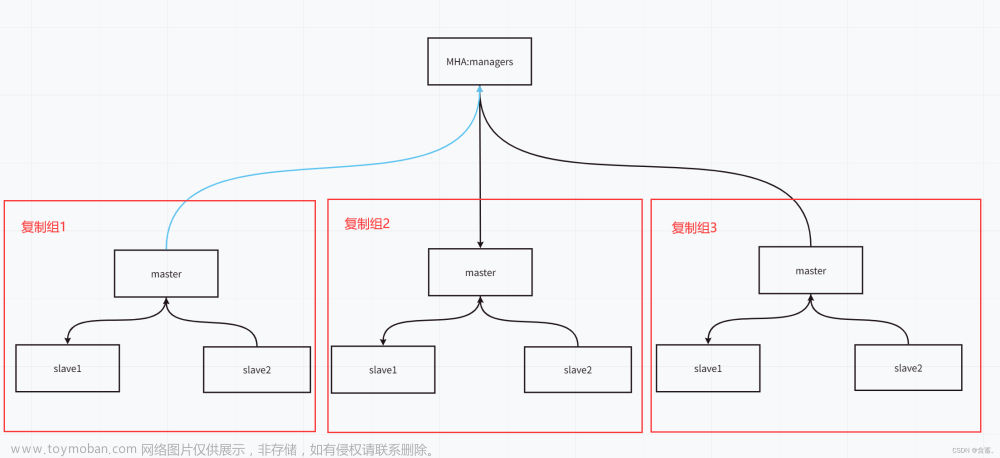
3、故障切换演练
3.1 failover切换演练
场景一、自动failover,主从正常,从IO,SQL进程down掉,主库down掉
- slave01停止IO、SQL线程
- 模拟主库down机
3.1.1 slave01停止复制
Mysql>stop replica; |
3.1.2 主库down机
| Pkill -9 mysqld |
3.1.3 观察maanger日志
| Master 172.16.134.24(172.16.134.24:3310) is down! Check MHA Manager logs at ebsproddb.ys:/var/log/mha/app1/manager.log for details. Started automated(non-interactive) failover. Invalidated master IP address on 172.16.134.24(172.16.134.24:3310) None of existing slaves matches as a new master. Maybe preferred node is misconfigured or all slaves are too far behind. Got Error so couldn't continue failover from here. Tue Mar 14 10:56:53 2023 - [info] Sending mail.. Unknown option: conf tail: manager.log: file truncated Thu Mar 16 19:32:14 2023 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Thu Mar 16 19:32:14 2023 - [info] Reading application default configuration from /etc/mha/masterha_default.cnf.. Thu Mar 16 19:32:14 2023 - [info] Reading server configuration from /etc/mha/masterha_default.cnf.. Thu Mar 16 19:32:14 2023 - [info] MHA::MasterMonitor version 0.58. Thu Mar 16 19:32:15 2023 - [info] GTID failover mode = 1 ----- Failover Report ----- masterha_default: MySQL Master failover 172.16.134.24(172.16.134.24:3310) to 172.16.134.25(172.16.134.25:3310) succeeded Master 172.16.134.24(172.16.134.24:3310) is down! Check MHA Manager logs at ebsproddb.ys:/var/log/mha/app1/manager.log for details. Started automated(non-interactive) failover. Invalidated master IP address on 172.16.134.24(172.16.134.24:3310) Selected 172.16.134.25(172.16.134.25:3310) as a new master. 172.16.134.25(172.16.134.25:3310): OK: Applying all logs succeeded. 172.16.134.25(172.16.134.25:3310): OK: Activated master IP address. 172.16.134.26(172.16.134.26:3310): OK: Slave started, replicating from 172.16.134.25(172.16.134.25:3310) 172.16.134.25(172.16.134.25:3310): Resetting slave info succeeded. Master failover to 172.16.134.25(172.16.134.25:3310) completed successfully. |
场景二、自动failover,备主延迟>100M,从库设置no_maseter
- slave01停止IO线程
- 主库开启压力测试数据
- 开启slave01 IO线程
4、模拟主库down机
3.1.3 slave01停止复制
Mysql>stop slave io_thread; |
3.1.2 主库创建测试数据
| mysqlslap --user=root --password=123456 -h 172.16.134.24 -P 3310 --auto-generate-sql --auto-generate-sql-load-type=write --concurrency=128 --number-of-queries=1000000 --create-schema=test03 |
3.1.3 slave01开启复制
Slave01
| Mysql>start slave io_thread; |
3.1.4 主库down机
| Pkill -9 mysqld |
3.1.6 观察maanger日志
| Tue Mar 14 10:56:48 2023 - [warning] Got error on MySQL select ping: 2006 (MySQL server has gone away) Tue Mar 14 10:56:48 2023 - [info] Executing secondary network check script: /bin/masterha_secondary_check -s 172.16.134.25 -s 172.16.134.26 --user=root --master_host=172.16.134.24 --master_ip=172.16.134.24 --master_port=3310 --master_user=root --master_password=123456 --ping_type=SELECT Tue Mar 14 10:56:48 2023 - [info] Executing SSH check script: exit 0 Tue Mar 14 10:56:48 2023 - [info] HealthCheck: SSH to 172.16.134.24 is reachable. Monitoring server 172.16.134.25 is reachable, Master is not reachable