dynamic angle
【反向提示词】
flat color, flat shading, nsfw, retro style, poor quality, bad face, bad fingers, bad anatomy, missing fingers, low res, cropped, signature, watermark, username, artist name, text
9. 查看效果
经过极短的时间即可生成图片,可根据图片下方按钮对图片进行保存等操作。
两组咒语分别执行了两资生成了四张图片。效果还不错吧。


三、故障排除
1. CUDA 版本不一致
在上述步骤第5步里启动执行脚本后,如果一直没有出现两个URL,而最后一行如下面错误所示:
RuntimeError: Detected that PyTorch and torchvision were compiled with different CUDA versions. PyTorch has CUDA Version=11.7 and torchvision has CUDA Version=11.8. Please reinstall the torchvision that matches your PyTorch install.
出现这种错误提示表示 PyTorch 和 torchvision 编译时使用的 CUDA 版本不一致。建议重新安装与你的 PyTorch 版本相匹配的 torchvision。
解决方法:
在ipynb文件中新开一行代码,记入如下脚本执行成功即可。
!pip uninstall torchvision
!pip install torchvision==0.15.1
插曲:
如果想要确认安装之后的torchvision版本的话,使用如下脚本可以确认torchvision版本。
import torchvision
print(torchvision.__version__)
我在上述确认版本的脚本执行过程不如出现了报错,如下:
ImportError: cannot import name 'is_directory' from 'PIL._util' (/usr/local/lib/python3.9/dist-packages/PIL/_util.py)
这个错误通常是因为使用的是 PIL 库的旧版本,而代码中使用了 PIL 的一个已经弃用的函数 is_directory。在较新的版本中,这个函数已被删除。
解决这个问题的方法是更新 PIL 库到最新版本。可以使用以下命令在终端中升级 PIL 库:
pip install --upgrade pillow
执行该命令后有如下提示:
依照提示点击结果输出中的【RESTART RUNTIME】按钮。
再次执行版本确认。此版本没有问题。
再次执行第5步的脚本启动。正常输出了两个URL。
2. xFormers在构建时没有包括CUDA支持
如果出现了URL,而且跳转界面都完好,但是点击【生成】按钮之后一直没反应,没有生成图片,则可以去看脚本输出,是否如我一样有相同的启动内容输出。
<省略>
xFormers wasn't build with CUDA support
<省略>
我们翻回该命令的启动日志输出(如果没有了,点击左侧按钮停止后再启动就是了),看启动过程中是否有如下输出:
WARNING[XFORMERS]: xFormers can't load C++/CUDA extensions. xFormers was built for:
PyTorch 1.13.1+cu117 with CUDA 1107 (you have 2.0.0+cu117)
Python 3.9.16 (you have 3.9.16)
Please reinstall xformers (see https://github.com/facebookresearch/xformers#installing-xformers)
Memory-efficient attention, SwiGLU, sparse and more won't be available.
Set XFORMERS_MORE_DETAILS=1 for more details
上述警告提示xFormers无法加载C++/CUDA扩展,因为它是使用不同的CUDA和Python版本构建的。建议重新安装xFormers并确保使用与警告中显示的版本相同的CUDA和Python版本。可以在xFormers的GitHub页面上找到安装说明和要求,也可以参考警告消息中提供的链接。
解决方法:
执行如下命令,用pip工具安装或更新名为xformers的Python包。
!pip install -U xformers
安装成功。再次跳转界面录入咒语点击【生成】按钮,没有问题。文章来源:https://www.toymoban.com/news/detail-464979.html
总结
以上,就是今天学习到的部署借助colab的GPU跑起来Stable diffusion webUI 项目生成美少女图片的内容。其实在UI界面里,可设置的项目很多,需要完整理解掌握 Stable diffusion 还是需要花费一些工夫的。但好在这些都免费啊!操练起来吧!文章来源地址https://www.toymoban.com/news/detail-464979.html
到了这里,关于【实操演练】平民玩家借力AI生成美少女图片的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!