DataHub调研&数据血缘
1. DataHub? 阿里的数据工具datahub?
回答: 不是
DataHub是由Linkedin开源的,官方喊出的口号为:The Metadata Platform for the Modern Data Stack - 为现代数据栈而生的元数据平台。官方网站A Metadata Platform for the Modern Data Stack | DataHub。目的就是为了解决多种多样数据生态系统的元数据管理问题,它提供元数据检索、数据发现、数据监测和数据监管能力,帮助大家解决数据管理的复杂性。
DataHub基于Apache License 2开源,采用基于推送的数据收集架构(当然也支持pull拉取的方式),能够持续收集变化的元数据。当前版本已经集成了大部分流行数据生态系统接入能力,包括但不限于:Kafka, Airflow, MySQL, SQL Server, Postgres, LDAP, Snowflake, Hive, BigQuery。
源码仓库地址:
- GitHub - linkedin/datahub: The Metadata Platform for the Modern Data Stack 该仓库包含DataHub前端和后端服务的完整源码。(DataHub采用先进的前后端分离架构)
- https://github.com/linkedin/datahub-gma 该仓库包含DataHub元数据搜索和发现服务GMA
当前支持的数据栈列表:
| 数据源名称版 | 当前支持状态 |
|---|---|
| Athena | 支持 |
| BigQuery | 支持 |
| Delta Lake | 计划支持 |
| Druid | 支持 |
| Elasticsearch | 支持 |
| Hive | 支持 |
| Hudi | 计划支持 |
| Iceberg | 支持 |
| Kafka Metadata | 支持 |
| MongoDB | 支持 |
| Microsoft SQL Server | 支持 |
| MySQL Oracle PostreSQL | 支持 |
| Redshift | 支持 |
| s3 | 支持 |
| Snowflake | 支持 |
| Spark/Databricks | 部分支持 |
| Trino FKA Presto | 支持 |
市面上常见的元数据管理系统有如下几个,后面章节进行比对:
a) linkedin datahub
b) apache atlas
c) lyft amundsen
2. 主要功能
DataHub是端到端的元数据发现工具,可以帮助数据管理者挖掘其公司数据的价值。
端到端搜索和发现
1)在数据库、数据湖、BI平台、ML特征存储、工作流配置等数据资产中进行[元数据集中查询搜索]
比如:在DataHub里面搜索"health",从所有的元数据(BigQuery数据集、DataHub Tags/Users等)中,得到了所有相关结果,可以在结果中,点击查看相关的结果。
2)通过跨平台、数据集、管道的[血缘关系追踪],轻松理解数据的端到端旅程
3)通过线性血缘图,快速获取相关实体的上下文
4)获取数据集准确性和相关性的确切信息
比如:DataHub针对流行的数据仓库平台提供数据集合的详细信息浏览和实用信息统计,让数据从业者更容易理解数据的形态。
构造坚实的文档和标签基础
1)通过API或DataHub UI获取并维护公司的知识库
随着我们日常操作中定义和用例的丰富,DataHub可以轻松地更新和维护文档。除了通过GMS管理文档外,DataHub通 过UI界面提供丰富的文档和外部支持链接操作界面。
2)通过API或DataHub UI创建和定义新的标签(tag)
在DataHub中可以通过GraphQL API轻松的创建和添加任何实体标签,这样随着时间的推移,实体的属性回越来越丰富。当有一天我们想要查看某一标签的相关实体信息时,只需要在标签位置点击该标签,就会将所有相关的实体数据 列出来。
触手可及的数据治理
1) 快速将资产所有权分配给用户或用户组
2) 使用策略管理细粒度访问控制
DataHub管理员可以创建相应的策略,来定义谁可以在哪些资源上执行什么样的活动。在指定策略时,同时管理员还可以进行如下指定操作:
- 平台型策略 - 最高级别的DataHub平台权限,比如用户管理、组管理和策略管理等
- 资源型策略 - 指定资源类型,比如数据集、看板、管道等
- 权限策略 - 选择权限范围集合,比如编辑用户、编辑文档、编辑链接等
- 用户或组策略 - 分配相关的用户或租;比如可以直接将策略分配给资源使用的用户,而不必太关注他属于哪个组
元数据质量和使用分析
通过DataHub可以对元数据进行深度挖掘。DataHub提供的分析视图可以清晰的展示元数据相关的操作信息,比如用户权限分配的频繁度、本周活动用户、常用的搜索条件及活动等。
3. 架构
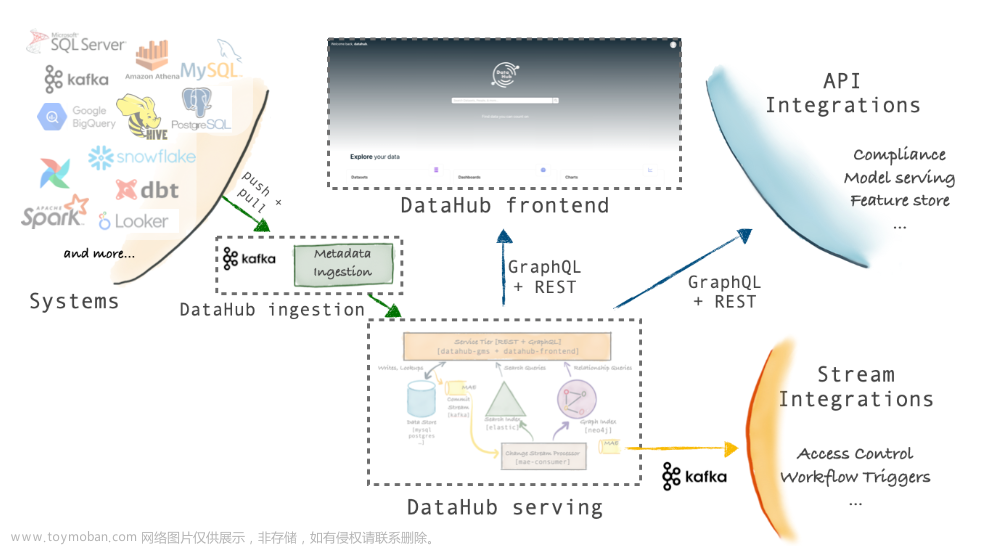
Datahub的采用了model-first的架构理念,通过提供一个通用的元数据管理模型,再通过插件的方式集成各种数据平台,进行元数据的导入。整体的架构如下:
该架构的优点有2个:
-
- 元数据同步方式多样:可以使用Rest、GraphQL API-s、Avro API(从Kafka消费元数据)
-
- 数据平台的元数据更改可以实时的被同步到Datahub;在Datahub对元数据进行更改,可以实时的在数据平台进行更新
3.1 Ingestion Framework的架构
DataHub支持Push、Pull、同步和异步的元数据导入
3.1.1 Metadata Change Event(MCE)
MCE是元数据导入的中心。各种数据平台的元数据的实时变更,发送到MCE(由Kafka负责),这是一种异步元数据同步。也可以直接将数据平台的元数据通过HTTP方式发送到Datahub,这是一种同步元数据导入
3.1.2 Pull-based Integration
Datahub通过基于Python的metadata-ingestion系统,从不同的数据平台Pull元数据。然后将元数据Push到Kafka(MCE)或直接Push到Datahub。还可以从Airflow调度系统同步元数据和血缘关系
3.1.3 Push-based Integration
可以向Kafka Push一个元数据变更事件(MCE),或通过HTTP Push数据到Datahub。DataHub还提供了一些简单的Python emitters ,将其集成到我们自己的系统中,以便获取我们自己的系统元数据
3.1.4 Applier(mce-consumer)
消费Kafka的元数据消息,并转换成Datahub的元数据储存格式,再同步到Datahub
3.2 Datahub Serivce Tier架构
主要的服务是datahub-gms,它提供了一个REST API和一个GraphQL API对元数据进行CRUD操作,还提供支持二级索引、全文搜索的搜索查询,和血缘关系的图数据库查询API
3.2.1 Metadata Storage
储存元数据的数据库,如Mysql、Postgresql、Couchbase
3.2.2 Metadata Commit Log Stream(MAE)
当将元数据更改更新到Metadata Storage中,Datahub Service Tier还会将该更改事件发送到Kafka
3.2.3 Metadata Index Applier (mae-consumer-job)
mae-consumer-job消费MAE(Kafka)中的数据,然后将更改事件流更新到elastic和neo4j,并生成相应的search index和graph index
3.2.4 Metadata Query Serving
基于主键的元数据读取,是从Data store数据库读取的。基于二级索引的元数据读取和全文搜索的元数据读取,是从elastic数据库读取的。基于血缘关系的图查询是从neo4j数据库读取的
4. 内部模块
4.1 Metadata Strore
用于储存Metadata 的Entities和Aspects(切面是一组属性的集合)。同时提供插入和查询API。其中储存由MySQL、Elasticsearch、Kafka负责。Rest API由Java Spring负责
4.2 Metadata Models