from 172.16.134.25. OK. Monitoring server 172.16.134.26 is reachable, Master is not reachable from 172.16.134.26. OK. Tue Mar 14 10:56:48 2023 - [info] Master is not reachable from all other monitoring servers. Failover should start. ----- Failover Report ----- masterha_default: MySQL Master failover 172.16.134.24(172.16.134.24:3310) Master 172.16.134.24(172.16.134.24:3310) is down! Check MHA Manager logs at ebsproddb.ys:/var/log/mha/app1/manager.log for details. Started automated(non-interactive) failover. Invalidated master IP address on 172.16.134.24(172.16.134.24:3310) None of existing slaves matches as a new master. Maybe preferred node is misconfigured or all slaves are too far behind. Got Error so couldn't continue failover from here. Tue Mar 14 10:56:53 2023 - [info] Sending mail.. Unknown option: conf |
结论:自动failover 失败,主从延迟>100M,另外从添加no_master,找不到新maseter,切换失败。
场景三、自动failover,备主延迟<100M
- slave01停止IO线程
- 主库开启压力测试数据
- 开启slave01 IO线程
- 模拟主库down机
结论:自动failover成功,备主延迟<100M,切换到备主成功。
场景四、自动failover, 备主延迟>100M,从库未设置no_maseter
- slave01停止IO线程
- 主库开启压力测试数据
- 开启slave01 IO线程
4、 模拟主库down机
结论:自动failover成功,备主延迟>100M,切换到从库成功
3.2 手动切换演练
手动failover,这种场景意味着在业务上没有启用MHA自动切换功能,当主服务器故障时,人工手动调用MHA来进行故障切换操作,具体命令如下:
3.2.1检测未开启MHA
| masterha_check_status --conf=/etc/mha/masterha_default.cnf masterha_default is stopped(2:NOT_RUNNING). |
3.2.2 模拟主库down机
| pkill -9 mysqld |
注意:如果,MHA manager检测到没有dead的server,将报错,并结束failover
| Thu Mar 16 20:05:47 2023 - [error][/usr/share/perl5/vendor_perl/MHA/MasterFailover.pm, ln188] None of server is dead. Stop failover. Thu Mar 16 20:05:47 2023 - [error][/usr/share/perl5/vendor_perl/MHA/ManagerUtil.pm, ln177] Got ERROR: at /bin/masterha_master_switch line 53. |
3.2.3手工切换MHA
| masterha_master_switch --master_state=dead --conf=/etc/mha/masterha_default.cnf --dead_master_host=172.16.134.24 --dead_master_port=3310 --new_master_host=172.16.134.25 --new_master_port=3310 --ignore_last_failover |
输出信息询问是否进行切换yes/no
3.2.4 查看切换日志
| Thu Mar 16 20:14:48 2023 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Thu Mar 16 20:14:48 2023 - [info] Reading application default configuration from /etc/mha/masterha_default.cnf.. Thu Mar 16 20:14:48 2023 - [info] Reading server configuration from /etc/mha/masterha_default.cnf.. Thu Mar 16 20:14:48 2023 - [info] MHA::MasterFailover version 0.58. Thu Mar 16 20:14:48 2023 - [info] Starting master failover. Thu Mar 16 20:14:48 2023 - [info] Thu Mar 16 20:14:48 2023 - [info] * Phase 1: Configuration Check Phase.. Thu Mar 16 20:14:48 2023 - [info] ----- Failover Report ----- masterha_default: MySQL Master failover 172.16.134.24(172.16.134.24:3310) to 172.16.134.25(172.16.134.25:3310) succeeded Master 172.16.134.24(172.16.134.24:3310) is down! Check MHA Manager logs at ebsproddb.ys for details. Started manual(interactive) failover. Invalidated master IP address on 172.16.134.24(172.16.134.24:3310) Selected 172.16.134.25(172.16.134.25:3310) as a new master. 172.16.134.25(172.16.134.25:3310): OK: Applying all logs succeeded. 172.16.134.25(172.16.134.25:3310): OK: Activated master IP address. 172.16.134.26(172.16.134.26:3310): OK: Slave started, replicating from 172.16.134.25(172.16.134.25:3310) 172.16.134.25(172.16.134.25:3310): Resetting slave info succeeded. Master failover to 172.16.134.25(172.16.134.25:3310) completed successfully. |
