一、搭建准备
1.安装VMware虚拟机
官网链接
进入后网站如图,各位按需下载
2.Xshell 7 远程客户端及Xftp 7安装
官网链接
进入页面点击下载
再根据我们需要下载的软件进入下载页面
点击右侧红框内的免费授权页面获取免费许可
进入后如图,两者我们都需要所以都勾选,填写的邮箱用于接收下载链接,下载后进行安装即可
3.搭建模板虚拟机hadoop100
这里先和大家强调一点,模板虚拟机搭建完成后作为母本不要去随意修改变动,因为当你的集群崩溃或者出现其它各种问题需要重新搭建时就可以直接克隆模板虚拟机了,省去不少时间,否则当出现问题时想起自己没有备留母本每次都要重新配置是很麻烦的
配置虚拟机网络
首先确认虚拟机是否可以联网,因为后面yum安装是需要网络的
如图为联网失败,正常未配置网络时应该是这样的
这里表示网络配置成功
下面说明如何配置网络
这里我使用的是minimal的centos7作为虚拟机范本,minimal版本的好处就是包体较小,需要什么工具自己再安装即可,相对的除了一些基本的工具和内核,其它例如图形化界面都是没有的(都可自行安装)
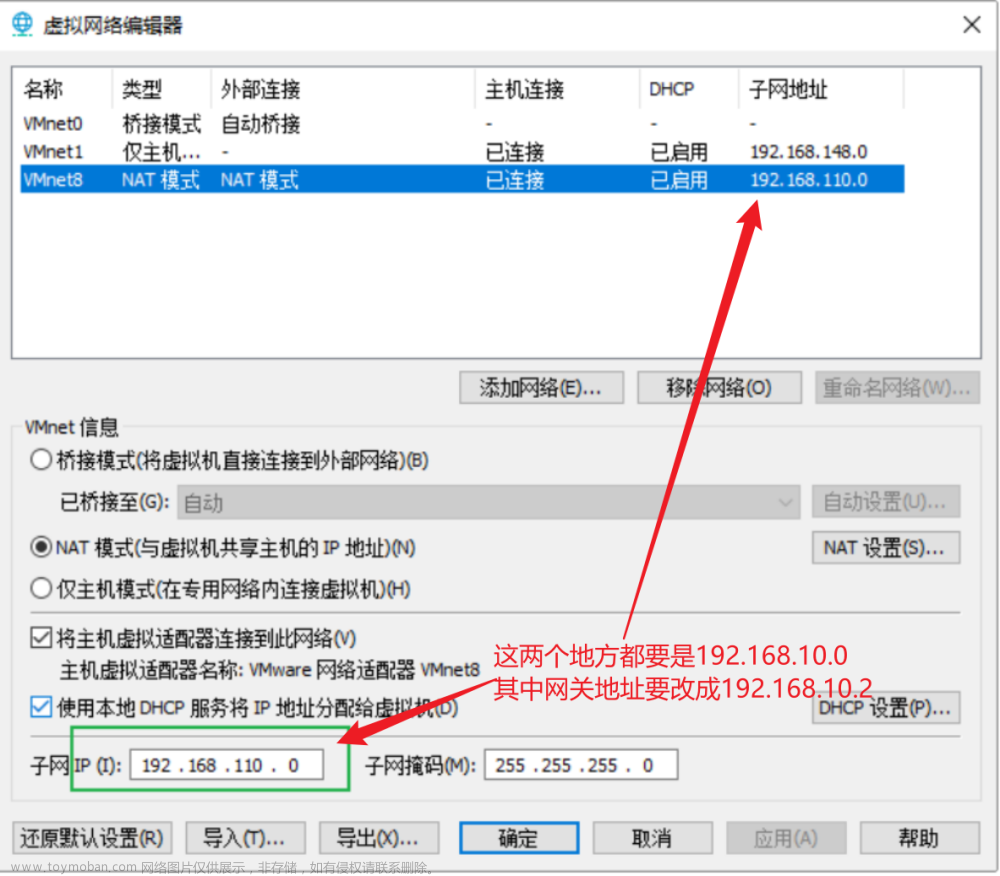
首先点击VM左上角的编辑,再点击虚拟网络编辑器进入后点击如图的更改设置
进入后点击NAT模式,可以按照我的图示修改子网和子网掩码以及网关(点击NAT设置),子网IP也可自己设置但别设置一些特殊的就行,网关和子网前三位保持一致,还有这些设置的值请记住后面还要用到

然后我们返回主机Windows
这里是Win11系统,在设置中点击网络和Internet再进入高级网络设置,点击更多网络适配器选项,不同系统版本进入方式可能会有所不同
进入后点击VMnet8,再点击IPv4按照之前虚拟机中的网络配置对此处进行相同操作,DNS可填8888等也可不填,IP地址和子网掩码,网关务必保持一致
之后回到虚拟机
minimal的centos是没有vim编辑器及一些工具包的,所以进行网络配置时我们选择通过vi命令访问文件进行修改
输入
su //回车后输入root密码进入root管理员模式才能修改保存接下来的文件
vi /etc/sysconfig/network-script/ifcfg-ens33
按照图上进行修改,把ip由原先的dhcp修改为static(静态),后面再补上IP地址,子网掩码,网关,DNS等,ZONE那行可以不写
看到这里相信大家也注意到了,配置虚拟机网络最关键的一点在于保证虚拟网络编辑器、主机Windows以及虚拟机内部网卡三者的子网地址、子网掩码以及网关等保持一致
配置完成后输入以下代码重启网络服务
service network restart
再进行网络检测,ping网成功
最后再安装相关的工具包及软件,模板虚拟机基本搭建完成
yum install -y net-tools //安装工具包集合,包含ifconfig等命令
yum install -y vim //安装vim编辑器
yum install -y epel-release //epel指Extra Packages for Enterprise Linux,提供额外的软件包。相当于是一个软件仓库,大多数rpm包在官方 repository 中是找不到的)
为虚拟机普通用户配置root权限
在root用户下输入
vim /etc/sudoers
或者在普通用户下输入