元数据模型采用PDL建模语言进行建模。分为Entity、Aspects、Relationships。
Entity:表示一个实体(如果数据库的一个表),每个实体实例都有一个唯一标识符;
Aspects:表示实体实例的术语、标签等;(DatasetProperties)包含一组描述数据集(Dataset)的属性(attributes)。切面可以在一组实体间共享,例如:属主(Ownership)是一个可以在多个拥有“拥有者(owners)”属性的实体间共享。
Relationships:表示不同实体实例的关系
下面是一个示例图,它由3种类型的实体(CorpUser、 Chart、 Dashboard)、2种类型的关系(OwnedBy、 Contains)和3种类型的元数据方面(OwnedInfo、 ChartInfo 和 DashboardInfo)组成。
实体(Entities)的核心类型:
- Data Platform: 一种数据“平台”。也就是说,涉及处理、存储或可视化数据资产的外部系统。示例包括 MySQL、 Snowflake、 Redshift 和 S3。
- DataSet: 一组数据。表、视图、流、文档集合和文件都在 DataHub 上建模为“数据集”。数据集可以有标记、所有者、链接、术语表术语和附加到它们的描述。它们还可以具有特定的子类型,如“视图”、“集合”、“流”、“探索”等。示例包括 Postgres 表、 MongoDB 集合或 S3文件。
- Chart: 图表,从数据集派生的单个数据可视化。单个图表可以是多个仪表板的一部分。图表可以有标签、所有者、链接、术语表术语以及附加到它们的描述。示例包括超集或查看器图表。
- Dashboard: 用于可视化的图表集合。仪表板可以有标签、所有者、链接、术语表术语和描述附加到它们上面。示例包括 Superset 或 Mode Dashboard。
- Data Job,Task: 处理数据资产的可执行作业,其中“处理”意味着消耗数据、生成数据或两者兼而有之。数据作业可以有标签、所有者、链接、术语表术语以及附加到它们的描述。它们必须属于单个数据流。示例包括 Airflow 任务。
- Data Flow(pipe line) : 数据作业的一个可执行集合,它们之间存在依赖关系,或者一个 DAG。数据作业可以有标签、所有者、链接、术语表术语以及附加到它们的描述。例子包括气流 DAG。
元数据模型不同实体间的关系:
DataSets元数据模型
DataSets元数据模型支持由三部分组成:
- Data Platform (e.g. urn:li:dataPlatform:mysql)
- Name (e.g. db.schema.name)
- Env or Fabric (e.g. DEV, PROD, etc.)
完整的:urn:li:dataset:(urn:li:dataPlatform:<platform>,<name>,ENV)
4.3 Ingestion Framework
元数据导入框架通过插件(python库)的方式,集成到Datahub系统。
可以从不同的数据平台将元数据,两种方式:
- 以Rest API直接导入,
- 将元数据生产到Kafka,再从Kafka消费导入到Datahub
元数据导入只需定义一个YAML文件,并执行datahub元数据导入命令
元数据摄取
元数据集成datahub支持push-based与pull-based两种方式:
push-based:直接是数据源系统在元数据发生变化时主动推送到datahub
pull-based:是连接到数据源通过批量或者增量的方式提取元数据的过程
datahub提供两种形式的元数据摄取:通过直接api调用或kafka流。前者适合离线,后者适合实时。
datahub的api基于rest.li,这是一种可扩展的,强类型的restful服务架构,已在linkedin上广泛使用。由于rest.li使用pegasus作为其接口定义,因此可以逐字使用上一节中定义的所有元数据模型。从api到存储需要多层转换的日子已经一去不复返了-api和模型将始终保持同步。
对于基于kafka的提取,预计元数据生产者将发出标准化的元数据更改事件(mce),其中包含由相应实体urn键控的针对特定元数据方面的建议更改列表。
对api和kafka事件模式使用相同的元数据模型,使我们能够轻松地开发模型,而无需精心维护相应的转换逻辑。
元数据服务
datahub旨在支持对大量元数据的四种常见查询类型:
- 面向文档的查询
- 面向图的查询
- 涉及联接的复杂查询
- 全文搜索
4.4 GraphQL API
GraphQL API提供了一个强类型的、面向Entiry的API,通过GraphQL API与储存的元数据进行交互