3.3 在线切换演练
许多情况下, 需要将现有的主服务器迁移到另外一台服务器上。 比如主服务器硬件故障,RAID 控制卡需要重建,将主服务器移到性能更好的服务器上等等。维护主服务器引起性能下降, 导致停机时间至少无法写入数据。 另外, 阻塞或杀掉当前运行的会话会导致主主之间数据不一致的问题发生。 MHA 提供快速切换和优雅的阻塞写入,这个切换过程只需要 0.5-2s 的时间,这段时间内数据是无法写入的。在很多情况下,0.5-2s 的阻塞写入是可以接受的。因此切换主服务器不需要计划分配维护时间窗口。
MHA在线切换的大概过程:
1.检测复制设置和确定当前主服务器
2.确定新的主服务器
3.阻塞写入到当前主服务器
4.等待所有从服务器赶上复制
5.授予写入到新的主服务器
6.重新设置从服务器
注意,在线切换的时候应用架构需要考虑以下两个问题:
1.自动识别master和slave的问题(master的机器可能会切换),如果采用了vip的方式,基本可以解决这个问题。
2.负载均衡的问题(可以定义大概的读写比例,每台机器可承担的负载比例,当有机器离开集群时,需要考虑这个问题)
为了保证数据完全一致性,在最快的时间内完成切换,MHA的在线切换必须满足以下条件才会切换成功,否则会切换失败。
1.所有slave的IO线程都在运行
2.所有slave的SQL线程都在运行
3.所有的show slave status的输出中Seconds_Behind_Master参数小于或者等于running_updates_limit秒,如果在切换过程中不指定running_updates_limit,那么默认情况下running_updates_limit为1秒。
4.在master端,通过show processlist输出,没有一个更新花费的时间大于running_updates_limit秒。
检测MHA状态
| masterha_check_status --conf=/etc/mha/masterha_default.cnf masterha_default is stopped(2:NOT_RUNNING). |
在线切换
| masterha_master_switch --conf=/etc/mha/masterha_default.cnf --master_state=alive --new_master_host=172.16.134.25 --new_master_port=3310 --orig_master_is_new_slave --running_updates_limit=10000 |
查看切换日志
| masterha_master_switch --conf=/etc/mha/masterha_default.cnf --master_state=alive --new_master_host=172.16.134.25 --new_master_port=3310 --orig_master_is_new_slave --running_updates_limit=10000 Mon Mar 20 19:14:23 2023 - [info] MHA::MasterRotate version 0.58. Mon Mar 20 19:14:23 2023 - [info] Starting online master switch.. Mon Mar 20 19:14:23 2023 - [info] Mon Mar 20 19:14:23 2023 - [info] * Phase 1: Configuration Check Phase.. Mon Mar 20 19:14:23 2023 - [info] Mon Mar 20 19:16:37 2023 - [info] -- Slave switch on host 172.16.134.26(172.16.134.26:3310) succeeded. Mon Mar 20 19:16:37 2023 - [info] Unlocking all tables on the orig master: Mon Mar 20 19:16:37 2023 - [info] Executing UNLOCK TABLES.. Mon Mar 20 19:16:37 2023 - [info] ok. Mon Mar 20 19:16:37 2023 - [info] Starting orig master as a new slave.. Mon Mar 20 19:16:37 2023 - [info] Resetting slave 172.16.134.24(172.16.134.24:3310) and starting replication from the new master 172.16.134.25(172.16.134.25:3310).. Mon Mar 20 19:16:37 2023 - [info] Executed CHANGE MASTER. Mon Mar 20 19:16:37 2023 - [info] Slave started. Mon Mar 20 19:16:37 2023 - [info] All new slave servers switched successfully. Mon Mar 20 19:16:37 2023 - [info] Mon Mar 20 19:16:37 2023 - [info] * Phase 5: New master cleanup phase.. Mon Mar 20 19:16:37 2023 - [info] Mon Mar 20 19:16:37 2023 - [info] 172.16.134.25: Resetting slave info succeeded. Mon Mar 20 19:16:37 2023 - [info] Switching master to 172.16.134.25(172.16.134.25:3310) completed successfully. You have mail in /var/spool/mail/root文章来源:https://www.toymoban.com/news/detail-465079.html |
切换成功文章来源地址https://www.toymoban.com/news/detail-465079.html
到了这里,关于Mysql8 MHA(完结)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!