sudo vim /etc/sudoers //注意这里因为还未配置root权限,所以需要输入用户密码
修改文件,找到%wheel这行,在其下添加
用户名 ALL=(ALL) NOPASSWD:ALL
如图,用户名填自己的
之后再执行需要root权限的命令时可直接输入sudo + 命令执行,不需要再输入密码
4.克隆三台虚拟机用于搭建完全分布式集群
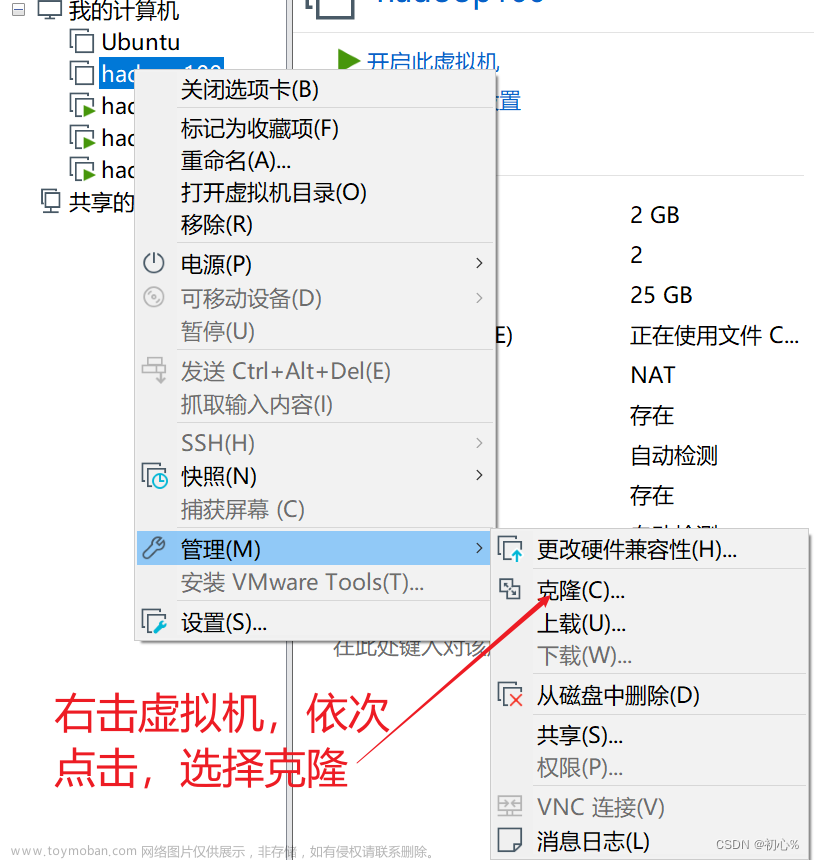
关闭hadoop100,右键划至管理,点击克隆
注意下图,这里点击创建完整克隆而非链接克隆
克隆出3台虚拟机分别命名为hadoop101,hadoop102,hadoop103,并通过命令进入ens33各自修改下IP地址
如图hadoop101为例:
这里我将原先的结尾的100改为了101,前三位的数字不要改变,大家在保证几个虚拟机的地址不冲突的情况下修改就行
二、环境搭建
1.主机地址的映射
首先进入root模式
再修改主机名称
vim /etc/hostname
hadoop101 //每个克隆的主机名称依次改为101,102,103
再配置主机名称的映射hosts文件
vim /etc/hosts
将下面的内容粘贴进去,使主机名与IP地址相映射
192.168.10.100 hadoop100
192.168.10.101 hadoop101
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104
192.168.10.105 hadoop105
192.168.10.106 hadoop106
192.168.10.107 hadoop107
192.168.10.108 hadoop108
重启虚拟机
reboot
修改Windows的主机映射文件
C:\Windows\System32\drivers\etc //路径
进入后找到hosts文件,将同样的内容粘贴进去
可能不同电脑的有名字有不同,但内容打开应该是差不多的,如果文件名字不同一定要改为hosts,否则可能无效,如果直接粘贴不了可以先拷贝出来修改保存再进行覆盖即可
2.使用Xshell连接虚拟机
打开Xshell,点击左上角新建
名称可按自己喜好取,主机处填需要连接的虚拟机的子网IP地址,例如连接的是hadoop101的话就填192.168.10.101(当时在ens33网卡处填写的IP地址),这里能直接填hadoop101是因为修改了Linux和Windows的主机映射文件,使主机名即可代表IP地址即上一步所作的好处体现了出来,记下主机名显然比IP地址简单得多

**之后再点击用户身份验证,此处用户名和密码按照自己设置的来,连接时可以省去登录验证,不建议直接填root用户
**
确定后进行连接,完成如图所示,说明登录成功
同样的方法将克隆的三台虚拟机都连接上即可
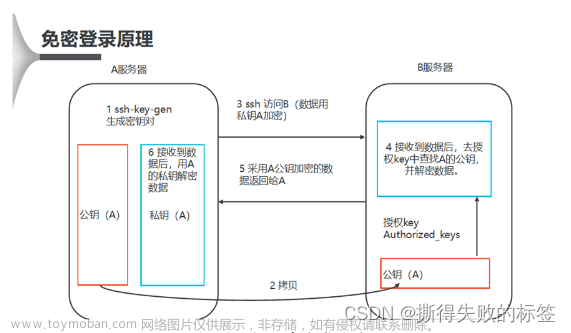
3.SSH免密登录配置(另一篇文章写过,这里就直接放链接了)
SSH免密登录教程
4.配置集群分发脚本
在用户名下创建bin文件夹,并在bin内创建xsync脚本
cd /home/用户名
mkdir bin
vim xsync
将以下代码粘贴进脚本中,注意2中的host名称与自己的保持一致
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop101 hadoop102 hadoop103