4.5 User Interface
4.5 用户管理
新用户帐户可以通过3种方式在 DataHub 上供应:
-
- 共享邀请链接
-
- 使用 OpenID 链接来配置单点登录(支持的有Azure AD, Okta, keycloak,Ping!, Google Identity)
-
- 静态凭证配置文件(仅自托管)单点登录


- 静态凭证配置文件(仅自托管)单点登录
5. 特性
5.1 SQL分析
每个表的行和列计数对于每个列:
- 空值计数和比例
- 不同的数量和比例
- 最小值,最大值,平均值,中位数,标准差,一些分位数值
- 独特值的直方图或频率

5.2 数据血缘
DataHub 支持的数据血缘连接类型如下:
- 数据集到数据集
- 流水线谱系(数据集到作业到数据集dataset-to-job-to-dataset)
- 从仪表盘到图表的血统
- 图表到数据集的血缘
- Job-to-dataflow (dbt 血缘)
字段血缘支持不足 没有atlas对hive那么精细?
新版本支持了字段血缘,FineGrainedLineages可以加上下游字段对应:

6. 安装
6.1 release版本
Data Hub v0.1.0-alpha Pre-release 2019-10-28 warehouse文章来源:https://www.toymoban.com/news/detail-465017.html
LinkedIn开源出来的,原来叫做WhereHows 。经过一段时间的发展datahub于2020年2月在Github开源文章来源地址https://www.toymoban.com/news/detail-465017.html
| Version | Release Date | Links |
|---|---|---|
| v0.10.0 | 2023-02-07 | Release Notes, View on G |
到了这里,关于DataHub调研&数据血缘的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!