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
给脚本配置执行权限
chmod +x xsync
测试脚本
xsync /home/用户名/bin //在root权限下输入,或者使用sudo
5.配置hadoop及java环境变量
新建文件my_env.sh用于配置环境变量
sudo vim /etc/profile.d/my_env.sh
输入
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk-11
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
注意配置的环境变量第一行后的名称和自己解压出来的名称保持一致
保存退出后输入以下命令使新的环境变量生效
source /etc/profile
输入以下命令检查是否配置成功
hadoop version
java -version
6.安装hadoop及jdk包(通过Xftp)
这里首先提醒jdk版本不要下载过新的版本,最好是jdk11以下,否则群起集群时可能会出现问题
首先在opt处创建文件夹,用于存放存放和解压文件
cd /opt //进入此文件夹
mkdir software //创建此文件夹用于传输下载的hadoop和jdk包
mkdir module //创建此文件夹用于存放解压文件
使用ll命令可以查看当前目录下的文件夹
如图可以看到这两个文件夹已经创建好了,其它的文件夹是我自行创建的可以不用管,只需要创建这两个文件夹即可
打开Xshell点击红圈处启动Xftp
在左侧找到需要传输的hadoop以及jdk包体,进行传输
注意这一步可能报错传输失败,原因是文件夹缺少写入权限,右键文件夹点击更改文件权限可以查看
如果显示不是777而是755之类的说明没有写入权限,直接在此修改为777即可
修改后如果再次查看发现权限没有改变那就去虚拟机下进行修改
输入命令
chmod 777 文件夹名 //为文件夹赋予写入权限,再回看可以看到权限已经变为777了,可以进行数据传输
接下来便是解压文件
输入以下命令将两个压缩包均解压至module文件夹
tar -zxvf hadoop-3.3.4.tar.gz -C /opt/module/ //包体名以自己的为准
解压成功后查看如图
按照图示输入检验是否配置成功

7.配置集群文件
集群规划
| hadoop101 | hadoop102 | hadoop103 | |
|---|---|---|---|
| HDFS | NameNode Datanode | Datanode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
自定义配置文件
四个配置文件core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml,都包含在以下路径,可进入后按需修改
cd $HADOOP_HOME/etc/hadoop
核心配置文件
vim core-site.xml
在文件内补充内容,configuration内应该是空的,补充即可,注意地址名称、用户名、hadoop版本等要与自己的一致
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.3.4/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为fancy -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>fancy</value>
</property>
</configuration>
HDFS配置文件
vim hdfs-site.xml
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop101:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop103:9868</value>
</property>
</configuration>
YARN配置文件
vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
MapReduce配置文件
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
分发脚本
全部配置完成后通过之前配置的脚本xsync将配置同步到另外两台虚拟机上
xsync /opt/module/hadoop-3.3.4/etc/hadoop/
三、群起集群
1.配置workers
vim /opt/module/hadoop-3.3.4/etc/hadoop/workers
添加三台主机名称,注意名称后不能有空格,中间也不能有空行
2.格式化(第一次启动)
首次启动集群需要在hadoop101格式化NameNode
hdfs namenode -format //hadoop-3.3.4目录下
注意格式化NameNode会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。所以如果需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,再进行格式化。
3.启动集群
在hadoop101输入
sbin/start-dfs.sh //启动HDFS
sbin/start-yarn.sh //启动YARN
特别注意启动YARN时要在配置了ResourceManager的节点启动,否则ResourceManager会启动失败
4.web端查看以及jps命令确认集群启动成功
浏览器输入
http://hadoop101:9870 //查看HDFS的NameNode
http://hadoop102:8088 //查看YARN的ResourceManager
如图
 文章来源:https://www.toymoban.com/news/detail-465145.html
文章来源:https://www.toymoban.com/news/detail-465145.html
同样在各个虚拟机通过输入jps命令也可以查看到集群的启动情况,如果启动成功,各个虚拟机对应查看到的应该与集群规划时的一致
如图

 文章来源地址https://www.toymoban.com/news/detail-465145.html
文章来源地址https://www.toymoban.com/news/detail-465145.html
到了这里,关于大数据开发·关于虚拟机Hadoop完全分布式集群搭建教程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!